
【保姆级教程】使用ollama在cpu上运行llamafactory训练后的大模型
本地运行条件有限,原本在GPU上训练运行正常的模型,转到CPU上就不可以运行了,所以就有了这篇文章。大模型:Qwen/Qwen2.5-7B-Instruct。训练框架:llamafactory。转格式工具:llama.cpp。运行工具:ollama。
一、前言

本地运行条件有限,原本在GPU上训练运行正常的模型,转到CPU上就不可以运行了,所以就有了这篇文章。主要用的模型与技术有下:
大模型:Qwen/Qwen2.5-7B-Instruct
训练框架:llamafactory
转格式工具:llama.cpp
运行工具:ollama
二、处理 llamafactory 训练后的数据
训练完成后的文件存储至saves目录下,如图:
1.大模型合并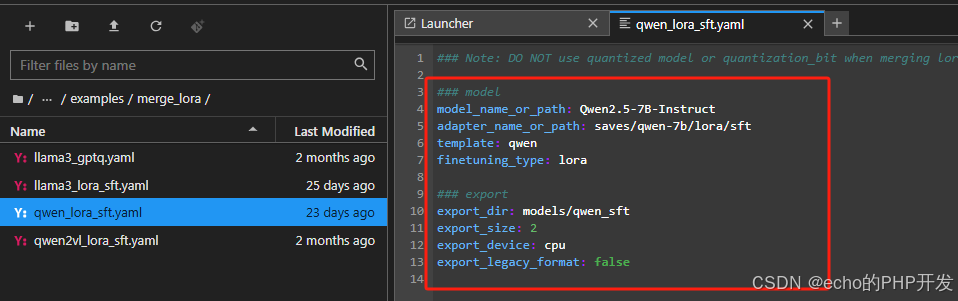
执行 llamafactory-cli export examples/merge_lora/qwen_lora_sft.yaml
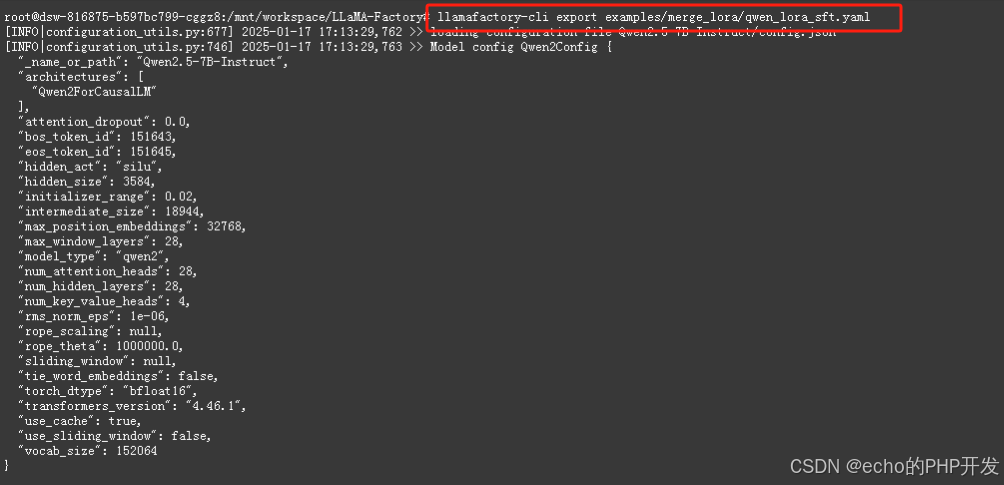
执行完成后,会在model/qwen/ 路径下生成合成的相关文件,如下图:
二、lama.cpp模型转换guff
1. 安装llama.cpp
下载文件:https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py
2. 模型转换
python3 convert_lora_to_gguf.py /data/release/models/qwen_sft --outtype f16 --outfile
解释:
/data/release/models/qwen_sft 为合并之后的文件路径
/data/release/models/qwen_sft/qwen_sft.gguf 为转化后文件的路径和文件名
–outtype f16根据项目需求进行调整
三、ollama 运行转换后的gguf模型文件
1.ubuntu22.04安装ollama
2. 创建 ModelFile 文件
FROM ./my_model.gguf
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
"""
SYSTEM """
系统提示词,限制等
"""
PARAMETER stop [INST]
PARAMETER stop [/INST]
PARAMETER stop <<SYS>>
PARAMETER stop <</SYS>>
PARAMETER temperature 0.7
PARAMETER top_p 0.9
PARAMETER top_k 20
PARAMETER repeat_penalty 1.05
PARAMETER seed 10
PARAMETER num_ctx 4096

3. 运行这个模型
ModelFile 为上面创建的ModelFile文件,模型文件较大的话,运行会比较慢,稍等即可
ollama create my_model -f ModelFile
4. 常用的ollama 命令
启动Ollama服务: ollama serve
创建模型: ollama create /path/to/Modelfile
显示模型信息: ollama show model_name
列出所有模型: ollama list 或 ollama ls
运行模型: ollama run model_name
列出正在运行的模型: ollama ps
删除模型: ollama rm model_name
查看版本: ollama -v 或 ollama --version
复制模型: ollama cp old_model new_model
从注册表拉取模型: ollama pull model_name
将模型推送到注册表: ollama push model_name
获取有关Ollama任何命令的帮助信息: ollama help

在这里,我们一起交流AI,学习AI,用AI改变世界。如有AI产品需求,可访问讯飞开放平台,www.xfyun.cn。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)