
机器学习--sklearn与模型评估
sklearn是python机器学习的常用库,其中有非常多的方法与数据便于编写机器学习代码。
sklearn工具包
sklearn是python机器学习的常用库,其中有非常多的方法与数据便于编写机器学习代码
1.数据集的下载
在sklearn中使用dataset模块可以调用其中的内置数据集,并下载其中的数据
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original')
得到的数据图像如图:
2.交叉验证
X, y = mnist["data"], mnist["target"]
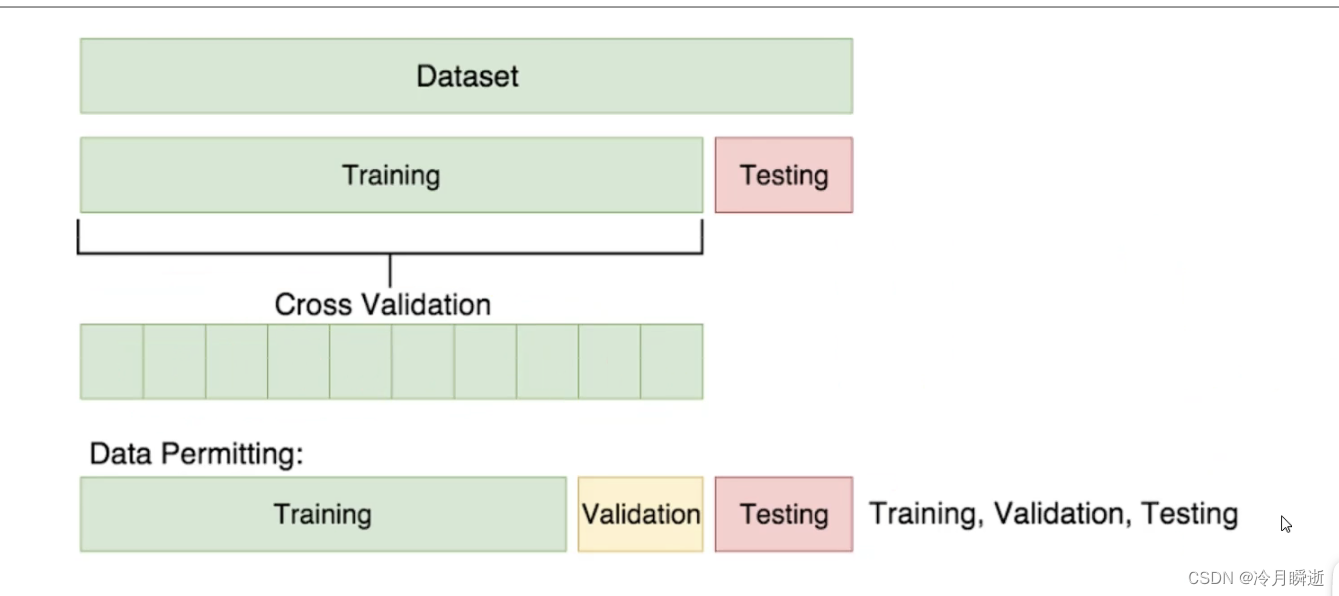
交叉验证即将训练的数据平均分成自己设定的份数(图中为10份),然后在这10份中任取几份作为训练中的训练集,剩下的为验证集,分别得到训练的θ值之后,分别算出预测的值,再对求出的值进行平均处理,得到最终的值。
sklearn梯度下降相关方法
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
y_train_5 = (y_train==5)
y_test_5 = (y_test==5)
y_train_5[:10]
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(max_iter=5,random_state=42)
sgd_clf.fit(X_train,y_train_5)
sgd_clf.predict([X[35000]])
SGDClassifier()方法可以实现梯度下降
fit()方法可以进行训练
predict()方法可以进行预测值的计算
cross_val_score()方法可以得到预测值的结果
StratifiedKFold()方法可以对数据集进行切分
clone()方法可以对数据集进行复制克隆
实现交叉验证:
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
skflods = StratifiedKFold(n_splits=3,random_state=42)
for train_index,test_index in skflods.split(X_train,y_train_5):
clone_clf = clone(sgd_clf)
X_train_folds = X_train[train_index]
y_train_folds = y_train_5[train_index]
X_test_folds = X_train[test_index]
y_test_folds = y_train_5[test_index]
clone_clf.fit(X_train_folds,y_train_folds)
y_pred = clone_clf.predict(X_test_folds)
n_correct = sum(y_pred == y_test_folds)
print(n_correct/len(y_pred))
混淆矩阵
TP(true positives):被检索到的正类
FP(false positives):被检索到的负类
FN(false negatives):未被检索到的负类
TN(true negatives):未被检索到的正类
precision=TP/(TP+FP)
可通过precision_score()求出.
