
【毕业设计】基于机器视觉的建筑工程车量分类 人工智能 深度学习 Python 目标检测 数据集 YOLO
毕业设计选题:建筑工程车辆数据集专注于识别四种主要类型的重型设备:挖掘机(excavator)、装载机(loader)、运输车(moxy)和压路机(roller)。数据集通过在真实施工环境中采集图像,确保了样本的多样性和代表性,为深度学习模型的训练提供了坚实基础。每种车辆类别均经过精确标注,确保每个边界框准确无误,以便于后续的模型训练和评估。该数据集的构建旨在提升建筑工程管理的智能化水平,通过高效
一、背景意义
随着城市化进程的加快和基础设施建设的不断发展,建筑工程车辆在施工现场的使用日益普遍。准确识别和管理这些车辆对于提升施工效率、保障安全和优化资源配置至关重要。然而,传统的人工监控方式存在效率低、误判率高等问题,亟需引入先进的技术手段以提高管理水平。通过对建筑工程车辆的实时识别,管理人员可以更好地监控施工进度和资源使用,优化调度,提高整体工作效率。
二、数据集
2.1数据采集
数据采集是创建建筑工程车辆识别数据集的第一步,主要包括以下几个步骤:
-
确定数据来源:选择适合的图像来源,如建筑工地的实时监控视频、在线图像库、社交媒体平台以及专业的工程设备网站。这些来源能够提供多样化的建筑工程车辆图像。
-
收集图像:通过拍摄或下载的方式获取包含不同类型建筑工程车辆(如挖掘机、装载机、运输车和压路机)的图像。确保所采集的图像涵盖多种品牌、型号和环境条件,以增强数据集的代表性。
-
保证多样性:在采集过程中,注意覆盖不同的光照条件、拍摄角度、背景和天气情况,以提高模型的泛化能力,使其能够适应各种实际施工场景。
在收集到大量图片后,对这些原始数据进行了清洗和筛选:
-
去除低质量图片:一些图像模糊、分辨率过低或者有其他物体干扰的图片被剔除掉。确保每张图片都能清晰地展示XX类特征是数据质量的关键。
-
统一格式:将所有图片转换为统一的JPEG格式,并将图片的分辨率统一到256x256像素,这样可以在后续的训练中减少不必要的图像缩放操作,保证数据的一致性。
-
分类整理:将所有图片按照类别进行分类,分别放入对应文件夹中。每个类别的文件夹下严格只包含对应的图片,避免数据集出现混乱。
2.2数据标注
收集的数据通常是未经处理的原始数据,需要进行标注以便模型训练。数据标注的方式取决于任务的类型:
- 分类任务:为每个数据样本分配类别标签。
- 目标检测:标注图像中的每个目标,通常使用边界框。
- 语义分割:为每个像素分配一个类别标签。
在使用LabelImg标注建筑工程车辆数据集的过程中,标注者需要对每张图像中的挖掘机、装载机、运输车和压路机等车辆进行仔细识别和框选。这一过程面临着高工作量和复杂性,因数据集中包含数千张图像,每张图像的标注时间从几分钟到十几分钟不等。标注者必须在复杂的工地环境中准确判断,并确保每个边界框的准确性。此外,标注完成后还需进行复核和修正,以确保标注的一致性和质量。尽管挑战重重,但高质量的标注对后续模型训练和建筑工程车辆识别的准确性至关重要。

