
一文搞懂大模型强化学习策略:DPO、PPO和GRPO
大模型很多技术干货,都可以共享给你们,如果你肯花时间沉下心去学习,它们一定能帮到你!
随着 DeepSeek 的兴起以及其研究人员引入的创新方法,强化学习在大模型对齐和微调中的应用成为了研究的前沿。
但要真正理解 RLHF,我们需要先回顾一下历史。2017 年,OpenAI 的研究人员引入了一种名为近端策略优化(PPO)的新算法。为什么要选择 PPO?早期的强化学习方法往往不稳定且难以调优。PPO 的设计目标是更加可靠和高效,使强化学习能够更实际地应用于复杂问题。
到 2022 年,OpenAI 研究人员在开创性的 InstructGPT 论文中将 PPO 提升到了一个新的水平。这篇论文展示了如何利用 PPO 根据人类偏好对大型语言模型(如 GPT-3)进行微调。InstructGPT 学会了生成人类真正喜欢的文本——这些文本是有帮助且无害的,而不仅仅是预测下一个单词。
如今,这一领域发展迅速!研究人员不断寻找改进 RLHF 的方法,使其更加高效和有效。一个令人兴奋的新进展是 DeepSeek AI 引入的组相对策略优化(GRPO)。GRPO 在 PPO 的基础上进行了改进,使 RLHF 训练更加精简和快速,尤其是在复杂的推理任务中。2023 年,斯坦福大学的研究人员引入了一种名为 DPO 的新方法。
这篇文章是关于 RLHF 中三个关键算法的友好指南:PPO、DPO 和 GRPO。我们将逐步剖析它们,即使你刚刚开始 LLM 微调之旅,也能轻松理解。
1. 必备基础知识
在深入算法之前,让我们先准备一些强化学习的必备工具。这些是你需要的基本概念:
1.1 强化学习(RL)
想象一下教一辆自动驾驶汽车。你不会为每一种可能的情况编写代码,对吧?相反,你会让它通过驾驶来学习,并给予它反馈,例如:
-
奖励:当它保持在车道内、遵守交通规则或到达目的地时,给予“干得好!”的反馈。
-
惩罚:当它偏离车道或离其他车辆太近时,给予“小心!”的反馈。
这就是强化学习(RL)的核心。一个 AI 代理(比如我们的自动驾驶汽车或 LLM)通过在环境中做出决策来学习,目标是最大化长期奖励。它学习一种策略——一种在不同情境下选择行动的方法。
1.2 为什么 LLM 需要偏好学习?
对于简单任务,定义奖励很容易(“到达出口得 +1 分”)。但对于生成文本的 LLM,什么是“好”文本?它不仅仅是语法或事实的问题,而是人类的品味、思维的连贯性、推理的正确性、消除输出中不希望出现的偏见等更多内容。
这些是主观的!尝试编写一个“好文本”的公式是非常困难的。
偏好学习来帮忙!与其编写一个奖励公式,我们使用人类的偏好。我们让人们比较两个 LLM 的响应,并询问“你更喜欢哪一个?”
