
大模型微调:从全量到高效的演进之路
大模型微调(Fine-tuning)指在通用预训练大模型(如GPT、LLaMA等)基础上,通过特定领域或任务数据对模型参数进行二次优化,实现通用能力向专业场景的定向迁移。其本质是利用迁移学习原理,将预训练模型在大规模数据中习得的通用知识(如语言模式、常识推理)适配到垂直领域,解决“通用模型专业能力不足”与“全量训练成本过高”的矛盾。
一、核心定义
大模型微调(Fine-tuning)指在通用预训练大模型(如GPT、LLaMA等)基础上,通过特定领域或任务数据对模型参数进行二次优化,实现通用能力向专业场景的定向迁移。其本质是利用迁移学习原理,将预训练模型在大规模数据中习得的通用知识(如语言模式、常识推理)适配到垂直领域,解决“通用模型专业能力不足”与“全量训练成本过高”的矛盾。
二、大型模型的经典网络结构
以GPT系列中的Transformer为例,这种深度学习模型结构通过自注意力机制等技巧解决了相关问题。正是得益于Transformer架构,基于GPT的大型语言模型取得了显著的进展。
Transformer模型架构包含了众多模块,而我们讨论的各种微调技术通常是对这些模块中的特定部分进行优化,以实现微调目的。
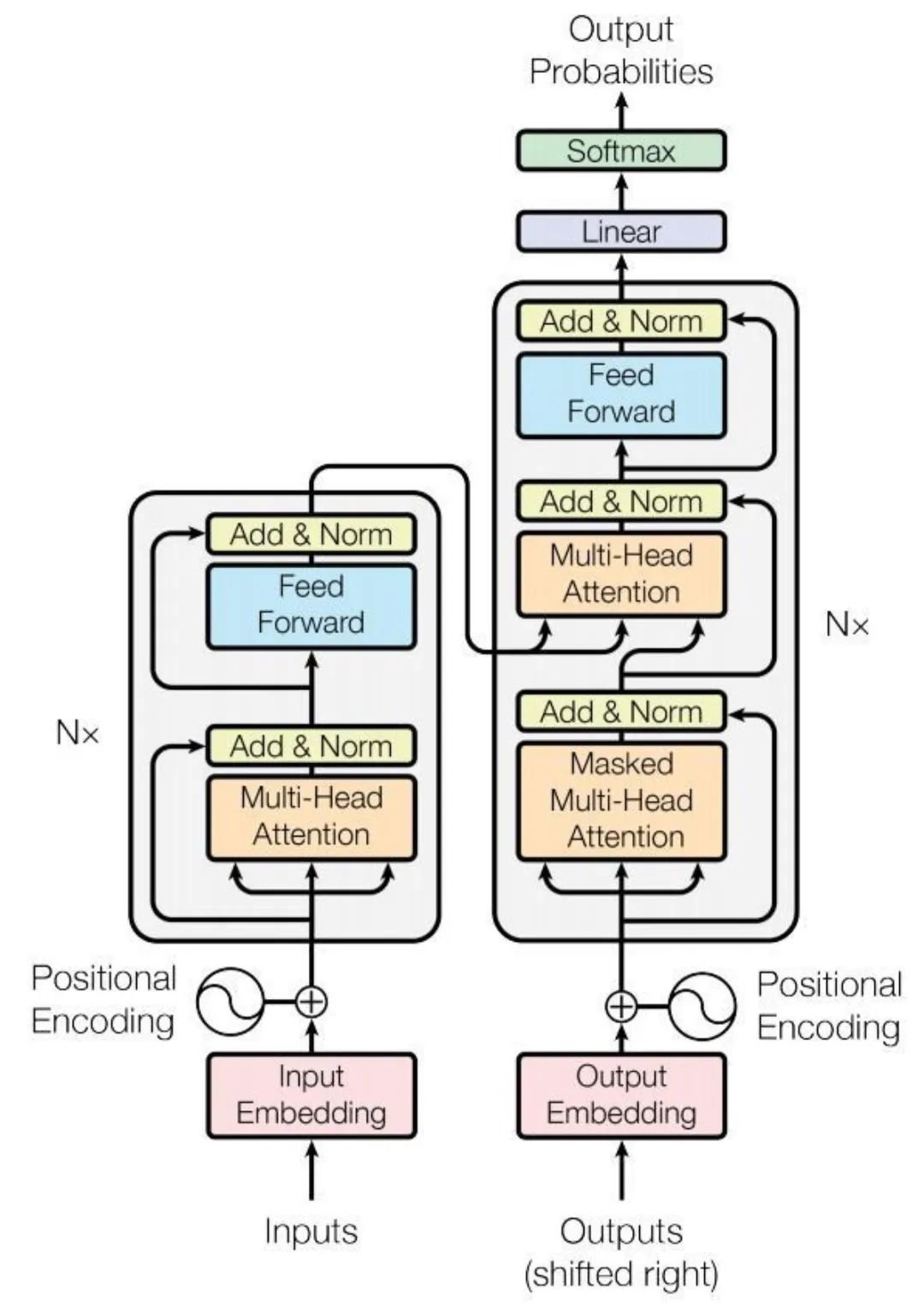
三、微调的核心步骤
1.数据准备
选择与任务相关的数据集。
对数据进行预处理,包括清洗、分词、编码等。
2.选择基础模型
选择一个预训练好的大语言模型,如BERT、GPT-3等。
3.设置微调参数
设定学习率、训练轮次(epochs)、批处理大小(batch size)等超参数。
根据需要设定其他超参数,如权重衰减、梯度剪切等。
4.微调流程
加载预训练的模型和权重。
根据任务需求对模型进行必要的修改,如更改输出层。
选择合适的损失函数和优化器。
使用选定的数据集进行微调训练,包括前向传播、损失计算、反向传播和权重更新。
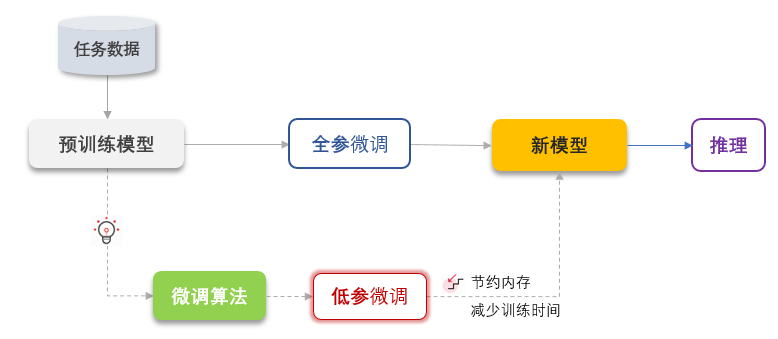
