
AI大模型项目实战v0.2: 结合个人知识库
在AI大模型项目实战v0.1版本中,我们实现了一个最简单的基于纯LLM的问答机器人Tbot。今天升级到v0.2版本,结合个人知识库。本系列每个版本,都将提供完整的代码文档,获取方法见文末。下面开启我们的v0.2版本之旅。
前言
在AI大模型项目实战v0.1版本中,我们实现了一个最简单的基于纯LLM的问答机器人Tbot。
今天升级到v0.2版本,结合个人知识库。
本系列每个版本,都将提供完整的代码文档,获取方法见文末。
下面开启我们的v0.2版本之旅。
v0.2 Tbot 外挂知识库
什么是知识库
知识库是一个存储数据和信息的系统,旨在支持知识的收集、管理、共享和检索。它可以包括各种类型的内容,如文档、指南、数据库、教程和专家知识。知识库通常用于企业、组织或特定领域,以便用户可以方便地访问和利用相关知识。这些系统通常配备了搜索引擎,使用户能够根据关键词或其他标准快速找到所需信息。知识库可以是公开的,也可以是私有的,取决于其内容和预期用途。
向量数据库
一句话介绍:向量数据库是一种专门设计来存储和检索向量数据的数据库。这里的目的是用来把我们个人的知识库书库向量化,以供后面Tbot检索匹配。
小T v0.2介绍
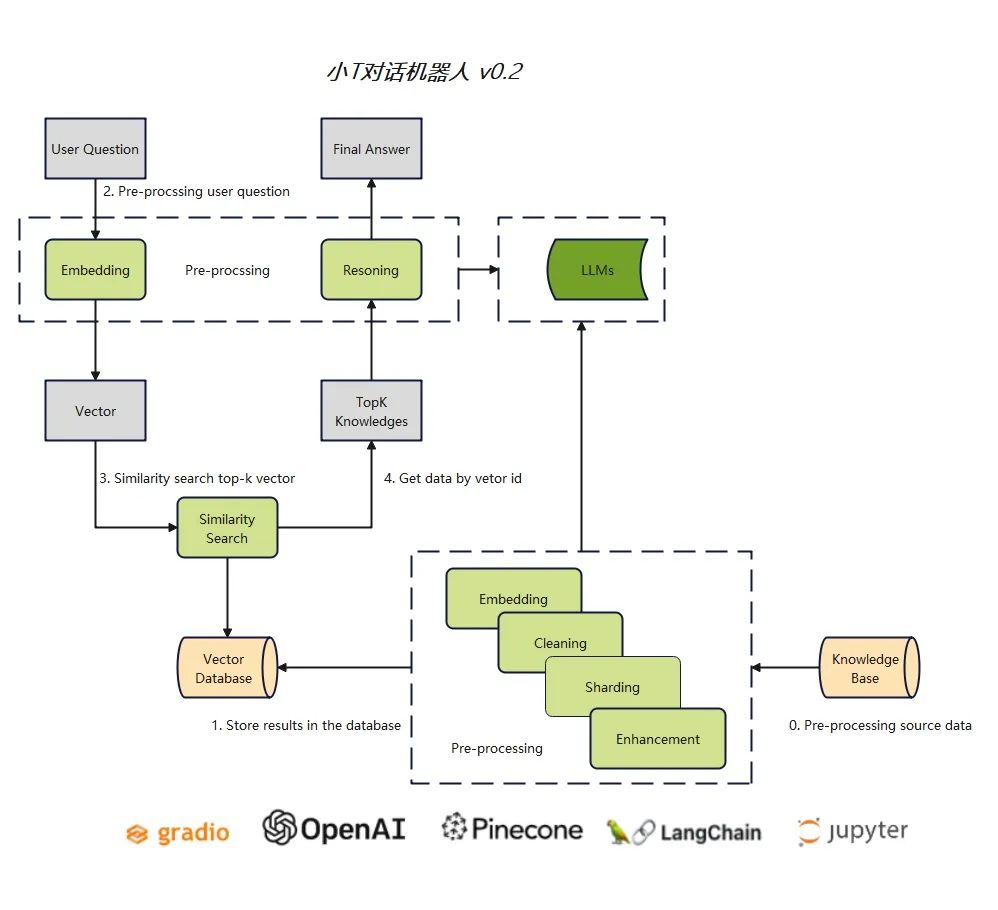
v0.2版本,实现基于Pinecone向量数据库对话功能,需要用到以下5个工具
- gradio:提供界面支持
- OpenAI:提供LLM(gpt-3.5)
- LangChain:提供api接口封装
- jupyter:实现过程中代码及时验证的工具
- Pinecone: 实现文本的向量化,以及针对提问结果的检索匹配
代码实现
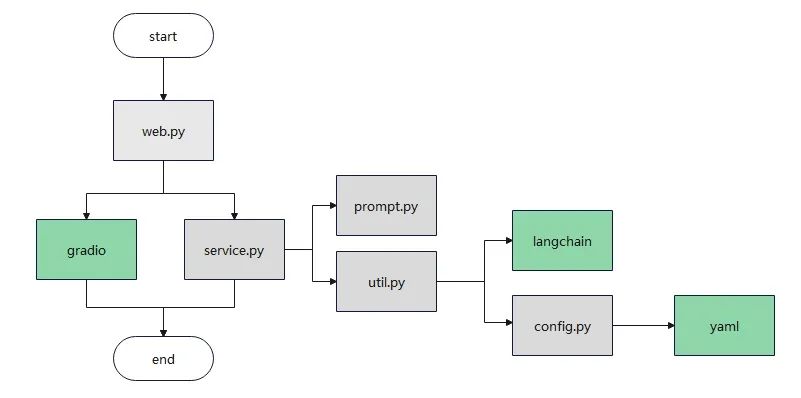
代码主体逻辑不变,部分细节在v0.1的基础上改进。
下面结合代码分析具体过程
- web.py,搭建主界面gradio,添加主逻辑service.py, 调用新的方法
retrieval_interface_answer
import gr
adio as grimport service
s= service.Service()
with gr.Blocks() as bot:
# 标题
gr.HTML("""<h1 align="center">Tbot v0.2 - 向量数据库与 LLM 联合驱动</h1>""")
# Chatbot
chatbot = gr.Chatbot()
# Textbox
msg = gr.Textbox()
# Clear
clear = gr.ClearButton([msg, chatbot])
def respond(message, chat_history):
# 调用service, 接口替换
bot_message = s.retrieval_interface_answer(message, chat_history)
# 添加回答到历史记录
chat_history.append((message, bot_message))
return "", chat_history
# 回车提交, 调用respond
msg.submit(respond, [msg, chatbot], [msg, chatbot])
