
模型部署之知识蒸馏:理论、原理与实践
知识蒸馏(Knowledge Distillation)
1. 模型蒸馏概述
定义
知识蒸馏(Knowledge Distillation)是一种模型压缩和迁移学习的技术,旨在训练一个较小的学生模型(Student Model),使其能够模仿更大、更复杂的教师模型(Teacher Model)的行为。学生模型通过学习教师模型的输出概率分布(软标签)以及原始数据集上的标签信息,获得更好的泛化能力和性能表现。这种方法使得学生模型能够在保持较高精度的同时更加轻量级,适合部署到资源受限环境中。
优点
- 高效性:学生模型在资源消耗上远低于教师模型,同时能保持较高的性能水平,非常适合移动设备或边缘计算场景。
- 迁移学习:可以从预训练的大型模型中提取有用的信息,而不需要从头开始训练整个模型,大大减少了训练时间和成本。
- 简化部署:较小的学生模型更容易部署,并且可以降低推理时的延迟,提高用户体验。
挑战
- 设计合适的温度参数:温度参数 (T) 用于控制软标签的平滑程度,对学生的最终学习效果有着重要影响。选择不当可能导致学生模型过拟合或欠拟合教师模型的知识。
- 选择适当的架构:为了有效捕捉教师模型的知识,学生模型需要有足够的表达能力,但又不能过于复杂以至于失去轻量化的优势。
2. 知识蒸馏的原理和算法
2.1 教师模型
定义
教师模型通常是一个复杂且高性能的深度神经网络,具有大量的参数,能够捕捉输入数据中的复杂特征和关系。由于其较大的规模和高计算需求,教师模型可能不适合直接应用于实际生产环境中,但却是传授知识给学生模型的理想来源。
特点
- 参数量大,能够学习复杂的特征和模式。
- 在某些情况下,教师模型可能是经过长时间训练得到的最佳模型之一,拥有出色的预测性能。
2.2 学生模型
定义
学生模型是简化版的教师模型,参数量较少,结构更为紧凑。它的设计目的是在保证一定性能的前提下,尽量减少计算资源的使用,以便于快速部署和高效运行。
特点
- 参数量小,适用于资源受限的环境,如移动端或嵌入式系统。
- 能够继承教师模型的部分性能优势,实现良好的权衡。
2.3 蒸馏过程
图解: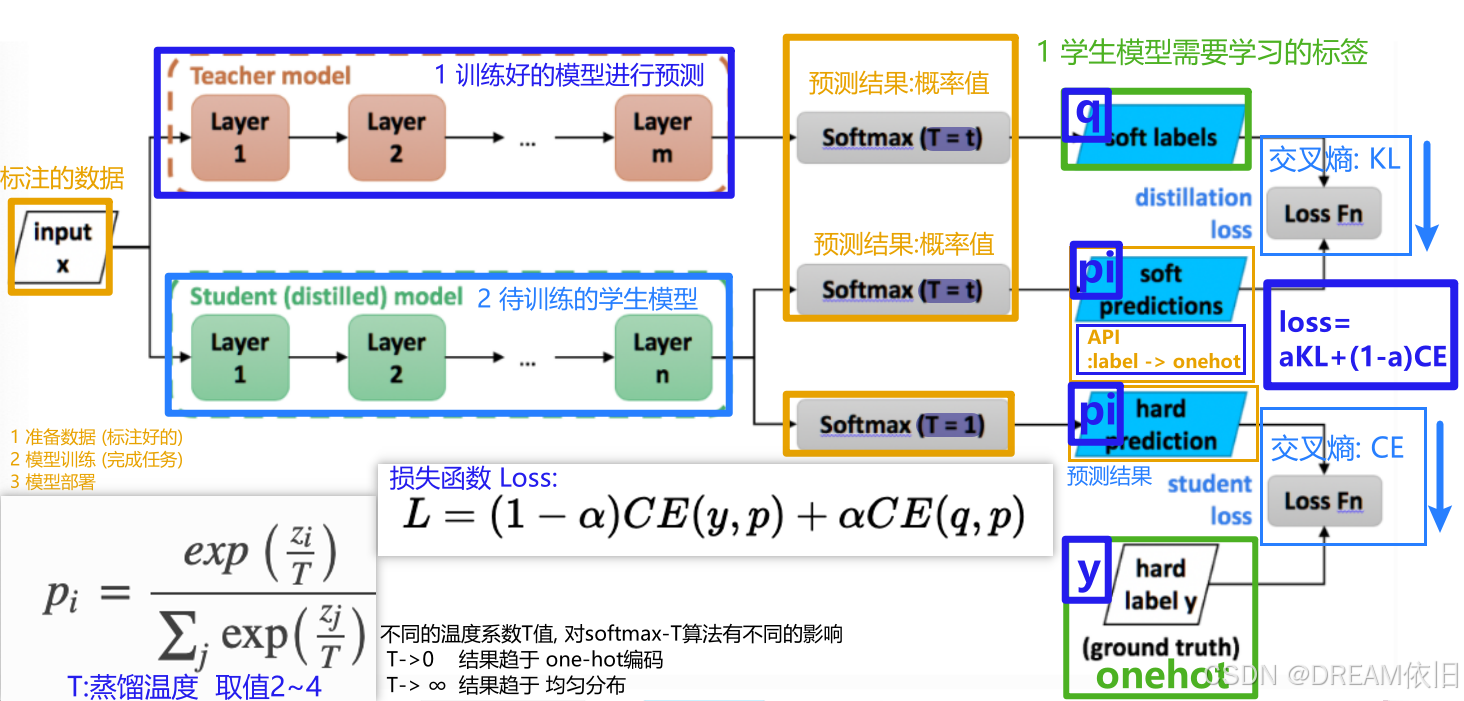
流程
蒸馏过程主要包括以下几个基本步骤:
- 训练教师模型:首先使用完整的训练集来训练一个高性能的教师模型。
- 准备软标签:利用教师模型对训练样本进行推断,生成包含更多细节信息的概率分布作为软标签。
- 训练学生模型:基于原始数据集的真实标签和教师提供的软标签,采用特定的损失函数对学生模型进行训练。
公式
在知识蒸馏过程中,常用的损失函数结合了交叉熵损失和教师模型输出的软标签。具体来说,损失函数 (L) 可以表示为:
L = ( 1 − α ) ⋅ C E ( y , p ) + α ⋅ K L ( softmax ( q / T ) ∑ j softmax ( q j / T ) , softmax ( p / T ) ∑ j softmax ( p j / T ) ) \ L = (1-\alpha) \cdot CE(y, p) + \alpha \cdot KL\left(\frac{\text{softmax}(q/T)}{\sum_j \text{softmax}(q_j/T)}, \frac{\text{softmax}(p/T)}{\sum_j \text{softmax}(p_j/T)}\right) \ L=(1−α)⋅CE(y,p)+α⋅KL(∑jsoftmax(qj/T)softmax(q/T),∑jsoftmax(pj/T)softmax(p/T))
其中,
- (CE) 是交叉熵(Cross Entropy),
- (y) 是真实标签,
- (q) 是教师模型的输出结果,
- (p) 是学生模型的输出结果,
- (KL) 表示Kullback-Leibler散度,用来衡量两个概率分布之间的差异,
- (T) 是温度系数,用于调整软标签的平滑程度,
- (\alpha) 是一个权重因子,用于平衡两种损失的重要性。
对于学生模型的学习目标 (p),我们通常会应用带有温度系数 (T) 的 softmax 函数,即:
p i = exp ( z i / T ) ∑ j exp ( z j / T ) \ p_i = \frac{\exp(z_i / T)}{\sum_j \exp(z_j / T)} \ pi=∑jexp(zj/T)exp(zi/T)
这里 (z_i) 是学生模型在最后一个全连接层之前的输出(logits)。通过调节 (T) 的值,我们可以控制软标签的平滑程度:
- 当 (T=1) 时,上述公式退化为标准的 softmax 函数;
- 随着 (T) 增加,输出的概率分布变得更加平缓,有助于保留相似类别的信息;
- 当 (T) 接近无穷大时,所有类别上的概率趋向均匀分布;
- 相反,当 (T) 接近 0 时,最大值接近 1,其余接近 0,类似 one-hot 编码。
一般实践中,(T) 的取值范围在 2 到 4 之间,这既能保证足够的平滑度,又不会使分布过于平坦。
3. 应用案例与发展前景
随着硬件性能的不断提升以及应用场景的多样化,知识蒸馏技术得到了广泛的应用和发展。例如,在自然语言处理领域,BERT等大型预训练模型可以通过蒸馏方法转化为更小、更快的版本,如DistilBERT;在计算机视觉方面,ResNet等复杂网络也可以被蒸馏成MobileNet这样的轻量级模型,从而更好地适应移动端的需求。此外,研究者们还在探索如何将多模态或多任务的知识有效地传递给单一模型,进一步拓展了知识蒸馏的应用边界。

在这里,我们一起交流AI,学习AI,用AI改变世界。如有AI产品需求,可访问讯飞开放平台,www.xfyun.cn。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)