
Fish-Speech TTS语音合成本地部署
Fish-Speech TTS本地部署与推理接口文档
·
1. 环境准备
- 操作系统:Windows 10/11(建议使用
cmd或PowerShell) - Python 版本:建议 3.8 ~ 3.10
- 建议使用虚拟环境(venv)
python -m venv venv
venv\\Scripts\\activate
1.1 下载项目代码和模型文件
- 下载 Fish-Speech 项目代码:
git clone https://github.com/yourname/fish-speech.git
cd fish-speech/Fish-Speech
- 下载模型权重文件(推荐使用 huggingface 镜像加速):
# 可选:加速下载
# set HF_ENDPOINT=https://hf-mirror.com
# export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download fishaudio/fish-speech-1.5 --local-dir checkpoints/fish-speech-1.5/
下载完成后,模型文件应位于 checkpoints/fish-speech-1.5/ 目录下。
2. 依赖安装
# 推荐使用 pip 根据 pyproject.toml 安装依赖
pip install .
# 或者使用 pipx
pipx install .
项目采用 pyproject.toml 管理依赖,推荐直接在项目根目录下运行 pip install .。 如遇缺少依赖或报错,根据提示补充安装(如 pip install torch numpy flask 等)。
3. 模型与资源准备
- 下载模型权重,放到
checkpoints/fish-speech-1.5/目录下。 - 确保
firefly-gan-vq-fsq-8x1024-21hz-generator.pth文件在checkpoints/fish-speech-1.5/目录下。 - 准备参考 token 文件(如
fake.npy(下面4.1生成的token文件:这个是中文语音用)、fake1.npy(下面4.1生成的token文件:这个是日文语音用 )),放在项目根目录。
4. 命令行三步推理流程(参考 test1.py)
- Step 1:从参考音频生成 prompt token(fake.npy 或 fake1.npy),reference.wav是中文语音,reference1.wav是日文语音,都是录制好的参考音色文件,用于生成自己想要的音色
python fish_speech/models/vqgan/inference.py -i "reference.wav" --checkpoint-path checkpoints/fish-speech-1.5/firefly-gan-vq-fsq-8x1024-21hz-generator.pth --device cpu
python fish_speech/models/vqgan/inference.py -i "reference1.wav" --checkpoint-path checkpoints/fish-speech-1.5/firefly-gan-vq-fsq-8x1024-21hz-generator.pth --device cpu
- Step 2:从文本生成语义 token(codes_N.npy)
python fish_speech/models/text2semantic/inference.py --text "你好,世界" --prompt-text "发奶龙的小朋友你们好呀,你们的妈已经上天了!" --prompt-tokens "fake.npy" --checkpoint-path checkpoints/fish-speech-1.5 --num-samples 2 --device cpu
python fish_speech/models/text2semantic/inference.py --text "こんにちは、私の名前はそじじょうです。" --prompt-text "やはり、犯人の手がかりはここにあったんだ。時計の針が示す時間と、防犯カメラの映像。そして、被害者の靴の向き。これらすべてが真実を指し示している。真相はいつも一つ!" --prompt-tokens "fake1.npy" --checkpoint-path checkpoints/fish-speech-1.5 --num-samples 2 --device cpu
- Step 3:从语义 token 生成语音(fake.wav)
python fish_speech/models/vqgan/inference.py -i "temp/nailong_codes_1.npy" --checkpoint-path checkpoints/fish-speech-1.5/firefly-gan-vq-fsq-8x1024-21hz-generator.pth --device cpu
python fish_speech/models/vqgan/inference.py -i "temp/nihongimouto_codes_0.npy" --checkpoint-path checkpoints/fish-speech-1.5/firefly-gan-vq-fsq-8x1024-21hz-generator.pth --device cpu
你可以将这三步写入 Python 脚本(如 app.py),实现自动化批量推理。
5. 启动 API 服务
- 确保
app.py已按最新逻辑修改(自动查找 temp 和根目录下的 .npy/.wav 文件)。 - 运行服务:
python app.py
默认监听 http://0.0.0.0:5000,可通过 POST 请求 /generate_speech 接口进行推理。
app.py 主要代码示例