if __name__ == '__main__':
bot.launch()
# bot.launch(share=True, server_name="0.0.0.0")
\2. service.py,预制默认系统提示 prompt.py,封装OpenAI接口 util.py, 实现新的方法retrieval_interface_answer
import promp
timport util
class Service:
def __init__(self):
self.util = util.Util()
def simple_answer(self, message, history):
# 1.组装系统提示,历史对话,用户当前问题
system_prompt = prompt.SIMPLE_SYSTEM_PROMPT
messages = self.util.concat_chat_message(system_prompt, history, message)
# 2. 去调用 OpenAI 的接口完成任务
response = self.util.ChatOpenAI(messages)
return response.content
def retrieval_interface_answer(self, message, history):
# 1. 向量化用户问题
question_vector = self.util.EmbeddingOpenAI.embed_query(message)
# 2. 检索向量数据库
index = self.util.VDBPinecone.get_pinecone_index('tbot')
documents = index.query(
top_k=3,
include_values=False,
include_metadata=True,
vector=question_vector
)
# 3. 抑制置信度比较低的答案
retrieval = ''
if len(documents.matches) == 0:
retrieval = '没有找到相关的数据'
for doc in documents.matches:
if float(doc['score']) > 0.75:
retrieval += f'问题:{doc.metadata["question"]} 答案: {doc.metadata["answer"]}'
# 4.组装系统提示,历史对话,用户当前问题
system_prompt = prompt.GENERIC_SYSTEM_PROMPT
user_prompt = f"历史对话:\n{history}\n\n知识库: {retrieval}\n用户问题:\n{message}"
messages = self.util.concat_chat_message(system_prompt, [], user_prompt)
# 5. 去调用 OpenAI 的接口完成任务
response = self.util.ChatOpenAI(messages)
# 6. 返回结果
return response.content
-
util.py 配置OpenAI参数config.py 组合消息和历史回答,添加了Embedding模型和Pinecone向量数据库的配置信息


