
大数据毕业设计hadoop+spark知识图谱医生推荐系统 门诊预测 医疗数据可视化 医疗大数据 医疗数据分析 医生爬虫 大数据毕设 机器学习 深度学习 人工智能 数据可视化 计算机毕业设计
大数据毕业设计hadoop+spark知识图谱医生推荐系统 门诊预测 医疗数据可视化 医疗大数据 医疗数据分析 医生爬虫大数据毕设 机器学习 深度学习 人工智能 数据可视化 计算机毕业设计
·
1. 项目背景
随着人们对健康的关注日益增加,医疗保健领域的信息化和智能化需求也日益迫切。针对医生推荐系统的需求,本项目旨在利用Python构建一套智能化的医生推荐系统,帮助患者更快速、更准确地找到适合自己需求的医生。
2. 项目目标
- 构建一个基于患者症状、疾病、地理位置等信息的医生推荐系统。
- 提供个性化的医生推荐,考虑患者需求、医生专长、就诊距离等因素。
- 实现用户友好的交互界面,方便患者使用系统进行医生选择。
3. 技术方案
3.1 数据收集
- 收集医生信息、患者需求、医院地理位置等数据。
- 利用公开的医疗数据库或通过网络爬虫技术获取相关数据。
3.2 数据处理与特征提取
- 对医生信息进行清洗和预处理,提取医生的专业领域、擅长治疗的疾病、所在医院等特征。
- 提取患者需求的关键特征,如症状、疾病类型等。
3.3 模型建立
- 基于收集到的医生和患者信息,构建机器学习模型或推荐系统模型。
- 考虑使用协同过滤、内容过滤等推荐算法,结合医生特长、患者需求和地理位置等因素进行医生推荐。
3.4 用户界面设计
- 设计用户友好的交互界面,方便用户输入症状、选择疾病类型等信息。
- 通过界面展示推荐的医生信息,包括医生姓名、所在医院、擅长治疗的疾病等。
3.5 系统测试与优化
- 对系统进行全面测试,验证医生推荐的准确性和实用性。
- 根据用户反馈和测试结果,不断优化系统的推荐算法和用户界面设计。
4. 预期成果
- 实现一个功能完善、准确度高的医生推荐系统,能够满足用户的实际需求。
- 提供稳定可靠的用户界面,方便患者使用系统进行医生选择。
