
大数据毕业设计Python+Spark知识图谱医生推荐系统 医生门诊预测系统 医生数据分析 医生可视化 医疗数据分析 医生爬虫 机器学习 计算机毕业设计 知识图谱 深度学习 人工智能 数据可视化
大数据毕业设计Python+Spark知识图谱医生推荐系统 医生门诊预测系统 医生数据分析 医生可视化 医疗数据分析 医生爬虫机器学习 计算机毕业设计 知识图谱 深度学习 人工智能 数据可视化
·
1. 项目背景
随着互联网和人工智能技术的不断发展,医疗领域也迎来了数字化转型的时代。医生推荐系统作为医疗信息化和智能化的重要组成部分,可以帮助患者更快速、更准确地找到适合自己需求的医生,提升医疗服务的效率和质量。本项目旨在设计和开发一款基于用户需求和医生特长的医生推荐系统,为患者提供个性化的医生推荐服务。
2. 项目目标
本项目旨在构建一个医生推荐系统,实现以下目标:
- 根据患者的病情、就诊目的、地理位置等因素,为其推荐适合的医生或医疗机构。
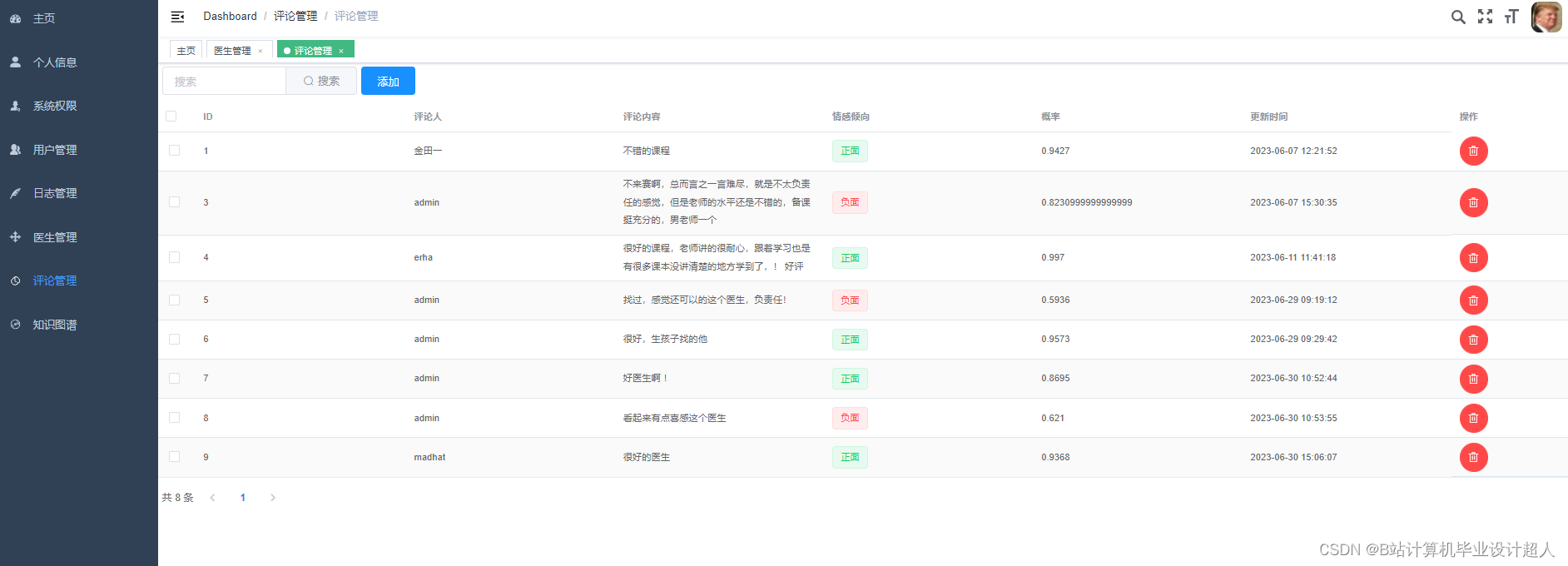
- 结合医生的专业领域、经验、患者评价等因素,为患者提供个性化的医生推荐。
- 提升医疗资源利用效率,降低患者就医成本,提高就医体验。
3. 项目内容与方法
3.1 数据收集与处理
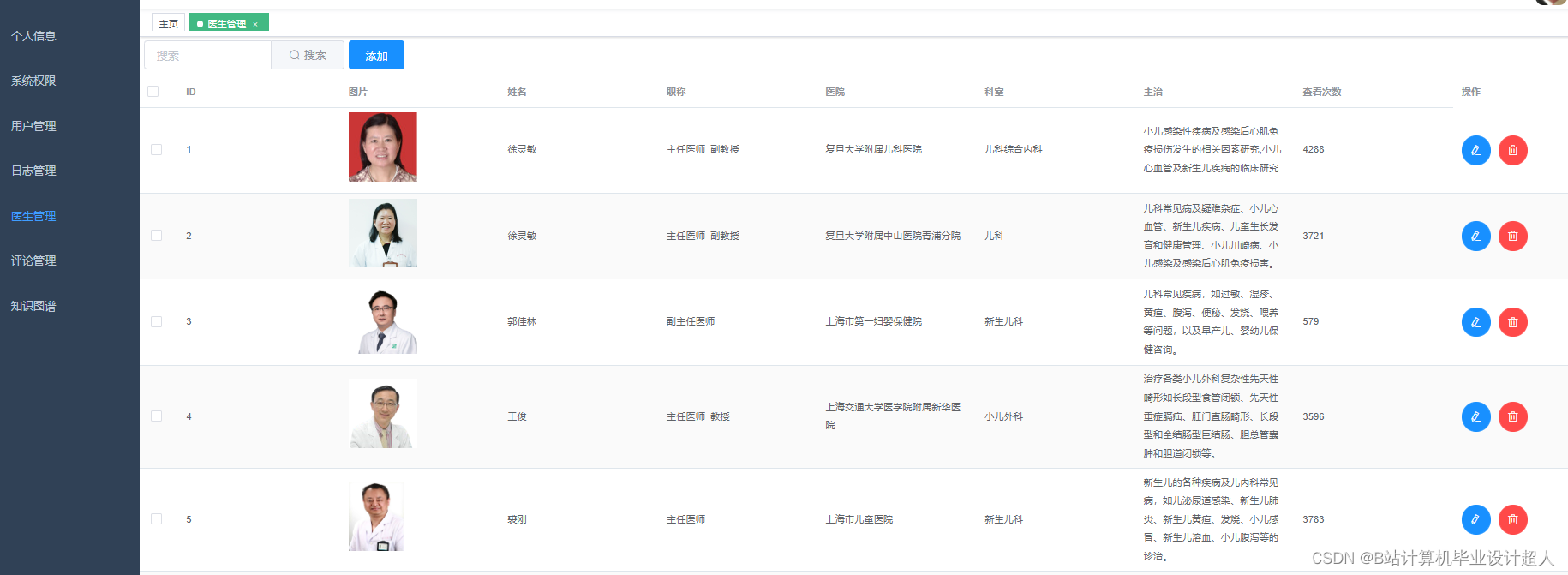
- 收集医院、医生、患者评价等数据,包括但不限于医生擅长领域、就诊时间、患者评价、地理位置等信息。
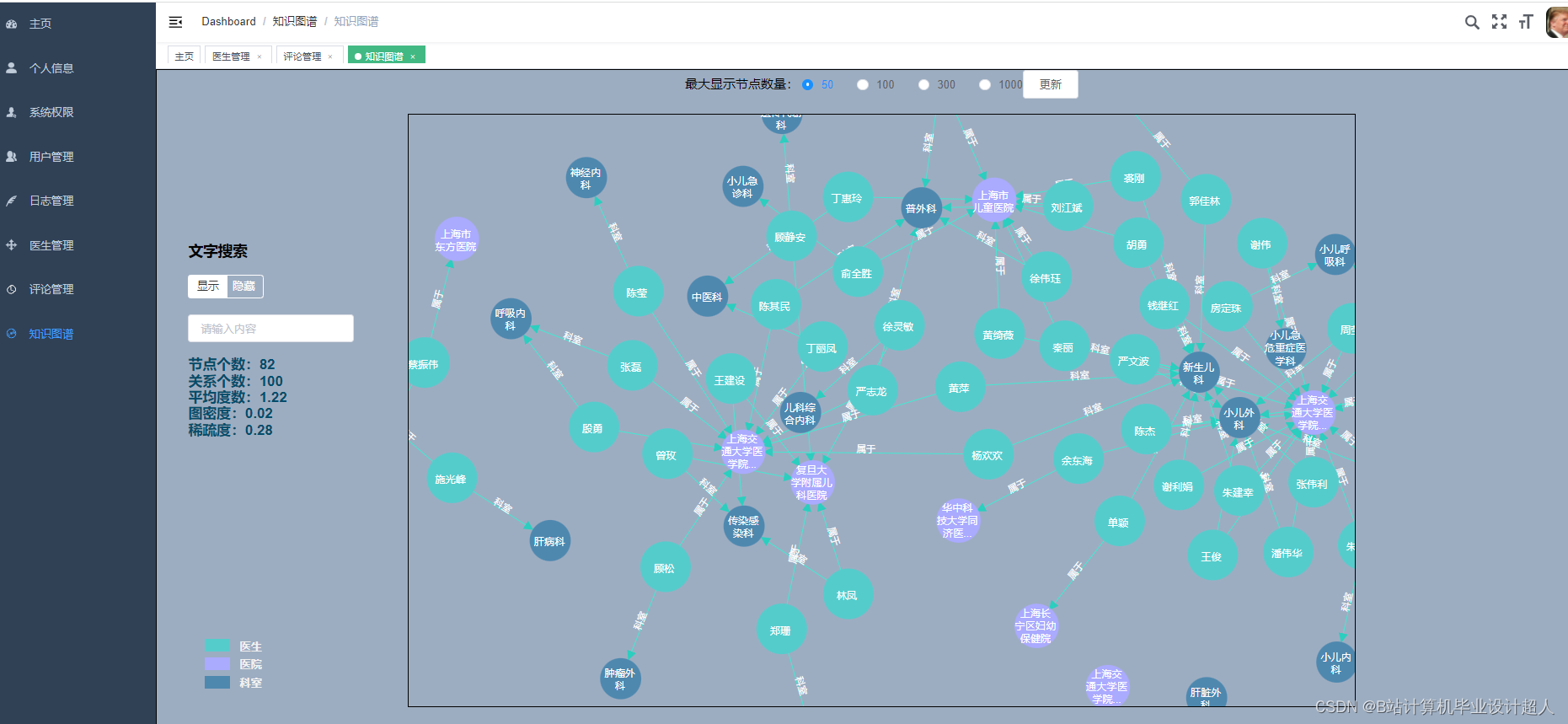