from flask import Flask, request, jsonify, send_file
import os
import sys
import subprocess
import tempfile
import uuid
import logging
import time
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
app = Flask(__name__)
# 添加项目根目录到 Python 路径
project_root = os.path.abspath(os.path.dirname(__file__))
sys.path.insert(0, project_root)
logger.info(f"Project root: {project_root}")
# 创建临时目录
TEMP_DIR = os.path.join(project_root, "temp")
os.makedirs(TEMP_DIR, exist_ok=True)
logger.info(f"Temp directory: {TEMP_DIR}")
def generate_speech(text, language="zh"):
"""
生成语音的主函数
:param text: 要转换的文本
:param language: 语言类型,默认为中文
:return: 生成的语音文件路径
"""
logger.info(f"开始生成语音: text={text}, language={language}")
# 删除生成唯一文件名和相关变量
# unique_id = str(uuid.uuid4())
# codes_file = os.path.join(TEMP_DIR, f"{unique_id}_codes.npy")
# output_file = os.path.join(TEMP_DIR, f"{unique_id}_output.wav")
# logger.info(f"临时文件: codes={codes_file}, output={output_file}")
try:
# 根据语言选择不同的参考音频
if language == 'zh':
prompt_text = "发奶龙的小朋友你们好呀,你们的妈已经上天了!"
prompt_tokens = "fake.npy"
elif language == 'ja':
prompt_text = "やはり、犯人の手がかりはここにあったんだ。時計の針が示す時間と、防犯カメラの映像。そして、被害者の靴の向き。これらすべてが真実を指し示している。真相はいつも一つ!"
prompt_tokens = "fake1.npy"
else:
raise ValueError(f"不支持的语言: {language}")
# 1. 从文本生成语义 token
logger.info("生成语义 token...")
# 使用绝对路径
checkpoint_path = os.path.abspath("checkpoints/fish-speech-1.5")
prompt_tokens_path = os.path.abspath(prompt_tokens)
cmd = [
'python', 'fish_speech/models/text2semantic/inference.py',
'--text', text,
'--prompt-text', prompt_text,
'--prompt-tokens', prompt_tokens_path,
'--checkpoint-path', checkpoint_path,
'--num-samples', '1',
'--device', 'cpu',
'--output-dir', TEMP_DIR
]
logger.info(f"执行命令: {' '.join(cmd)}")
result = subprocess.run(cmd, capture_output=True, text=True)
if result.returncode != 0:
logger.error(f"命令输出: {result.stdout}")
logger.error(f"命令错误: {result.stderr}")
raise Exception(f"生成语义 token 失败: {result.stderr}")
# 等待文件生成
max_wait = 30 # 最大等待时间(秒)
wait_interval = 1 # 检查间隔(秒)
waited = 0
codes_file_found = None
while waited < max_wait:
# 查找 temp 目录下最新的 codes_*.npy 文件
code_files = [f for f in os.listdir(TEMP_DIR) if f.startswith('codes_') and f.endswith('.npy')]
if code_files:
code_files.sort(key=lambda x: os.path.getmtime(os.path.join(TEMP_DIR, x)), reverse=True)
codes_file_found = os.path.join(TEMP_DIR, code_files[0])
break
time.sleep(wait_interval)
waited += wait_interval
logger.info(f"等待 codes_*.npy 文件生成 (已等待 {waited} 秒)")
if not codes_file_found or not os.path.exists(codes_file_found):
raise Exception(f"codes_*.npy 文件未生成")
logger.info(f"找到 codes 文件: {codes_file_found}")
# 2. 从语义 token 生成语音
logger.info("生成语音...")