-
人类裁判,而非公式:人类成为我们的“奖励函数”。
-
学习人类喜欢的内容:我们训练 LLM 生成人类更可能喜欢的文本。
1.3 奖励模型
在训练过程中,我们不能让人类对每一个 LLM 的响应进行评判——那太慢了。因此,我们训练一个奖励模型——一个学习模仿人类偏好的人工智能裁判。
-
奖励模型 = AI 品尝师:我们在人类偏好数据上训练它。它学会给人类倾向于喜欢的文本赋予更高的分数。
-
RL 算法使用奖励模型:像 PPO、DPO 和 GRPO 这样的算法随后使用这个奖励模型来指导 LLM 的学习。LLM 试图生成能够从 AI 裁判那里获得高分的文本。
2. 近端策略优化(PPO)
PPO 是一种强大且可靠的强化学习算法,通常是 RLHF 的起点。
谨慎的改进步骤:PPO 就像是教你的 LLM 一步步走路,确保它在每次更新时不会摔倒。它对 LLM 的“走路方式”(策略)进行温和的调整。
PPO 的关键角色:
-
策略(LLM):我们正在训练的 LLM,用于生成更好的文本。
-
奖励模型:根据人类偏好对文本打分的 AI 裁判。
-
价值函数(辅助教练):另一个 AI 模型,充当“辅助教练”。它估计每个状态的“好坏”(当前文本生成的前景如何)。这有助于 PPO 进行更智能的更新。
PPO 训练
-
生成文本(Rollout):LLM(策略)为不同的提示生成大量文本样本。
-
获取分数(奖励模型):奖励模型对每个文本样本进行打分。
-
计算优势(GAE —— “好多少”分数):这就是 GAE 的作用!它是一种巧妙的方法,用于计算每个单词选择的优劣,考虑奖励和价值函数的预测。(关于 GAE 的更多内容见下文!)
-
优化 LLM(策略更新):我们更新 LLM 的策略,以最大化一个特殊的 PPO 目标函数。这个目标函数现在有三个关键部分:
-
鼓励更高奖励:它推动 LLM 生成能够获得更高分数的文本。
-
限制策略变化(剪切代理目标):它防止策略在一次更新中变化过大,确保稳定性。
-
KL 散度惩罚:如果新策略与旧策略偏离太远,它会增加惩罚,进一步增强稳定性。
-
熵奖励:它还包括一个熵奖励。简单来说,熵衡量 LLM 文本生成的“随机性”或“多样性”。增加熵奖励可以鼓励 LLM 更多地探索,而不是总是生成相同、可预测的响应。它有助于防止 LLM 过早变得“过于确定”,从而错过可能更好的策略。
- 更新价值函数(辅助教练更新):训练价值函数成为一个更好的“辅助教练”——更准确地预测不同文本生成的“好坏”。
为什么选择 GAE?
-
蒙特卡洛(MC)—— 高方差,低偏差:想象一下等到整个文本生成后再获得奖励,然后将该奖励分配给文本中的每一个单词。就像只有在小狗完成整个“坐下、待命、取回”动作序列后才给予奖励。对整个序列的奖励是准确的,但对单个动作(“坐下”与“待命”与“取回”)的信号非常嘈杂。高方差,学习速度慢。
-
时间差分(TD)—— 低方差,高偏差:想象一下在每个单词生成后给予奖励。“好单词!”“普通单词!”“很棒的单词!”信号不那么嘈杂,学习速度更快。但是,我们只是局部地判断单词,没有考虑整个文本的长期质量。可能会有偏差,可能会错过“大局”。
-
GAE —— 平衡:广义优势估计(GAE)就像“多步 TD”。它考虑了多个步骤(单词)上的奖励,平衡了方差(MC)与偏差(TD)之间的权衡。就像不仅在结束时给予奖励,还在价值函数预测的指导下,为沿途的“小步骤”给予奖励。
概念性 PPO —— Python 伪代码
# 这是一个高度简化的预期目标版本 def ppo_loss_with_gae_entropy(old_policy_logprobs, new_policy_logprobs, advantages, kl_penalty_coef, clip_epsilon, entropy_bonus_coef): """概念性 PPO 损失函数,带有 GAE 和熵奖励(简化版)。""" ratio = np.exp(new_policy_logprobs - old_policy_logprobs) # 概率比 # 剪切代理目标(限制策略变化) surrogate_objective = np.minimum(ratio * advantages, np.clip(ratio, 1 - clip_epsilon, 1 + clip_epsilon) * advantages) policy_loss = -np.mean(surrogate_objective) # KL 散度惩罚(保持接近旧策略) kl_divergence = np.mean(new_policy_logprobs - old_policy_logprobs) kl_penalty = kl_penalty_coef * kl_divergence # 熵奖励(鼓励探索) entropy = -np.mean(new_policy_logprobs) # 简化版熵(概率越高 = 熵越低,取负值以最大化熵) entropy_bonus = entropy_bonus_coef * entropy total_loss = policy_loss + kl_penalty - entropy_bonus # 减去熵奖励,因为我们希望*最大化*熵 return total_loss
3. 直接偏好优化(DPO)
DPO 是“新晋成员”——一种更简单、更高效的方式来进行偏好学习,跳过了 RL 的复杂性。
直截了当:DPO 就像是直接告诉 LLM:“响应 A 比响应 B 更好。多生成像 A 这样的响应,少生成像 B 这样的响应!”它省略了 RL 中用于策略优化的奖励模型这一中间环节。
DPO 避免了 PPO 的迭代 RL 循环。它直接基于人类偏好数据利用一个巧妙的损失函数对 LLM 进行优化。
DPO 训练流程
-
偏好数据仍然是关键:与 PPO 一样,DPO 仍然从相同的关键成分开始:人类偏好数据(成对的响应,带有标签,指示哪个响应更受青睐)。人类反馈仍然是基础!