包含4000张建筑工地车辆图片,数据集中包含以下几种类别
- 挖掘机:用于土方工程和挖掘作业的重型机械。
装载机:用于搬运和装载物料的多功能机械。
莫克斯:一种特殊的全地形运输车辆,适用于恶劣环境下的物料运输。
压路机:用于压实土壤和沥青的施工设备。
2.3数据预处理
数据预处理是为模型训练准备数据的关键步骤,主要包括以下内容:
- 图像格式转换:将收集到的图像转换为统一的格式(如JPEG或PNG),并调整为相同的尺寸,以便于模型输入。
- 数据增强:通过旋转、缩放、翻转、裁剪等方式对图像进行数据增强,增加样本数量,提高模型的鲁棒性和泛化能力。
- 归一化处理:对图像像素值进行归一化处理,将其缩放到0到1之间,以加速模型训练过程,确保训练过程的稳定性。
- 划分数据集:将数据集划分为训练集、验证集和测试集,以确保每个集的样本能够代表整体数据分布,便于后续模型训练和评估。
在使用深度学习进行训练任务时,通常需要将数据集划分为训练集、验证集和测试集。这种划分是为了评估模型的性能并确保模型的泛化能力。数据集划分为训练集、验证集和测试集的比例。常见的比例为 70% 训练集、20% 验证集和 10% 测试集,也就是7:2:1。数据集已经按照标准比例进行划分。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
算法采用邻接和缩放网络(AZ-Net)进行自适应目标搜索。该网络能够根据图像内容智能地删减不相关的大候选框区域,尤其在图像中存在少量小目标时,可有效提高检测效率;而在大目标图像的情况下,则会退回到依赖少量候选区域框的检测策略。通过这种方式,AZ-Net生成的候选区域集合将被输入到Fast R-CNN检测器中进行进一步的识别和定位。
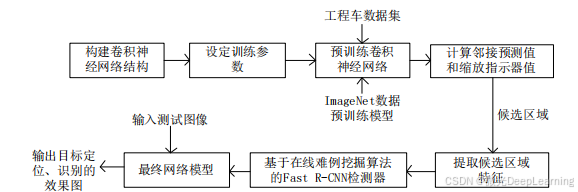
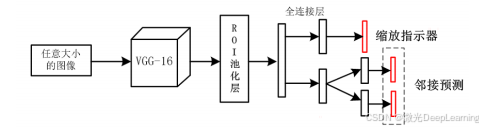
数据集中存在大量简单样本和少量难例,可能导致训练过程中的类别不平衡问题。引入了在线难例挖掘(OHEM)算法,自动挑选难例以提升训练效率。该算法与主干网络VGG-16结合,首先对任意大小的图像进行处理,然后通过邻接和缩放网络计算缩放指示器和邻接预测值,从而自适应生成候选区域。在检测阶段,候选区域将映射到卷积特征图上,并分别由只读ROI网络和标准ROI网络处理,前者负责挑选难例样本以反馈训练,后者则输出最终的检测识别结果。这种方法不仅提高了目标检测的准确性,还增强了算法对不同场景的适应能力。
3.2模型训练
在数据集划分和准备完成后,开发一个建筑工程车辆识别系统的YOLO(You Only Look Once)项目通常包括几个关键步骤。
首先,环境配置是开发YOLO项目的第一步。确保所有必要的库和工具都已正确安装,这一过程涉及创建一个新的虚拟环境,以避免与其他项目的依赖冲突。安装PyTorch、OpenCV和YOLO相关库是至关重要的,因为这些库将为模型训练和推理提供支持。通过命令行创建并激活虚拟环境后,可以使用pip安装所需的库,以确保YOLO项目能够顺利运行。
# 创建并激活虚拟环境
python -m venv yolov5_env
source yolov5_env/bin/activate # Linux/Mac
# yolov5_env\Scripts\activate # Windows
# 安装必要的库
pip install torch torchvision
pip install opencv-python
pip install matplotlib
pip install pandas
pip install tqdm
完成环境配置后,接下来是进行模型训练。这一过程需要准备好数据集配置文件,设置超参数,并选择合适的预训练模型。训练的目标是通过不断调整权重,最小化损失函数,从而提高模型在特定任务上的准确性。通过调用YOLO的训练函数,可以指定使用的数据集、训练图像大小和其他参数。这一步骤至关重要,因为训练的效果将直接影响模型的性能。
import torch
from yolov5 import train
# 设置训练参数
train.run(
data='data.yaml', # 数据集配置文件,包含类别和路径信息
imgsz=640, # 输入图像大小,通常为320, 640, 或其他值
batch=16, # 每批次的图像数量,影响训练速度与内存使用
epochs=50, # 训练的轮数,决定模型的学习时间
weights='yolov5s.pt', # 使用的预训练模型
workers=4 # 数据加载线程数,提高训练效率
)
训练完成后,必须对模型的性能进行评估。这一过程通常通过在验证集上测试模型的表现来实现,评估指标包括准确率、召回率和F1分数等。使用YOLO提供的评估函数,可以加载训练好的模型权重,并在验证集上进行推理,生成评估报告。这一环节至关重要,有助于了解模型在不同类别上的识别能力及其鲁棒性。
from yolov5 import val
# 评估模型
val.run(
weights='runs/train/exp/weights/best.pt', # 最佳模型权重
data='data.yaml', # 数据集配置文件
imgsz=640, # 输入图像大小
conf_thres=0.25, # 置信度阈值,控制检测结果的置信度
iou_thres=0.45 # IOU阈值,用于评估检测框的重叠度
)
一旦模型经过训练和评估,接下来是使用训练好的模型进行推理,对新图像进行检测,并可视化结果。此过程验证模型的实际效果,并展示其能力。通过读取待检测的图像,模型会返回检测结果,并将目标框选出来。这个步骤不仅帮助开发者理解模型的实际表现,还可以为后续的优化提供依据。
import cv2
import torch
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='runs/train/exp/weights/best.pt')
# 读取图像并进行推理
img = cv2.imread('test_image.jpg')
results = model(img)
# 显示检测结果
results.show() # 在窗口中显示检测结果
results.save('output') # 将检测结果保存到output文件夹
最后一步是将训练好的模型导出为适合部署的格式,以便在实际应用中使用。导出后的模型可以在不同的环境中运行,如服务器、移动设备或嵌入式系统。根据需求,使用YOLO的导出功能,可以将模型导出为ONNX、TensorFlow格式或TorchScript格式,以确保其在目标环境中的可用性和性能。
# 导出模型为ONNX格式
model.export(format='onnx') # 可以选择导出为其他格式,如TensorFlow
# 或者保存为TorchScript格式
torchscript_model = torch.jit.trace(model, torch.randn(1, 3, 640, 640)) # 示例输入
torchscript_model.save('yolo_model.pt') # 保存TorchScript模型四、总结
随着城市化进程的加速,建筑工程车辆的使用日益频繁,准确识别和管理这些车辆变得尤为重要。建筑工程车辆识别系统不仅能帮助管理者实时监控施工进度,还能为后续的数据分析和决策提供重要依据,推动行业的数字化转型和智能化发展。通过实时监控和识别,提升施工效率,优化资源配置,并保障施工安全。系统采用高效的YOLO模型进行训练,能够在复杂的施工环境中快速、准确地检测车辆,满足现代建筑行业对智能化管理的需求。

在这里,我们一起交流AI,学习AI,用AI改变世界。如有AI产品需求,可访问讯飞开放平台,www.xfyun.cn。
更多推荐



 9
9 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)