
大模型时代下做科研的四个思路【论文精读·52】
大家好,上个礼拜FacebookMetaAI刚刚开源了他们自己的一个语言的大模型,叫做LLAMA,这个LLAMA的模型有65billing的参数,效果自然是不错的。他们的目的也是想让这个大模型更加的亲民,能够让更多人拿到这个模型的参数,有可能就能直接应用到他们的领域中去了,是一件非常好的事儿。他们分别开源了四个模型,从小到大就从有这个70亿、130亿、330亿和650亿参数量,这四个模型。
目录
1 使用parameter efficient finetuning去做模型的训练
2 能不做Pretraining就不做Pretraining,能借助已有的东西,那就尽量借助已有的东西
大家好,上个礼拜FacebookMetaAI刚刚开源了他们自己的一个语言的大模型,叫做LLAMA,这个LLAMA的模型有65billing的参数,效果自然是不错的。他们的目的也是想让这个大模型更加的亲民,能够让更多人拿到这个模型的参数,有可能就能直接应用到他们的领域中去了,是一件非常好的事儿。他们分别开源了四个模型,从小到大就从有这个70亿、130亿、330亿和650亿参数量,这四个模型。但这里面比较有意思的一个点,就是他们虽然管自己叫这个large language model LLM但事实上在这篇博文里,他们管他们自己的LLAMA叫做smaller models,就是他认为他们自己是小模型。这个其实就看和谁比了,如果和GPT3175billion比,或者和Google的palm这个540billion比,那这个66billion确实是小了一个数量级,但其实66billion已经比我们平时用的大多数模型都要大很多倍了,基本上很少有人能够去训练这些上10亿参数的模型,就更不用说产品部署了。这些大模型对于大部分研究者来说其实是可望而不可即的,那自然语言处理那边,我们已经知道大模型已经是主流,模型越对越大了那计算机视觉这边肯定也不甘落后,也就在两周前,这个Google又推翻了自己之前最大的这个vision transformer,又推出了更大的这个VIT,有22billion的参数,那现在视觉也算是有了自己的这个大模型了。之前不论是Google,他们自己推出的这个vit-g就有两billion,还是说他们这个pali,还有就他这里写的这个chen2022这个多模态的工作里提出的vit-e,还有这个4billion的模型都是刚上10亿,然后这回这个VIT一下就到了220亿。所以终于能跟这个language这边保持差不多的这个模型大小了,那这个效果自然也是不用说,各种各样的视觉任务都能做,而且效果都很好。那眼看这个科研进步的速度越来越快,不仅每天可能都有这种立意比较新的这个论文出来,而且之前的模型也是越做越大,现在这些模型都成了系列,动不动就是V1、V2、V3,所以是一代比一代大,一代比一代强,所以我看很多小伙伴经常在这个视频下面留言,而现在这个模型方向已经卷的都玩不动了,还有什么别的方向可以做呢?还有同学可能说现在很多工作都是大力出奇迹,那如果我没有这个大力,我该怎么出奇迹?或者还有很多同学就问,马上要开题了但是实验室又没有那么多计算资源,该怎么样选择一个合适的研究方向呢?那其实面对进步如此之快、竞争如此白热化的这个科研领域来说,你说你不慌肯定是假的。
那今天我就抛砖引玉用自己参与过的一些不那么需要计算资源的项目来跟大家讨论一下,如何在有限的计算资源内做出一遍让自己比较满意的工作,如果大家有别的更好的想法,也欢迎在视频下方留言,大家一起交流,一起进步因为我做的方向一般比较偏视觉或者多模态,所以今天要分享的工作,也都是偏这些领域的。那今天主要会提到四个方向:
- 第一个方向就是因为你没有那么多的计算资源,所以你肯定是要往这个efficiency上去做的,所以这也是最直白的一个方式,就是哪里慢我就让它哪里快起来,哪里太heavy了,我就把它变得lightweight一些,总之就是让所有的这些方法变得更efficient一点。在这里我们举的一个例子就是用最近比较火的这个PEFT的这个概念,就是parameter efficient finetuning去如何做这个大模型的微调
- 那第二个方向就是能不做Pretraining就不做Pretraining,能借助已有的东西,那就尽量借助已有的东西,比如说别人已经预训练好的模型,那不用白不用,那clip出来之后就有那么多那么多几百、上千篇论文出来,直接就调用clip的模型去做各种非常有意思的应用,这些都很有impact。同时可以选择那些比较新的研究方向,这样能避免有很多的这个竞争者,而且也不用天天想着如何去刷榜,能够全心全意投入到自己喜欢的科研工作之中。
- 那第三个方向,就是尽量做一些通用的,能够Plugandplay,就是即插即用的这种模块儿。那这个模块儿其实不光是说模型上的这种模块儿,它有可能也是一个目标函数,一个新的loss,它有可能也是一个data competition的方法,总之就是一个很简单的东西,但是能够应用到各种领域的。那这个方法的好处就是说你只需要选很多很多的baseline,然后在一个你能承受的这个setting之下去做这个实验,因为它是公平对比,所以这就已经足可以说明你方法的有效性了,而不需要你真的在特别大的数据集上,用特别大的模型去证明你的有效性。
- 那最后一个方向就是比如说构建一个数据集,然后或者做一些以分析为主的文章,或者写一篇综述论文那这个方向是最不需要计算资源的,但同样非常有这个影响力因为你给整个领域都提供了一些非常新颖的见解,同时也能让你自己对这个领域的理解加深一些。
1 使用parameter efficient finetuning去做模型的训练
所以上这些都是我认为比较有用,而且不那么耗费资源的研究方向那我们先来看一下今天第一篇要讲的工作,就是如何使用parameter efficient finetuning去做这个模型的训练。这个是我们最近刚中的一篇iclr23的论文,叫做AIM: ADAPTING IMAGE MODELS FOR EFFICIENTVIDEO ACTION RECOGNITION,是用来做这个视频动作识别,也就视频理解的一个工作。视频理解其实我们之前也讲过很多期了,从最开始的双流网络到后面的这个I3D网络,后面又讲了视频理解上,视频理解下,基本是把最近几年比较耳熟能详的视频理解的工作都提了一下。
那我们先来看一下这篇文章的图一,其实就是回顾一下之前的那些视频理解的工作都是怎么做的,
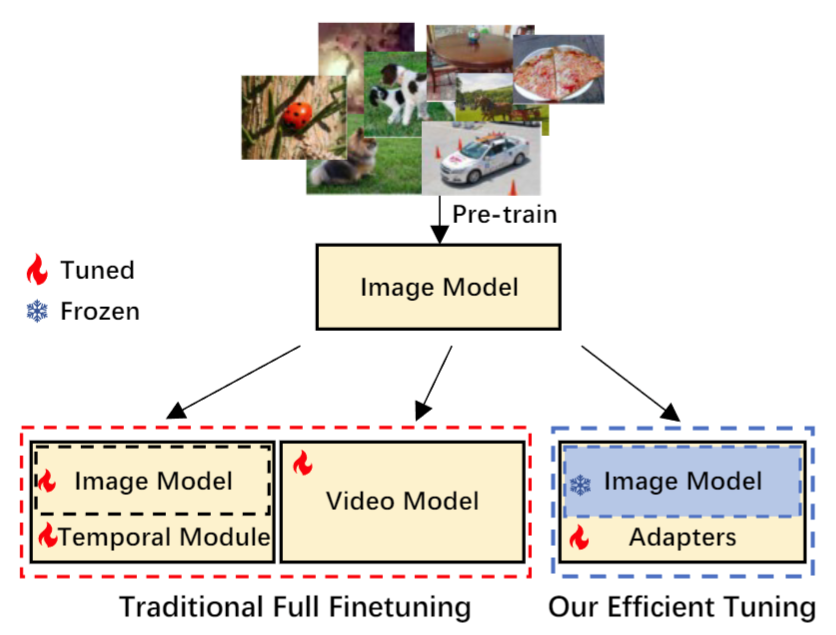
其实简单一点,粗略一点来分类的话。大部分之前的工作都可以被划分为两类
一类就是这个时间上和空间上的处理尽量分开来做,另外一类就是时空一起来做。那如果画的这张图里来表示,就往往是说我们先有一个很大的这个图像的数据集,我们先去做一个预训练,得到一个image的模型,比如说这里就是一个,比如说在imagenet1k上训练过的一个rise50的模型,或者说是在一个imagenet21K上训练的一个VIT或者swing的模型。总之这里面就是一个已经预训练好的一个图像的模型,那接下来要么就是你在这个已经有的这个图像模型之上去单独的增加一些这个时序处理的模块,比如说在TSN里他就把这个视频p成几段,然后最后去把这些视频抽出来的特征做一下加权平均那在TSM里,作者就是把这个模型的特征在这个channel维度上进行来回的这个shift,从而去模拟这个时序建模,那或者说在最近的使用Transformer来做视频理解的工作里,像timesformer,那就是先做timeattention,然后再做这个specialattention,就把这个specialtemporal劈开来做。所以大致上就可以总结为是在一个已有的图像模型之上,加了一些这个时序处理的模块
那另外一系列工作就是这个时间空间的特征,我要一起学。那当然这里面主要就是这个3D网络,比如我们之前讲过的这个I3D或者说像Transformer时代的这个video swing,那就把2D的这个shiftedwindow变成了3D的shiftwindow总之输入是3D的,模型也是3D的,是一个joint modeling的过程
