
Ollama 环境变量与常用 CLI 命令
环境变量设置及说明localhost127.0.0.1 CLI 命令在终端,输入上面的命令 + '-h',可查看具体命令的帮助文档(如,ollama show -h, 可查看 show 命令的帮助文档)。下面列出每个命令的具体用法和示例。在本地系统上启动 Ollama:ollama server。
·
环境变量设置及说明
网络配置
- OLLAMA_HOST:定义 Ollama 服务器的协议和主机地址。默认为
127.0.0.1:11434,仅本机地址可通过 11434 端口访问该服务。可以通过此变量自定义 Ollama 服务的监听地址和端口,例如设置为0.0.0.0:8080,可允许其他电脑访问 Ollama(如:局域网中的其他电脑)。默认使用 http 协议。若要使用 https 协议,可设置为:https://0.0.0.0:443 - OLLAMA_ORIGINS:配置允许跨域请求的来源列表。默认包含
localhost、127.0.0.1、0.0.0.0等本地地址以及一些特定协议的来源。通过设置此变量,可以指定哪些来源可以访问 Ollama 服务,例如OLLAMA_ORIGINS=*,https://example.com允许所有来源以及https://example.com的跨域请求。
模型管理
- OLLAMA_MODELS:指定模型文件的存储路径。默认为用户主目录下的
.ollama/models文件夹。通过设置此变量,可以自定义模型文件的存储位置,例如OLLAMA_MODELS=/path/to/models将模型存储在指定的路径下。 - OLLAMA_KEEP_ALIVE:控制模型在内存中的存活时间。默认为 5 分钟。负值表示无限存活,0 表示不保持模型在内存中。此变量用于优化模型加载和运行的性能,例如
OLLAMA_KEEP_ALIVE=30m可以让模型在内存中保持 30 分钟。 - OLLAMA_LOAD_TIMEOUT:设置模型加载过程中的超时时间。默认为 5 分钟。0 或负值表示无限超时。此变量用于防止模型加载过程过长导致服务无响应,例如
OLLAMA_LOAD_TIMEOUT=10m可以将超时时间设置为 10 分钟。 - OLLAMA_MAX_LOADED_MODELS:限制同时加载的模型数量。默认为 0,表示不限制。此变量用于合理分配系统资源,避免过多模型同时加载导致资源不足,例如
OLLAMA_MAX_LOADED_MODELS=4可以限制同时加载 4 个模型。 - OLLAMA_MAX_QUEUE:设置请求队列的最大长度。默认为 512。此变量用于控制并发请求的数量,避免过多请求同时处理导致服务过载,例如
OLLAMA_MAX_QUEUE=1024可以将队列长度设置为 1024。 - OLLAMA_MAX_VRAM:设置 GPU 显存的最大使用量(以字节为单位)。默认为 0,表示不限制。此变量用于控制 GPU 资源的使用,避免显存不足导致的问题,例如
OLLAMA_MAX_VRAM=8589934592可以将显存限制为 8GB。 - OLLAMA_GPU_OVERHEAD:为每个 GPU 预留的显存(以字节为单位)。默认为 0。此变量用于确保每个 GPU 有一定的显存余量,避免显存不足导致的问题,例如
OLLAMA_GPU_OVERHEAD=1073741824可以为每个 GPU 预留 1GB 的显存。
性能与调度
- OLLAMA_NUM_PARALLEL:设置同时处理的并行请求数量。默认为 0,表示不限制。此变量用于优化服务的并发处理能力,例如
OLLAMA_NUM_PARALLEL=8可以同时处理 8 个并行请求。 - OLLAMA_SCHED_SPREAD:允许模型跨所有 GPU 进行调度。默认为
false。启用此变量可以提高模型运行的灵活性和资源利用率,例如OLLAMA_SCHED_SPREAD=1可以启用跨 GPU 调度。
调试与日志
- OLLAMA_DEBUG:启用额外的调试信息。默认为
false。开启此变量可以获取更多的调试日志,帮助排查问题,例如OLLAMA_DEBUG=1可以启用调试模式。 - OLLAMA_NOHISTORY:禁用 readline 历史记录。默认为
false。启用此变量可以避免保存命令历史记录,例如OLLAMA_NOHISTORY=1可以禁用历史记录。 - OLLAMA_NOPRUNE:在启动时不清理模型文件。默认为
false。启用此变量可以保留所有模型文件,避免不必要的清理操作,例如OLLAMA_NOPRUNE=1可以禁用模型文件的清理。
特性开关
- OLLAMA_FLASH_ATTENTION:启用实验性的 Flash Attention 特性。默认为
false。此变量用于测试和使用新的注意力机制特性,例如OLLAMA_FLASH_ATTENTION=1可以启用 Flash Attention。 - OLLAMA_MULTIUSER_CACHE:为多用户场景优化提示缓存。默认为
false。启用此变量可以提高多用户环境下的缓存效率,例如OLLAMA_MULTIUSER_CACHE=1可以启用多用户缓存优化。
代理设置
- HTTP_PROXY:设置 HTTP 代理服务器地址。此变量用于配置 Ollama 在进行 HTTP 请求时使用的代理服务器,例如
HTTP_PROXY=http://proxy.example.com:8080可以让 Ollama 使用指定的 HTTP 代理。 - HTTPS_PROXY:设置 HTTPS 代理服务器地址。此变量用于配置 Ollama 在进行 HTTPS 请求时使用的代理服务器,例如
HTTPS_PROXY=https://proxy.example.com:8080可以让 Ollama 使用指定的 HTTPS 代理。 - NO_PROXY:设置不使用代理的地址列表。此变量用于指定哪些地址在进行请求时不使用代理,例如
NO_PROXY=localhost,example.com可以让 Ollama 在访问localhost和example.com时不使用代理.
