
大数据毕业设计Hadoop+Spark知识图谱电影推荐系统 电影用户画像系统 电影评论情感分析 电影爬虫 电影可视化 电影大数据 电影数据分析 机器学习 深度学习 人工智能 计算机毕业设计
大数据毕业设计Hadoop+Spark知识图谱电影推荐系统 电影用户画像系统 电影评论情感分析 电影爬虫 电影可视化 电影大数据 电影数据分析机器学习 深度学习 人工智能 计算机毕业设计
6.1 总结
本文从实际生活的应用出发,综合运用各类技术,设计并实现了基于Spark的电影推荐系统。在本次课题研究中,所做的工作总结有以下几点:
- 学习了许多推荐算法的原理;
- 学习了许多之前的未接触过的技术,如Spark计算框架、ElasticSearch搜索引擎、MongoDB数据库和Vue前端框架等;
- 详细分析了本系统的功能性需求和非功能性需求;
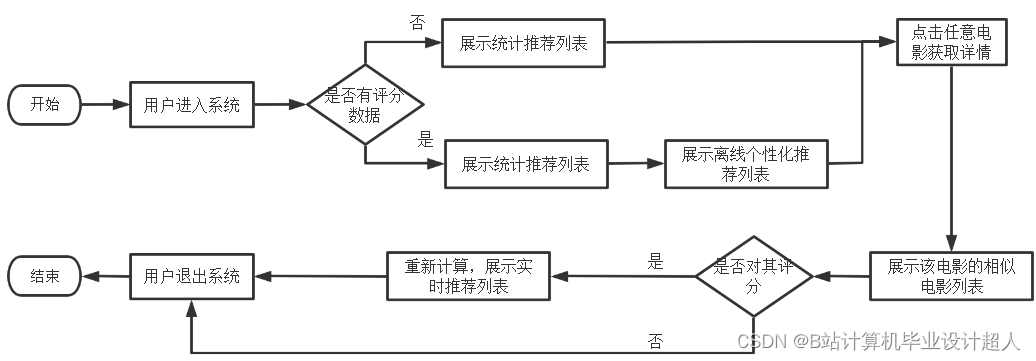
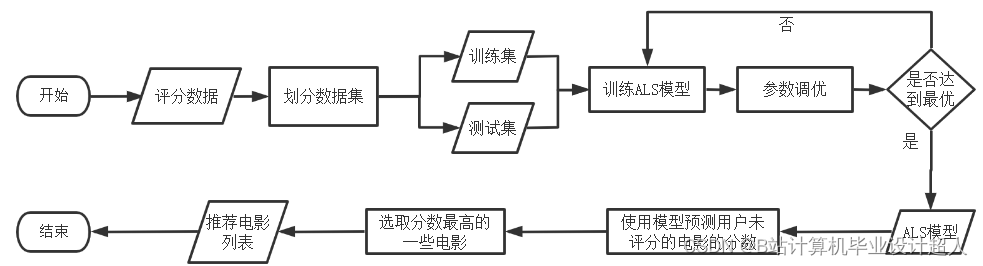
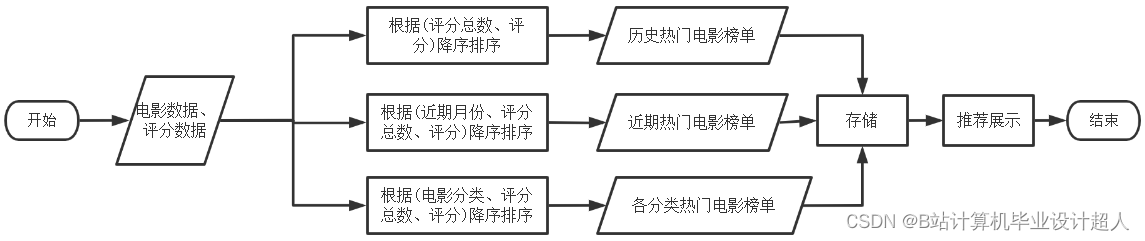
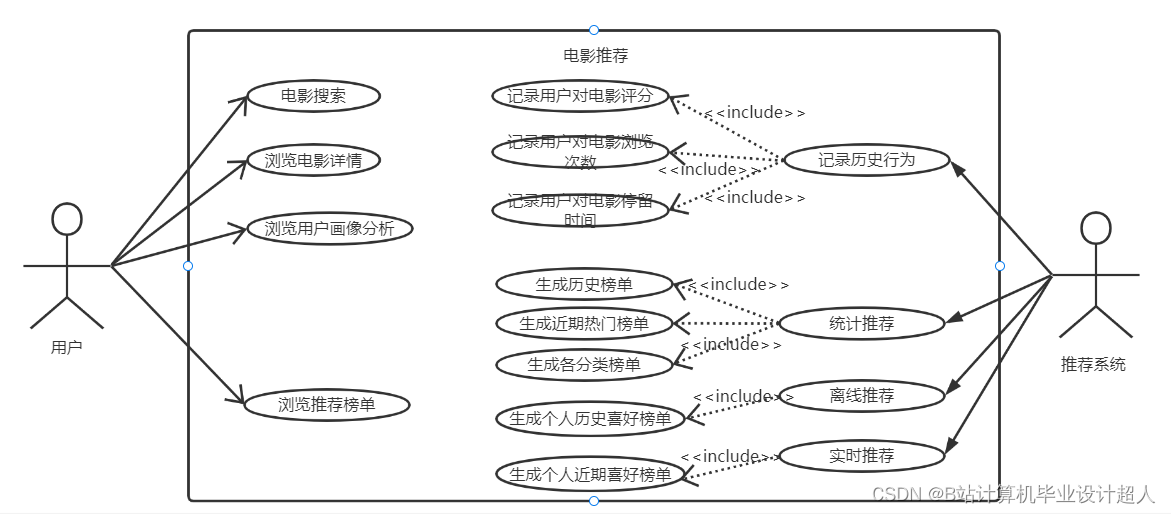
- 详细设计了本系统的架构与各个功能模块,详细设计了系统所需的几种推荐算法,如统计推荐、离线推荐和实时推荐算法,详细设计了数据库并给出了优化策略;
- 测试了推荐算法的误差,以及对系统进行了高并发的性能测试。
6.2 展望
虽然本文最终实现了基于Spark的电影推荐系统,但是仍还有进一步完善、优化和提升的空间。笔者提出以下两点优化意见:
- 搭建Spark集群
目前本系统还是单机模式,但是面对日益庞大的数据量,单机的计算能力就有点捉襟见肘了。当搭建了Spark集群,每台机器的计算和内存压力会减轻不少,大大提高了计算效率。
- 探索其它推荐算法
由于本系统中用户评分矩阵十分稀疏,会对推荐算法的准确性有一定的影响。在以后的学习中,还可以探索其他推荐算法,使本系统具有更高的准确性。
核心算法代码分享如下:
import scrapy
import re
from DouBanSpider.db_handler import connection, cursor
from DouBanSpider.items import IMDbRatings
class ImdbRatingsSpider(scrapy.Spider):
name = 'IMDb_ratings'
allowed_domains = ['imdb.com']
sql = "SELECT douban_id,imdb_url FROM movie_detail WHERE douban_id NOT IN (SELECT douban_id FROM imdb_ratings) AND imdb_url IS NOT NULL;"
cursor.execute(sql)
tuple_list = cursor.fetchall()
def start_requests(self):
for temp in self.tuple_list:
imdb_id = re.findall('XXXXX/title/(.*)', temp[1])[0]
douban_id = temp[0]
url = 'XXXXX/title/{}/ratings?ref_=tt_ql_op_4'.format(imdb_id)
item = IMDbRatings()
# 获取豆瓣id和IMDb id
item['douban_id'] = douban_id
item['imdb_id'] = imdb_id
# 这里后面可能会加Cookie
yield scrapy.Request(
url,
meta={'item': item, 'dont_redirect': True, 'handle_httpstatus_list': [302]},
dont_filter=True
)
def parse(self, response):
item = response.meta['item']
self.get_imdb_rating(item, response)
self.get_rating_scores(item, response)
self.get_rating_scores_weights(item, response)
self.get_rating_scores_votes(item, response)
self.get_age_ratings(item, response)
self.get_male_ratings(item, response)
self.get_female_ratings(item, response)
yield item
# 获取IMDb评分
def get_imdb_rating(self, item, response):
regx = '//div[@name="ir"]/span/text()'
data = response.xpath(regx).get()
if data is None:
data = '0.0'
item['imdb_rating'] = data
return item
# 获取IMDb评分分级列表
def get_rating_scores(self, item, response):
regx = '//*[@id="main"]/section/div/div[3]/div/table[1]//tr/td[1]/div/div/text()'