所以大致就分为这两类。那之前的这些方法虽然说效果上都非常的好但是他们都有一个小小的问题,就是这个计算代价实在是太大,因为他们的这些模型全都是需要fullfinetuning的,就是整个模型所有的参数都要拿下来,在这个视频数据集上去做这个finetuning但是本身视频数据集就比较大,这个数据的io一般又有bottleneck,然后这些模型本身也比较大,所以这个训练的cos非常昂贵,一般左边这种时间和空间分开的方法还好,可能就是说如果你有一台8卡机,可能就是三四天、四五天就能完成一个模型的训练,当然如果你的backbone特别大的话,可能也需要一周或者10天的时间,总之稍微能轻量一些。但是对于这种joint的video model比如说大部分的3D网络或者这个videoswing的模型,他们的训练时间就非常感人了,当然这些模型还好,因为他们利用了这个预训练的这个图像模型,所以说白了他们更多的还是在做一个finetuning那如果像视频领域里有一些模型是从头开始训练,纯formScratch那这些模型就需要更长的时间了啊,比如说像maskfeet或者videoMae这些最近的自监督的这个视频学习方法,他们的训练代讲都是以周为计算单位的,一般情况下想要复现他们的模型都很困难,更不要说是提出什么新模型去比他效果更好了。
所以我自己一直想做的一个方向就是如何把这个视频理解做得更亲民,然后有更多的玩家,然后可以让这个领域更加蓬勃的发展,所以之前在组里做过这个gluon CV,视频里的开源,也写过一篇综述的论文,最近也准备在这个视频数据集上下功夫。但这篇文章主要的这个研究动机还是来自于CLIP,因为当时在20年的时候,这个对比学习很火,我自己也很痴迷于对比学习,所以一直想的就是能不能做一个很大的这个视频数据集,然后在上面用纯视觉的方法对比学习,然后训练出来一个很好的这个视频的特征。但是后来正在做的过程中,CLIP21年年初的时候就出来了,当时一看这个效果确实是太厉害了,它里面也做了这个视频动作识别UCF101和这个connect700的这两个数据集,直接zeroshot效果就非常好。虽然说这两个数据集比较specialheavy,之前我们也说过,就是这两个数据集比较偏重于这个物体的识别和这个背景的识别,就是说他不太看重这个时序性,就如果他看到一个视频里有一个篮球,那他就说十有八九这个动作就是打篮球了,他不太会是别的动作。所以这种视频数据集就是一般用这个图像的模型,也能做得很好所以这就解释了CLIP作为一个图像模型,它也能做这种视频动作识别的任务,但即使如此CLIP的效果还是好的出奇,也给了我一些启发,我主要想的一个问题就是,到底这个已经训练好的这个图像模型需不需要再finetuning?也就是这里面这个image model需不需要再去微调它?这里面有几个原因首先第一个原因就是CLIP已经证明了,就是即使Zeroshot它的效果就很好Zeroshot就是模型不变,我直接在各个数据集上所推理,所以它已经部分验证了这个假设,就是如果一个已经训练得很好的一个图像模型,我们可以直接从它里面抽,这个视觉的特征应该是比较具有泛化性,而且随着这个时代的进步,随着大家都在讨论这个foundation model我当时就在想以后的这个视觉模型,这个视觉的foundationmodel肯定是越来越好,越来越大了,那也就意味着它里面抽出来的特征肯定是越来越具有泛化性,而且越来越有效的。所以从有效性的这个方面来讲,当有了一个极其强大的已经预训练好的这个图像模型之后,我们可能就不需要finetuning这个部分。那另外一个原因也很好理解,就是为了防止这种灾难性遗忘,就是说如果你已经训练好了一个特别大的模型,它的参数量也非常多,那这个时候如果你的这个下游数据集没有很好的数据,或者说没有很多的数据,你硬要去finetuning这个大模型的话,往往你是finetuning不好的,要么就是直接overfit了,整个模型就不能用了,要么呢就是即使你能在你现在这个下游任务上表现得很好,但是它有了灾难性遗忘,就是它之前的很多大模型有的这种特性全都就丢失了,它的泛化性可能也丢失了,这也是得不偿失的一件事情。
所以说从这两个主要的方面去考虑,我当时就很想尝试这条路,就是说当拿来一个非常大、非常有效的这个image model之后,我能不能直接就把它的这个模型参数锁住,然后在它上面加一些这种时序处理的模块,或者加一些新的这个目标函数啊?综之就是通过修改周边的方式来让这个模型具备这个时序建模的能力,从而让一个图像模型能直接做这个视频理解的任务,而不需要从头再去训练这么一个视频模型,省时省力。所以21年的时候其实就已经写了这么一个proposal,不过当时也没有想好什么可以用的这个很好的周边改动的方式,而且手头上还有几个别的正在进行的项目,所以就迟迟没有动手做这个工作,一直到22年年初,就是从21年年底开始很多基于Prompt工作,然后到22年初这个visual prompttuning VPT的出现,再让我感觉到这个方向如果再不做就来不及了。所以就赶紧去学习了一下这个prompt tuning以及这个prompter efficient finetuning这一系列的各种方法,好在其实这个prompterefficientfinetuning它一点儿都不难,不论是形式上还是理解起来都不难。
Adapter和prompt tuning Adapter
我们接下来就可以稍微过一下其中两个比较普遍的方法,Adapter和这个prompt tuning Adapter最早来自于这篇2019年的论文,最早的时候就是用来做NLP。最近其实我们可以看到很多视觉这边或者多模态这边用的这个技术都是从NLP那边过来,原因就是因为大家都用transformer做backbone了。所以说那之前在NLP那边工作的一些方法,大概率在这边也是能work的,所以说就能很好的迁移过来,比如说这些parameter efficient finetuning的技术,或者说最近比较火的这个incontext learning,还有InstructGPT里那个RLHF,这些基于reinforcement learning的方法都会快速的被运用到视觉里面,而且我觉得以这个视觉这个卷的速度。很快,这个视觉的community就能反哺回这个NLP community了。
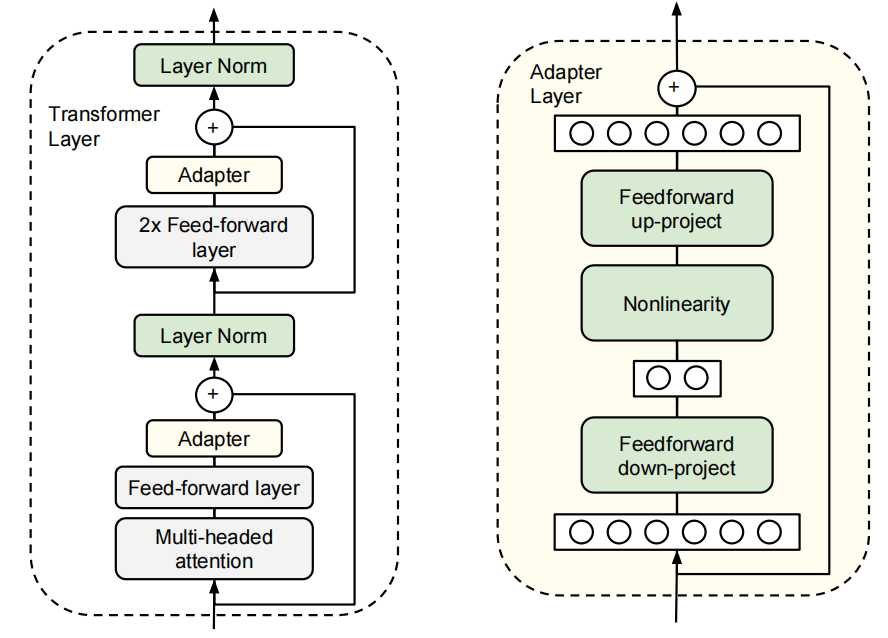
那Adapter究竟是什么呢啊?其实Adapter很简单这是一个下采样的FC层,所以说这里你看这个feature从多变少,然后再过一层这个非线性的激活层,然后再经历一层feed forward up project,就是一个上层硬的FC层,然后就结束了。好,当然这里还有一个residual connection,这个其实就是Adapter layer,它就像一个即插即用的模块一样,可以插到这个consumerlayer里的任何一个地方。那像2019年这篇工作的时候,它就是先在这个attention后面加了一层Adapter,然后在这个MLP后面又加了一个Adapter。所以就是一个transferblock里面它加了两层Adapter,别的其实可能就没什么好讲的了。
然后加这个Adapter的作用,以及为什么叫它parameterefficientfinetuning?其实就是说原来的这个大模型,原来这个已经训练好的transformer它是不动的,所以也就是这里面这些灰色的,这个feedforward类MLP层和这个Multiheadattention,它全都是锁住的,它在模型微调的过程中是完全没有gradientupdate的,只有这些新添加的Adapter层在不停的学习,那因为Adapter层我们也看到了,它里面就是两层FC,而且也有这个下采样的过程,所以说它的参数量是非常之少的。尤其是跟那些动辄就几b、几十b或者几百b的这个language模型比新添加的depter就这几million的这个新参数量。其实就可以完全忽略不计了。比如说在最新的一个path的方法Lora这个论文的摘要里,他就写如果你在一个超大的模型里,比如说GPT3175B的模型里使用这个Lora,那其实最后需要训练的这个模型参数只是原来模型参数的1/10,000。所以说是这个可训练的这个模型参数量的节省是非常impressive,但说白了其实我们看这个Adapter,它其实就跟CV之前这个2018年CVPR的一篇论文啊Seenetsqueeze,anexcitationnetwork,triggerchannelattentionasyouface.非常相近了,SEnet里也是一层下采样,上采样,而中间有一个激活层,所以其实很多方法之间都是有共通性的。
prompt tuning
那接下来就说prompttuning,prompt其实我们之前在讲CLIP的时候就说过,这里我们再借用这个CoOp这篇论文里的这个图一再回顾一下这个prompt

那具体来说prompt就是一个提示,就是你给模型一个提示,让模型去做你想让他做的事情。啊那如果拿CLIP这个模型来举例,就是说我现在有一个图片,我想去对这个图片进行分类,那我怎么去给这个prompt?最简单的方式就是说我把我想要的这个class这些类别名称,我都给这个模型一个一个给他,看最后哪个这个文字和这个图片的这个相似度最高,我们就说这个文字应该大概率就是这个图片所描述的物体了。