-
直接策略更新(分类式损失——直接使用 logits!):这是 DPO 的魔法所在。DPO 使用一个特殊的损失函数直接比较两个模型的 logits(概率之前的原始输出分数):
-
增加首选响应的 logits(和概率):让当前模型在未来更有可能生成像响应 A 这样的响应。
-
减少非首选响应的 logits(和概率):让当前模型在未来更不可能生成像响应 B 这样的响应。
-
保持接近参考模型(隐式 KL 控制):损失函数还隐式地鼓励当前模型在行为上保持与参考模型的接近(使用参考模型的 logits),这有助于稳定性,类似于 PPO 的 KL 惩罚,但直接嵌入在损失函数中!
-
当前模型(正在训练中):我们将首选响应(响应 A)和非首选响应(响应 B)都输入到我们正在训练的当前 LLM 中,得到两者的 logits。
-
参考模型(旧版本):我们还将响应 A 和响应 B 输入到一个参考模型中。这通常是 LLM 的旧版本(比如我们开始时的 SFT 模型)。我们也会从参考模型中得到 logits。
-
DPO 的损失函数直接使用这两个模型的 logits 来计算损失,这与分类任务中使用的二元交叉熵损失非常相似。这个损失函数旨在:可以这样理解:DPO 的损失函数就像一个“偏好指南针”,直接根据首选和非首选响应的相对 logits 指导 LLM 的权重,而无需显式预测奖励。
DPO 损失函数
# 注意:这不是实际公式。 # 这是一个高度简化的预期目标版本 def dpo_loss(policy_logits_preferred, policy_logits_dispreferred, ref_logits_preferred, ref_logits_dispreferred, beta_kl): """概念性 DPO 损失函数(简化版——直接使用 logits)。""" # 1. 从 logits 中获取对数概率(当前和参考模型的首选和非首选响应) policy_logprob_preferred = F.log_softmax(policy_logits_preferred, dim=-1).gather(...) # 提取首选响应中实际标记的对数概率 policy_logprob_dispreferred = F.log_softmax(policy_logits_dispreferred, dim=-1).gather(...) # 提取非首选响应中实际标记的对数概率 ref_policy_logprob_preferred = F.log_softmax(ref_logits_preferred, dim=-1).gather(...) # 同样适用于参考模型 ref_policy_logprob_dispreferred = F.log_softmax(ref_logits_dispreferred, dim=-1).gather(...) # 2. 计算对数比率(使用对数概率——如前所述) log_ratio = policy_logprob_preferred - policy_logprob_dispreferred - (ref_policy_logprob_preferred - ref_policy_logprob_dispreferred) # 3. 偏好概率(Bradley-Terry 模型——隐式奖励信号) preference_prob = 1 / (1 + np.exp(-beta_kl * log_ratio)) # 4. 二元交叉熵损失(直接优化策略) dpo_loss = -np.log(preference_prob + 1e-8) return dpo_loss
4. 组相对策略优化(GRPO)
GRPO 是 DeepSeek AI 对 PPO 的一种聪明的改进,旨在更加高效,尤其是在复杂的推理任务中。
GRPO 就像是 PPO 的精简版表亲。它保留了 PPO 的核心思想,但去掉了独立的价值函数(辅助教练),使其更轻量、更快速。