cmd = [
'python', 'fish_speech/models/vqgan/inference.py',
'-i', codes_file_found,
'--checkpoint-path', os.path.join(checkpoint_path, 'firefly-gan-vq-fsq-8x1024-21hz-generator.pth'),
'--device', 'cpu'
]
logger.info(f"执行命令: {' '.join(cmd)}")
result = subprocess.run(cmd, capture_output=True, text=True)
if result.returncode != 0:
logger.error(f"命令输出: {result.stdout}")
logger.error(f"命令错误: {result.stderr}")
raise Exception(f"生成语音失败: {result.stderr}")
# 等待音频文件生成
waited = 0
output_file_found = None
while waited < max_wait:
logger.info(f"当前项目根目录文件: {os.listdir(project_root)}")
# 只查找项目根目录下最新的 .wav 文件
root_wav_files = [f for f in os.listdir(project_root) if f.endswith('.wav')]
if root_wav_files:
root_wav_files.sort(key=lambda x: os.path.getmtime(os.path.join(project_root, x)), reverse=True)
output_file_found = os.path.join(project_root, root_wav_files[0])
break
time.sleep(wait_interval)
waited += wait_interval
logger.info(f"等待项目根目录 .wav 文件生成 (已等待 {waited} 秒)")
if not output_file_found or not os.path.exists(output_file_found):
logger.error(f"最终未找到 .wav 文件,项目根目录文件: {os.listdir(project_root)}")
raise Exception(f".wav 文件未生成")
logger.info(f"找到音频文件: {output_file_found}")
return output_file_found
except Exception as e:
logger.error(f"生成语音失败: {str(e)}")
return None
@app.route('/generate_speech', methods=['POST'])
def generate_speech_api():
"""
API 接口
请求格式:
{
"text": "要转换的文本",
"language": "zh" # 可选,默认为中文
}
"""
try:
logger.info("收到生成语音请求")
data = request.json
text = data.get('text')
language = data.get('language', 'zh')
logger.info(f"请求参数: text={text}, language={language}")
if not text:
logger.warning("缺少文本参数")
return jsonify({"error": "Text is required"}), 400
# 生成语音
output_file = generate_speech(text, language)