那prompttuning,这个tuning体现在哪呢?就是说我这个prompt可以各种各样的调,它有可能对最后这个性能影响非常之大。比如在coop这篇论文里,我们来看第一个例子,就这个Caltech101里的一个图片,这是应该是一个飞机,你如果用这个prompt说,aclass就是一个飞机,它其实准确率非常高,有82。那如果你像CLIP里那个默认的用的就是aphotoof飞机,那其实它的准确率反而还下降了。然后更神奇的是,如果你给这个photoof后面再加一个a—— a photo of 飞机,它一下这个准确率就从80提到86了,就非常匪夷所思。
所以说prompttuning在去年之所以被吹得那么火,也是因为不论是在分类任务里,还是在这些图像生成的任务里,这个prompttuning对最后的这个性能影响是非常非常巨大,你最后能否得到你想要的那个结果,很大程度上取决于你有没有选择一个很好的prompt。
但是这里其实就有个问题,就是之前你这种手工写的prompt,其实都叫hardprompt,就是一旦写死就写死了,就不能动也不能学,啊比如说这里面后面写这种flowerphotoofclass,或者这个photoof什么classtypeofflower?就是你可以随便写,但是这种需要你有一些先验知识,但我们并不是总有这个先验知识的,而且我们也不知道这些先验知识到底是有用还是没用。所以这个时候大家肯定就开始想,既然我们是深度学习时代,那万物都可学习,那我们来学这个prompt不就行了吗?所以说这也就是Coop这篇文章的想法,就是我把这个hardprompt变成softprompt,我去学习它,那具体来说就是它有一个可学习的这个向量![]() ,就是这是一个Learnable的Vector,其实就跟DETR里的那个learnablequery都一样,它就是一个可学习的一个向量。然后在模型的训练过程中,整个模型我是锁住不动的,我只根据最后这个loss去调整我这个prompt,最后我就希望我学到这个prompt能够泛化到各种各样的情形里去,从而我就不用手动的去每次写这个prompt。
,就是这是一个Learnable的Vector,其实就跟DETR里的那个learnablequery都一样,它就是一个可学习的一个向量。然后在模型的训练过程中,整个模型我是锁住不动的,我只根据最后这个loss去调整我这个prompt,最后我就希望我学到这个prompt能够泛化到各种各样的情形里去,从而我就不用手动的去每次写这个prompt。
那如果想再了解的清楚一点,我们来看后面它这个总览图
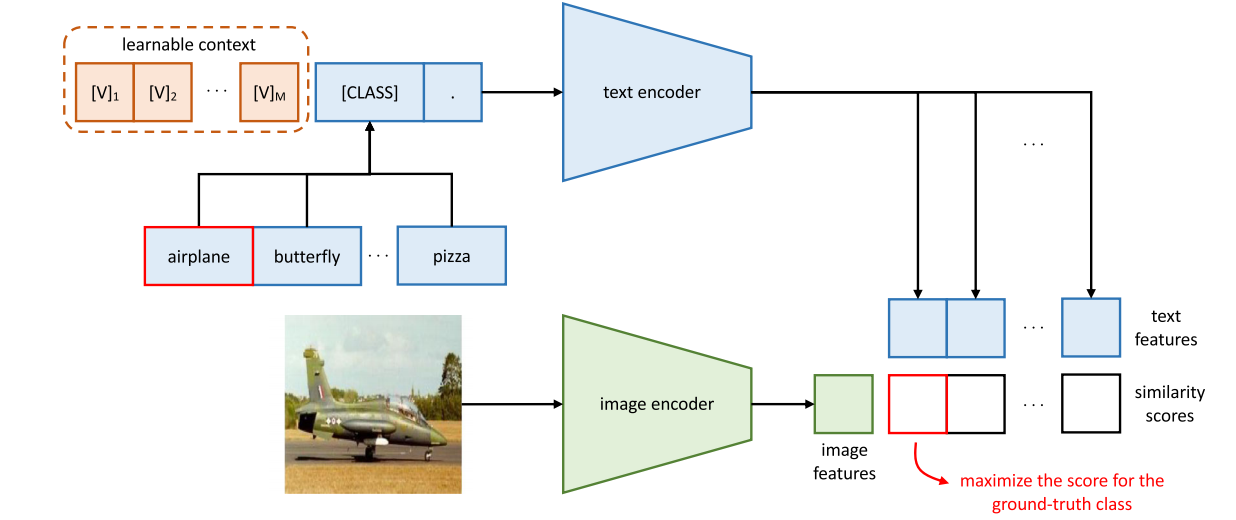
其实就跟CLIP模型之前在做推理的时候画出来是一模一样,上面是这个文本的分支,一个prompt进这个文本编码器,然后得到很多这个文本特征,图像进这个图像编码器得到一个图像特征,然后这个图像特征和这些文本特征去做相似度,然后最后看哪个最高我选哪个,但是这里跟这个CLIP模型在做推理时候的区别就在于, 这里其实是在训练的。文本端的输入不再是固定的this is a photo of什么class了,而是一个可以学习的learnable的context。所以这也就是他们这个文章的起名就是context optimization,就它主要优化的是这个context是前面这个prompt这个learnable的Vector而不是这个模型本身,所以就通过这种方式——就是把这个原来的模型都锁住,只学习prompt这种方式,能够大幅度的降低这个计算量,而且还能帮我们在transferlearning的时候学到一个很好的这个prompt,从而避免我们在做下游任务的时候,去给每一个下游任务去手工的设计这些prompt,当然这只是prompttuning,或者说softprompt最简单最基本的一个形式,后续还有很多改进的工作,他们自己也又推出了cocoop这个工作,那些大家如果感兴趣的话可以自己有时间再去看。那这里面我们讨论还是在这个文本端的这个prompt,就是它还是一个多模态的工作,它有一个图像编码器,有一个文本编码器,这个prompt还在文本这边,更多的还是像一个NLP的工作。
这里其实是在训练的。文本端的输入不再是固定的this is a photo of什么class了,而是一个可以学习的learnable的context。所以这也就是他们这个文章的起名就是context optimization,就它主要优化的是这个context是前面这个prompt这个learnable的Vector而不是这个模型本身,所以就通过这种方式——就是把这个原来的模型都锁住,只学习prompt这种方式,能够大幅度的降低这个计算量,而且还能帮我们在transferlearning的时候学到一个很好的这个prompt,从而避免我们在做下游任务的时候,去给每一个下游任务去手工的设计这些prompt,当然这只是prompttuning,或者说softprompt最简单最基本的一个形式,后续还有很多改进的工作,他们自己也又推出了cocoop这个工作,那些大家如果感兴趣的话可以自己有时间再去看。那这里面我们讨论还是在这个文本端的这个prompt,就是它还是一个多模态的工作,它有一个图像编码器,有一个文本编码器,这个prompt还在文本这边,更多的还是像一个NLP的工作。
那如果我是一个纯视觉的工作,我只有一个纯视觉的这个图像编码器,那我能不能用prompt?那其实也是有的,就我刚才提到的,在22年年初的时候就有一篇叫visual prompt tuning的方法,就把这个prompt用到了这个纯视觉的任务里,那这个就是VPD论文的这个图2,模型的这个总览图
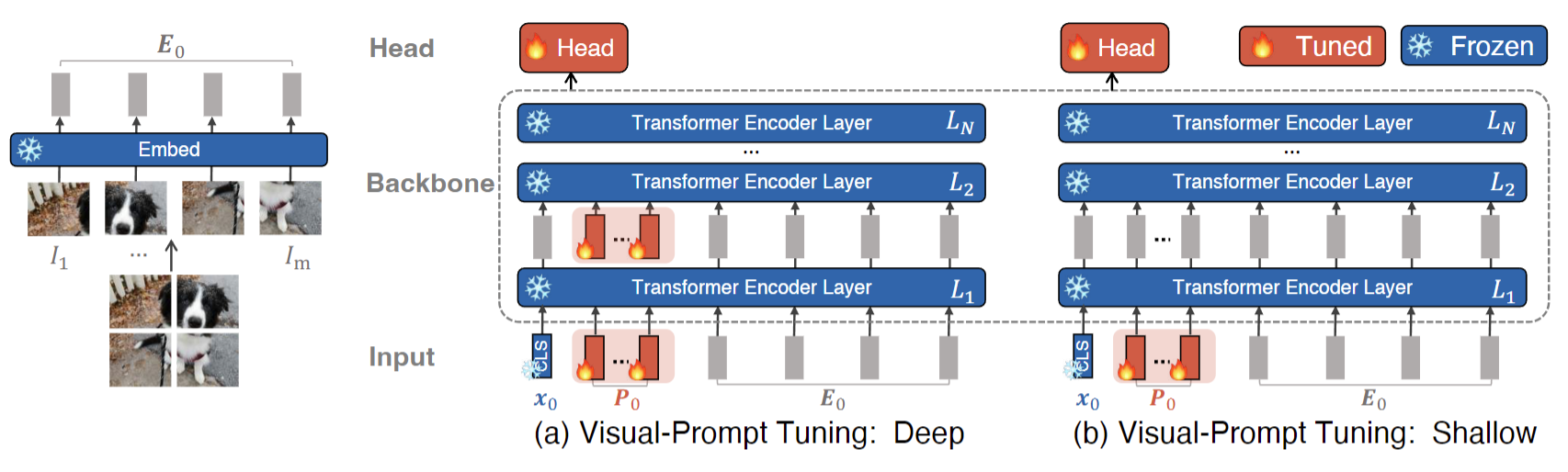
首先我们就是有一个输入,就这个图片,还有一个模型,就是所有的这个蓝色的部分,包括刚开始的这个embedding层和后续的所有的这个transformerlayer,它就是原来的这个已经训练好的模型。那现在我们要使用prompt,这个prompt应该加在哪?VPT这篇论文提出了两种方式,一个是这个VPTdeep,一个是这个VPTshallow
我们先从这个VPT shallow开始讲,VPT shallow其实就跟文本那边非常非常像,它就是在这个输入端加了一个这个learnable的prompt,具体来说就是原来当你有这个图片的时候,你像VIT一样先把它打成patch,然后这些patch通过这个embedding层就得到了这些输入的这个sequence比如说我们这里原来是224*24的图片,打成这个patch之后,它就变成了一个长度为196的这么一个token sequence,这个就是准备给整个Transformer的这个输入,也就是这里显示的这个E0那如果我们把这个E0看成是之前文本端那边那个class name的话,或者说photo of class的话,我们很容易就能想到这个prompt就应该加在它之前,就跟文本那边一模一样。
那加上之后后续的操作也跟文本那边一模一样,就只有这个input的prompt是在学习的,啊剩下所有的过程中这个模型的参数都是锁住的,那最后的那个目标函数也只用来优化这个prompt,这个P0。那对应过来这个VPTdeep的是什么意思?其实就是说我在这个每一层的这个输入输出的时候,我都加上这个learnable的prompt所以就是这里面看这个着火的地方![]() ,就是tune的就是可以学习的参数,把它每一层都加上这个learnableprompt这样就无形的增加了这个可学习的参数量所以说在他们后续的实验中,这个VPTdeep的这个效果一般是要比VPTshallow要好的。但不论是VPTdeep还是VPTshallow都比不用这个prompt效果要好,所以说整体上来说,VPT是一个非常有效的方法。但总之说了这么多,不论是最开始的Adapter还是Hard promp 还是softprompt,还是说visualprompt.他们的共通性就是当你有一个已经训练好的大模型的时候,我希望这个模型是锁住不动的,这样不光有利于我训练而且有利于我做部署,做这个下游任务的transfer,而且它的性能还不降,很多时候它不降反升。这是最近几年非常受追捧,而且也非常实用的一个技巧,也正因为它非常的实用,非常的火啊,所以说就连huggingface也在两三周之前开放了一个专门用来做path的这么一个包,大家是可以直接在getup上找到的,它的目的就像这篇博文的这个题目说的一样,这是当你只有很少量的硬件,或者当你的GPU内存不高的时候,如何去finetuning或者使用这些billion scale的模型。所以如果你还没有在你的问题中试过peft,或者你对peft很感兴趣,那我非常推荐你来玩一玩,般如果只是刚开始做实验的话,一张卡就可以。