item['rating_scores'] = '|'.join(response.xpath(regx).getall())
return item
# 获取各级评分权重,|分割
def get_rating_scores_weights(self, item, response):
regx = '//*[@id="main"]/section/div/div[3]/div/table[1]//tr/td[2]//div[@class="topAligned"]/text()'
str_list = response.xpath(regx).getall()
data = []
for str in str_list:
str = str.strip()
data.append(str)
item['rating_scores_weights'] = '|'.join(data)
return item
# 获取各级评分票数,|分割
def get_rating_scores_votes(self, item, response):
regx = '//*[@id="main"]/section/div/div[3]/div/table[1]//tr/td[3]/div/div/text()'
votes_list = response.xpath(regx).getall()
data = []
for votes in votes_list:
data.append(votes.replace(',', ''))
item['rating_scores_votes'] = '|'.join(data)
return item
# 获取各年龄段评分情况,评分|投票数
def get_age_ratings(self, item, response):
for i in range(2, 7):
regx_score = '//*[@id="main"]/section/div/div[3]/div/table[2]//tr[2]/td[{}]/div[1]/text()'.format(i)
regx_votes = '//*[@id="main"]/section/div/div[3]/div/table[2]//tr[2]/td[{}]/div[2]/a/text()'.format(i)
score = response.xpath(regx_score).get()
votes = response.xpath(regx_votes).get()
if score is None or score == '-':
score = '0'
votes = '0'
else:
votes = votes.strip().replace(',', '')
if i == 2:
item['age_all'] = score + '|' + votes
elif i == 3:
item['age_less_than_18'] = score + '|' + votes
elif i == 4:
item['age_18_29'] = score + '|' + votes
elif i == 5:
item['age_30_44'] = score + '|' + votes
elif i == 6:
item['age_more_than_45'] = score + '|' + votes
return item
# 获取男性投票数
def get_male_ratings(self, item, response):
regx_score = '//*[@id="main"]/section/div/div[3]/div/table[2]//tr[3]/td[2]/div[1]/text()'
regx_votes = '//*[@id="main"]/section/div/div[3]/div/table[2]//tr[3]/td[2]/div[2]/a/text()'
score = response.xpath(regx_score).get()
votes = response.xpath(regx_votes).get()
if score is None or score == '-':
score = '0'
votes = '0'
else:
votes = votes.strip().replace(',', '')
item['male_ratings'] = score + '|' + votes
return item
# 获取女性投票数
def get_female_ratings(self, item, response):
regx_score = '//*[@id="main"]/section/div/div[3]/div/table[2]//tr[4]/td[2]/div[1]/text()'
regx_votes = '//*[@id="main"]/section/div/div[3]/div/table[2]//tr[4]/td[2]/div[2]/a/text()'
score = response.xpath(regx_score).get()
votes = response.xpath(regx_votes).get()
if score is None or score == '-':
score = '0'
votes = '0'
else:
votes = votes.strip().replace(',', '')
item['female_ratings'] = score + '|' + votes
return item

