
AI 人工智能 生成式AI生命周期模式
然后,将细分群体或细分市场中的前几名客户的数据发送到LLM进行生成式AI步骤,该步骤将生成个性化的营销社交媒体帖子或电子邮件,向这些客户群体发送个性化的联系信息,提高他们对这些个性化信息的响应机会。选择模型,提示它,获得响应,评估响应,重新提示,直到累积的响应给您想要的结果,如产品描述、特定格式的摘要、可运行的SQL语句、生成的Python代码等。但这些链并非一次性完成,它们本质上是实验,因此我们
在本文中,我们将探讨在采用生成式人工智能(Generative AI)的旅程中,如何扩大企业规模和生产规模的可选路径。我们如何将应用从研究原型扩展到生产?考虑将这些模式作为成熟的开发过程,以实现企业规模的生产。
我们将探讨一些通常结合使用的非详尽的技术列表,这些技术用于处理您在企业级采用生成式人工智能时遇到的常见问题和挑战。
您可以将此作为采用生成式人工智能的生产规模企业在企业或工业环境中的模式清单。此外,您还可以通过了解克服在采用过程中常见的挑战所需的许多技能来为您的企业做好准备。
本质上,机器学习是关于创建或选择模型,查看它在一些数据上的表现,尝试预测或生成下游任务的过程。但这个过程是非常实验性的、迭代性的;就像使用反向传播来收敛更好的权重集以降低下游任务的损失函数的机器学习算法本身一样。
迭代和周期。Langchain是一个非常流行和有用的库,可帮助创建生成式人工智能的任务链。但这些链并非一次性完成,它们本质上是实验,因此我们必须为自己、我们的团队和我们的企业准备好周期的这些任务链,并在这些任务链的周期中对实验进行迭代。
让我们探索一些在上下文中经常遇到的问题的解决方案:模式。在这里涵盖的模式更多是迭代模式或周期模式:任务链中的迭代或“周期”。例如,从提示大型语言模型(LLM)获得完成或“得到答案”的任务链。重要的是我们要建立周期并评估结果并进行迭代。我将其设置为一系列越来越成熟的采用更复杂和复杂的策略和模式来完成任务的示例。
下面是一张图表,其中包含了我们在本文中讨论的所有周期和迭代。请将其用作可能的艺术的指示性参考,并根据您特定企业的需要进行调整/添加。
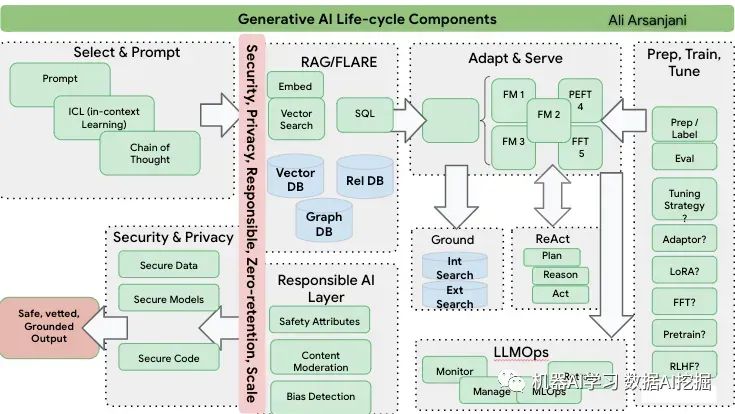
它们集体代表了更复杂或更成熟的处理企业级生成式人工智能复杂性的方法和方式。
每个随后的“周期”包括:prompt → FM → completion(提示→ 调优模型 → 完成)扩展为:prompt → Tuned Model → Completion(提示 → 调优模型 → 完成)prompt → RAG | FLARE → Model → Completion(提示 → 随机森林/稀疏表示 → 模型 → 完成)prompt → Model → Completion → Grounding(提示 → 模型 → 完成 → 落地)prompt → ToT → Model → ToT → Completion steps(提示 → 任务树 → 模型 → 任务树 → 完成步骤)
让我们以一个简单的例子开始:
提示 - -> 基础模型 - -> 适应 - -> 完成(“翻译为法语”)(初始翻译)(验证)(“你好,你好吗?”)