,就是tune的就是可以学习的参数,把它每一层都加上这个learnableprompt这样就无形的增加了这个可学习的参数量所以说在他们后续的实验中,这个VPTdeep的这个效果一般是要比VPTshallow要好的。但不论是VPTdeep还是VPTshallow都比不用这个prompt效果要好,所以说整体上来说,VPT是一个非常有效的方法。但总之说了这么多,不论是最开始的Adapter还是Hard promp 还是softprompt,还是说visualprompt.他们的共通性就是当你有一个已经训练好的大模型的时候,我希望这个模型是锁住不动的,这样不光有利于我训练而且有利于我做部署,做这个下游任务的transfer,而且它的性能还不降,很多时候它不降反升。这是最近几年非常受追捧,而且也非常实用的一个技巧,也正因为它非常的实用,非常的火啊,所以说就连huggingface也在两三周之前开放了一个专门用来做path的这么一个包,大家是可以直接在getup上找到的,它的目的就像这篇博文的这个题目说的一样,这是当你只有很少量的硬件,或者当你的GPU内存不高的时候,如何去finetuning或者使用这些billion scale的模型。所以如果你还没有在你的问题中试过peft,或者你对peft很感兴趣,那我非常推荐你来玩一玩,般如果只是刚开始做实验的话,一张卡就可以。

这里面我就不再过多介绍这个peft的这个方法,如果大家感兴趣,也可以去看一下之前一篇比较类似于综述论文的工作,写得非常好,他就把最近这个peft的方法全都总结了一下,同一个统一的观点,就这里说的这个unifiedview做了一些总结和归纳,非常值得一读。
Aim是如何设计的
绕了一大圈我们现在回归正题那之前我们一直想的就是说,如果能把这个预训练好的图像模型锁住不动,只要在旁边加一些周边就可以了但是一直不知道这个周边加什么那现在有了peft之后,首当其冲肯定是需要试一试peft。我个人当时比较喜欢Adapter,所以说就先从Adapter试起,但是Adapter它就是一个即插即用的模块,它到底应该插在哪儿啊?每一个transferblock里到底要插几个?这些我们就接下来去看一下图2,看看aim是具体如何设计。
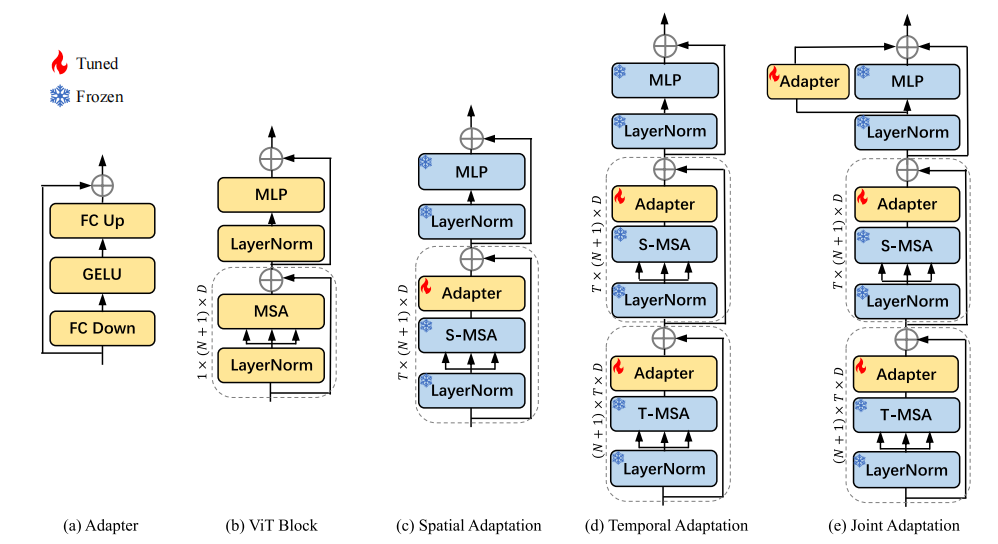
其实今天这个视频,主要是在讲如何在有限的资源内做出更有impact的工作,但是说着说着就说多了,所以接下来方法部分我们可以快速过一下。其实方法本身也非常简单,其中一个审稿人在审稿意见里就写我们这篇论文,最强的地方可能就是我们的简单性,真的可以算是能实现里面最简单的一个方式。那我们接下来看看到底有多简单。

- 那首先我们把这个Adapter和这个VITblock画在这里,Adapter其实就跟19年那篇原始的工作一样,一层fcdown,一个Jello,然后在一个fcup,然后旁边一个残差连接就完事
- 然后VITblock之前我们也见过很多次,先是lairnorm,然后再selfattention,再lairnorm,再MLP。标准的VIT。
那现在我们的任务就是说如何在一个已经训练好的VIT的模型之上锁住它的模型参数,然后在它里面到处加Adapter,看看怎么加这个Adapter能让他会理解视频,怎么加Adapter能让最后的这个视频动作识别的效果做得最好。那我们就依次提出了三种方式,分别叫做这个special adaptation、temporal adaptation和这个joint adaptation,其实这个思路是非常直接的。如果去看十年间做这个视频理解的工作,大部分也都是这几个方向,要么呢就是在这个special backbone上下文章,要么就是在怎么说tempor analysis上下文章,要么就是怎么去学这个join的special temper modeling总之基本都是这个套路,所以我们也是按照这个套路去加这个Adapter。
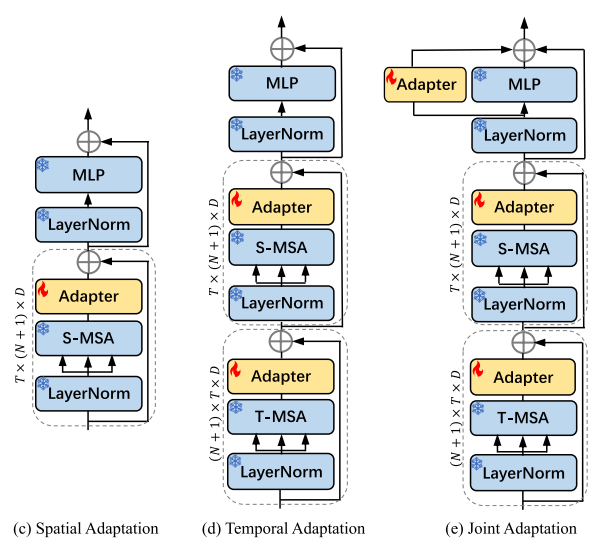
- 那最基本的baseline就是指加这个special adaptation就是在已有的VITblock之上,别的全部都锁住,只在这个selfattention后面加一层Adapter。这个的意义其实就是说,我不给你添加什么这个视频理解的能力,这个时序建模的能力啊。我只是让你加一些可以学习的参数,看看你能不能从这个图像学到的这个特征迁移到这个视频数据集来看,能不能稍微解决一下这个domain gap的问题。事实上我们看后面的实验结果,这一步就已经很有用了,但是因为缺少了时序建模的能力,所以在很多这个video的数据集上,它的效果不尽人意,是比不上之前这个full finetuning的model。
- 那既然你缺时序建模的能力,那下一个我们要加的肯定就是加这个时序建模的能力了,那当然这里面有很多方法了,比如说在已有的这个模型之上,我在旁边再加一个branch,专门做temper modeling像slowfast一样,一个slow branch,一个fast branch,或者最近也有一些工作在后面加一个video decoder,或者还要在旁边加一些什么cross attention。当然最近也有一些工作在最开始的时候加prompt。总之方法五花八门,我们这里选择了最简单的一种方式,就是我们先复用一下这个selfattention,就是原来是一个self attention加一个MLP,我现在是两个self attention加一个MLP,但是其实这两个selfattention参数是完全一致,而且锁住的。只不过我们想让它一个去处理special信号,一个去处理temporal信号,但是你输入都是一个输入,怎么让它一会儿去关注这个specialdimension?另外一会儿又让它去关注这个templatedimension?那我们这里比较简单,就是做了一下reshape这个操作,就是我们这个输入进来的时候,我先把它reshape一下,然后它这个自助力在这个时序这个t这个dimension上去做。所以说这里虽然复用的是同样的selfattention,但它其实是在时序这个维度上去做自助一力。然后做完这次操作之后,我再把这个数据reshape回来,这样接下来再去做selfattention的时候,它就是在n加一,就在那个196+1,那个sequencelens那个维度上去做这个自主与力了,就是正常的special上的自主运力,很多人可能会问,那你这里这个specialsubattention和这个Templesubattention都是锁住的,而且是共享参数的,就算是输入变了变,你怎么能确保他一个就是学special,另外一个就学Tempo?所以这里面我们又额外加了一个adapter,就是在这个template subpotential后面我们又加了个Adapter,那这里的目的就是说我们希望这个adapter,可以学习的参数去更多的关注这个templatedimension上的信息。而后面的这个specialAdapter更多的去关注specialdimension的信息,这样我们至少有两套可以学习的参数,希望模型能从special和timePro这两个方向上,去学习这个下游数据集成的特性,从而能有一些这个时序建模的能力。后面实验我们可以看到,当在这个的基础之上加了额外的这个timeProAdaptationmodule之后,其实我们的性能就已经非常的强了,而且基本上已经能够match之前fullfinetuning的模型,甚至能够超越它了。
- 但是我们还想能不能再把这个性能再提升一些,那之前大家一般都会做一次jointmodeling,那我们也做一次这个jointmodeling。所以就像Adapterpaper原文里提出了一样,其实在这个MLP的旁边也可以加adapter,是这种最原始的方式啊,希望就是说你刚开始做temporal,然后现在是做的special,然后你这两步都做完之后,你最后希望做一层specialtemporal,也就是说让这三个adapter各司其职,各自去管各自那一部分,学各自该学的,尽量让这个优化问题变得更简单一些。所以最后的这个jointadaptation,就这个模型结构其实就已经就是aim了。啊这就是我们最后采用的一个VITblock,把它重复12次,就是一个标准的VITbase,但是加了Adapter能做视频理解的aim模型了,是不是感觉超级简单?