GRPO 的魔法成分在于它如何估计优势。它不是使用辅助教练,而是使用一组由 LLM 生成的相同提示的响应来估计每个响应相对于组内其他响应的“好坏”。
GRPO 训练流程:
-
生成一组响应:对于每个提示,从 LLM 中生成多个响应的一组。
-
对组进行打分(奖励模型):获取组内所有响应的奖励分数。
-
计算组内相对优势(GRAE —— 组内比较):通过比较每个响应的奖励与组内平均奖励来计算优势。在组内对奖励进行归一化以得到优势。
-
优化策略(使用 GRAE 的 PPO 风格目标函数):使用一个 PPO 风格的目标函数更新 LLM 的策略,但使用这些组内相对优势。
概念性 GRPO 损失函数 —— Python 伪代码
# 注意:这不是实际公式。 # 这是一个高度简化的预期目标版本 def grae_advantages(rewards): """概念性组相对优势估计(结果监督)。""" mean_reward = np.mean(rewards) std_reward = np.std(rewards) normalized_rewards = (rewards - mean_reward) / (std_reward + 1e-8) advantages = normalized_rewards # 对于结果监督,优势 = 归一化奖励 return advantages def grpo_loss(old_policy_logprobs_group, new_policy_logprobs_group, group_advantages, kl_penalty_coef, clip_epsilon): """概念性 GRPO 损失函数(对一组响应取平均)。""" group_loss = 0 for i in range(len(group_advantages)): # 遍历组内的每个响应 advantage = group_advantages[i] new_policy_logprob = new_policy_logprobs_group[i] old_policy_logprob = old_policy_logprobs_group[i] ratio = np.exp(new_policy_logprob - old_policy_logprob) clipped_ratio = np.clip(ratio, 1 - clip_epsilon, 1 + clip_epsilon) surrogate_objective = np.minimum(ratio * advantage, clipped_ratio * advantage) policy_loss = -surrogate_objective kl_divergence = new_policy_logprob - old_policy_logprob kl_penalty = kl_penalty_coef * kl_divergence group_loss += (policy_loss + kl_penalty) # 累加组内每个响应的损失 return group_loss / len(group_advantages) # 对组内损失取平均
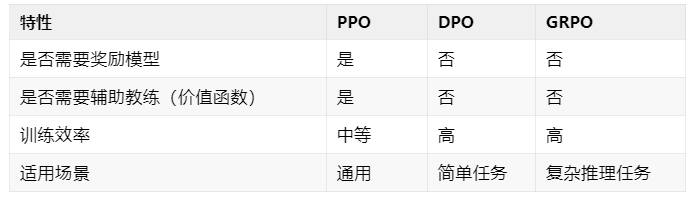
5. PPO vs. DPO vs. GRPO
让我们用表格总结一下它们的关键区别:
6. 通过链式思考和偏好学习解锁推理能力
我们已经讨论了 PPO、DPO 和 GRPO 如何帮助 LLM 学习生成人类更喜欢的文本。但对于复杂的任务,如数学问题、编程或逻辑推理,仅仅得到一个“首选”的最终答案是不够的。我们希望 LLM 也能正确推理,展示它的“思考过程”。
这就是链式思考(Chain-of-Thought, CoT)推理的作用!可以将其视为要求 LLM 在给出最终答案之前“展示它的解题步骤”。
链式思考 —— 逐步推理
LLM 使用 CoT 不是直接输出最终答案,而是生成一系列中间“思考”或推理步骤,最终得出答案。
示例:
提示:“如果一辆火车以 60 英里/小时的速度行驶 2 小时,它行驶了多远?”