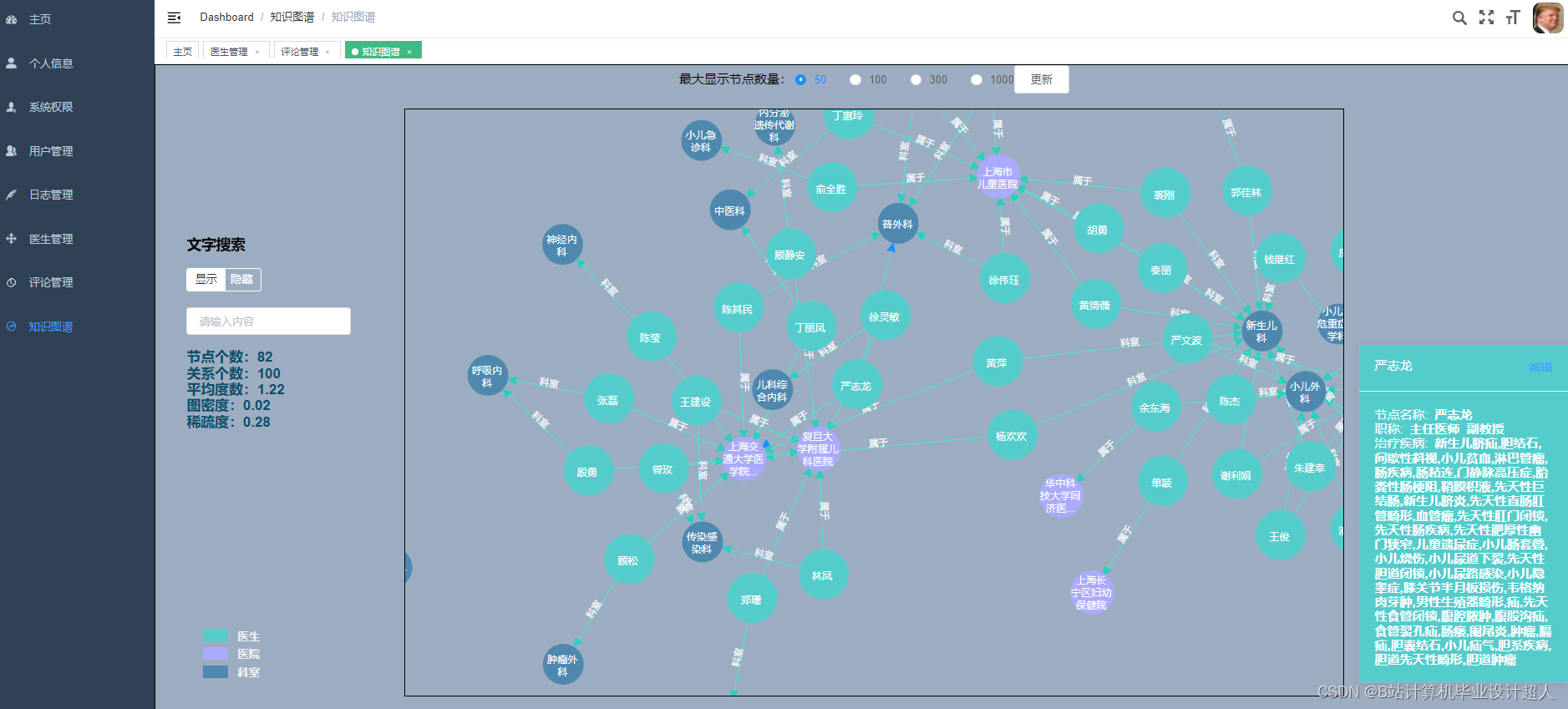
- 对数据进行清洗、整合和标准化处理,构建医生推荐系统所需的数据集。
3.2 模型设计与实现
- 基于用户需求和医生特长,设计合适的推荐算法,如基于内容的推荐、协同过滤推荐等。
- 开发医生推荐系统的后端服务,实现患者搜索、医生推荐、信息展示等功能。
3.3 系统评估与优化
- 对推荐系统进行评估,包括准确度、召回率、覆盖率、用户满意度等指标。
- 根据评估结果对系统进行优化,改进推荐算法和用户体验。
4. 预期成果
- 实现一个基于用户需求和医生特长的医生推荐系统原型,具备基本的医生推荐功能。
- 完成系统的搭建与测试,并对系统进行初步的用户体验评估。
- 撰写相关技术文档和用户手册,为系统的实际应用做好准备。
5. 可行性分析
- 技术可行性:当前已有成熟的推荐算法和技术框架可供选择,系统开发技术上存在较高的可行性。
- 经济可行性:医生推荐系统的应用前景广阔,具有较高的经济可行性。
- 法律合规性:在数据采集和隐私保护方面需合理遵守相关的法律法规,确保系统的合法合规运行。
6. 预期进度安排
- 第一阶段:数据收集与处理,预计耗时2个月。
- 第二阶段:模型设计与实现,预计耗时3个月。
- 第三阶段:系统评估与优化,预计耗时1个月。
- 第四阶段:编写文档与用户手册,预计耗时1个月。
7. 预期投入和产出
- 预期投入:系统开发团队、数据采集与处理成本、系统测试成本等。
- 预期产出:医生推荐系统原型、相关技术文档和用户手册、系统运营和推广计划。