消融实验
其实三个审稿人也都觉得我们的方法很简单,但我们接下来大概看一下效果,那就发现效果其实还是不错。那我们先来看一下table1做了一下消重实验,证明一下提出的每一个component都是有用。
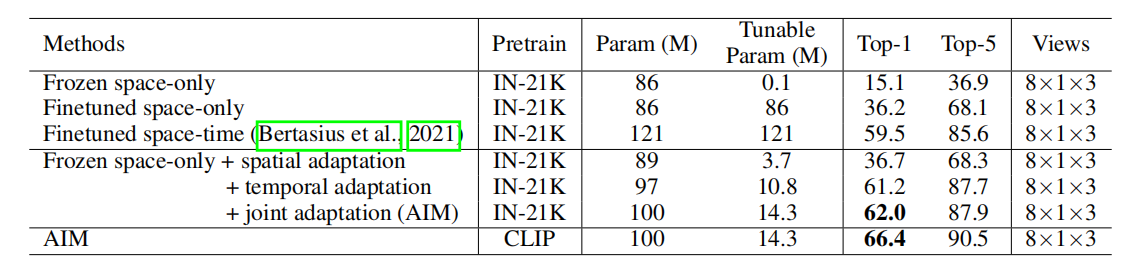
这里我们就选的是timesommer做baseline,因为它是第一个做的videoTransformer,而且结构上也比较简单,跟我们的结构也非常的相近,所以拿它来做比较就会相对公平一些。
- 那这里frozenspaceonly其实就是我们常说的linearPro,就说整个backbone锁住只去tune最后的head,所以我们也可以看到了这个tunable的parameter非常少,只有0.1million当然了它的这个结果也是非常的差。
- 那接下来这个finetuning的spaceonly就是正常的一个模型fineTUNING了,就你拿一个imagemodel,我在视频数据集上去做正常的finetuning,全部都打开,那这样呢?这个效果立马就提升了很多,但是也不尽人意,因为这个也没有考虑到时序信息
- 那最后就是这个timesformer本身是一个video的fullfinetuning的过程,那这里我们可以看到它模型参数本来就是121million,然后tunable也是121,因为全都在打开训练。它的效果当然是非常好了啊在something上它的这个topone accuracy有59.5非常高,但是就是计算量太大。
- 那我们现在来看一看我们的方法是怎么样?那我们的方法就是从一个预训练的image模型开始,也就是这里的这个frozen spaceonly开始,我们逐步开始加我们提出的这几个component如果我们先加这个specialadaptation,我们就会发现已经就36.7了,就跟之前完全打开这个finetuning的spaceonly的结果是差不多的,但是我们听到过的pronter只有3.7,而不是之前的这个86,所以省了十几倍的这个可训练的参数量
- 那第二步一旦加上这个时序建模的能力,这个temple adaptation虽然这个tunnel prompt增加了一些,加到了10.8million,但是这个效果一下就暴增到61.2,直接提升了一倍,而且我们会看到其实比之前的这个fullfinetuning的这个59.5还高了,按道理来说,其实之前的这种video full finetuning的model应该是upper bound,就是说它应该是最高的,我们怎么着都不应该比它高才对。但是这里面只通过增加special Adaptation和Temple Adaptation就已经比59.5还高了,就说明其实模型的优化,在这个视频理解问题里还是非常重要的一个问题。很多时候可能并不是你的模型不好,或者你的数据不好,有可能只是你没训练好。
- 那最后加上这个joinadaptation,就是MLPpermanentAdapter,这个效果就能再提升一点。
- 总之就是只用大概只有14million的这个可训练的参数量,就已经完全高过之前121million的这个video复盘tunemodel了,大概就只用了原来1/10的这个可训练的参数量。所以这个训练速度、训练占用的内存,全都大幅度的减少。aim其实还有一个好处,更准确的说还有一个目标就是说当你这个image的foundation model越来越强,越来越好的时候,它如果能跟着这个图像模型也变得越来越好,就是视频也处理的越来越好,那就符合我们的预期了。那所以这里面我们也试了一下,就是把这个预训练模型从这个imagenet 21k变成CLIP预训练的模型之后,我们会发现这个性能又大幅度的增长了4.4个点。所以这就证明了我们的这个方法是能和大部分的这个预训练模型是compatible,而且更鼓舞人心的,就是说如果你这个图像foundationmodel一个劲儿的发展到明年,后年出来更新更强的这个VIP了,啊比如说刚才说的VIT21billion,那我们也可以把同样的这个方法,把aim用到Vit22b上,直接就会出来一个更强的视频理解模型,我觉得应该不出意外肯定是可以刷榜。
对比实验
那最后我们来快速过一下aim在四个视频数据集上的这个表现。
首先就是大家最常刷的这个K400数据集了。
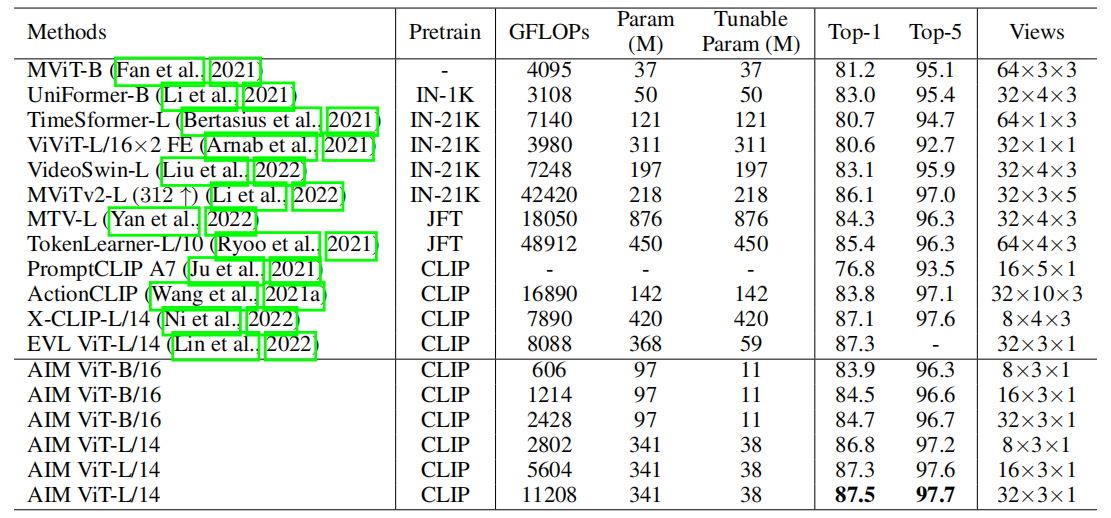
我们可以看到使用aim,而且是用clip里提供最大的那个VIPlargemodel,我们在K400上可以达到87.5的这个top one accuracy,比之前的方法都是要高的。尤其还有很多最近新的工作,比如说这些都是ECCV 的工作,他们也是用了 CLIP 预训练模型。他们的效果自然也不错,但是他们的可训练参数量都非常多。原因就是他们要么还依赖于这个 clip 里另外的那个文本分支,要么呢就是加了新的 video decoder across attention,很多别的module。跟我们就加了几个Adapter,而且把这个输入 reshape 来 reshape 去的这简单操作比,复杂了很多。
那接下来我们一起再看一下,就是 something 数据集和这个case K700 数据集和这个单元 48 数据集上这个 aim 的表现。
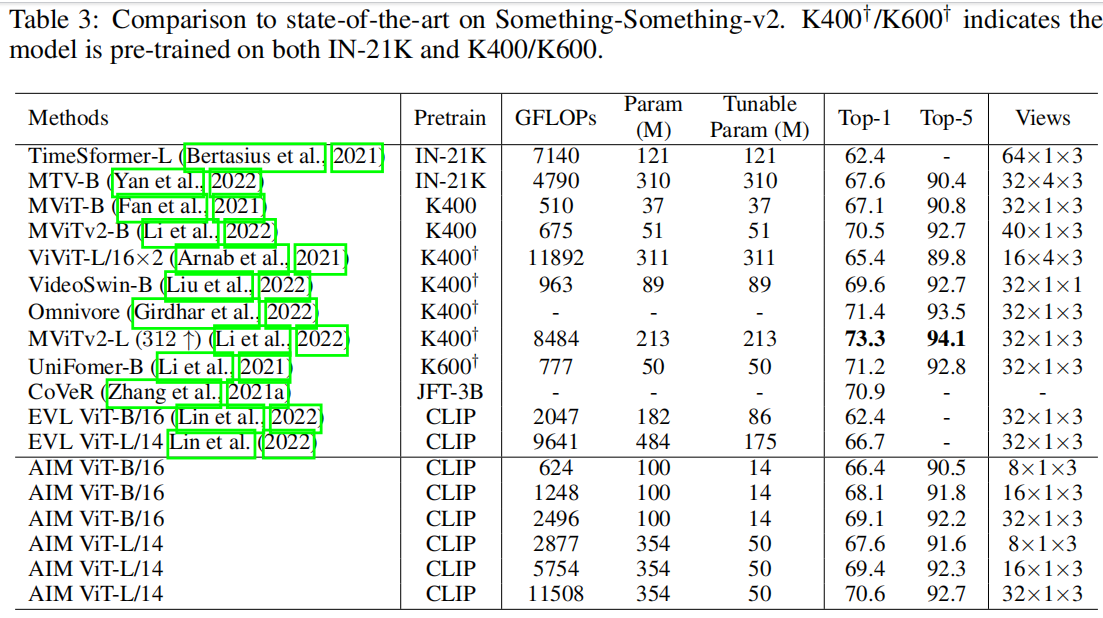
那在something上其实我们表现不是最好的啊。因为 something something 更加 temporal heavy,就是他更注重这个时序信息,而且他的那个时序信息都特别特别的这个细粒度,就是有的,就是说把什么东西从左移到右,然后从右移到左。那这个时候我们发现我们这种只是 reshape input 的这种方式还是不够强大,就是可能还是需要一个更强大的这个时序建模的框架,来做更好的这个视频理解,尤其做这种 temporal challenging 的数据集。但总体而言,我们最后这个结果70. 6 也是非常 competitive 的。只比之前这种,先在 K400——就是已经在视频数据集上预训练过的模型,然后又在 something 上 fine tuning 的模型差一些,所以也还好。
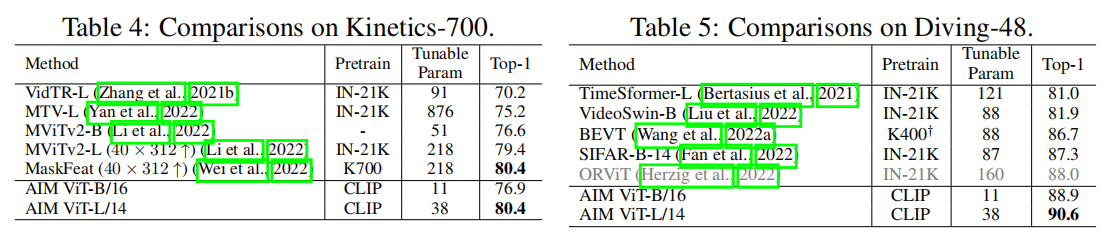
那对于下面这两个数据集,其实我们最好的模型要么呢,是跟之前的这个 SOTA 打成平手,要么就是比之前 SOTA还要高一些。
所以总体来看,作为如此简单的一个方法,这个性能还是不错的。论文的后面其实还有很多消融实验,还有一些可视化。但是限于时间,这里就不多说了,感兴趣的同学欢迎来看,我们的代码和模型也都已经开源了。
总结
总之我们这里想说的第一个方向,能把之前做不了或者做得很慢的任务,能够通过一些方法模型上的改进,从而使得用少量的计算资源就能达到同样的效果。那 parameter efficient fine tuning 只是其中的一个方式。像这个工作因为是视频,本身需要的计算量就比较大,但是用了 parameter efficient fine tuning 之后,大部分的实验其实就是一台8卡机就能完成的。短则半天,长则三四天,只有这个 K700 这个数据集因为太大了,所以需要一两周的时间,但剩下的大部分的实验,尤其是消融实验,都是可以在合理的时间内完成的。组里其实还有另外一篇用 prompt tuning 去做 test time adaptation 那个任务本身就比视频要省计算资源很多啊。所以那篇论文大部分的实验都是 4 卡机器就能完成了。
那除了parameter efficient fine tuning 其实前几年比较火的就是怎么把 attention 做成 efficient attention。比如说什么 lean former performer 这些 attention 的近似最近还出了一个更好的叫 Flash attention,更省内存,而且效果也非常的好。最近我看已经有人把 Flash attention 用到各种文字生成图像的模型中去了,这样就能有很小的GPU,而就能用更大的这个 stable diffusion去生成图像。
2 能不做Pretraining就不做Pretraining,能借助已有的东西,那就尽量借助已有的东西
那接下来我想说的第二个方向其实有两点,第一点其实跟我们刚才说的这个 efficient fine tuning 很像,就是说当你没有足够多的资源的时候,尽量不要去碰 Pre training,能 Zero shot 就 Zero shot,不能 Zero shot 就 feel shot,实在不行你就fine tuning。但是千万别碰预训练,因为预训练现在这个规模是越做越大。 20 年或者 21 年的时候可能还有一些工作能够一个8卡机训练个两三天完成,但是现在这个规模的实验已经不太可能了。预训练的这个模型和数据的规模全都上去了,如果用小模型和小数据是很吃亏的,而且很多时候如果只用小模型和小数据,很有可能本来有一些能大力出奇迹的东西也出不来了,所以你也不知道你的方法有效还是没效,当然预训练也不是完全不行,我们接下来再说第三个方向,会提到之前做的一篇工作。