使用链式思考的 LLM:
LLM 首先生成一个“思考链”(步骤 1-4),解释其推理过程,用 <thought> 标签括起来。然后在 <answer> 标签中给出最终答案。
<thought> 步骤 1:确定公式:距离 = 速度 × 时间 步骤 2:从问题中提取速度:速度 = 60 英里/小时 步骤 3:从问题中提取时间:时间 = 2 小时 步骤 4:计算距离:距离 = 60 英里/小时 × 2 小时 = 120 英里 </thought> <answer> 120 英里 </answer>
为什么 CoT 对推理很重要?
-
透明性:CoT 让 LLM 的推理过程更加透明和易于理解。我们可以看到它是如何得出答案的,而不仅仅是答案本身。
-
提高准确性:对于复杂问题,强迫 LLM 逐步推理通常会导致更准确的最终答案。这就像将一个难题分解为更小、更简单的步骤。
-
可调试性:如果 LLM 得出错误答案,CoT 可以帮助我们调试并理解它的推理过程在哪里出错了。
为良好的 CoT 提供奖励——奖励“思考过程”
那么,PPO、DPO 和 GRPO 如何与 CoT 结合呢?我们可以使用这些偏好学习算法,专门奖励 LLM 生成正确且有帮助的链式思考推理!
-
奖励正确的推理,而不仅仅是答案:我们可以设计奖励模型(或 DPO/GRPO 的偏好数据集),当 LLM 生成的思考链:
-
正确:推理步骤逻辑严谨且得出正确答案。
-
有帮助:推理步骤清晰、易于理解且很好地解释了解题过程。
CoT 的奖励信号示例:
假设我们有两个 LLM 对数学问题的输出:
-
输出 1(正确的 CoT):包含一个正确的思考链,得出正确答案。奖励:+0.9(高奖励)
-
输出 2(无 CoT 或错误的 CoT):要么只给出答案,要么推理过程有缺陷。奖励:+0.2(低奖励)
然后我们可以使用 PPO、DPO 或 GRPO 训练 LLM,生成更多像输出 1(有良好 CoT)的响应,减少像输出 2(没有良好 CoT)的响应。
解锁 LLM 的推理能力:通过偏好学习奖励良好的 CoT,我们本质上是在教 LLM 如何逐步思考。这是解锁它们全部推理潜力并使它们成为更可靠的解题者的关键一步。
7. 结论
我们已经探索了 LLM 的偏好学习世界,了解了 PPO、DPO 和 GRPO 这些强大的算法旨在使这些模型更有帮助、更合理且无害。我们看到了它们如何相互补充,每种方法都为将 AI 与人类价值观对齐这一挑战提供了独特的解决方案。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
大模型就业发展前景
根据脉脉发布的《2024年度人才迁徙报告》显示,AI相关岗位的需求在2024年就已经十分强劲,TOP20热招岗位中,有5个与AI相关。 字节、阿里等多个头部公司AI人才紧缺,包括算法工程师、人工智能工程师、推荐算法、大模型算法以及自然语言处理等。
字节、阿里等多个头部公司AI人才紧缺,包括算法工程师、人工智能工程师、推荐算法、大模型算法以及自然语言处理等。
除了上述技术岗外,AI也催生除了一系列高薪非技术类岗位,如AI产品经理、产品主管等,平均月薪也达到了5-6万左右。
AI正在改变各行各业,行动力强的人,早已吃到了第一波红利。
最后
大模型很多技术干货,都可以共享给你们,如果你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。


三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

在这里,我们一起交流AI,学习AI,用AI改变世界。如有AI产品需求,可访问讯飞开放平台,www.xfyun.cn。
更多推荐



 28
28 0
0- 0



 已为社区贡献107条内容
已为社区贡献107条内容

所有评论(0)