以上是医生推荐系统开题报告的简要内容,后续将根据实际情况进行详细的研究和开发。
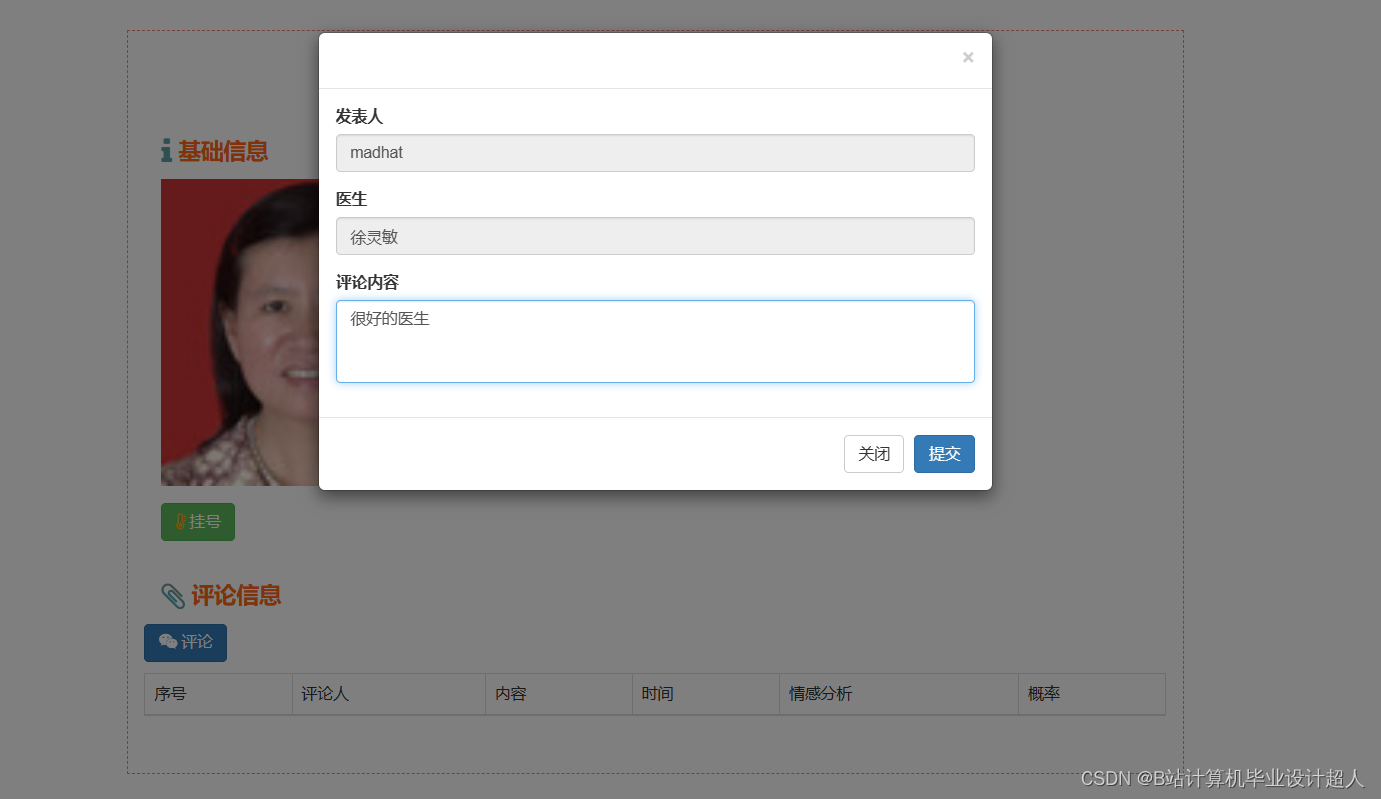
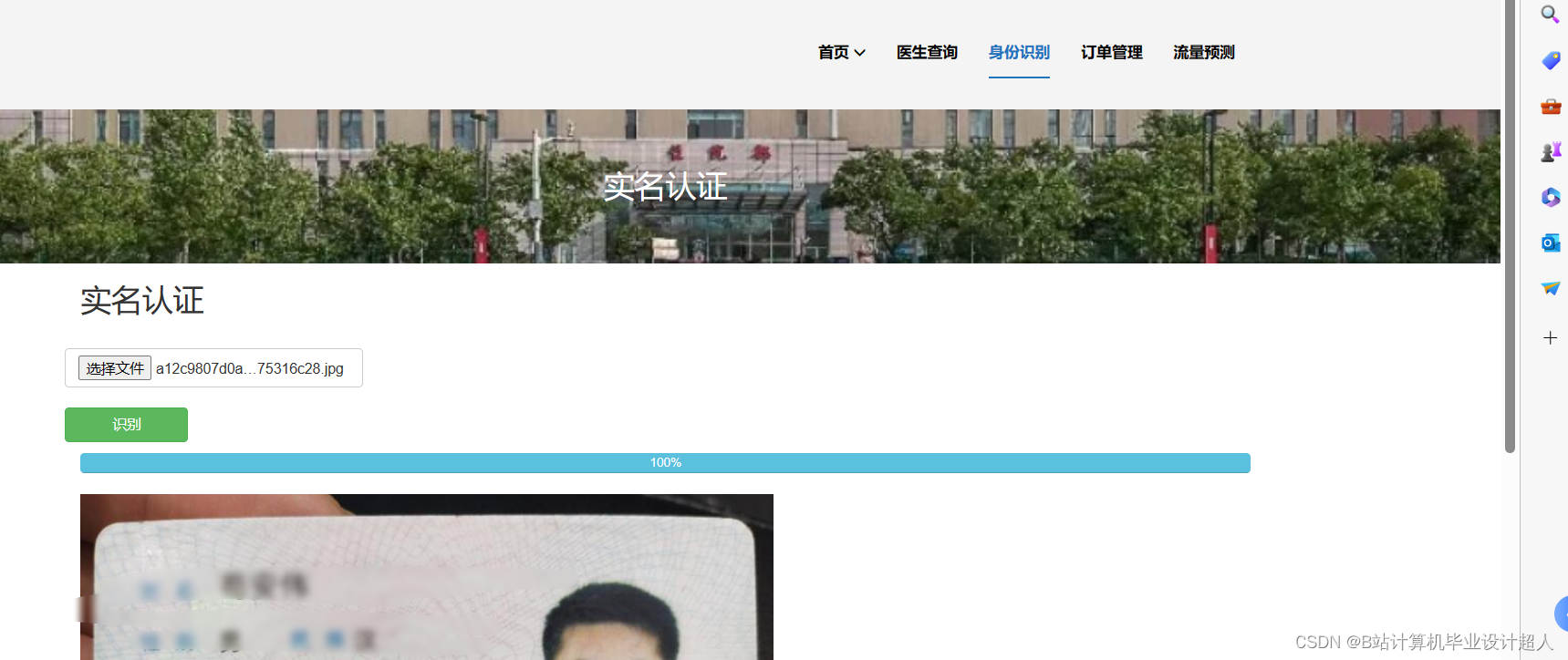
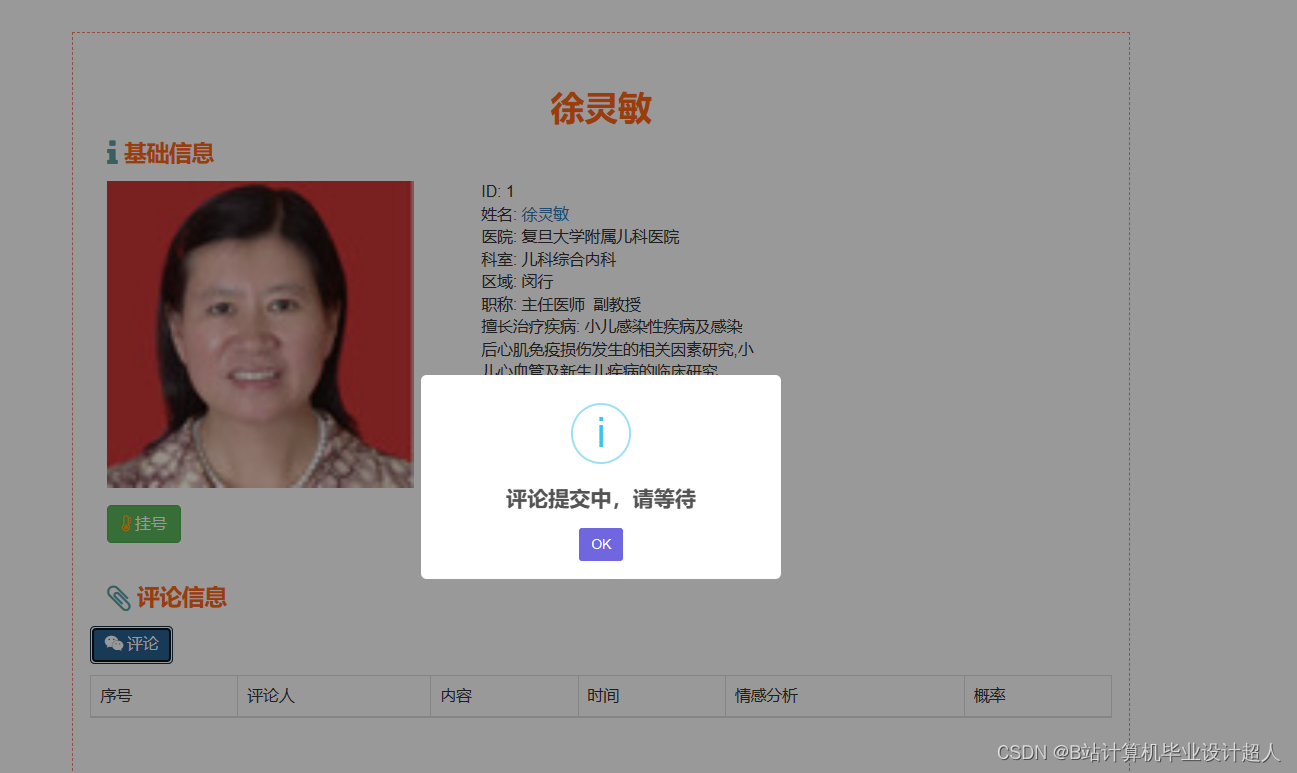

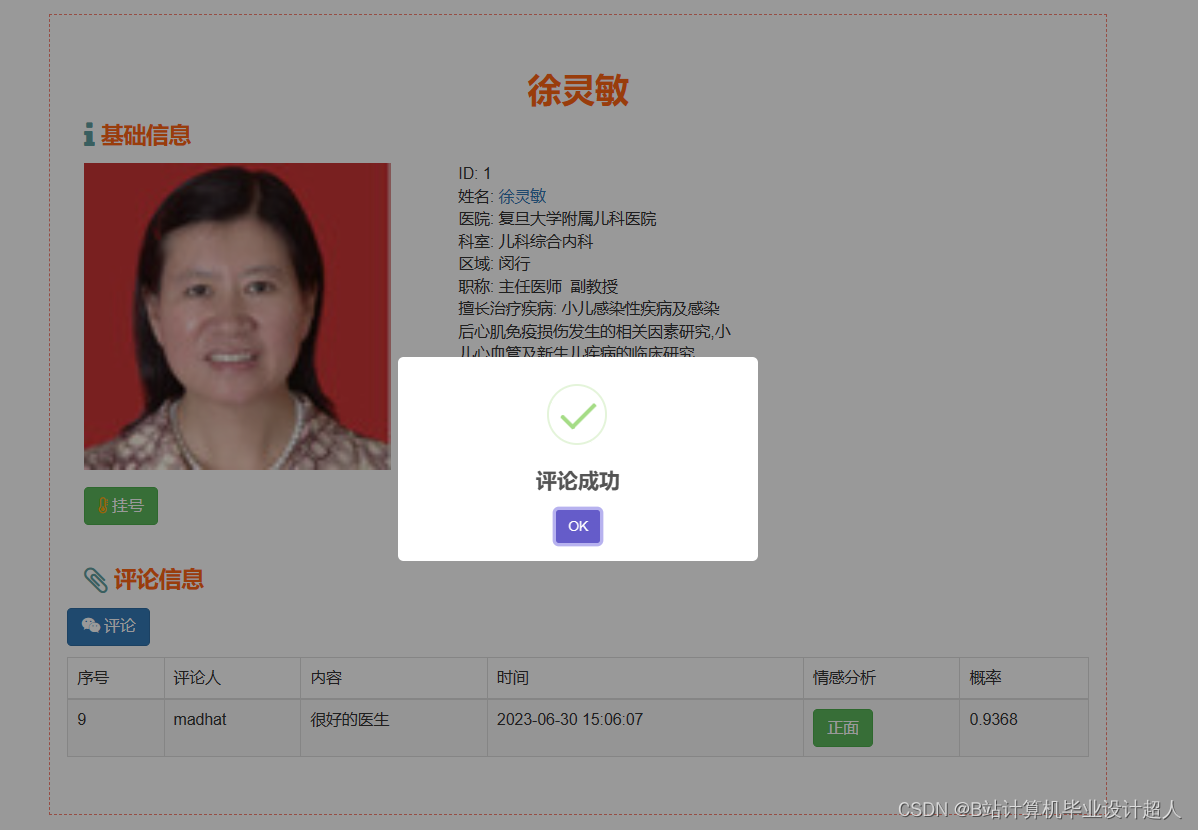
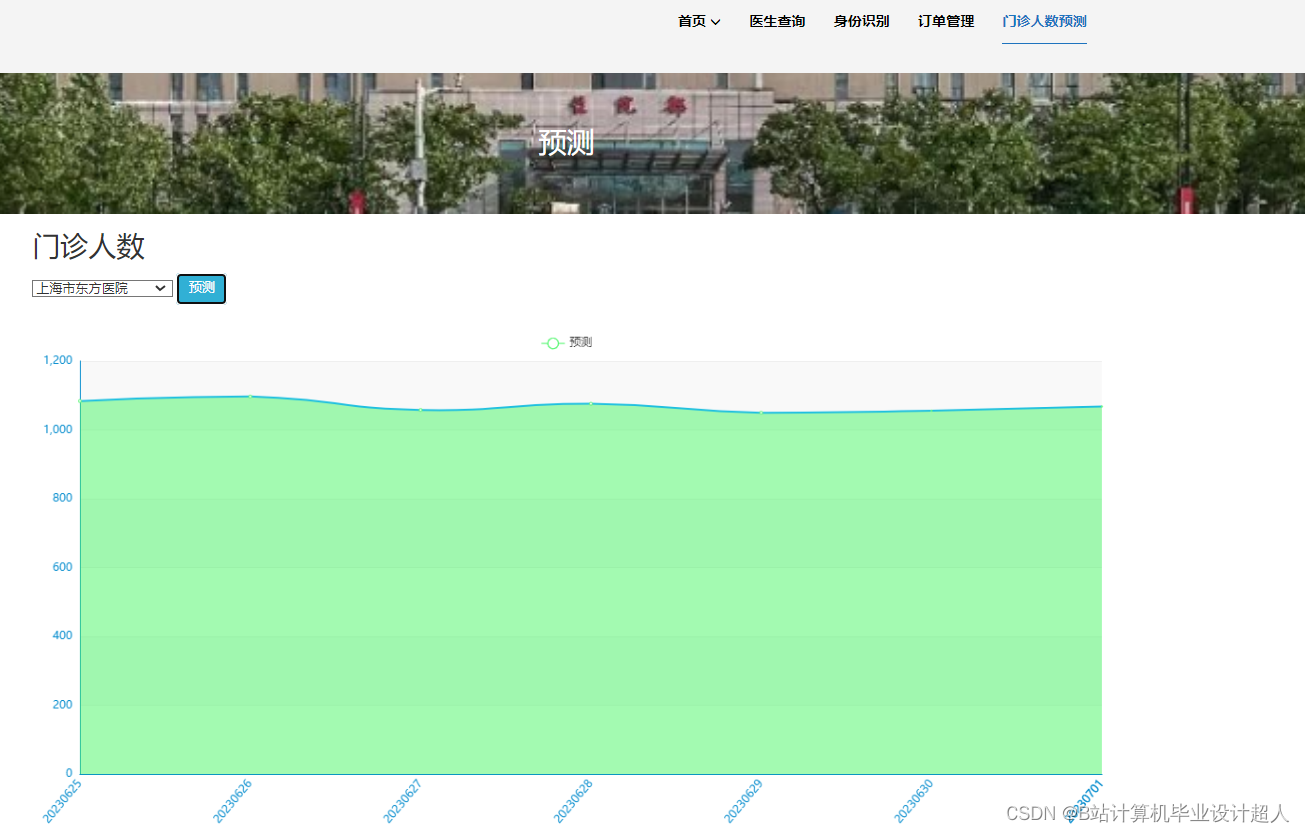
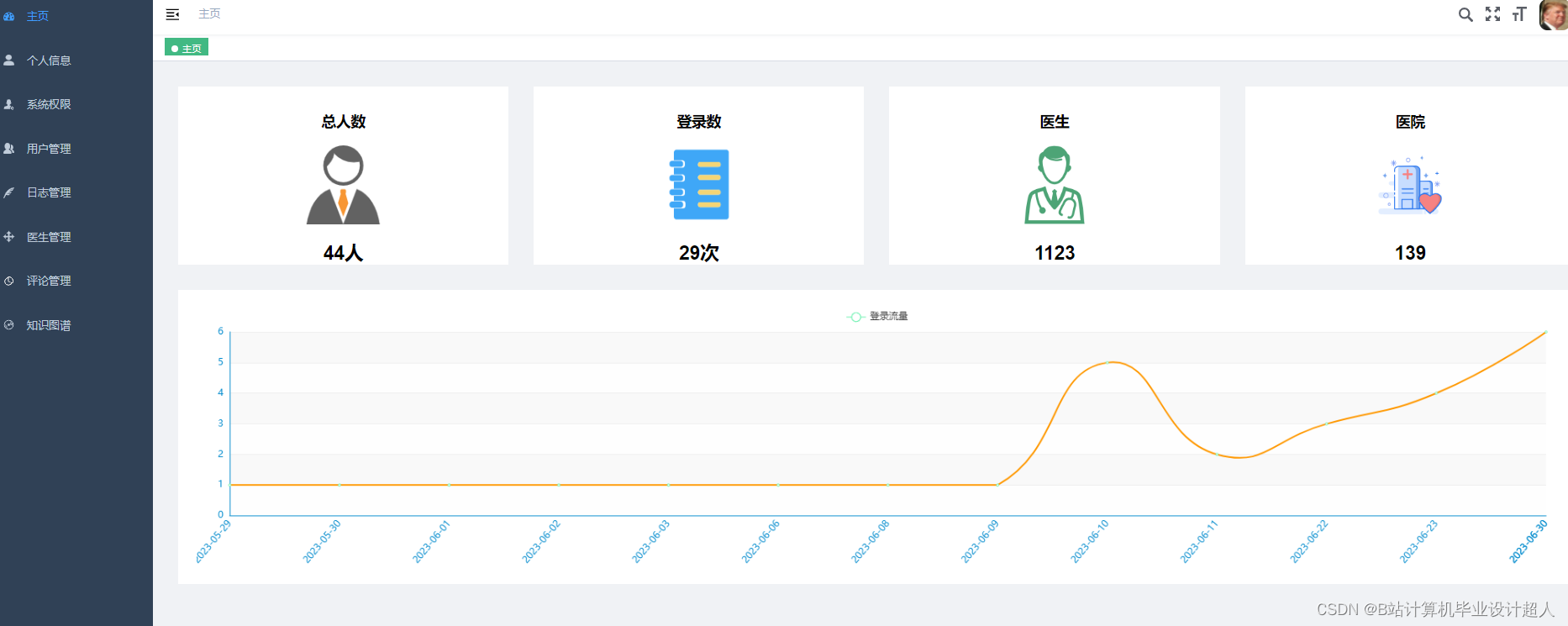
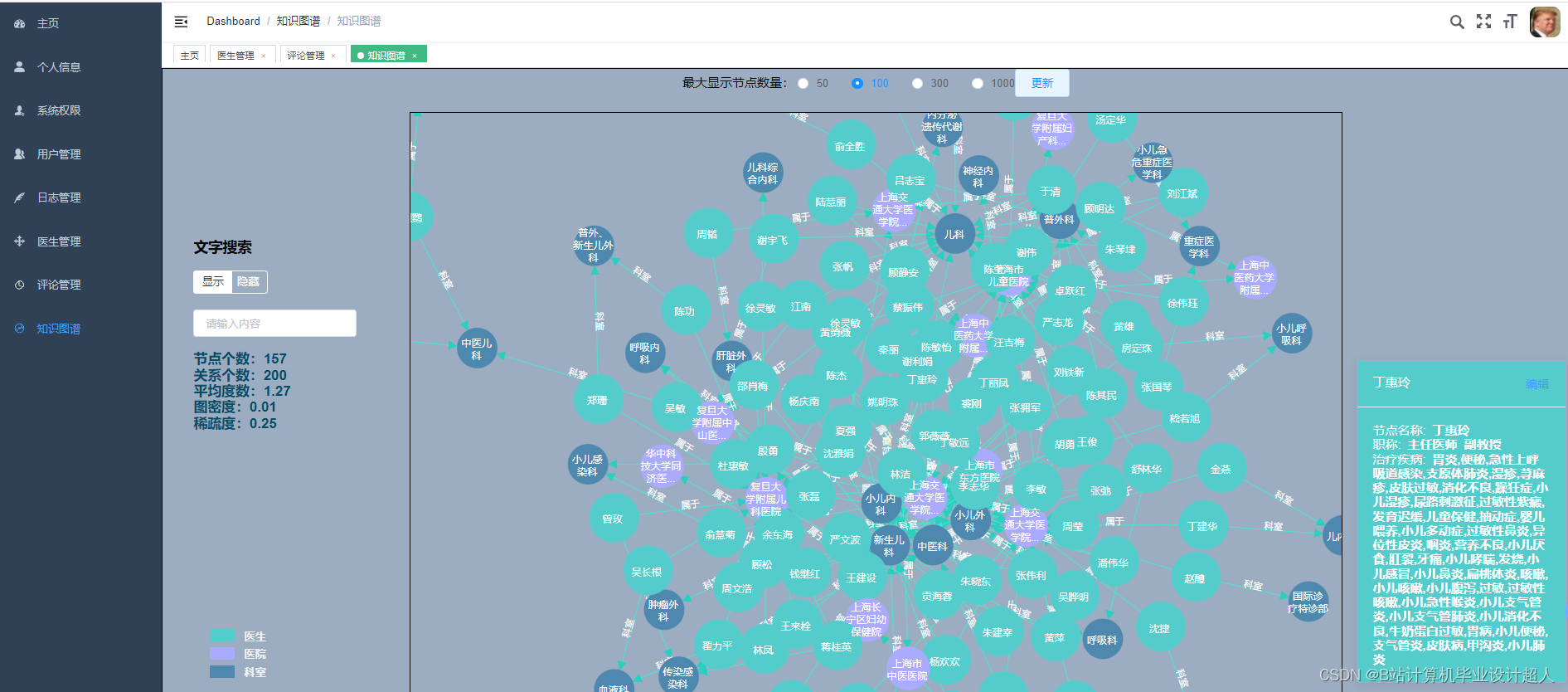
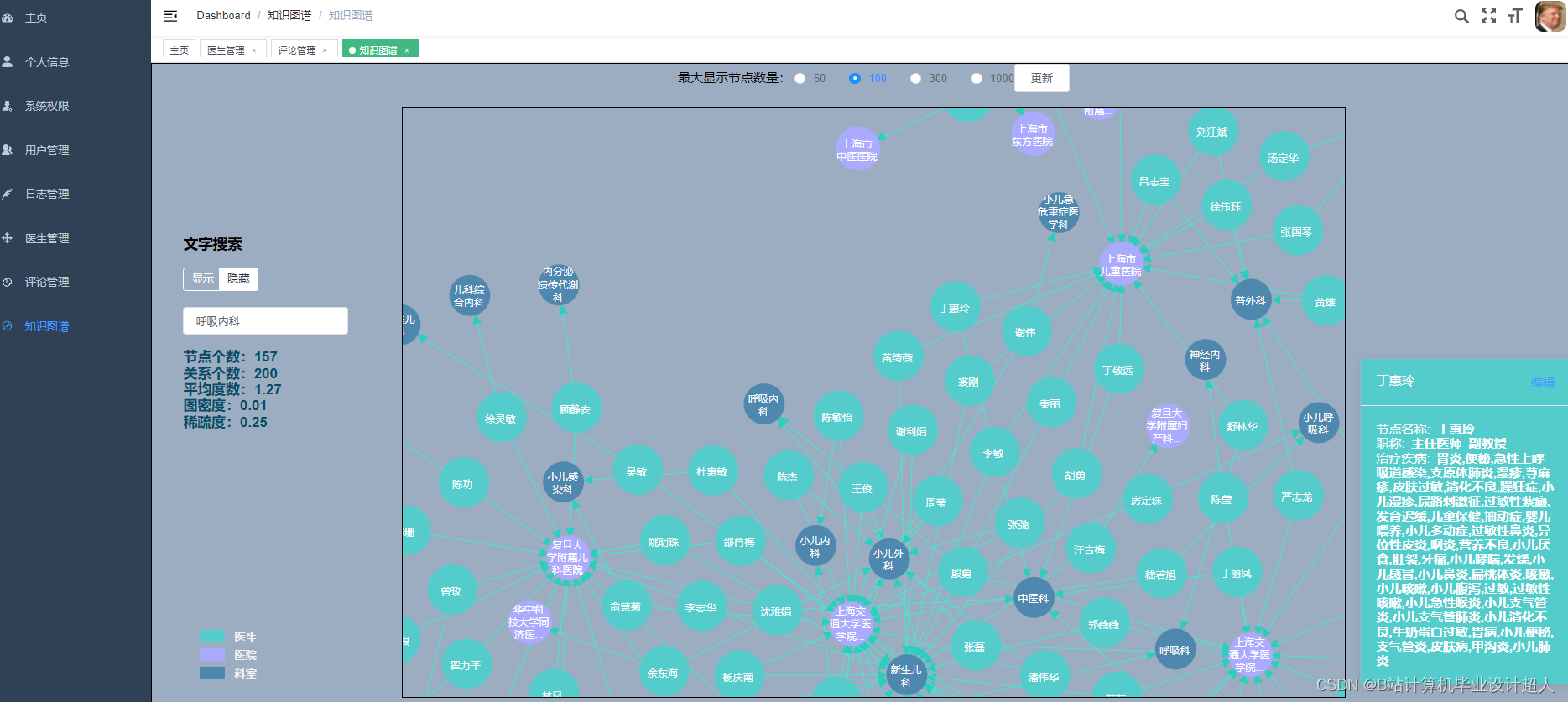
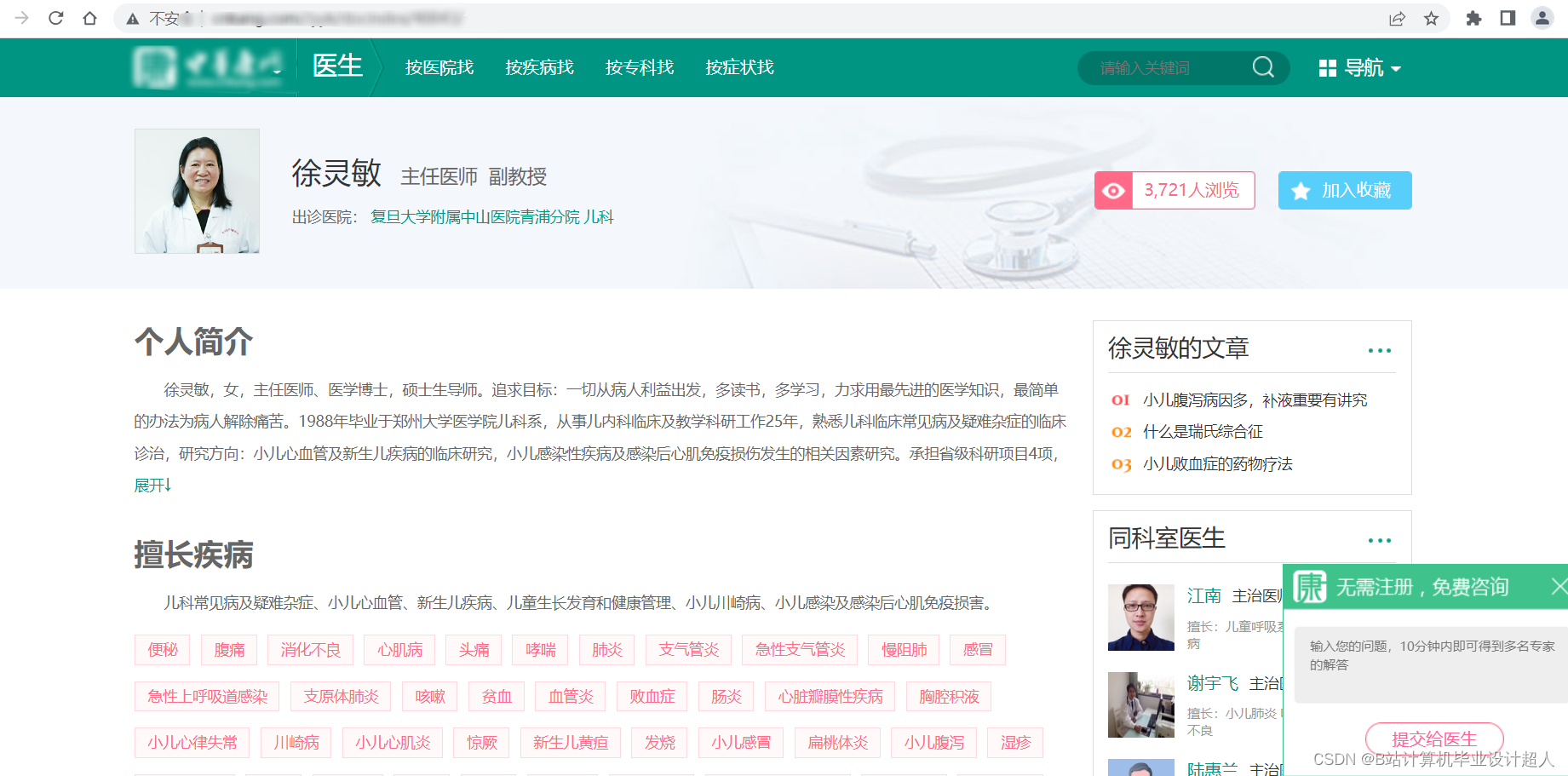
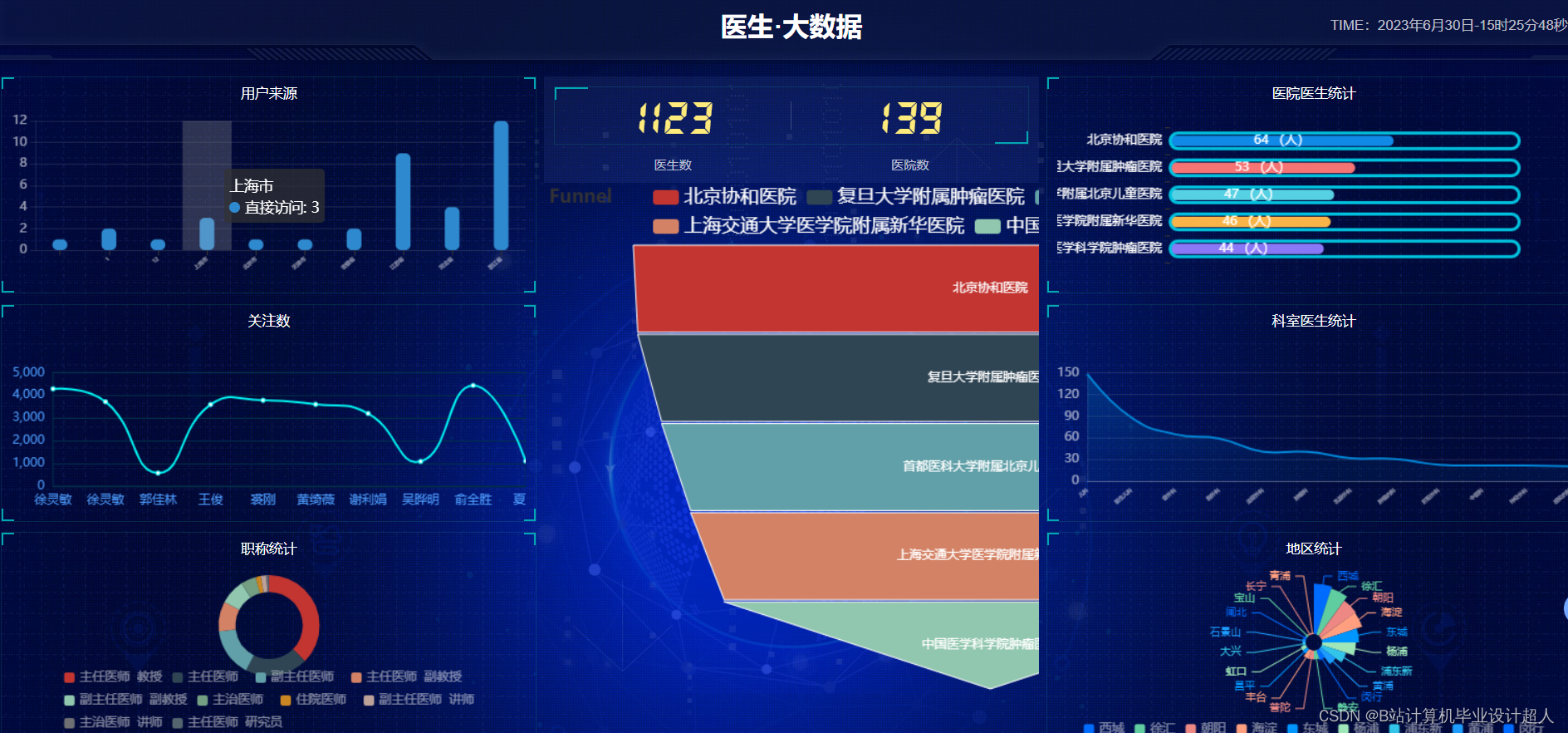

# coding=utf-8
from bs4 import BeautifulSoup
import requests
import sys
import random
import pymysql
links = []
datas = []
hea = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36'
}
urls =[
"https://www.chinanews.com/china.shtml", #国内