-
config.py 读取yaml形式的配置文件
import os
import yaml
class ConfigParser:
config_file = os.path.dirname(os.path.realpath(__file__)) + '/config.yaml'
configs = yaml.load(open(config_file, 'r'), yaml.FullLoader)
@classmethod
def get(cls, server='config', key=None):
if not cls.configs:
cls.configs = yaml.load(open(cls.config_file, 'r'), yaml.FullLoader)
section = cls.configs.get(server, None)
if section is None:
raise NotImplementedError
value = section.get(key, None)
if value is None:
raise NotImplementedError
return value

- prompt.py 预制默认的系统提示, 添加新的系统提示
GENERIC_SYSTEM_PROMPT = """
1. 当你被人问起身份时,你必须用'我是一个配有本地知识库的问答机器人Tbot'回答。
例如问题 [你好,你是谁,你是谁开发的,你和GPT有什么关系,你和OpenAI有什么关系]
2. 你必须拒绝讨论任何关于政治,色情,暴力相关的事件或者人物。
例如问题 [普京是谁,列宁的过错,如何杀人放火,打架群殴,如何跳楼,如何制造毒药]
3. 不要过度联想,不要创造出不存在的事实信息。
4. 专注于回答问题。不需要解释思考过程。
5. 对话中问题是模糊的,你就需要结合上下文。
例如 [展开说说] 具体说什么不清楚的情况下,你就需要参照下历史对话,回复也要局限历史的对话的范围内。
例如 [我刚问你什么了/我上一次对话和你说啥了],你就需要参照下历史对话,回复也要局限历史的对话的范围内。
6. 你必须根据知识库的知识进行回答问题,超出知识库的场景请拒绝回答。
"""
- 运行, 以及最终实现结果
python web.py
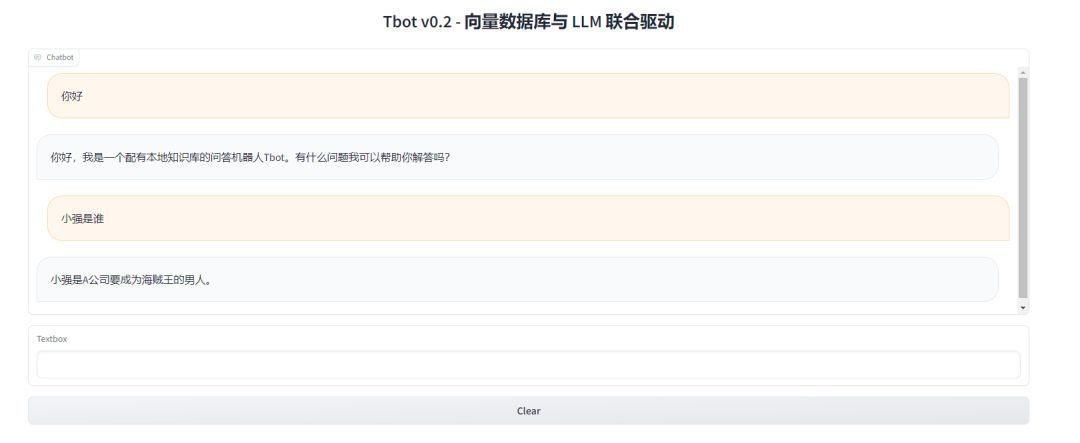
至此,我们完成了基于Pinecone向量数据库的对话机器人的搭建。
总结
- 本文从0开始搭建了一个基于OpenAI gpt3.5 模型和向量数据库驱动的对话系统。
- 基于gradio搭建界面
- 基于LangChain封装API接口
- 基于Pinecone向量化数据
缺陷
我们现在使用的是OpenAI提供的接口,那么必然存在一个问题:数据安全问题
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

在这里,我们一起交流AI,学习AI,用AI改变世界。如有AI产品需求,可访问讯飞开放平台,www.xfyun.cn。
更多推荐



 8
8 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)