- 在医疗保健领域取得一定的技术突破,为智能医疗领域的发展贡献力量。
5. 时间安排
- 数据收集与处理:2周
- 模型建立与调优:4周
- 用户界面设计与系统整合:2周
- 系统测试与优化:2周
6. 风险分析
- 数据收集困难:部分医生信息可能难以获取,需要寻求其他途径或采用替代方案。
- 推荐准确度问题:推荐系统的准确性可能受到影响,需要通过不断优化提高推荐的精准度。
7. 结语
本项目旨在为患者提供智能化的医生推荐服务,通过整合医生信息和患者需求,为用户提供更便捷、个性化的医疗服务体验。我们将充分利用Python的数据处理和机器学习能力,致力于打造一个高效、准确的医生推荐系统。
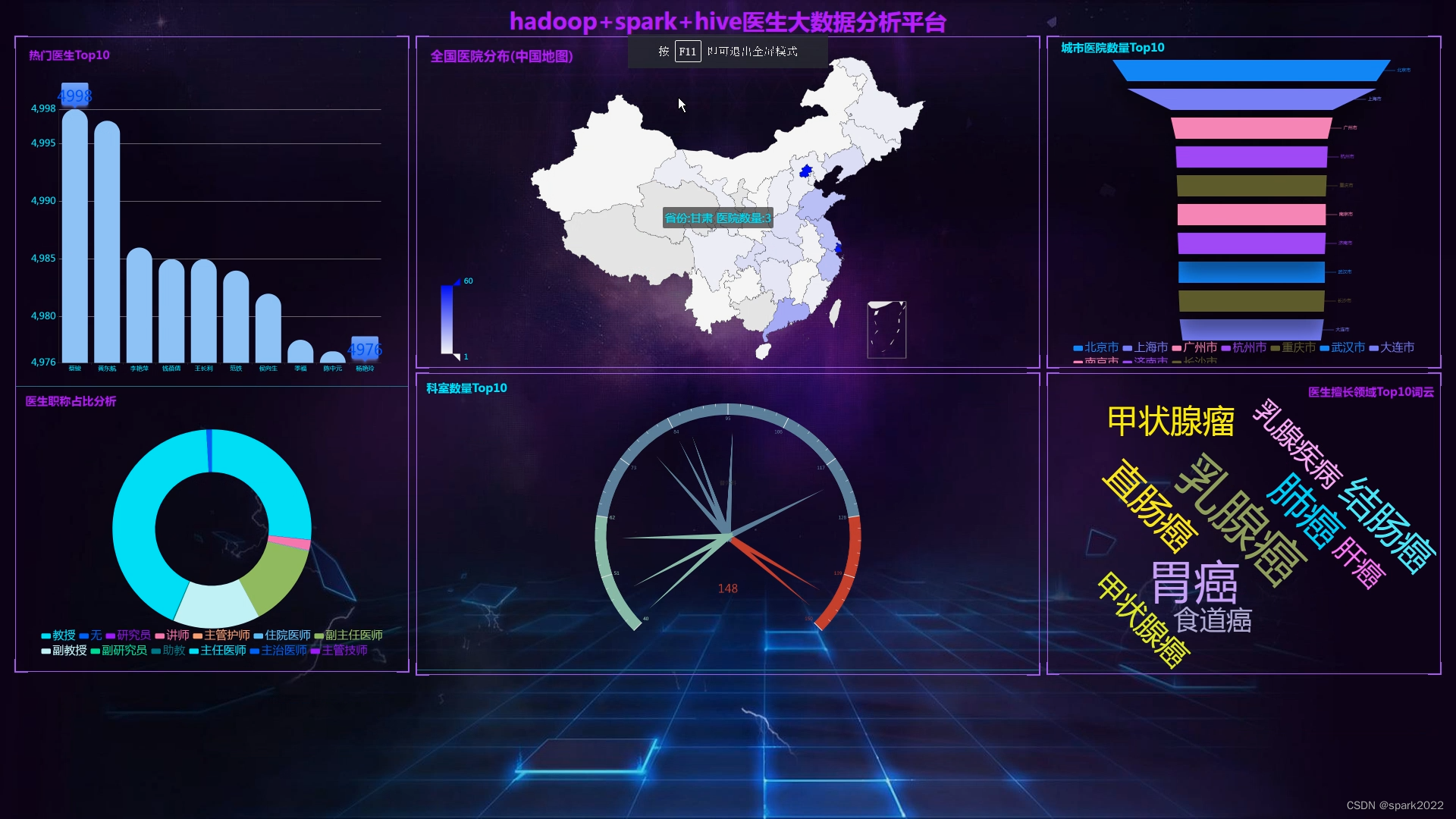
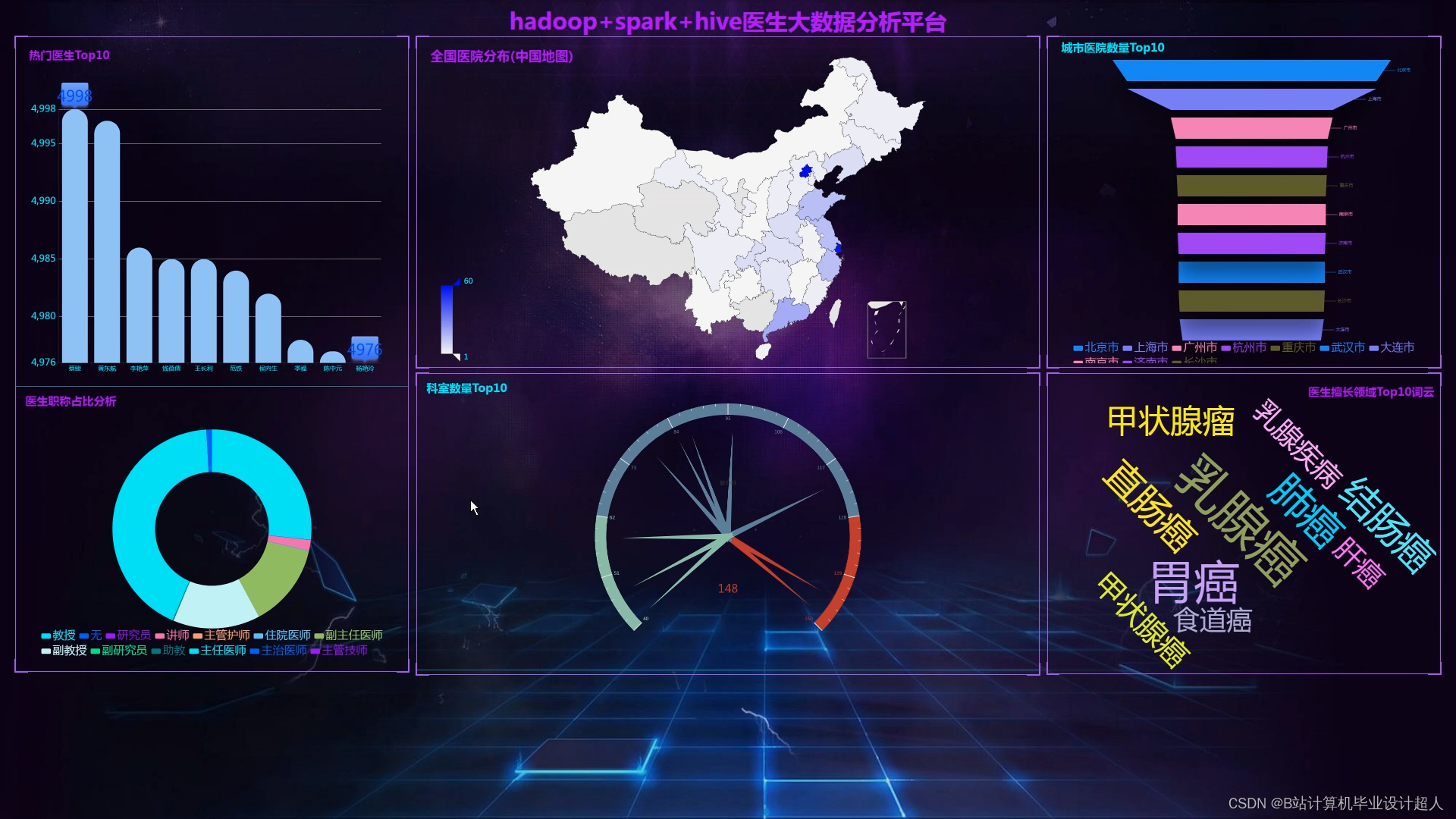
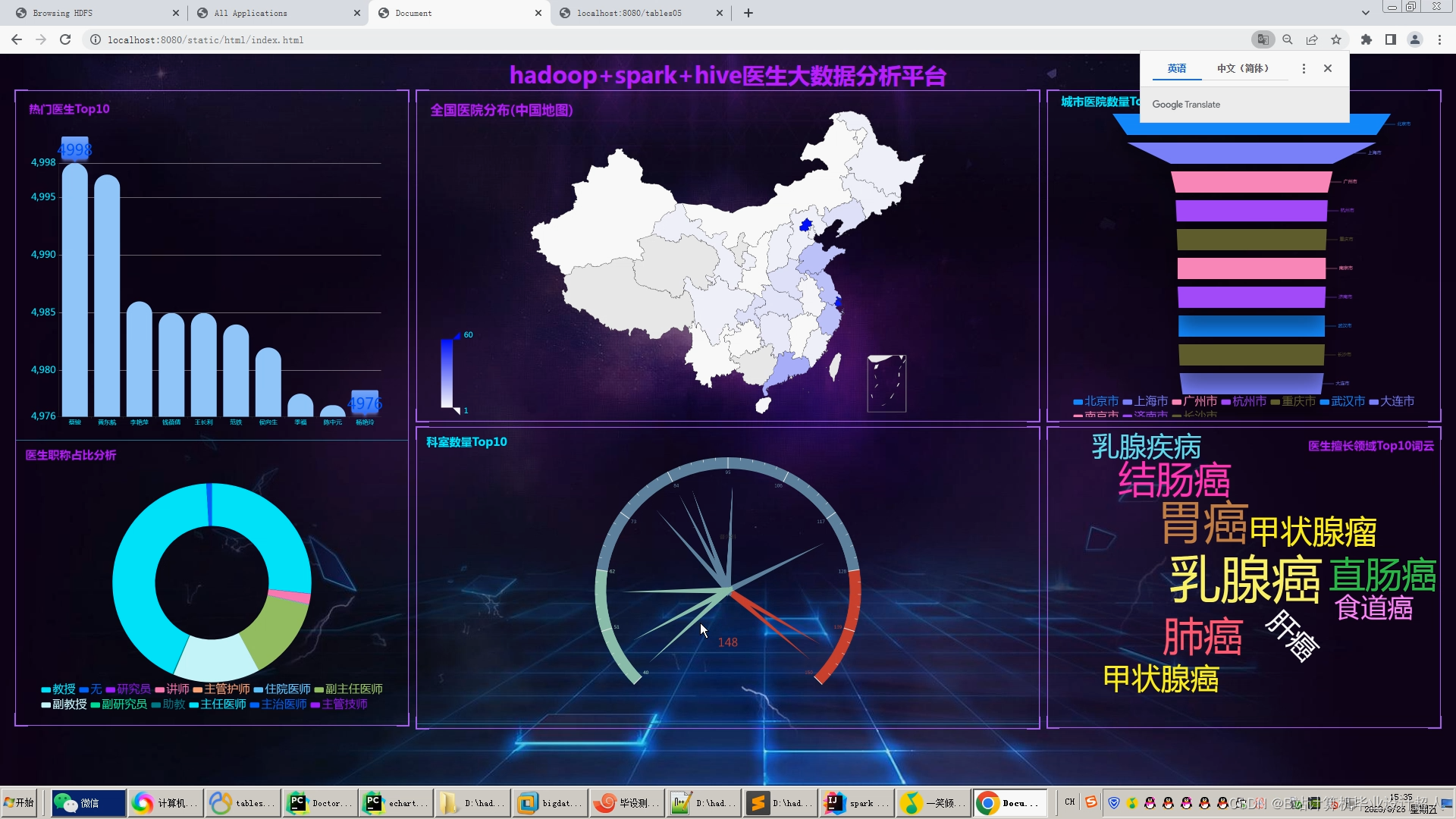
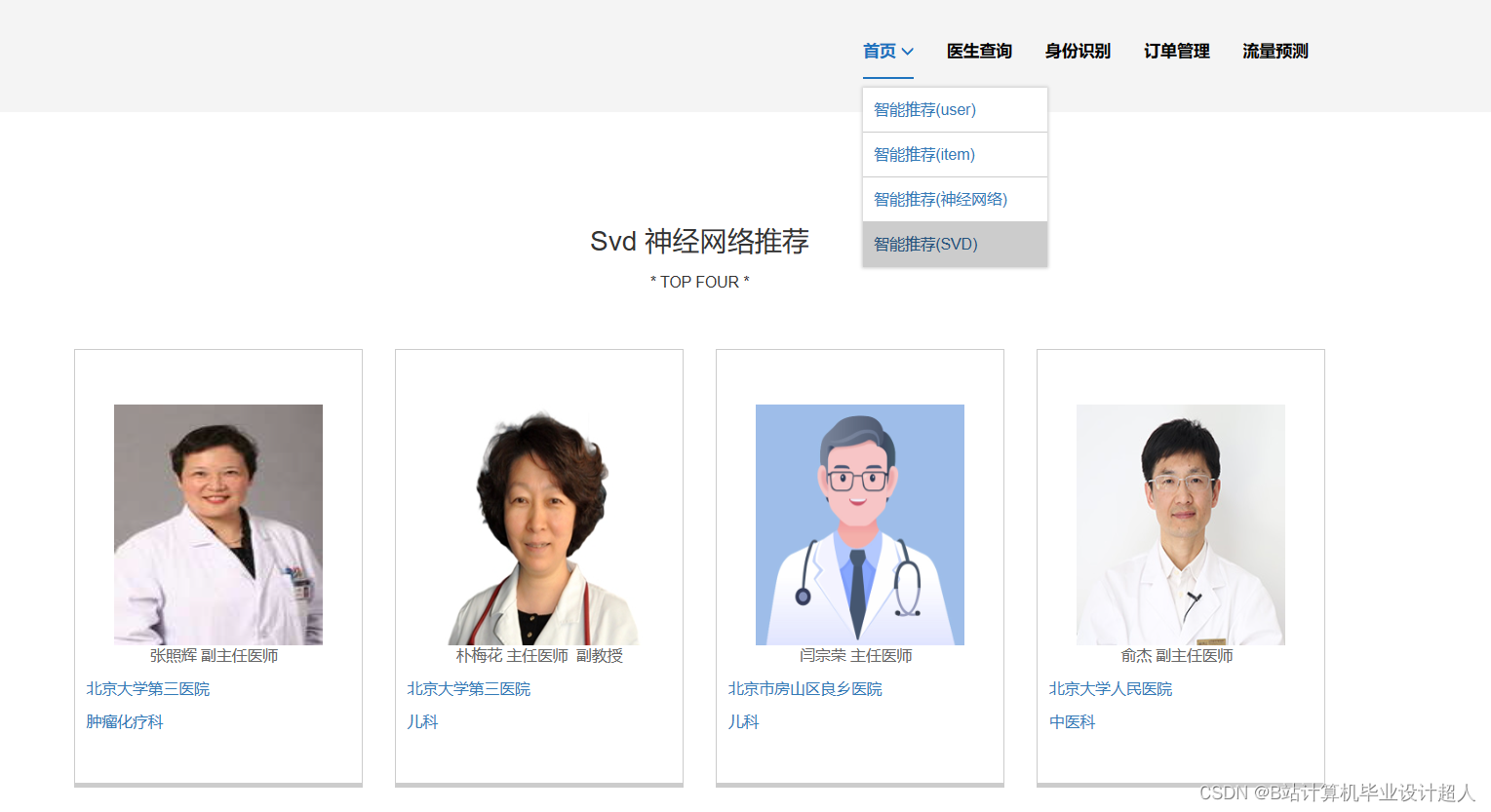