CLI 命令
Ollama 常用的 CLI 命令见下表:
| 命令 | 用途 |
| ollama serve | 在本地系统上启动 Ollama。 |
| ollama create <new_model> | 从现有模型创建一个新模型,用于定制或训练。 |
| ollama show <model> | 显示特定模型的详细信息,例如其配置和发布日期。 |
| ollama run <model> | 运行指定的模型,使其准备好进行交互。 |
| ollama pull <model> | 将指定的模型下载到您的系统。 |
| ollama list | 列出所有已下载的模型。 |
| ollama ps | 显示当前正在运行的模型。 |
| ollama stop <model> | 停止指定的正在运行的模型。 |
| ollama rm <model> | 从您的系统中移除指定的模型。 |
在终端,输入上面的命令 + '-h',可查看具体命令的帮助文档(如,ollama show -h, 可查看 show 命令的帮助文档)。下面列出每个命令的具体用法和示例。
启动 Ollama
在本地系统上启动 Ollama:ollama server
PS C:\Windows\system32> ollama serve -h
Start ollama
Usage:
ollama serve [flags]
Aliases:
serve, start
Flags:
-h, --help help for serve
Environment Variables:
OLLAMA_DEBUG Show additional debug information (e.g. OLLAMA_DEBUG=1)
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)
OLLAMA_KEEP_ALIVE The duration that models stay loaded in memory (default "5m")
OLLAMA_MAX_LOADED_MODELS Maximum number of loaded models per GPU
OLLAMA_MAX_QUEUE Maximum number of queued requests
OLLAMA_MODELS The path to the models directory
OLLAMA_NUM_PARALLEL Maximum number of parallel requests
OLLAMA_NOPRUNE Do not prune model blobs on startup
OLLAMA_ORIGINS A comma separated list of allowed origins
OLLAMA_SCHED_SPREAD Always schedule model across all GPUs
OLLAMA_FLASH_ATTENTION Enabled flash attention
OLLAMA_KV_CACHE_TYPE Quantization type for the K/V cache (default: f16)
OLLAMA_LLM_LIBRARY Set LLM library to bypass autodetection
OLLAMA_GPU_OVERHEAD Reserve a portion of VRAM per GPU (bytes)
OLLAMA_LOAD_TIMEOUT How long to allow model loads to stall before giving up模型管理
1. 列出所有已下载的模型。
PS C:\Windows\system32> ollama list -h
List models
Usage:
ollama list [flags]
Aliases:
list, ls
Flags:
-h, --help help for list
2. 查看某个模型的详细信息
PS C:\Windows\system32> ollama show -h
Show information for a model
Usage:
ollama show MODEL [flags]
Flags:
-h, --help help for show
--license Show license of a model
--modelfile Show Modelfile of a model
--parameters Show parameters of a model
--system Show system message of a model
--template Show template of a model
Environment Variables:
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)如下图,可查看大模型的参数数量、上下文长度、嵌入长度等信息:
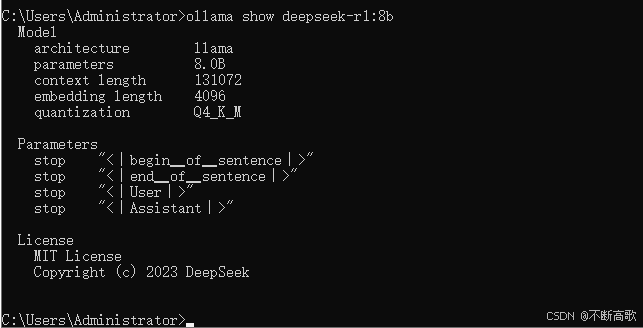
3. 显示正在运行的大模型

4. 停止指定的正在运行的模型
PS C:\Windows\system32> ollama stop -h
Stop a running model
Usage:
ollama stop MODEL [flags]
Flags:
-h, --help help for stop5. 删除已下载的大模型
PS C:\Windows\system32> ollama rm -h
Remove a model
Usage:
ollama rm MODEL [MODEL...] [flags]
Flags:
-h, --help help for rm6. 下载大模型
PS C:\Windows\system32> ollama pull -h
Pull a model from a registry
Usage:
ollama pull MODEL [flags]
Flags:
-h, --help help for pull
--insecure Use an insecure registry7. 运行大模型
PS C:\Windows\system32> ollama run -h
Run a model
Usage:
ollama run MODEL [PROMPT] [flags]
Flags:
--format string Response format (e.g. json)
-h, --help help for run
--insecure Use an insecure registry
--keepalive string Duration to keep a model loaded (e.g. 5m)
--nowordwrap Don't wrap words to the next line automatically
--verbose Show timings for response
技术共进,成长同行——讯飞AI开发者社区
更多推荐
 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)