- 总之第一点就是说尽量不要去预训练,尽量用人家已经训练好的模型。比如说你直接用clip,你直接用 image net 21K 上训练好的这个VIT。那这样就把整个预训练的时间全都省下来了,直接做 fine tuning 会简单很多啊。比如我们之前说这个多模态工作,上和下讲了那么多工作之所以能在 clip 出来之后这么短的时间内能把detection Segmentation, depth action. Audio 所有的这些工作全都拓展开来,其实还是因为直接利用 clip 预训练好的模型,不去做预训练,只做 fine tuning 这个计算资源是能节省很多的。所以大家有足够的时间,有足够的资源去做这些迭代,去扩展到各个不同的领域。
- 那第二点就是尽量选一些新的方法或者新的 topic 去做。尤其是那些你觉得或者大家也觉得还比较超前的那些topic,这就非常好。因为往往在那些领域里可能还没有很大的一些数据集,一些成熟的这个benchmark,所以你这个数据,你的这些 setting 你都可以自己选,这个规模就可以降下来。第二个就是也没有那么多已经有的工作,你需要去竞争,那这样你就能专心在提高自己的方法之上,而不用成天担心你比不过别人,所以这篇论文中不了。
那接下来。我就用另外一篇 am i clear R3 刚中的论文来说一下这两点是如何运用。这个工作是之前一个实习生 andrej 做的,方向从这个题目里一眼就看出来了,做的其实就是 unsupervised semantic segmentation,具体使用的方法是 self supervised object centric representations。这里面其实就包括了我刚才说的那两点啊。第一点就是 self superst,其实我们是利用了这个已经预训练好的这个 Dyno 这个网络和之前预训练好的这个 deep USPS 和bas net 的这些网络啊。总之所有的这些抽特征的网络都是已经预训练好的,我们本身是没有做任何训练。这样就省了很多的这个计算资源。那第二点其实我们一直想做这个方向,就是这个 object centric。learning,这个当然不能算是一个很新的 topic 了,但它还是属于一个正在蓬勃发展的一个topic,玩家不是那么多,数据集也不是那么大。所以在这两点的加持之下,其实这篇工作的这个计算开销就跟 2018 年 19 年大家做一个segmentation 的 network 的开销是一样的,其实就是训练那个 deep lab V3 的一个网络而已,有一台四卡机就能跑大部分的实验。
方法
接下来我们就直接来看图2,看看这个方法具体是怎么工作的,其实主要就是看一下这个预训练的网络我们是怎么使用的。
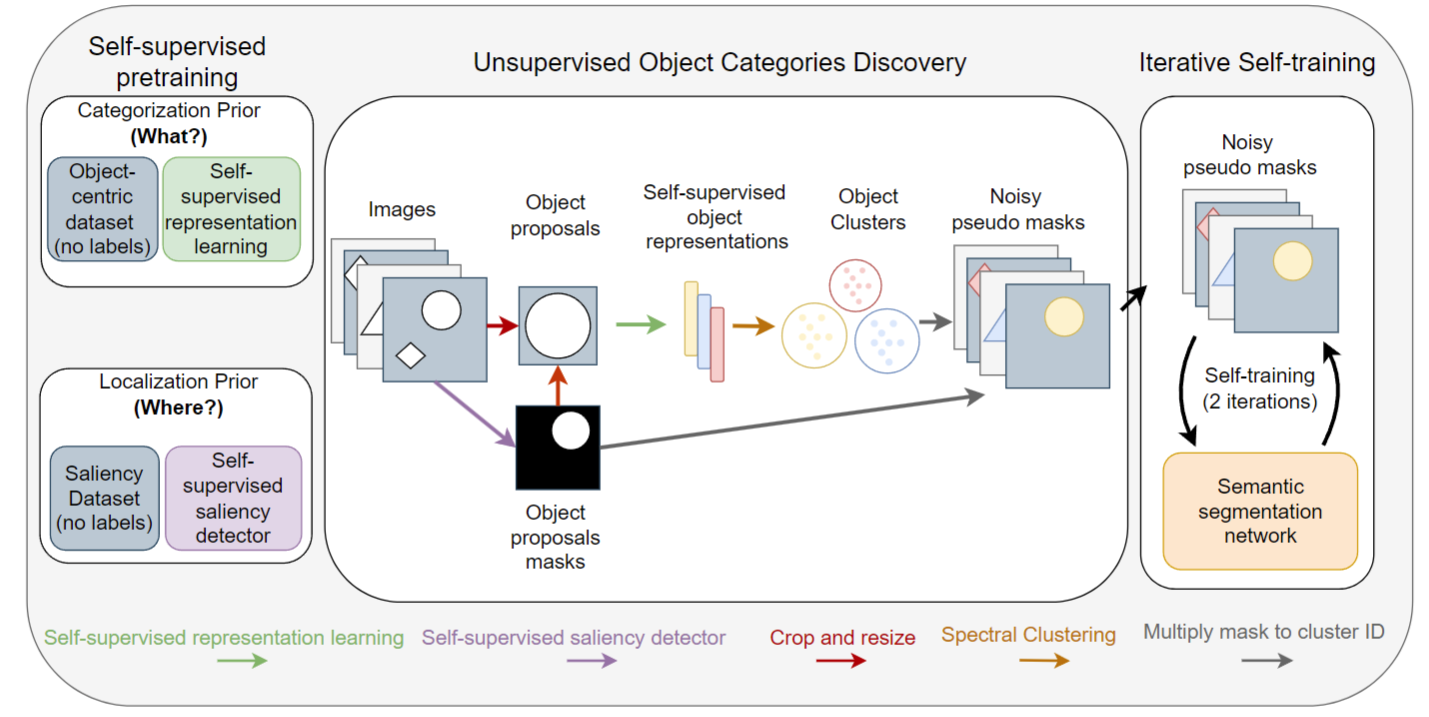
那基本上我们主要的流程其实就在这一步,就是 unsuper s object category discovery。就是怎么样能让这个模型无监督的情况下去找到这个新的物体? discover 这些new object。这个 object centric learning 其实最近很多人都很感兴趣。因为他们觉得,如果你理解一个图片,就是整体去理解,整体抽一个特征的话,其实不是那么合理,那像我们人在感受这个世界的时候,其实看东西都会有一个聚焦的点,都会先看一些人,或者看一些物体,然后再看人和物体之间怎么去做交互,然后通过这些关系来感知这个世界,然后来预判接下来会发生什么。很多人就觉得这个 object level 的这个representation,这个 object centric learning 其实比这个 global 的这个 learning 要更有效。那如果还能unsupers 或者 self supers 的去学习这个特征,那就更完美了。那当然我们也知道,那这些所谓的 unsupers 其实它都不是真的unsupervised,其实它是人为的通过设计了一些这个任务,或者人为的设计了一些label,从而让这个模型能够去学习的,那在我们这里其实也不例外。你如果想学习一个这个 segmentation 的网络,你肯定是需要某种程度上的这个mask information。那这个最初始的这个 mask information 到底应该从哪来呢?这个时候其实我们就借助了之前这个 saliency detection 的工作,那比如这里我们就直接用了这个 deep USPS 这个工作,很多之前 super semtation 工作也用的是它。就可以直接给定一张图片,然后他给你生成这张图片里那些比较具有显著性物体的 mask 是长什么样啊?虽然比较糙,而且也不准确。但是至少你有一个起始点了,你有一些这个 mask 的信息了。
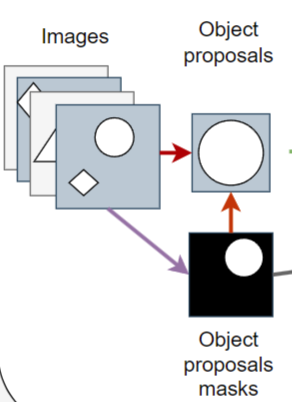
就跟我们这个图里画了一样,如果你这张图片里有一个圆圈,有一个这个菱形。那用了这个显著区域检测之后,它就把这个圆圈给detect出来了,这个其实。相当于有一个 mask 的label 了。
那解决完这个定位问题之后,我们又要解决这个分类问题。也就是说。当我把这个圆圈从这个图片里抠出来之后。我现在想要知道这个圆圈到底是哪一类的时候,这个时候我们就借助于之前的这个DINO这个工作,去抽它的特征,从而来判断到底这个物体是什么物体。简单的来说这整个流程就是说当你给定一个物体的时候,我们先用 DPU SPS 去抽出来它的这个saliency mask,然后把抽出来这些saliency mask,再去原来的图片中把对应的物体给抠出来啊。
比如说这张图片我可能就抠出来两张图,一张是这个圆形,一张是这个菱形。当我抠出来这两张图片之后,我再把它的图片大小 resize 成224* 224 变成正常的这个图片大小。然后我把这个正常的图片大小直接扔给 DINO这个网络啊。这个DINO就还给我一个 1024* 1 的一个global representation。接下来我把这些特征全扔过去做一次这个clustering。因为是这个无监督的算法,所以说它就能无监督的告诉我这些物体到底是什么啊?他不是真的告诉你这些物体是什么,只是给你一些这个物体的这个ID,比如说0123。因为它只是聚了个类。所以我们这里称这些是 Noisy Pseudo masks。但是即使它只是聚这个类,它还是能告诉你这是类0,这是类一,这是类2,那这样其实变相你就有了这些 mask label 了,那这个时候你有了原来的这个图像,你又有了后面的这个 mask label。 你就可以直接去训练一个Semantic Semitation Network。既可以是PSPnet, 也可以是 deep lab v3。任何一个 segmentation network 都可以,因为其实你现在做的就是一个有监督的 segmentation network 的训练。
那这里因为我们不光是想对一张图片里的单个物体进行分割,我们还想分割多个物体,所以我们又做了这个 self training,就来了好几个轮回,这样通过不停的自训练,我们的网络就能学到更多的这个物体的分类。甚至能学到新的类别。这也就是 object centric learning 想达到的目的了。
具体的细节我就不多说了,我想强调的就是说,通过使用这两个已经预训练好的模型。然后再加上做这个 object centric learning 比较新的这个topic,从而导致我们的这个性能不仅很高,比之前的sota都要高啊。比如说在 VOC 这个数据集上,我们的风格准确率就达到了50MLU,算是纯 vision 里这个效果非常好的了。而且我们的计算开销非常小,其实就是最后这个 semantic segmentation network 需要训练一些时间,那这个取决于你用什么network。如果你是 PSP net deep life v three 这种传统的网络的话,而且还是 VOC 这种小数据集,其实四卡的机器半天一天就训练完了,非常的快。
当然这个方向最近也卷起来了,因为有了这个 clip 之后,这个 language guided segmentation 是越来越火。去年就涌现了很多这个 language guide segmentation的工作。我看最近的sota好像已经把这个 VOC on super s 刷到 60 多了,所以进展还是非常快。
总结
然后关于使用借鉴这个人家已经预训练好的模型了。其实组里还有一篇利用已经训练好的这个swing模型。去做很多remote sensing,就是地理那边的任务。也在十几个数据集上都取得了不错的效果。计算开销也没有那么大,所以这就是第二个方向,巧妙地利用预训练的网络,从而达到能够去做 few shot、Zero shot,或者最多就是 fine tuning 的实验,然后再加上一些比较新的topic。比如说consultate learning,就是因果学习,或者说 Hinton 之间提出的这个 feed forward network——ffnet。或者说Language那边的In-Context Learning或者Chain of Thought Promppting就是 Aston 前几期讲过的那个 AI 鼓励师 COT 。所有的这些 topic 都很新,而且都很有前途,会很快成为新的研究热点。
3 即插即用的模块 MixGEN
