
机器学习——k-近邻算法、K-均值算法、PCA、异常检测算法、上限分析
K Nearest Neighbor算法⼜叫KNN算法,这个算法是机器学习⾥⾯⼀个⽐较经典的算法如果⼀个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的⼤多数属于某⼀个类别,则该样本也属于这个类别。d=∑i=1n(x1i−x2i)2d = \sqrt{\sum_{i=1}^n(x_{1i}- x_{2i})^2}d=∑i=1n(x1i−x2i)2二、K-均值算法(K Means
一、K-近邻算法(KNN)概念
K Nearest Neighbor算法⼜叫KNN算法,这个算法是机器学习⾥⾯⼀个⽐较经典的算法
定义
如果⼀个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的⼤多数属于某⼀个类别,则该样本也属于这个类别。
距离公式(欧式距离):
d = ∑ i = 1 n ( x 1 i − x 2 i ) 2 d = \sqrt{\sum_{i=1}^n(x_{1i}- x_{2i})^2} d=∑i=1n(x1i−x2i)2
from sklearn.neighbors import KNeighborsClassifier
estimator = KNeighborsClassifier(n_neighbors=1)
# 使⽤fit⽅法进⾏训练
estimator.fit(x, y)
estimator.predict([[1]])
二、K-均值算法(K Means)
K-均值算法是一种聚类算法,同时也是非监督学习的算法。它首先随机生成几个聚类中心,然后在每次递归时实现簇分配(通过聚类中心与点的最近距离)和移动聚类中心(该簇所有点的平均值)
对于开始随机生成的聚类中心而言,我们一般会随机选择样本里面的几个数据来当作聚类中心。
我们还可能遇到局部最优的情况,解决的方式是多运行几次K-均值算法并记录每次的cost函数值,最终选择最小的cost值的那组θ
如何正确的选择聚类的数量K?
我们可以通过肘部法则来手动的选择聚类数量K,不过它并不是每次都可以成功的运行,所以最终我们大多数还是通过经验和其实际需求来选择K的大小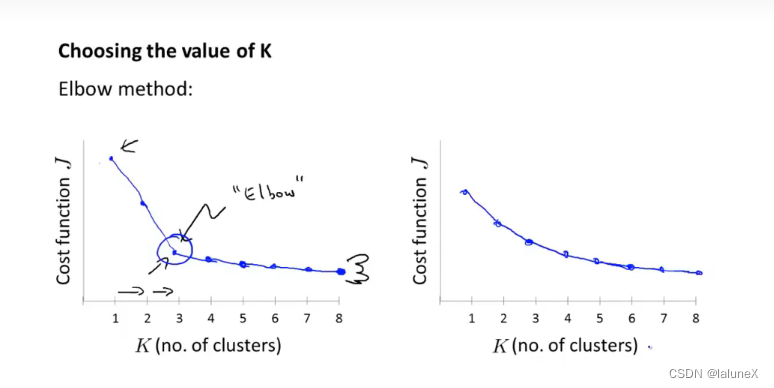
三、主成分分析(Principal Component Analysis)
PCA主要完成的工作是它会找到一个低维度,然后再将数据投影到该维度上面,以便最小化所有样本到该低维度的投影误差的平方,最终达到降维的效果。
而降维可以使提高算法的运算速度和到达压缩数据的目的
不过在进行PCA之前一般是要先进行均值归一化和特征规范化
若要使用PCA进行降维也是在训练集上运行,不可在交叉验证集或测试集上运行
为了选择压缩后的维度K,我们应该要求方差保留的百分比大于等于0.99
一般我们使用正则化来解决过拟合情况,而不用PCA,因为它省略掉了一些关键的信息,如y
四、异常检测算法(Anomaly detection)
异常检测算法是指通过对数据建立概率模型来识别数据中的“异常点”
若异常样本多则选择异常检测算法;若异常样本和正常样本都很多则选择监督学习算法
五、上限分析-ceiling analysis
上限分析一般存在于流水线,它的目的是为了分析出该流水线中哪一个模块更值得我们花更多的精力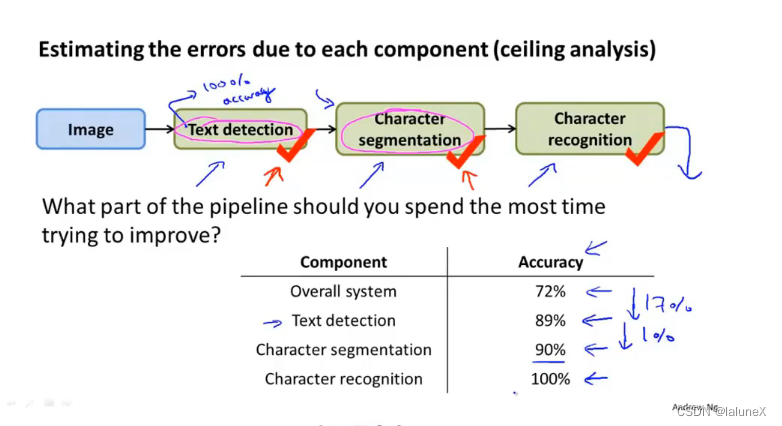
首先关注这个机器学习流程中的第一个模块文字检测,然后人为地告诉算法每一个测试样本中什么地方出现了文字,即100%正确地检测出图片中的文字信息。然后下来的几个模块也就是如法炮制。所以进行上限分析的一个好处是知道了如果对每一个模块进行改善 它们各自的上升空间是多大。
例如上图,我们应该把更多的精力放在文本检测和和字母识别上面,而不应该是放在字母分割上面
本文只用于个人学习与记录,侵权立删

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 2
2 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)