"https://www.chinanews.com/society.shtml", #社会
"https://www.chinanews.com/compatriot.shtml",#港澳
"https://www.chinanews.com/wenhua.shtml",#文化
"https://www.chinanews.com/world.shtml",#国际
"https://www.chinanews.com/cj/gd.shtml",#财经
"https://www.chinanews.com/sports.shtml",#体育
"https://www.chinanews.com/huaren.shtml" #华人
]
# 打开数据库连接
db = pymysql.connect(host='127.0.0.1', user='root', password='123456', port=3396, db='news_recommendation_system')
# 使用cursor()方法获取操作游标
cursor = db.cursor()
def main():
#reload(sys)
#sys.setdefaultencoding("utf-8")
#baseurl = 'https://www.chinanews.com/taiwan.shtml' # 要爬取的网页链接
baseurl = 'https://www.chinanews.com/taiwan.shtml' # 要爬取的网页链接
# deleteDate()
# 1.爬取主网页获取各个链接
getLink(baseurl)
# 2.根据链接爬取内部信息并且保存数据到数据库
getInformationAndSave()
# 3.关闭数据库
db.close()
def getInformationAndSave():
for link in links:
data = []
url = "https://www.chinanews.com" + link[1]
cur_html = requests.get(url, headers=hea)
cur_html.encoding = "utf8"
soup = BeautifulSoup(cur_html.text, 'html.parser')
# 获取时间
title = soup.find('h1')
title = title.text.strip()
# 获取时间和来源
tr = soup.find('div', class_='left-t').text.split()
time = tr[0] + tr[1]
recourse = tr[2]
# 获取内容
cont = soup.find('div', class_="left_zw")
content = cont.text.strip()
print(link[0] + "---" + title + "---" + time + "---" + recourse + "---" + url)
saveDate(title,content,time,recourse,url)
def deleteDate():