1.1 虚拟机
本项目所用到的所有技术框架及项目包都已部署到虚拟机中(模拟为服务器)。
所用虚拟机软件为VMware Workstation 15.5 Pro,若没有此虚拟机软件,请联系我下载。
1.1.1 内部配置
|
IP地址 |
192.168.126.66 |
|
主机名 |
cloud01 |
|
内存容量 |
5G |
|
硬盘容量 |
40G |
|
用户1及密码 |
用户名:root 密码:000000 |
|
用户2及密码 |
用户名:es-admin 密码:1q1w1e1r (仅用于开关ElasticSearch) |
|
所有的技术框架位置 |
/opt/module/ |
|
项目部署位置 |
/opt/module/movie_recommendation_system/ |
1.2 相关技术配置
1.2.1 MySQL
|
账号 |
密码 |
端口 |
数据库 |
|
root |
000000 |
3306 |
movie_recommendation |
1.2.2 Redis
|
Host |
Port |
密码 |
|
192.168.126.66 |
6379 |
000000 |
1.2.3 MongoDB
|
User |
密码 |
端口 |
数据库 |
|
Designer |
000000 |
27017 |
recommender |
1.2.4 ElasticSearch
|
Username |
密码 |
端口 |
Index |
|
elastic |
000000 |
9200 |
Movie_detail |

在这里,我们一起交流AI,学习AI,用AI改变世界。如有AI产品需求,可访问讯飞开放平台,www.xfyun.cn。
更多推荐



 8
8 0
0- 0



 已为社区贡献189条内容
已为社区贡献189条内容

所有评论(0)