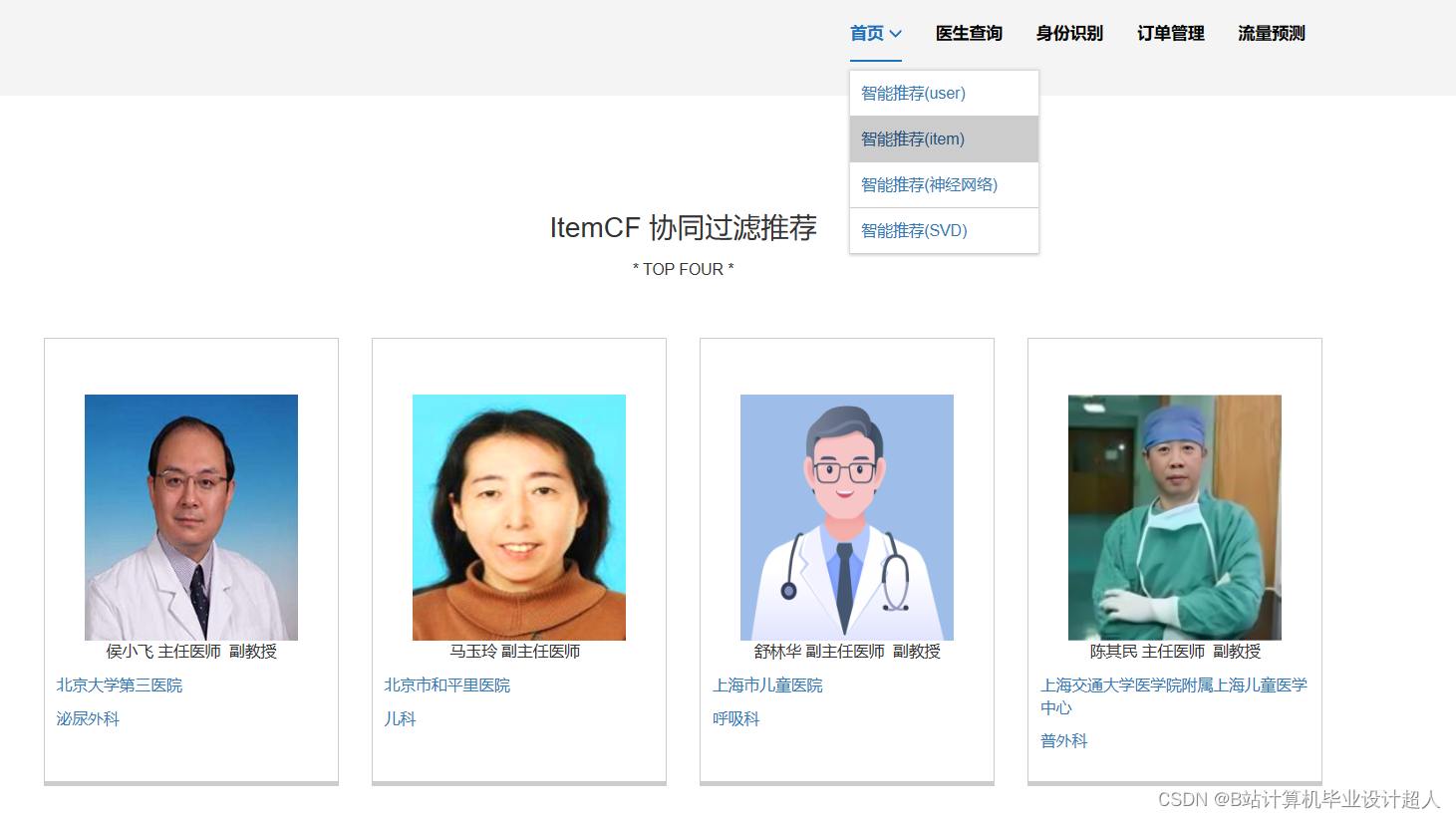
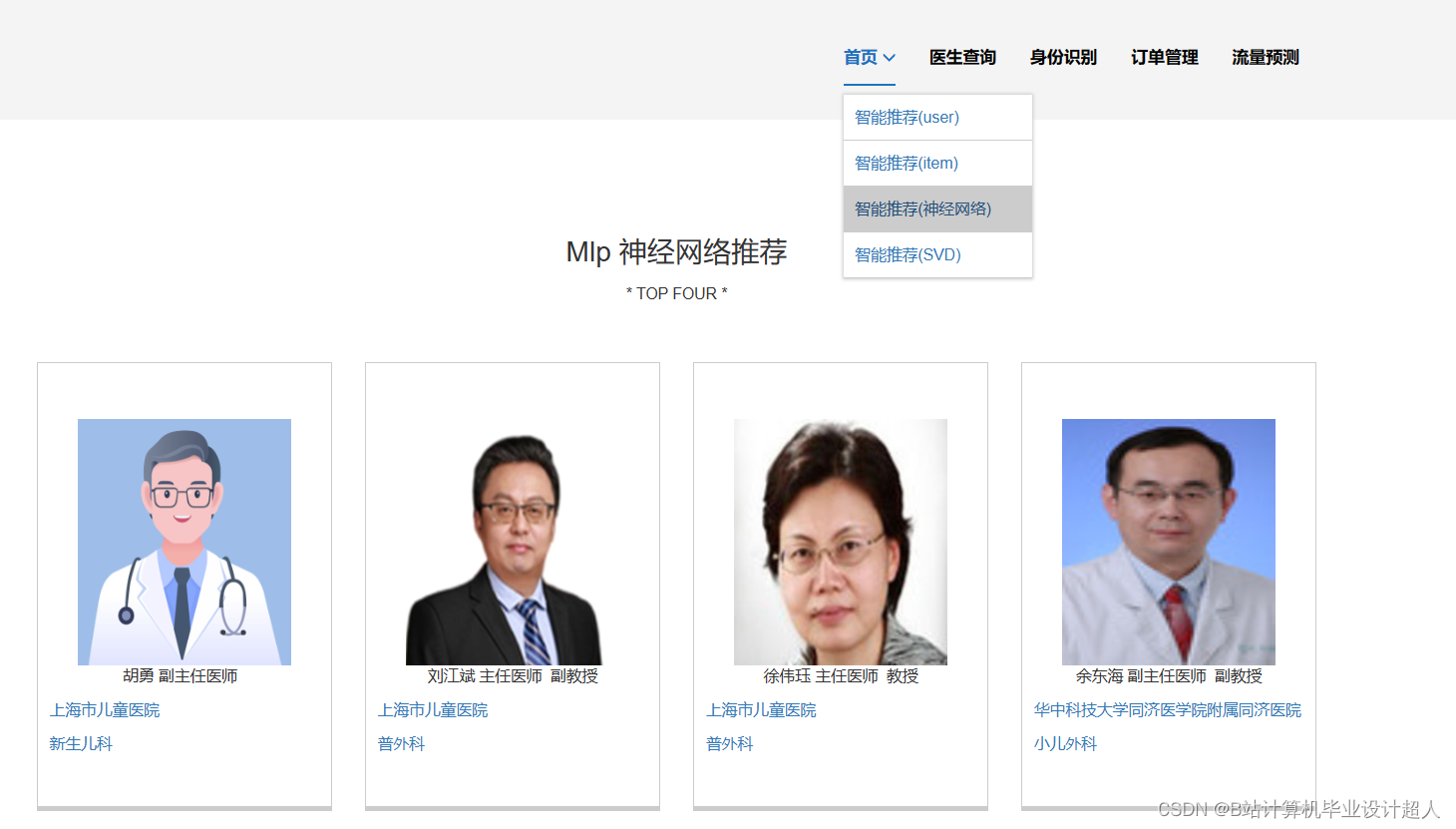
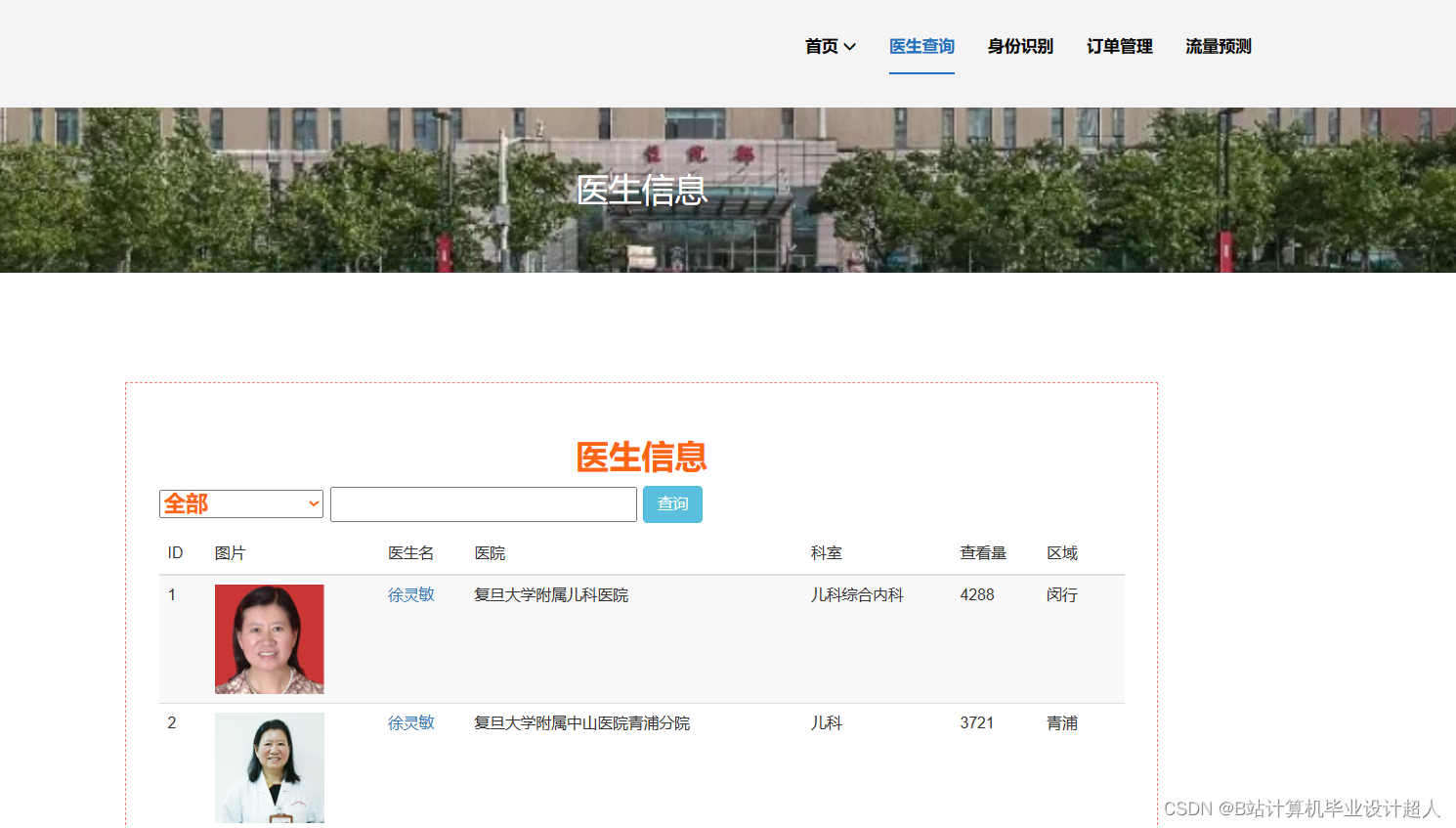
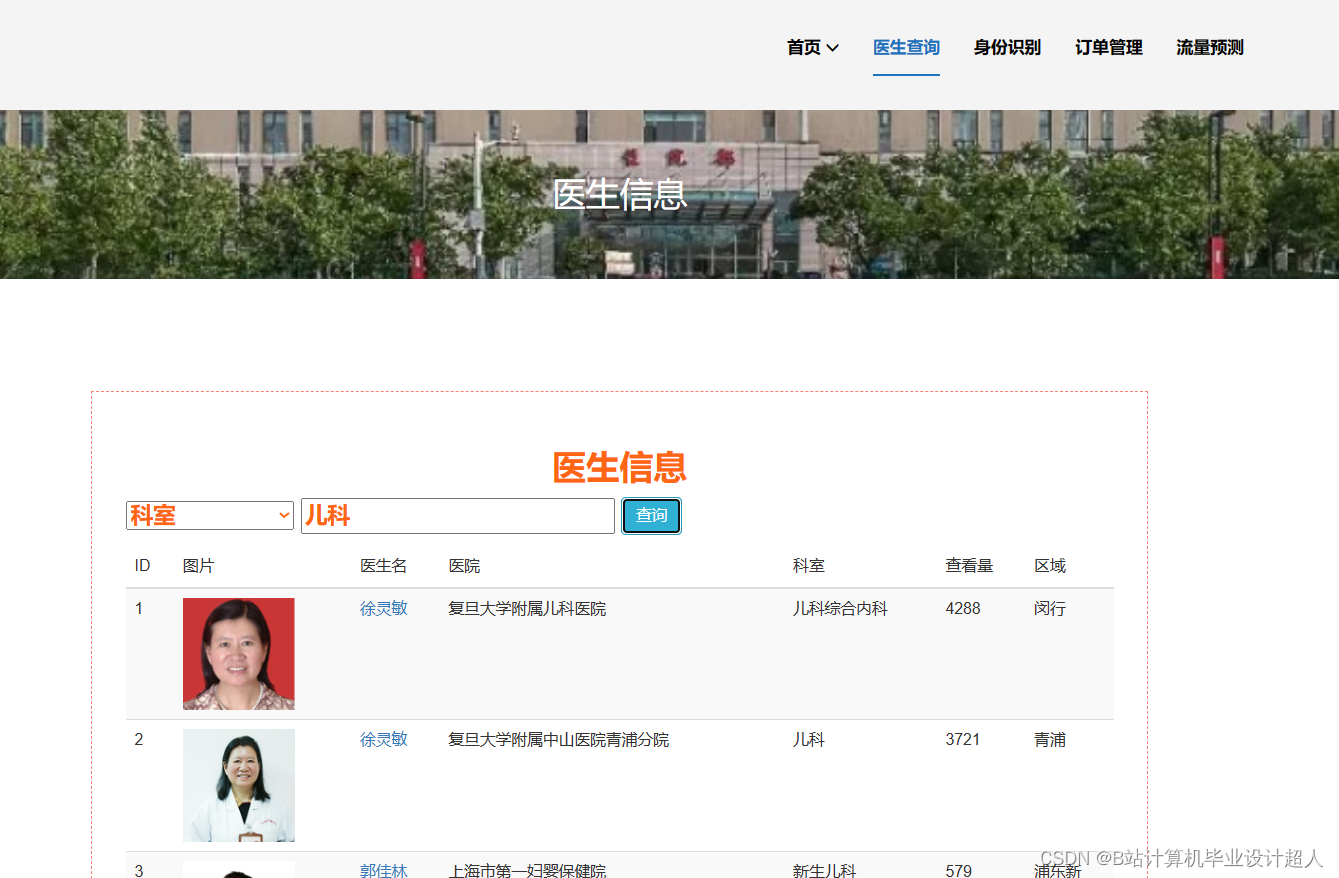
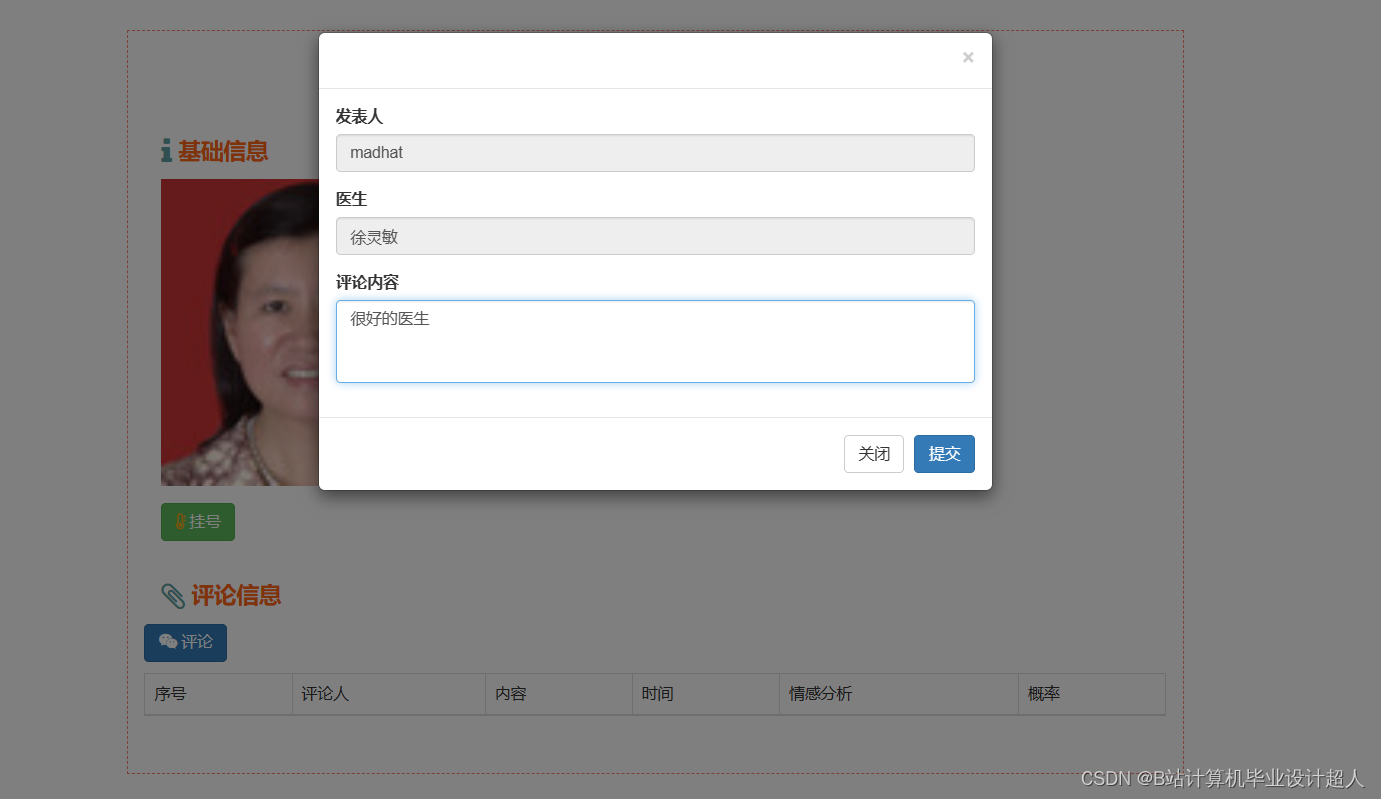
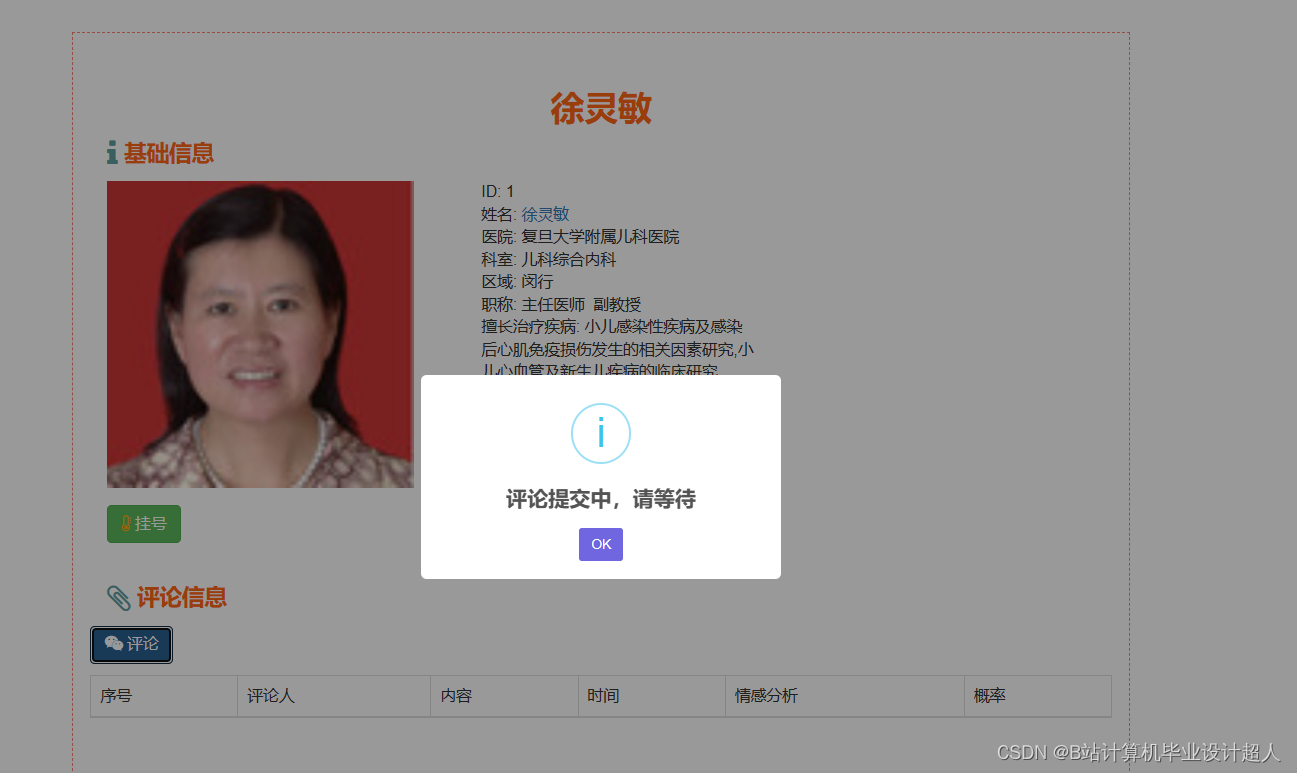

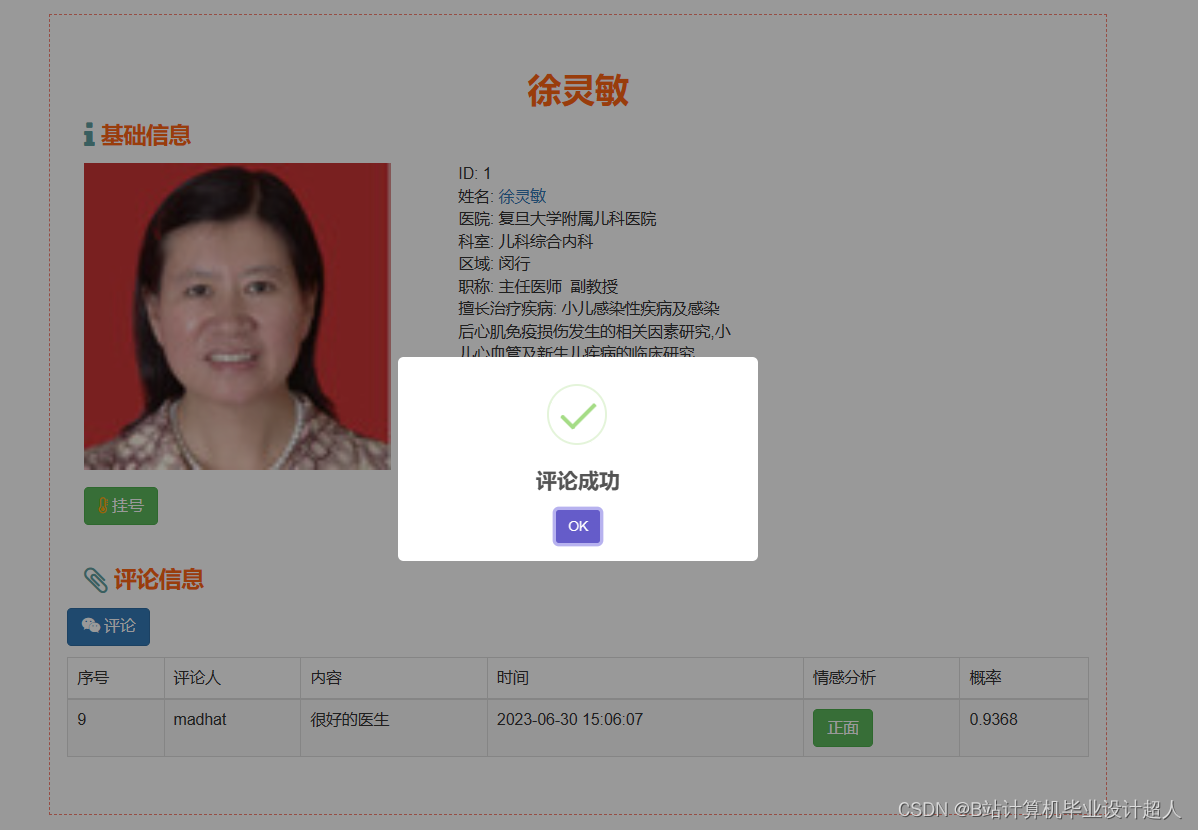
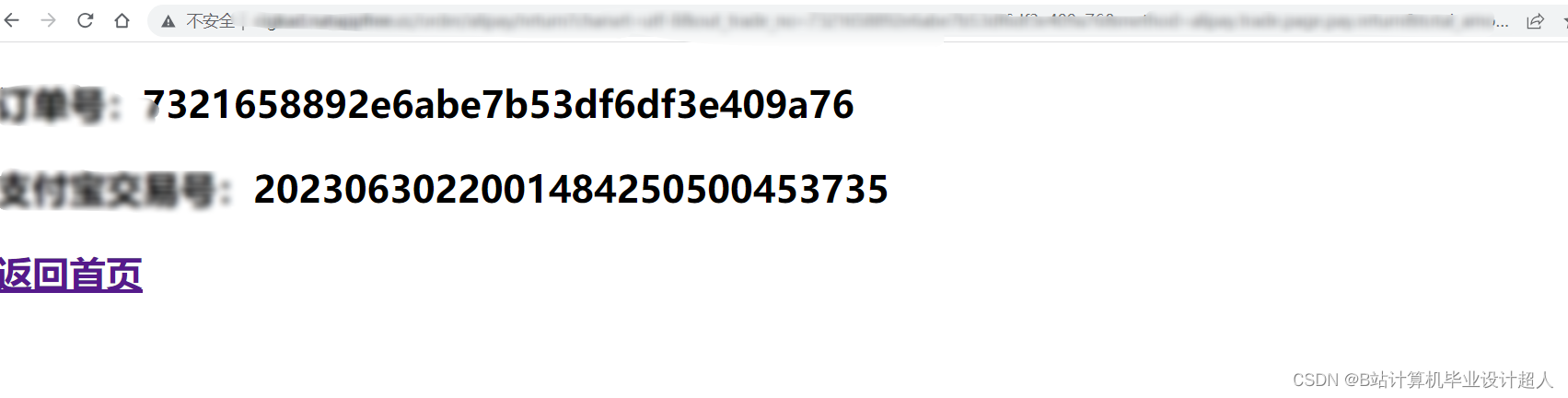
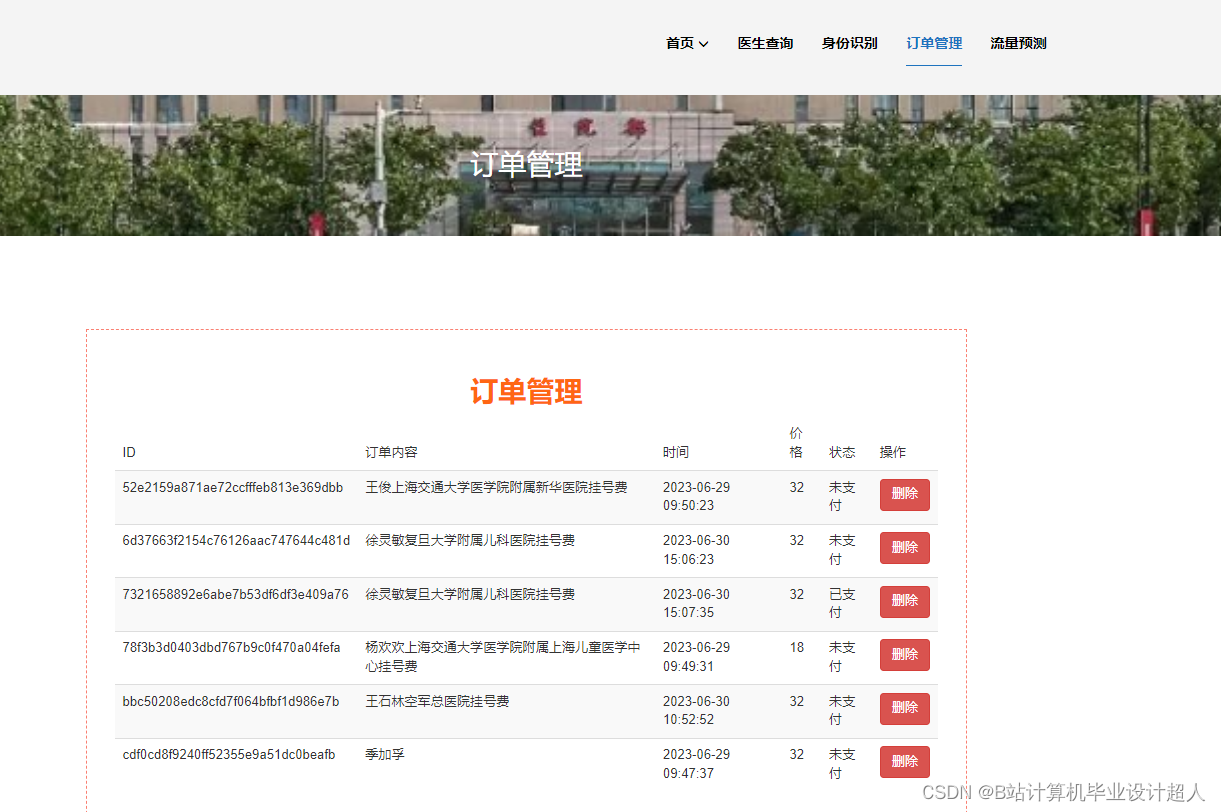
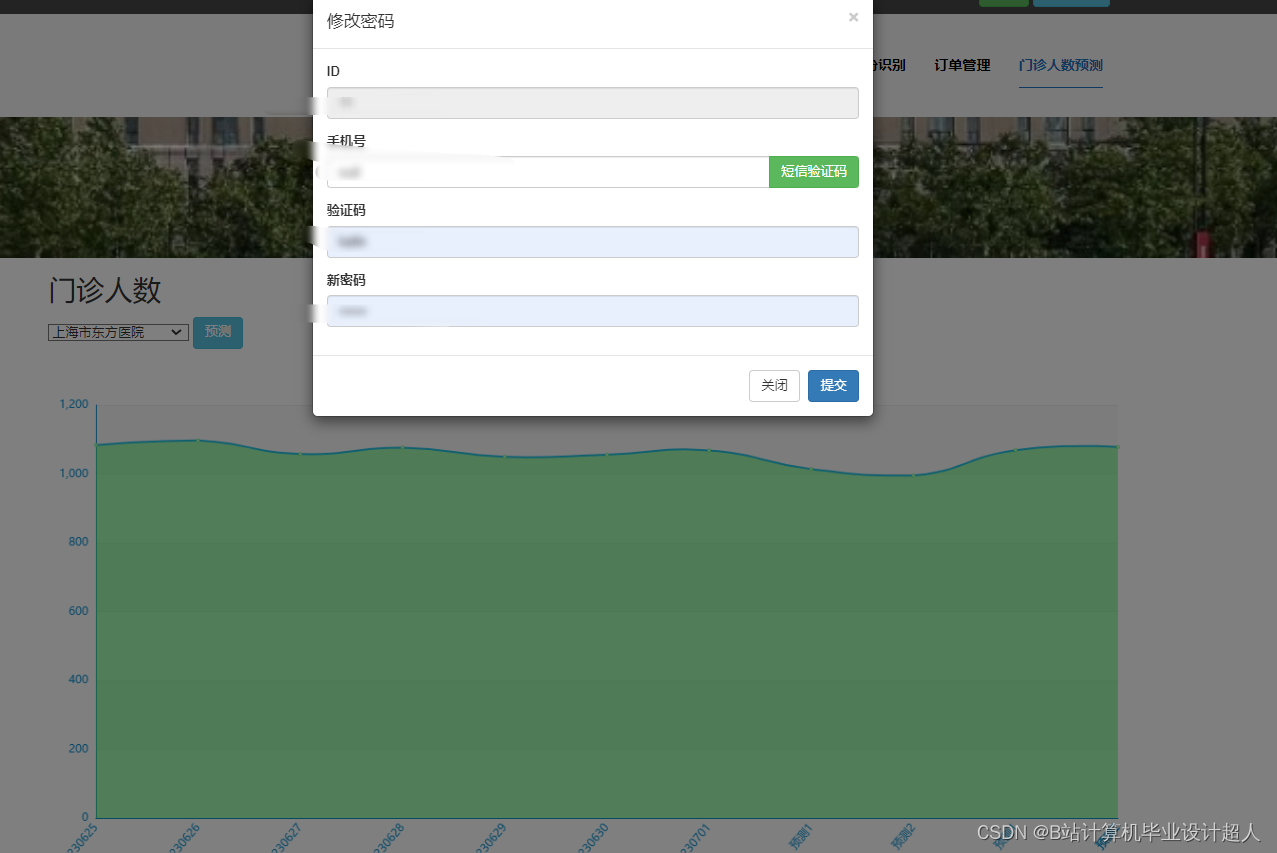
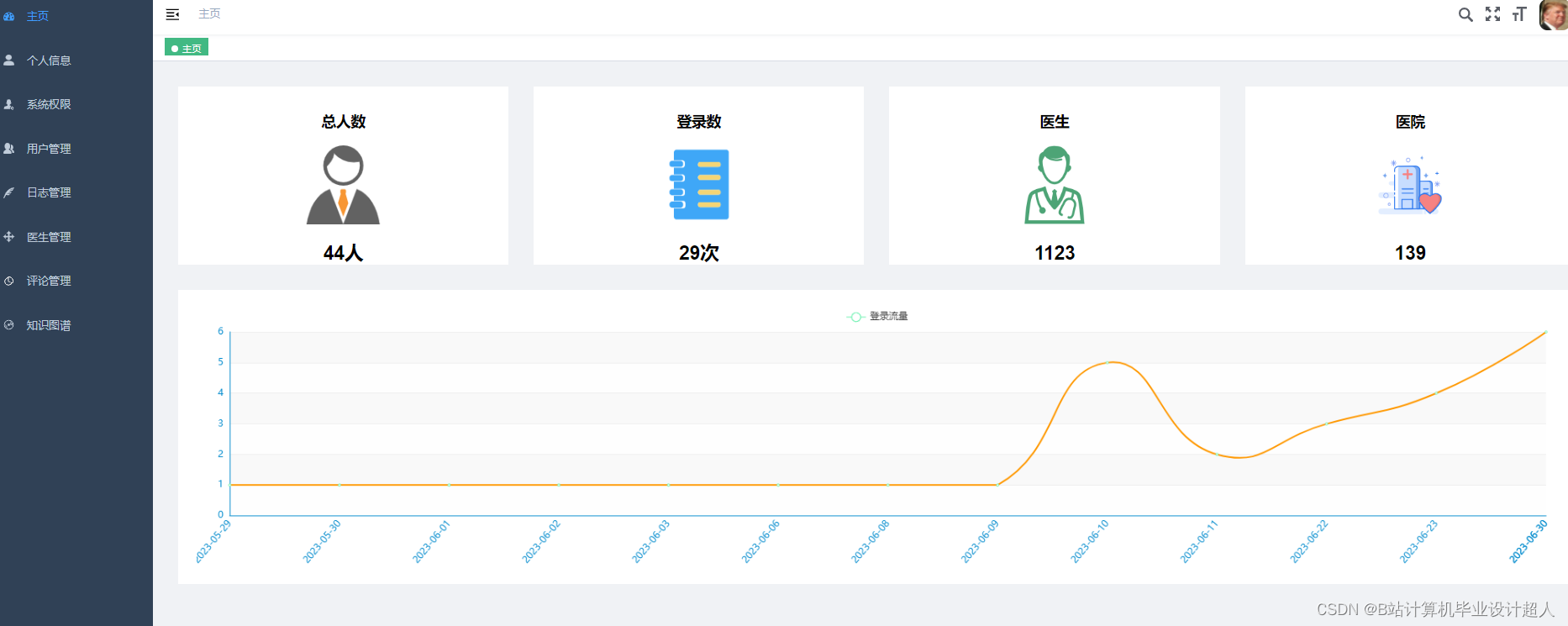