那接下来我们来说一下第三个方向。就是尽量做一些通用的,可以即插即用的模块儿。这个模块儿既可以是模型上的一个模块儿,比如说像 non local MODULE 一样,在已有的 Resnet 后面加一个 non local。或者说是一个目标函数,比如说把正常的 loss 换成 FOCAL loss,当然还有一个就是输入层面的,比如说就是数据增强了。那数据增强的方法往往是很通用,它一般不受限于你这个任务,很多时候它甚至不受限于你这个模态啊。比如说像 mix up 这后续已经全都玩出花来了,估计有几十种 mix up 的变体。那 mix up最初是用在这个图像分类里的,那后来这个 detection segmentation video 全都有用 mix up,那后来也用到了这个文本里,能用mix up。多模态里也有mix up。为什么说做这个方向对计算资源的要求会少呢?其实如果你是真的想要一个东西,非常的work,做得非常的好,而且做了大量的实验,大量的任务去验证它,可能这个花费的计算资源也不少。但它有一个好处。就说如果你只是想验证它的有效性。如果你只是想证明给这个神告人看,说我这个方法有用,我这篇论文能够被接收。这个时候有一件好事,就是你有可能不需要达到 SOTA,就你有可能不需要刷榜,你只需要证明你在很多个方法上或者很多个数据集上都有统一的提升就可以了。因为证明一个方法的有效性,不一定说我非要拿到某个数据集上第一。因为即使你拿到某个数据集上第一,有可能你只是overfit,所以反而还不能证明你有多有效。往往是那些很简单的,能够泛化到各种各样的任务,各种各样的数据集上才是真正有效的方法。那这个时候你就可以很选择很多baseline,然后可以自己定一个setting,让他们能够公平的比较。那这个 setting 可大可小,可以根据你的计算资源来定,那只要在这个 setting 里边,你在所有的 baseline 上加上你这个即插即用的模块之后,都能有统一的涨点。你也能给出合适的分析。那就非常有说服力了。所以从这个角度上来说,它是一个在你没有足够的计算资源的情况下,一个还不错的研究方向。
我们来快速来看一下 mix chain 这篇论文,其实 mix chain 这篇论文做的是一个多模态的数据增强,这个项目最开始开题的时候其实并不是做数据增强的。我们是想在多模态学习里面加上这个 knowledge distillation——就是蒸馏。因为当时我还在看很多对比学习的东西,我也在看 VLMO 那篇论文,就之前多模态串讲的时候提到过微软的 VLMO。当时有很多证据,证明就是说这个 self attention 一旦学好之后,不论是视觉的还是文本的这个 token 进来,它都可以去做这个自助力操作。你是不需要重新学习的,它是可以共享的。那这个时候我就在想,视觉这边的模型其实一直都不太大。比如说 VIT 之前最大的也就是 VIT 2 b 令或者 4B,当然这些其实挺大了,但是我们经常用的其实就还是 VIT base还是很小的。但是文本那边模型一般普遍都比较大了,比如他们常用的这个Deberta,或者说T5,还有最近比较火的这个FLAN T5 都已经是非常大的模型。也在很大的数据集上训练过,效果也非常好。所以我就在想既然这个自注意力的这个参数都能共享,我为什么不能拿一个文本的这个大模型来蒸馏一个视觉的小模型呢?那或者说再往前推一步,我能不能拿视觉的模型也去 Disteal 这个文本的模型呢?所以当时这个项目开题的时候,其实是想做一个 cross modelity 的这个知识蒸馏的工作。我和实习生其实也很感兴趣,搞了两个多月快三个月的时间,但可惜这个结果不尽人意。当然提高还是有的,但提高太小了。大概就是零点几个点的涨幅,在很多任务上都不超过一个点。而且因为加了蒸馏之后,这个整体的这个训练的 pipeline 也变得更复杂了,而且你还得去选到底我想用什么样的 teacher 来做这个 knowledge desolation?这里边凭空又会多很多消融实验,这个计算开销也会随着这个 teacher 模型的变大而变大。所以就对这个方向产生了怀疑。那正好在那个时候看了很多这个多模态的论文,比如说之前讲过的 l buff、VIOTA, viomo 或者 BIT 这一系列的论文。因为我们真的是在跑实验,所以说很注重这些 implementation details 的东西,所以就看得比较仔细,就发现一个很有意思的现象。就是这里面的很多工作它都没有用 数据增强,有的只是用了很基础的数据增强。比如说像 clip 这篇论文,他就用了最简单的这个 random resize crop 就结束了,再也没有用别的 数据增强。它的解释是说因为它已经有 400 million,就 4 个亿的这个图片文本对儿了,数据已经非常非常多了,所以我不需要 数据增强。那另外还有一些论文,比如说 l buff,还有后续的这些BLIP。他说他们虽然用了很好的这 数据增强,比如说 auto augment,但是他们把 auto augmented 这个 color gittering 和这个 random flip 给去掉了。这个就很有意思,比如说他们给出的原因是这样的,就当你有一个这个图片文本对儿的时候,比如说你这个图片里说我有一个白色的狗,然后在一个湖的右边在玩耍,旁边可能还有一棵绿色的树,你的文本就是我刚才说的那句话。但这个时候。如果你只对图片做这个数据增强的话,你做了一个 color gitering,那它的颜色就变了,这个狗就不再是白狗了,你的树也不再是绿树了,那这个时候你的文本和图片它就不匹配了。那同样的道理,当你做这个 random flip,比如说水平方向的 flip 或者数值方向的 Flip 之后,你的这个上下左右这种位置性的词它的意义也全都颠倒了。那这个时候你 flip 过后的图片和原来的这个文本它就不再是一个对了。所以出于这个考虑他们用了 auto augment,但是他们把这个 color gitering 和这个 random flip 给取消了。这个东西对于我一个做 CV 的人来说就很感兴趣。因为 CV 对这个 数据增强的依赖是非常强的。所以在我的信念里就觉得 数据增强还是有用的,如果能加我们还是加上。那多模态这边现在没有,那我们为什么不做这么一个 数据增强?
那首先我第一个思考的问题就是为什么之前大家不用这个多模态里这个 数据增强,后来发现其实很大程度上可能就是刚才提到的那个原因,就是在做了这个 数据增强之后,原来的图像文本对,可能就不再是一对了。这也就是说。在你做这个数据增强的时候,有一些信息被改变了,或者说有一些信息丢失了,所以才会导致他们两个不匹配。那我就在想怎么才能让这个信息不丢失,怎么才能最大程度上把这个信息给保留起来呢?那我们可以先一个模态来想,那图像这边儿如果想保留所有的信息,尽量不去毁坏它原来的东西。其实一个比较天然的选择就是 mix up,其实 mix up 就是把两张图片线性的插值到一起。那虽然在人眼看起来,有时候这个生成的图片可能比较诡异,但是它毕竟只是把两张图片直接就这么加了起来,所以该有的信息都还在里面,所以算是很大程度上保留了原来的信息。
那关键问题就在于文本那边儿我们在怎么样最大程度的保留信息呢?当然文本那边也是有 mix up 的,文本那边还有 random erasing,或者说 random insertion,或者说 back translation,各种各样的这种数据增强的方法。但我们当时想的就是,如果我们的目标是尽可能的保留更多的信息,那为什么不直接把两个句子就直接拼接在一起就行了呢?那这样什么信息都不会丢失,所有的单词都还在新生成的这个句子里面,这样不就最大程度地保留了原来文本的信息吗?所以这就得到了我们 mix GEN 的一个雏形
方法

如果我们来看这个图一。其实想法还是很简单,就比如说我们现在的这个数据集,就是个多模态的这个图片文本,对的数据集里有这么一个 I1 和这个T1,I2,这个T2,就这两个图片文本对的话。
那在图像这边我们就对 I1 和 I2 做这个 mix up,做这个 linear interpretation,我们就能得到这样一张 I3 这个图片,就一张新的图片,是数据增强过后的图片。我们可以看到它在很大程度上保留了前面两张图片里这种物体,还有包括这个背景 context 很多东西都保留下来。
那文本这边。那直接就是把 T1 和 T2 直接拼接了起来,就是concatenation,那这样子什么信息都不会丢失。所以就通过这种方式,我们就得到了一个新的训练样本,I3和T3。这个是在原来的数据集里从来没有见过,它是一个全新的样本,那这两个图片也有可能描述的是两个完全不相关的概念,它这两个句子也有可能是完全不能搭到一起的句子,就有可能读起来很别扭,上下文不连贯。但是从整体信息量上来说,它是最大程度了保留了之前的这个信息量,从而保证这个新生成的这个图像文本盾它尽可能的还是一个 match 的pair,所以我们教这个方法是 mix generation,也就是 mix Jan。

那如果把 civil code 写出来,其实这也不是 civil code,真的 code 也就长这样,其实一共就三行。图像就是 mix up 文本就是concat,然后结束。而且这个因为是在这个数据处理的时候做的,所以就是在 data loader 里完成的。不论你现在换什么方法,换什么Codebase,Pytorch,Tensorflow,或者你换方法vietlbuff, BLIP 都无所谓,只要你在 data loader 里把我们这一步加进去就可以了,其他什么都不用改,所以真的算是即插即用,而且能获得普遍的提升。
实验结果
那接下来我们就来看一看这些实验结果,因为做了太多实验了,比如这里就做了 5 个task,还有更多的数据集,所以肯定就不一一过了。