四、微调最佳实践
1.明确任务
在微调大型语言模型的过程中,明确任务是基础步骤。它可以提供清晰的方向,确保模型的强大能力被引导用于实现特定目标,并为性能测量设定明确基准。
2.选择合适的预训练模型
使用预训练模型进行微调至关重要,因为它利用了从大量数据中获得的知识,确保模型不会从零开始学习。这种方法既计算效率高又节省时间。此外,预训练捕捉了通用语言理解,使微调能够专注于领域特定的细节,通常能在专业任务中带来更好的模型性能。
3.设置超参数
超参数是模型训练过程中可调整的变量,对找到适合任务的最优配置至关重要。学习率、批量大小、周期数、权重衰减等是关键的超参数,需要调整以优化模型。
4.评估模型性能
微调完成后,通过测试集评估模型性能。这提供了对模型在未见数据上预期表现的无偏评估。如果模型仍有改进空间,也应考虑迭代优化模型。
要么驾驭AI,要么被AI碾碎
当DeepSeek大模型能写出比80%人类更专业的行业报告,当AI画师的作品横扫国际艺术大赛,这场变革早已不是“狼来了”的寓言。2025年的你,每一个逃避学习的决定,都在为未来失业通知书签名。
记住:在AI时代,没有稳定的工作,只有稳定的能力。今天你读的每一篇技术文档,调试的每一个模型参数,都是在为未来的自己铸造诺亚方舟的船票。
1.AI大模型学习路线汇总

L1阶段-AI及LLM基础
L2阶段-LangChain开发
L3阶段-LlamaIndex开发
L4阶段-AutoGen开发
L5阶段-LLM大模型训练与微调
L6阶段-企业级项目实战
L7阶段-前沿技术扩展
2.AI大模型PDF书籍合集

3.AI大模型视频合集

4.LLM面试题和面经合集

5.AI大模型商业化落地方案

📣朋友们如果有需要的话,可以V扫描下方二维码联系领取~


在这里,我们一起交流AI,学习AI,用AI改变世界。如有AI产品需求,可访问讯飞开放平台,www.xfyun.cn。
更多推荐



 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)