if output_file and os.path.exists(output_file):
logger.info(f"语音生成成功: {output_file}")
return send_file(
output_file,
mimetype='audio/wav',
as_attachment=True,
download_name='output.wav'
)
else:
logger.error("语音生成失败")
return jsonify({"error": "Failed to generate speech"}), 500
except Exception as e:
logger.error(f"处理请求时出错: {str(e)}")
return jsonify({"error": str(e)}), 500
if __name__ == '__main__':
logger.info("启动服务...")
logger.info("服务启动完成,监听端口 5000")
app.run(
host='0.0.0.0',
port=5000,
debug=True,
use_reloader=False,
threaded=False
)
详细完整代码请参考实际项目中的 app.py 文件。
API 请求示例
POST http://localhost:5000/generate_speech
Content-Type: application/json
{
"text": "你好,世界!",
"language": "zh"
}
返回内容为生成的 output.wav 音频文件。
6. 启动 WebUI 推理界面
- 在 Windows 下,命令需写成一行:
python tools/run_webui.py --llama-checkpoint-path checkpoints/fish-speech-1.5 --decoder-checkpoint-path checkpoints/fish-speech-1.5/firefly-gan-vq-fsq-8x1024-21hz-generator.pth
启动后浏览器访问 http://127.0.0.1:7860(或终端提示的端口)即可使用可视化界面。
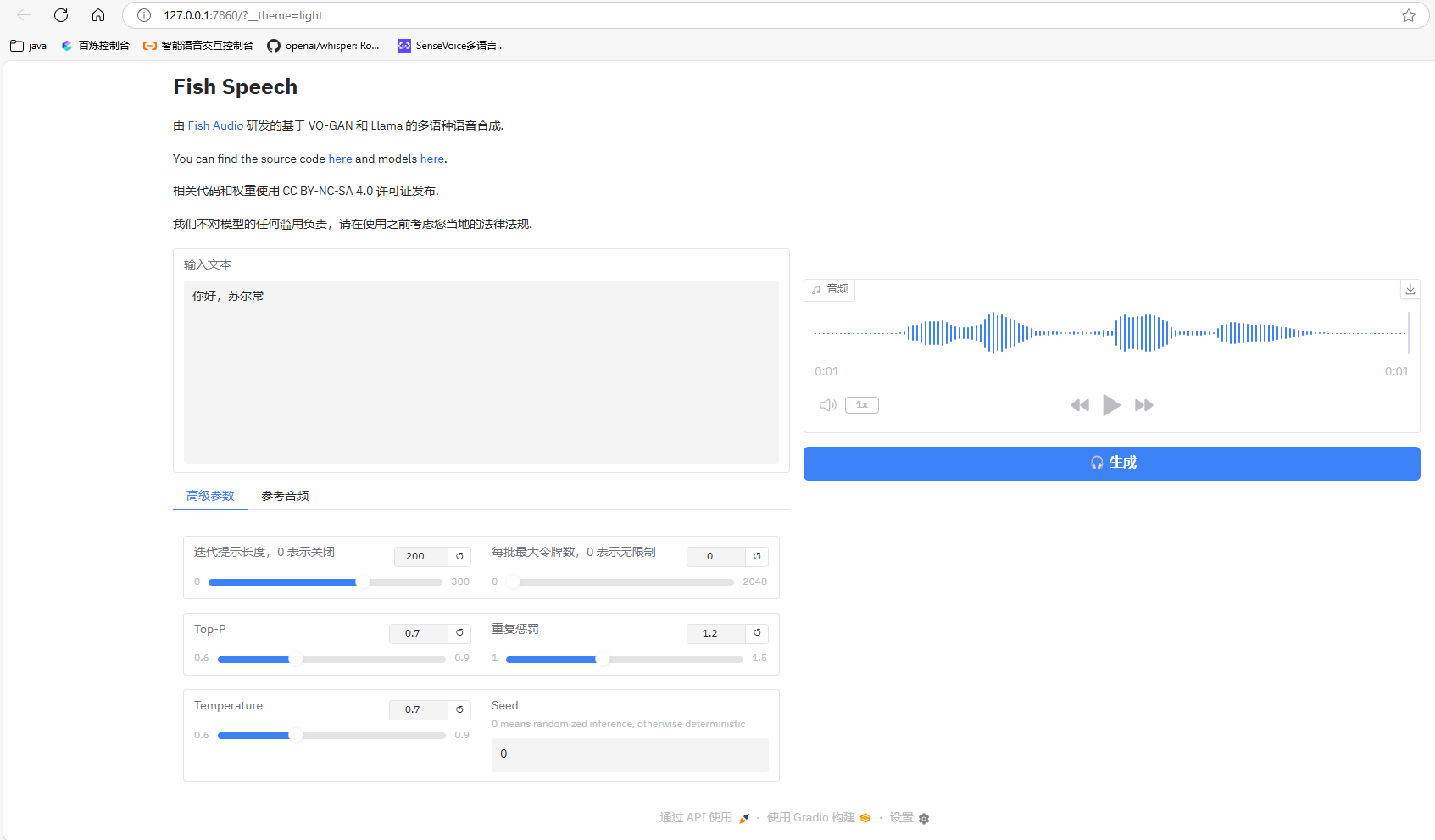
7. 常见问题与排查
- 文件未生成/找不到: 检查
temp和项目根目录下是否有codes_*.npy和.wav文件,确保脚本有写入权限。 - 命令行参数报错: Windows 下所有参数需写在一行,不能用
\\续行。 - 依赖缺失: 按报错提示
pip install 包名补齐。 - 进度条刷屏: 可尝试加
--disable-tqdm或--no-progress,或重定向输出到文件。 - API/推理慢: 检查模型是否在 CPU 上运行,建议有条件时用 GPU。
8. 参考目录结构
Fish-Speech/
├── app.py
├── requirements.txt
├── checkpoints/
│ └── fish-speech-1.5/
│ ├── ...模型文件...
│ └── firefly-gan-vq-fsq-8x1024-21hz-generator.pth
├── fake.npy ...prompt token文件...
├── fake1.npy ...prompt token文件...
├── temp/
│ ├── codes_0.npy ...token文件...
│ ├── codes_1.npy ...token文件...
├── ...生成的音频文件...
└── tools/
└── run_webui.py
9. 联系与支持
如遇到无法解决的问题,请将报错信息、日志截图等详细内容反馈给开发者或社区。

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)