recall=TP/(TP+FN)
可通过recall_score求出
例子:
已知条件:班级总人数100人,其中男生80人,女生20人。
目标:找出所有的女生。
结果:从班级中选择了50人,其中20人是女生,还错误的把30个男生挑选出来了。
得到:TP=20,FP=30,FN=0;TN=50.
混淆矩阵评估函数:
rom sklearn.metrics import confusion_matrix
confusion_matrix(y_train_5,y_train_pred)
其中第一个参数为训练值,第二个参数为预测值
阈值
设定阈值时会对结果产生影响,阈值越大precision值越大,recall值越小
调用decision_function()方法时,可以得到每个实例的分数,然后使用想要的阈值根据这些分数进行预测
可以使用precision_recall_curve函数生成不同的阈值
然后可以根据不同的阈值绘制出precision,recall与阈值的函数曲线
ROC曲线
它与精确度/召回曲线非常相似,但ROC曲线是绘制true positive rate与false positive rate的曲线
要绘制ROC曲线,首先需要使用roc_curve()函数去计算各种阈值的TPR和FPR。
TPR=TP/(TP+FN)
FPR=FP/(FP+TN)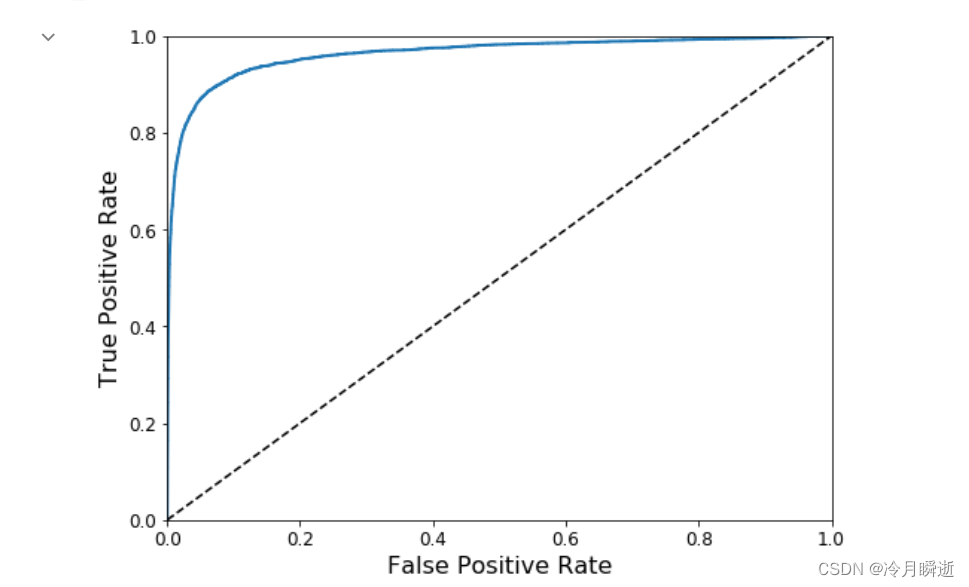
虚线表示纯随机分类器的ROC曲线,一个好的分类器应该尽可能远离该线,接近左上角。
比较分类器的一种方法是测量曲线下面积(AUC)。完美分类器的ROC AUC=1,纯随机AUC=0.5。
本部分主要学习了sklearn工具包、交叉验证、混淆矩阵分类评估、ROC曲线评估
共勉

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)