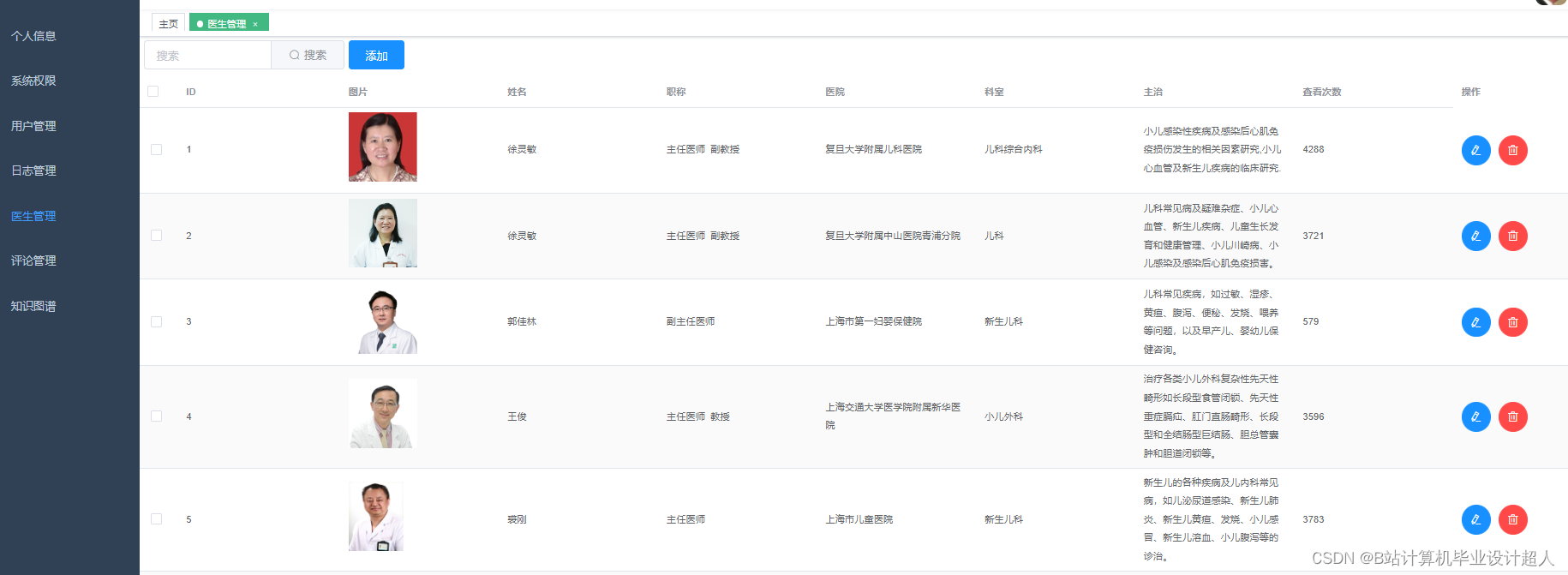
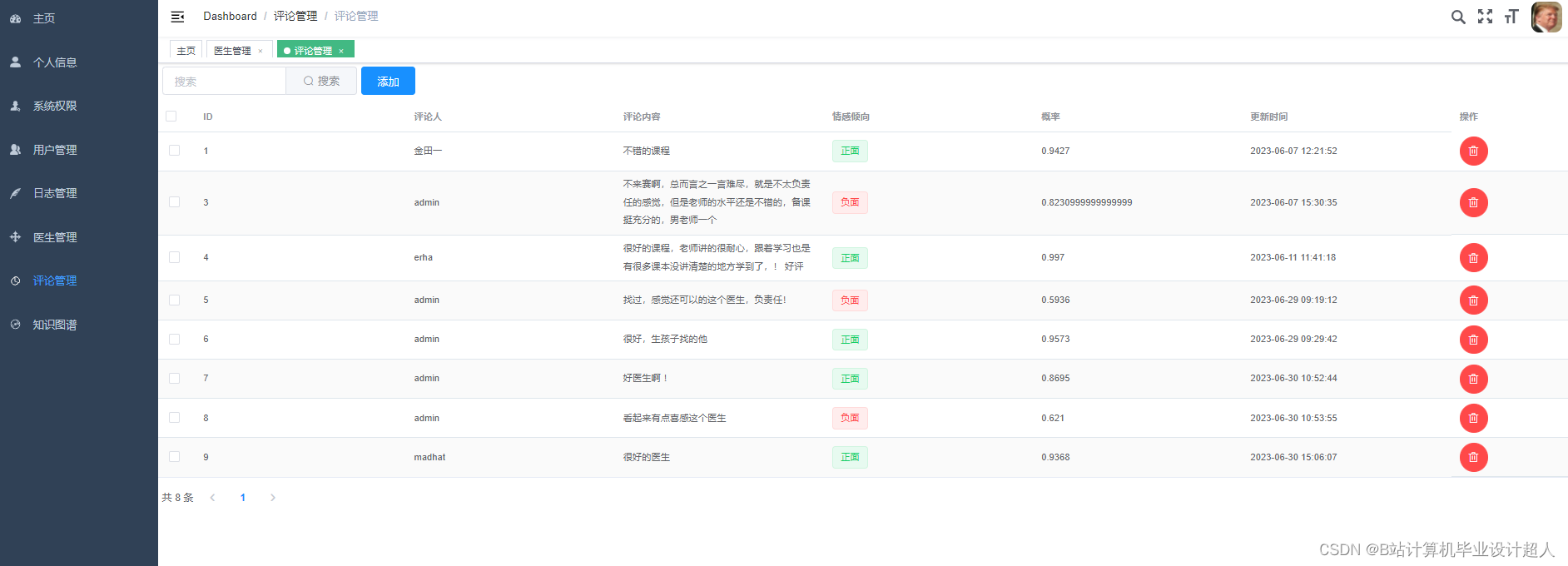
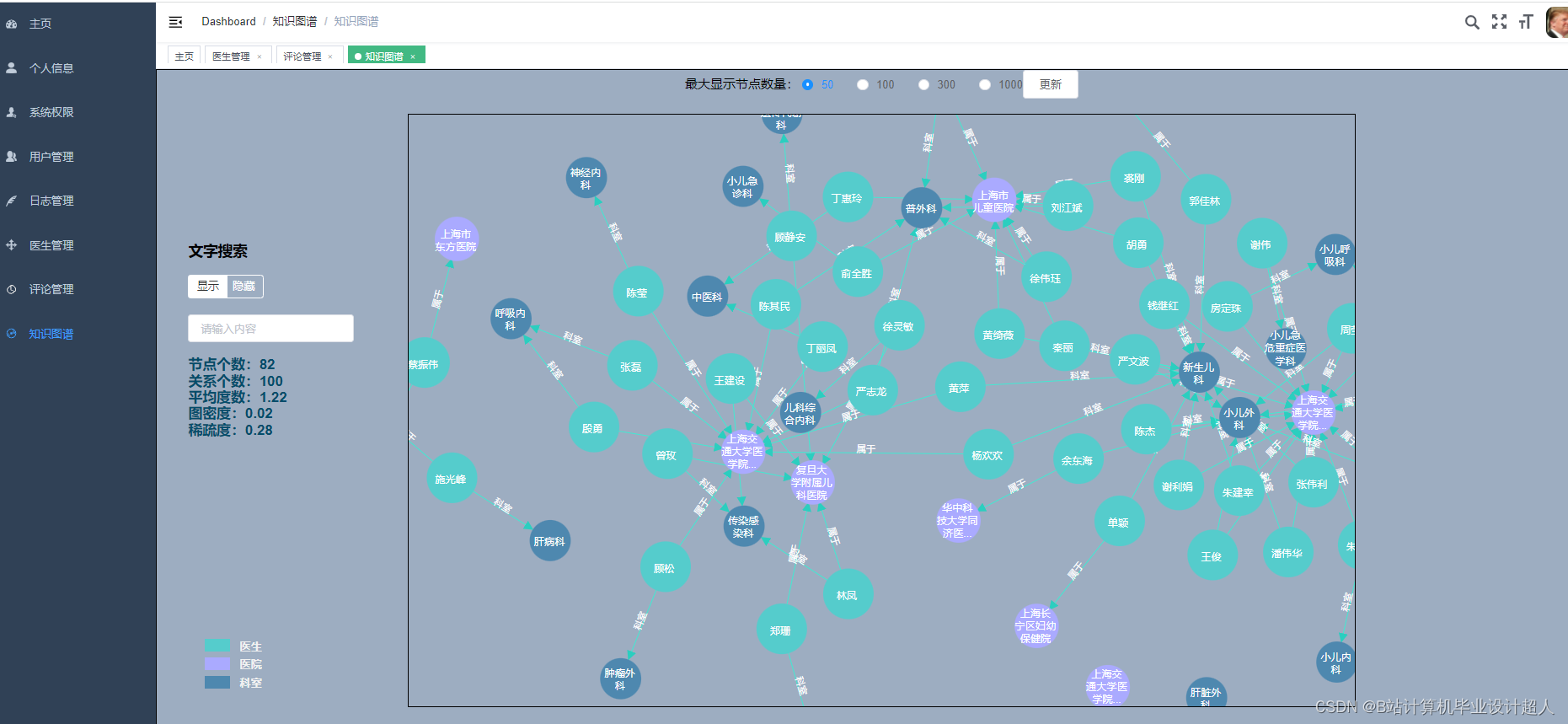
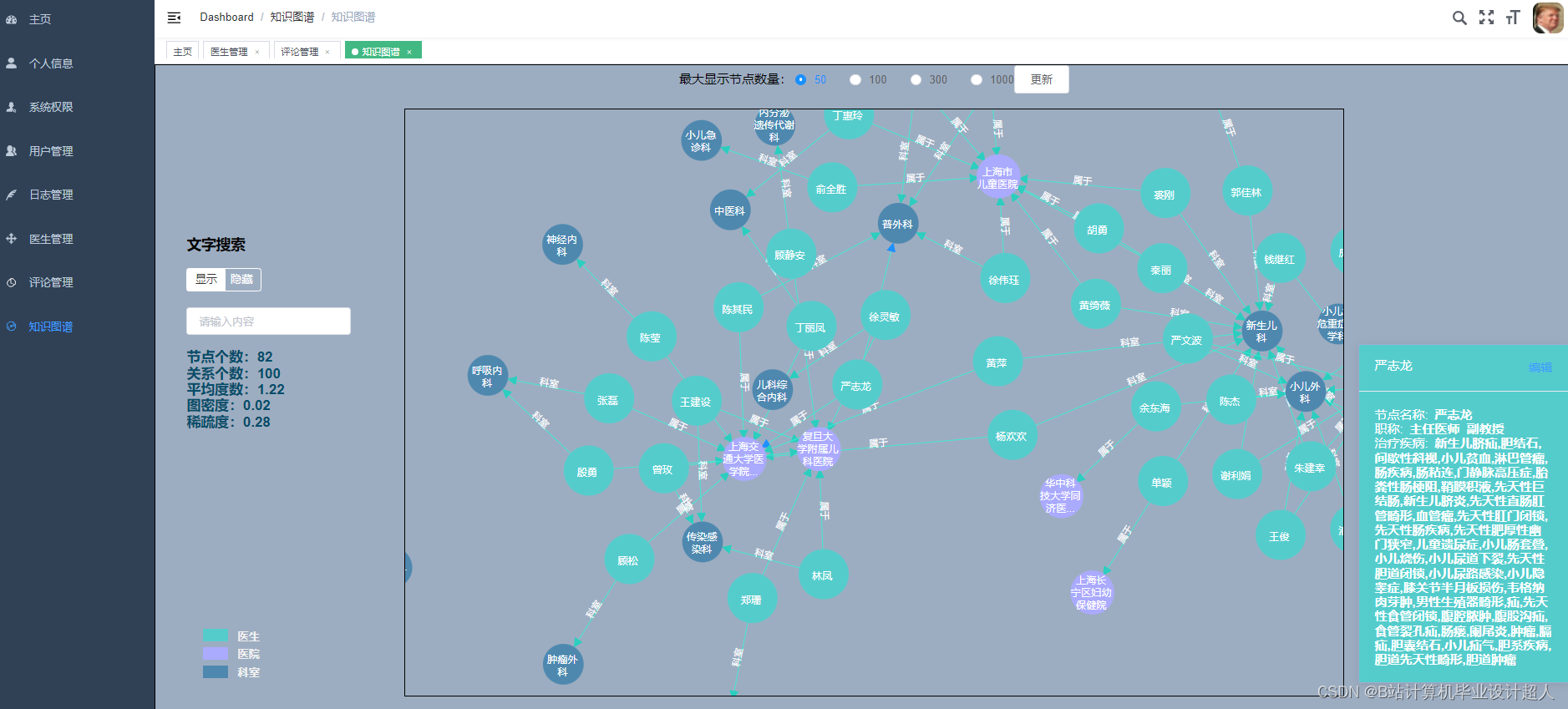
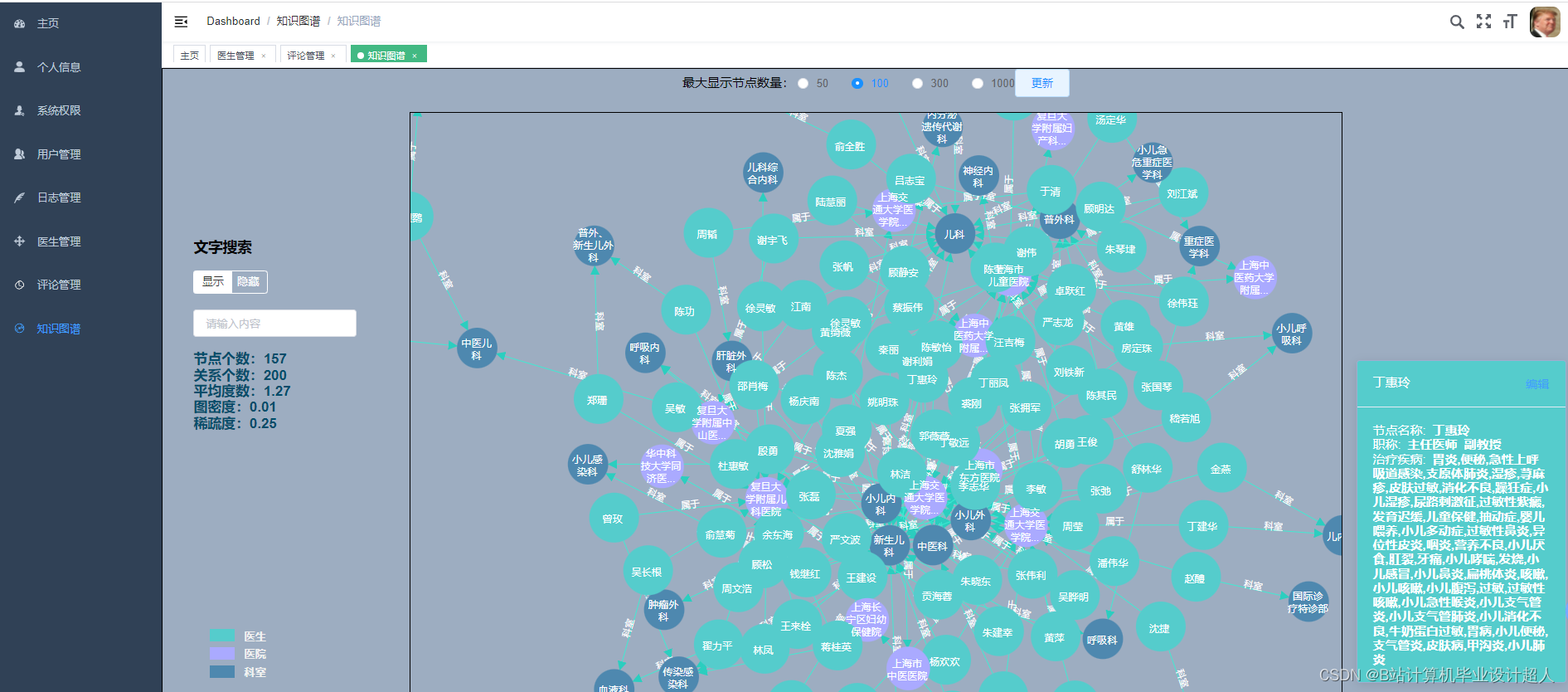
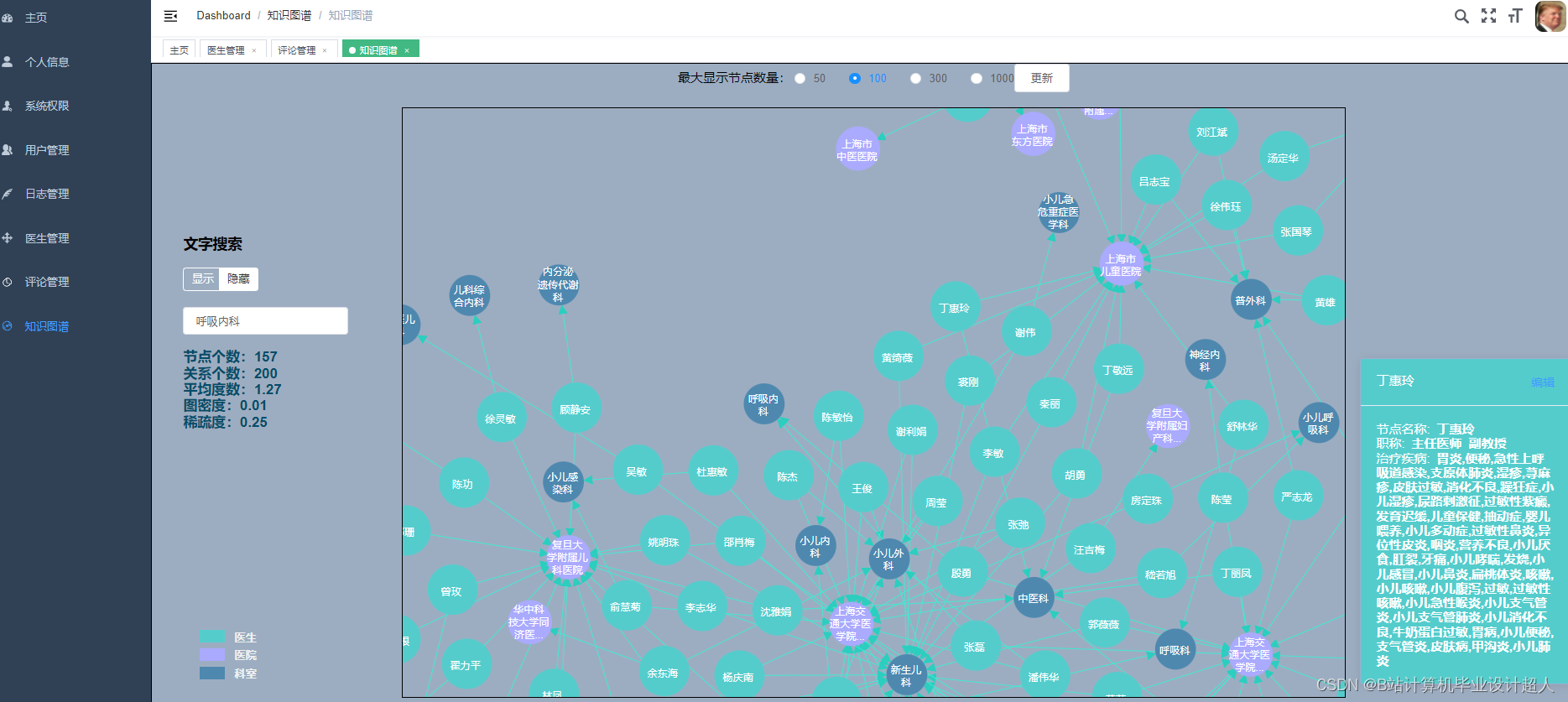
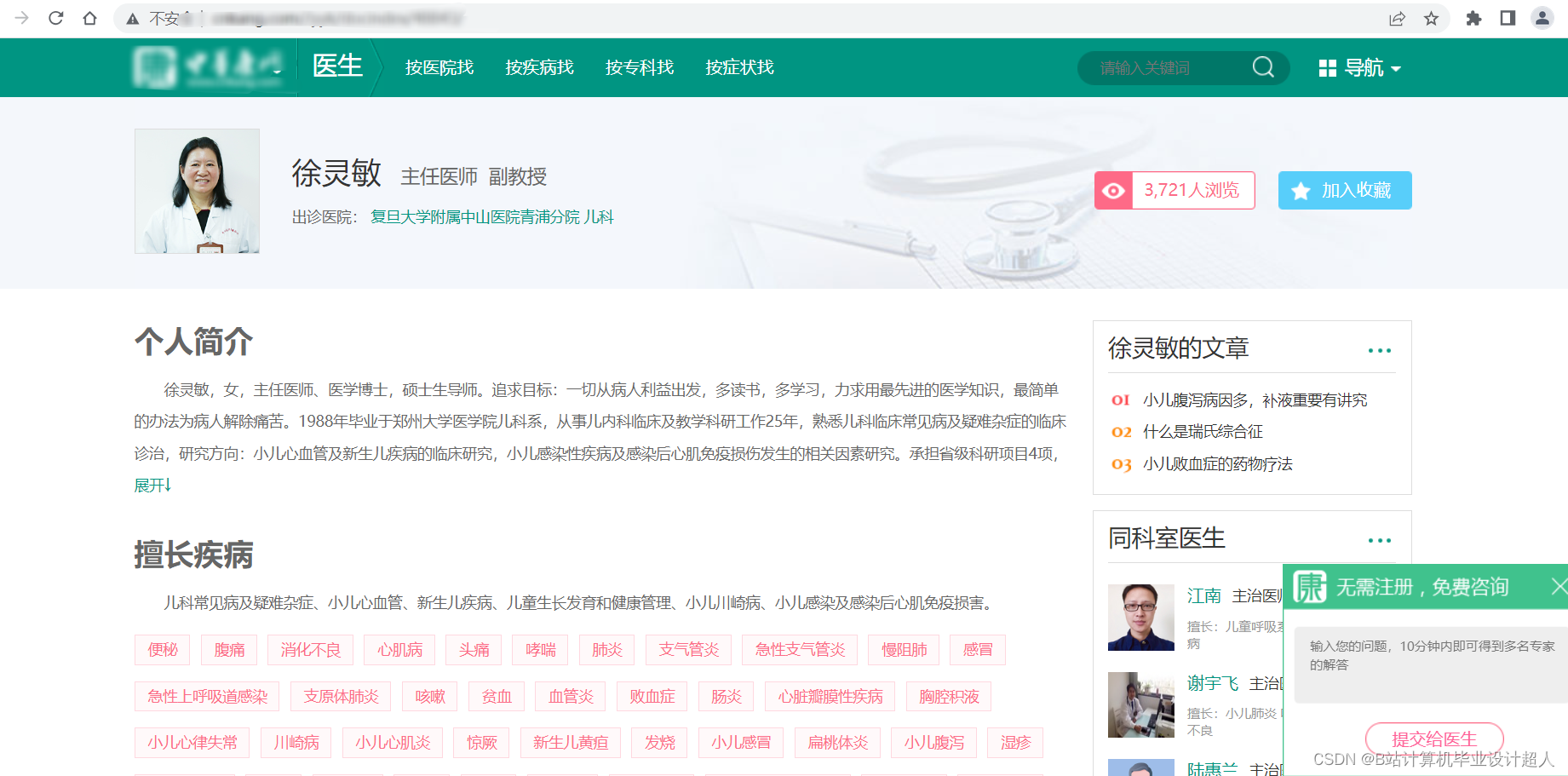
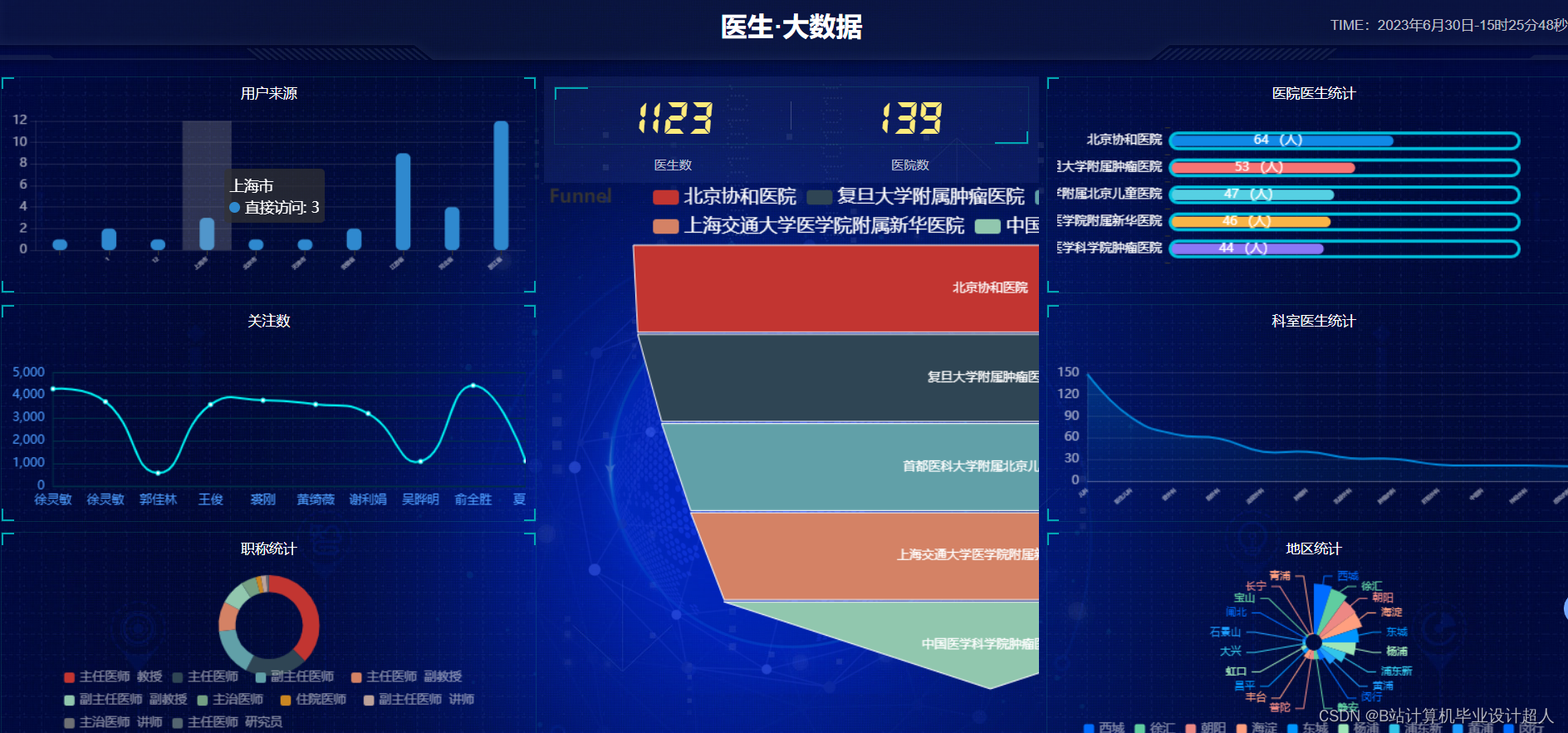
 由于医生推荐系统涉及到的数据可能较为复杂,而且SparkML主要用于大规模数据的处理和机器学习任务,下面我提供一个简单的示例代码,演示如何使用SparkML的ALS算法进行协同过滤推荐:
由于医生推荐系统涉及到的数据可能较为复杂,而且SparkML主要用于大规模数据的处理和机器学习任务,下面我提供一个简单的示例代码,演示如何使用SparkML的ALS算法进行协同过滤推荐:
from pyspark.sql import SparkSession
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
# 创建Spark会话
spark = SparkSession.builder.appName("DoctorRecommendationSystem").getOrCreate()
# 加载医生-患者评分数据,格式为(patientID, doctorID, rating)
data = spark.read.format("csv").option("header", "true").load("ratings.csv")
# 创建ALS模型
als = ALS(userCol="patientID", itemCol="doctorID", ratingCol="rating", coldStartStrategy="drop")
# 使用网格搜索调优ALS模型参数
paramGrid = ParamGridBuilder() \
.addGrid(als.rank, [10, 20, 30]) \
.addGrid(als.maxIter, [5, 10, 15]) \
.build()
# 使用均方误差作为评估指标
evaluator = RegressionEvaluator(metricName="rmse", labelCol="rating", predictionCol="prediction")
# 使用交叉验证选择最佳模型
crossval = CrossValidator(estimator=als,
estimatorParamMaps=paramGrid,
evaluator=evaluator,
numFolds=3)
# 拟合数据并得到最佳模型
model = crossval.fit(data)
# 进行医生推荐
patientSubset = data.select("patientID").distinct().limit(5)
recommendations = model.recommendForUserSubset(patientSubset, 5)
# 打印推荐结果
recommendations.show()
# 停止Spark会话
spark.stop()
请注意,这只是一个简单的示例代码,实际项目中需要根据具体情况进行数据处理、特征工程和模型调优。另外,还需要根据实际情况准备医生-患者评分数据集(如ratings.csv)以供模型训练和推荐。希望这段代码能够帮助你理解如何利用SparkML构建医生推荐系统。

在这里,我们一起交流AI,学习AI,用AI改变世界。如有AI产品需求,可访问讯飞开放平台,www.xfyun.cn。
更多推荐



 18
18 0
0- 0



 已为社区贡献189条内容
已为社区贡献189条内容

所有评论(0)