sql = "DELETE FROM news "
try:
# 执行SQL语句
cursor.execute(sql)
# 提交修改
db.commit()
except:
# 发生错误时回滚
db.rollback()
def saveDate(title,content,time,recourse,url):
try:
cursor.execute("INSERT INTO news(news_title, news_content, type_id, news_creatTime, news_recourse,news_link) VALUES ('%s', '%s', '%s', '%s', '%s' ,'%s')" % \
(title, content, random.randint(1,8), time, recourse,url))
db.commit()
print("执行成功")
except:
db.rollback()
print("执行失败")
def getLink(baseurl):
html = requests.get(baseurl, headers=hea)
html.encoding = 'utf8'
soup = BeautifulSoup(html.text, 'html.parser')
for item in soup.select('div.content_list > ul > li'):
# 对不符合的数据进行清洗
if (item.a == None):
continue
data = []
type = item.div.text[1:3] # 类型
link = item.div.next_sibling.next_sibling.a['href']
data.append(type)
data.append(link)
links.append(data)
if __name__ == '__main__':
main()
以下是一个简单的基于协同过滤的推荐算法的 Python 代码示例。在这个示例中,我们使用了 Surprise 库来实现基于近邻的协同过滤推荐算法。
from surprise import Dataset, Reader, KNNBasic
import pandas as pd
# 假设有一些用户评分数据,包括用户ID、物品ID和评分
data = {
'user_id': [1, 1, 2, 2, 3, 3, 4, 4, 5, 5],
'item_id': ['A', 'B', 'A', 'C', 'B', 'D', 'C', 'D', 'A', 'C'],
'rating': [5, 3, 4, 4, 5, 1, 4, 5, 3, 2]
}
df = pd.DataFrame(data)
# 使用 Surprise 库需要将数据加载到 Surprise 的 Dataset 对象中
reader = Reader(rating_scale=(1, 5)) # 定义评分范围
dataset = Dataset.load_from_df(df[['user_id', 'item_id', 'rating']], reader)
# 使用KNNBasic算法进行推荐
sim_options = {'name': 'cosine', 'user_based': False} # 基于物品的协同过滤
knn = KNNBasic(sim_options=sim_options)
# 训练模型
trainset = dataset.build_full_trainset()
knn.fit(trainset)
# 假设要为用户1推荐物品
user_id = 1
items_to_predict = ['A', 'C', 'D'] # 用户1尚未评分的物品
for item_id in items_to_predict:
prediction = knn.predict(user_id, item_id)
print("为用户{}推荐物品{},预测评分为{}".format(user_id, item_id, prediction.est))
在这个示例中,我们使用了 Surprise 库加载用户评分数据,并使用 KNNBasic 算法进行基于物品的协同过滤推荐。最后,我们为用户1推荐了物品 A、C 和 D,并给出了预测评分。
需要注意的是,这只是一个简单的示例。在实际应用中,可能需要更多的数据预处理、参数调优以及评估推荐效果等工作。

在这里,我们一起交流AI,学习AI,用AI改变世界。如有AI产品需求,可访问讯飞开放平台,www.xfyun.cn。
更多推荐



 4
4 0
0- 0



 已为社区贡献189条内容
已为社区贡献189条内容

所有评论(0)