成熟度1:提示、上下文学习和链接。
提示它并文本上下文学习(Textual In-Context Learning,简称ICL)。选择模型,提示它,获得响应,评估响应,重新提示,直到累积的响应给您想要的结果,如产品描述、特定格式的摘要、可运行的SQL语句、生成的Python代码等。
上下文学习是一种提示工程方法,允许语言模型从几个示例中学习任务。在这种方法中,模型被给予带有自然语言任务示例的提示。模型学会在不改变其权重的情况下解决问题。ICL已经成为NLP的新范式。
ICL的目标与少样本学习非常相似:使模型能够在不需要大量调整的情况下学习上下文数据。然而,微调一个模型需要在目标数据集上进行监督学习设置。在ICL中,模型被提示一系列输入-标签对,而不需要更新模型参数。
经验表明,通过ICL,大型语言模型可以执行各种复杂的任务,甚至像解决数学推理问题一样复杂[1]。
除了基本的提示 → FM → 适应 → 完成模式外,通常需要从某个地方提取数据,可能运行一个预测性的人工智能算法,然后将结果发送到一个生成式人工智能基础模型。这个任务链(CoTA,与思维链不同)模式的示例如下:
Chain:提取数据/分析 → 运行预测性[一组]机器学习模型 → 将结果发送到LLM → 生成输出
示例:市场营销激活。首先,使用BigQuery运行一条SQL语句,获取营销活动中希望接触的客户群体。接下来,运行一个预测性的人工智能排名算法,获取细分群体中的前n名客户或前一组微观细分群体。然后,将细分群体或细分市场中的前几名客户的数据发送到LLM进行生成式AI步骤,该步骤将生成个性化的营销社交媒体帖子或电子邮件,向这些客户群体发送个性化的联系信息,提高他们对这些个性化信息的响应机会。
你可以使用像LangChain这样的库来完成这个任务链的大部分工作。LangChain包括模型、链和代理。
模型。LangChain支持各种LLM,包括Google Vertex AI、OpenAI和Hugging Face模型。链。链是LangChain可以在文本或其他数据上执行的一系列操作。链可以用于执行文本分析、摘要和翻译等任务。代理。代理是使用LLM做出决策并采取行动的程序。代理可以用于构建应用程序,如聊天机器人和代码分析工具。
LangChain还提供了与其他工具和API的集成,以及完成工作流所需的端到端任务链。例如:
与其他工具的集成:LangChain可以与其他工具集成,如Google搜索和Python REPL,以扩展其功能。常见应用的端到端任务链:LangChain提供了预构建的任务链,用于常见的应用,如文档分析和摘要。LangChain代理特别强大,因为它们可以使用LLM以动态和数据驱动的方式做出决策并采取行动。例如,LangChain代理可以用于构建能够从与用户交互中学习和提高性能的聊天机器人。
LangChain可用于各种用例。例如:
文档分析和摘要:LangChain可用于分析并汇总文档,如法律文件或科学论文。聊天机器人:LangChain可用于构建能够以自然和信息丰富的方式与用户互动的聊天机器人。代码分析:LangChain可用于分析代码并识别潜在的错误或安全漏洞。总体而言,LangChain是一个强大的框架,可用于使用LLM构建各种应用程序。它特别适合于构建动态和数据响应能力强的应用程序。
LangChain代理使用LLM来决定采取哪些行动以及按什么顺序采取它们。他们通过观察先前行动的结果来做出未来的决策。这使得LangChain代理能够随着时间的推移学习和适应,在完成任务方面变得更加有效。
LangChain代理可用于构建各种应用程序,如聊天机器人、代码分析工具和客户服务助理。它们特别适用于需要推理、计划和决策的任务。
成熟度等级2。上述部分是在迭代循环中使用的非常典型的一组模式,用于利用生成式人工智能。现在让我们来探索一个更成熟的级别,以增强上述内容。
微调在评估模型的响应后,即使经过大量的提示工程和上下文学习尝试,您仍然发现它不满足需求。在这种情况下,您可能需要调整基础模型:将其适应于某个领域、行业、输出格式类型或特定的简洁性与冗长性输出之间的平衡(例如,在一组症状的分类中)。
参数高效的微调(PEFT)是一种对LLM进行微调的技术,与传统的微调相比计算成本较低。PEFT通过仅微调LLM参数的子集来工作。这可以通过使用所谓的适配器调整技术或使用所谓的LoRA(大型语言模型的低秩适应性)来实现。
适配器调整涉及向LLM添加一个新层,该层特定于手头的任务。新层在小标签示例数据集上进行训练。这使得LLM能够在不必微调所有参数的情况下学习任务的具体特征。
LoRA涉及用低秩矩阵近似LLM的参数。这可以通过使用矩阵分解技术来实现。然后,将低秩矩阵在小标签示例数据集上进行微调。这使得LLM能够在不必微调所有参数的情况下学习任务的具体特征。
传统的做法是对LLM进行全面微调。在全面微调中,将对LLM的所有参数进行微调,使用大标签示例数据集。这可能会计算成本较高,但它可以导致目标任务上的最佳性能。
使用人类反馈的强化学习(RLHF)可以进一步增强微调。关于第二部分的更多信息。
成熟度等级3。现在让我们在发送提示之前检索数据,并对输入进行更多的上下文化处理,以降低LLM产生幻觉的可能性。
成熟度等级4。现在我们进入了一个非常有趣的领域,你可以开始指导你的LLM如何推理以及完成任务的步骤。
在这个级别上,你可以尝试以下方法:
提供指导和示例:通过向模型提供指导和示例,你可以告诉它如何解决问题或完成特定任务。例如,如果你有一个关于自然语言处理的问题,你可以向模型展示相关的代码片段或算法描述,并要求它生成类似的解决方案。
逐步引导:与模型进行交互时,你可以逐步引导它完成任务。首先,提出一个简单的问题或任务,然后根据模型的回答逐步添加更复杂的细节和要求。这样可以帮助模型更好地理解你的需求,并提供更准确的答案。
检查和验证:在模型给出答案后,你可以检查和验证它的回答是否符合预期。这可以通过比较模型的回答与你的预期结果或使用其他可靠来源的信息来完成。如果模型的回答不符合预期,你可以尝试提供更多的上下文信息或重新定义问题,以帮助模型更好地理解你的意图。
迭代和改进:通过反复与模型交互并观察其表现,你可以不断改进和优化你的指导策略。了解模型在不同情况下的表现和响应模式,可以帮助你更好地理解其工作原理,并提供更有效的指导。
需要注意的是,随着你对模型的指导程度的增加,它的输出可能会变得更加准确和有用。然而,也要注意不要过度干预模型的工作,以免限制其创造性和自主性。

在这里,我们一起交流AI,学习AI,用AI改变世界。如有AI产品需求,可访问讯飞开放平台,www.xfyun.cn。
更多推荐



 0
0 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)