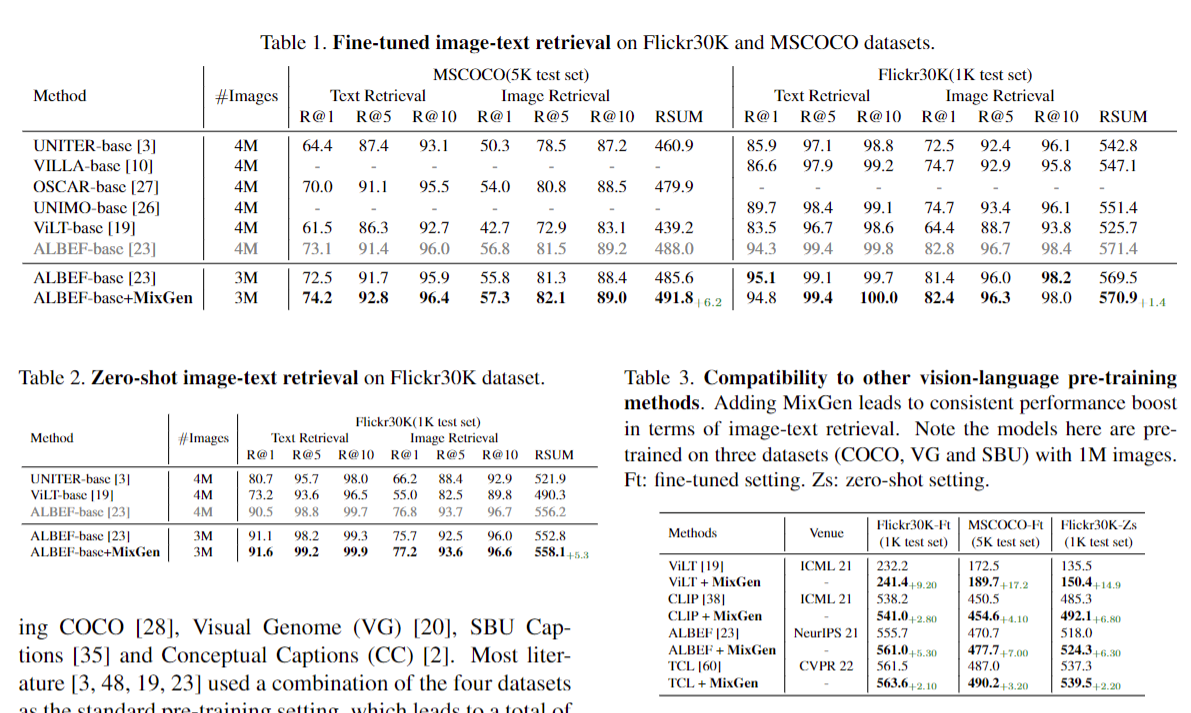
能看到的就是在各种各样的 setting 下,各种各样的数据集和这个task 下都会有这个统一的提升,所以是可以证明它的有效性。
但在这里我主要想强调的就是今天的主题就是有限的计算资源。所以像当时我们做的时候,我们选取的这个 setting 就是很多都是在这个 4 million 的这个图像文本对上去做的。这个算是 2020 年, 2021 年的时候一个比较标准的一个setting,不大不小,我们大部分的这个实验 setting 都是 follow lbuff 的,那所以说就是一台8卡机训练两三天的时间,在这个 4m的 setting 下,所以是可以承受的。
但我们在做消融实验的时候,因为有太多的消融实验也要做了,因为你有各种各样的 data gmentation。你有各种各样的方式去融合这两个这个模态。所以出于这个考虑,我们这个 table 3 里,还有后续的好几个 table 里,就把这个 setting 进一步的减小,就变成这个一million的 setting 了。也就是说只有100 万个这个图像文本对可以看到这里。我们是想证明这个 mix gener 是可以和很多别的方法去compatible,比如说在voult,clip、lbuff、 TCL 里都可以用,而且加上它都有提显著的提升。那因为只用了一 million 的这个图像文本对,所以这个训练是很快的,一台8卡机的话是不到一天就能完成这些训练。我们后面还做了很多消融实验和这个可视化,还有分析,还有limitation,当时自我感觉还是不错,而且看这个我们在摘要里写的这个性能提升,其实在很多数据集合 task 上提升也是比较显着。尤其是对于一个如此简单的这个数据增强方式来说,我们觉得并不会比之前的那些数据增强的方法逊色。那很可惜,这篇论文当时第一次 投neurlps 的时候并没有中。三个审稿人都觉得这个方法太简单了,那除了这个简单之外,其实有一个审稿人给出的意见还是蛮有建设性意义。他说数据增强一般是在你没有足够多的数据的时候才去做的一个选择。但是在这个多模态的预训练里,因为已经有很多这个大量的数据存在了,那确实像CLIP 论文里说的那样,你有可能就是不需要这种数据增强。但是相反的在这个多模态下游任务里,当你做这个 transfer 的时候,因为你下游任务的这个数据集不多,所以是不是应该考虑在这个 fine tuning 的时候用这个数据增强?这个其实是个很好的建议,我们当时在做项目的时候也有人提出过,说我们要不要把这个 data mentation 在 fine tuning 里也做一下。但当时有一个concern。就是说如果做在 Pretraining 里,因为你就是一个图片一个文本,所以你 mix Jan,这样就很简单,画图也简单,这个 伪代码也简单,整体论文就显得很干净。但是在下游任务里,因为根据每个下游任务的不同,而这个 mix Jan 的形式可能会变一变。比如说当你做VQA 的时候,你除了一个图片,还有一个question,你还有一个answer,所以你相当于是有一个图片和两个文本。那这个时候你该怎么做mixgen。那或者另外一个任务 visual enterment,就是两个图片和一个文本,那这个时候你又该如何做?这个mixgen?虽然肯定是可以。找到一个很简单的方式把mixgen用过去的,但当时就觉得这样会让整个论文看起来很messy。东西太多了,所以就没有做。但是后来想了想还是很有道理的,因为你做一个方法,你提出一个新的东西,它必须还是有用是第一位的。如果只是你觉得什么什么好,它不一定真的好。尤其是在审稿人那,更多的情况可能是我不要你觉得,我要我觉得。所以说在开题的时候跟更多的人尽可能去讨论,每一步的时候都仔细想了想这个东西到底最后能做成什么样啊?如果做成功了,它会有什么样的用处?有什么样的impact?这样可能会指导你做出更好的工作。
总之就是做这种即插即用的模块,因为你可以自由的去定这个setting。只要是公平的对比就可以了。这样即使用比较少的计算资源也能够证明方法的有效性。
4 做一个数据集
那今天其实想说的最后一个方向,对这个计算资源的要求是最少的,很多时候都不需要大量的计算资源,甚至只是断断续续,偶尔需要一些计算。资源就可以了。比如说就是做一个数据集,做一些纯evaluation 为主的论文,纯分析的论文,甚至就是写一篇综述论文。比如上一期牧神就刚刚讲了这个HELM语言模型的一篇评测文章。
BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training
那在这个方向上我们组里也有一些工作,比如说去年这个以数据集为主的这个 big detection 的这个工作,它就是一个非常大的一个目标检测的数据集。因为目标检测是一个非常实用的任务,所以如果我们有一个很大的数据集,能在上面预训练一个很好用的这个目标检测器,那它这个应用应该是非常广泛的。大家可能很多人一听说要造个数据集,那这个代价太大了,这可能需要很多人需要花很多钱才能做一个很大的数据集。但其实也不一定。比如说像我们。这篇论文里就是把三个已有的数据集LVS、 open image 和这个 object 365 给合到了一起,当然不是简单的合到一起了,因为这个它的每个数据集的这个 class 也不是完全一样的啊。所以你得考虑到底怎么去 merge 这些class,或者怎么去重新分布这些类别。而且根据你的这个任务的需求,你到底是想做预训练还是想做下游任务啊?你到底想 target 哪一个domain?这个也决定了你这个物体的这个类别到底该多细粒度。所以这些都是可以做的研究方向,都可以写成论文的。
那具体细节我在这里就不说了,总之这个 big detection 最后处理完,我们就是一个有 600 类的这个目标检测数据集,里面有超过 340 万个这个训练图片,而且有 3, 600 万个,这个 bonding box annotation 算是当时最大的一个目标检测数据集了,而且在上面可以预训练各种各样的这个目标检测器。因为训练的数据多,所以训练出来的这些目标检测器它的这个泛化性能,还有这个 feel shot 的能力都非常好。这个数据集代码,还有这些已经训练好的模型都开源了,就在 Amazon science 的这个 GitHub 上面,你搜这个big detection 就能有。因为比较新,刷的人也比较少,所以大家如果感兴趣可以在这个上面做一些,比如说 out of distribution 的这个分析, robustness 的分析, few shot、 Zero shot 各种各样的分析或者测评也是不错的这个研究方向。
组里最近还有另外一篇论文是做多模态的这个稳健性分析的,也是提出了很多这个 Benchmark data set,然后也提出了一些新的这个evaluation metric。总之都属于这一个方向,就是做新的数据集,提出新的 evaluation metric,具体的论文都可以在我的个人主页上找到。
5 评测分析或者综述论文
那另外一个就是刚才提到以这个评测分析为主的论文,或者说就是一篇综述论文,那这里就拿我之前写的一篇做这个视频动作检测的一篇综述论文来举例子。因为当时在做gluonCV 的时候复现了很多这个网络结构。之前也一直是做这个方向,所以有很多想写出来的这些很细碎的点,就索性写了一篇综述论文,就放到 arxiv上了。但总之写这种以 evaluation 为主,或者写这种综述论文其实是非常有好处的。它有助于帮助你理解已有的这些方法,它们的这个优点、缺点都在哪啊?现在所有的方法的这些 limitation 都在哪?现在的痛点以及未来的这些 future work 该在哪些方向上发力?其实都是通过这种evaluation 的工作,大家才能找到这些 nsight 的。所以说不论 你是还没决定进入哪一个领域,或者说你已经打定主意整个博士期间就做这个领域了,写一篇这个综述论文,或者做一些这种 evaluation 的分析,绝对是对你的科研有百利 而无一害的。而且这些论文往往不太需要那么多计算资源。 evaluation 的话有时候可能只是做inference,就算有的时候要做一下训练,更多的时候可能也只是 fine tuning,或者在小范围上做这个训练。那对于综述论文来说,那就更是不需要计算资源了,主要考验的是你的写作能力和你对这个问题理解的清晰程度。
所以算是今天讲的这四个方向里面最不需要计算资源的一种,大家都可以去做。
总结
那今天要说的四个方向其实就已经说完了。大部分的实验。其实只要一台 4 卡机或者 8 卡机就足够可以完成了。而且取决于你工作的这个 domain 或者你选择的这个任务,有的时候这个任务或者数据集比较小,那这个资源还可以进一步压缩,有的时候一张卡两张卡也是能做出不错的工作的。希望能对还在选研究课题的你有所帮助。另外和实验室的同学或者跟别的学校的,哪怕是开会的时候认识的人经常的交流甚至去合作。是非常能激发灵感的一种方式,而且经常能碰撞出很有影响力的工作。那今天就先到这里,祝大家科研。顺利。

在这里,我们一起交流AI,学习AI,用AI改变世界。如有AI产品需求,可访问讯飞开放平台,www.xfyun.cn。
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)