
大模型学习:Qwen2.5-Coder 本地部署
前段时间,阿里开源了 Qwen2.5-Coder 系列模型,其中 32B 模型在十余项基准评测中均取得开源最佳成绩。无愧全球最强开源代码模型,在多项关键能力上甚至超越 GPT-4o。
·
前段时间,阿里开源了 Qwen2.5-Coder 系列模型,其中 32B 模型在十余项基准评测中均取得开源最佳成绩。
无愧全球最强开源代码模型,在多项关键能力上甚至超越 GPT-4o。
1.1 模型下载
关于下载多大的模型,可根据自己的显存进行选择,32B 模型至少确保 24G 显存。
我的显卡只有8G,所以下面我以 7b 模型来介绍怎么部署:
ollama pull qwen2.5-coder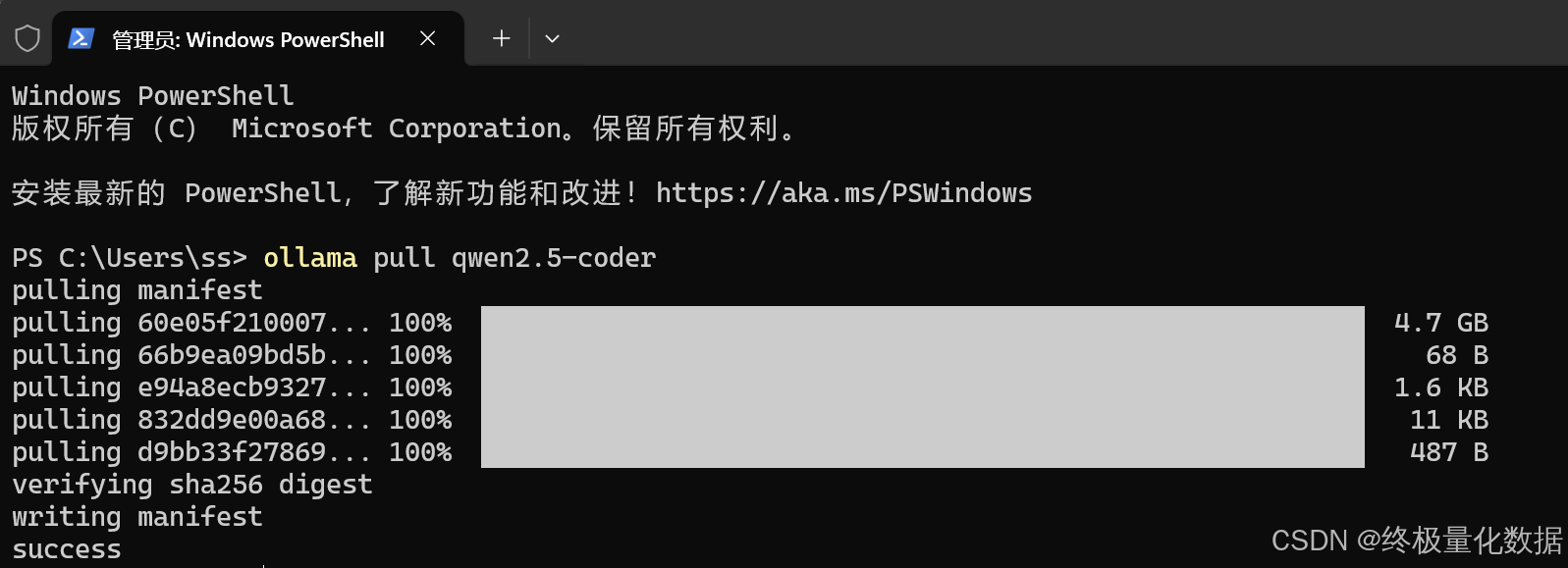
1.2 模型修改
因为Ollama 的默认最大输出为 4096 个token,对于代码生成这种复杂任务而言,显然是不够的。
为此,我们需要修改模型参数,增加上下文 Token 数量
首先,我们在模型存放目录新建 一个Modelfile 文件,然后填入:
FROM qwen2.5-coder
PARAMETER num_ctx 32768然后,我们在powershell开始模型转换
ollama create -f Modelfile qwen2.5-coder-extra-ctx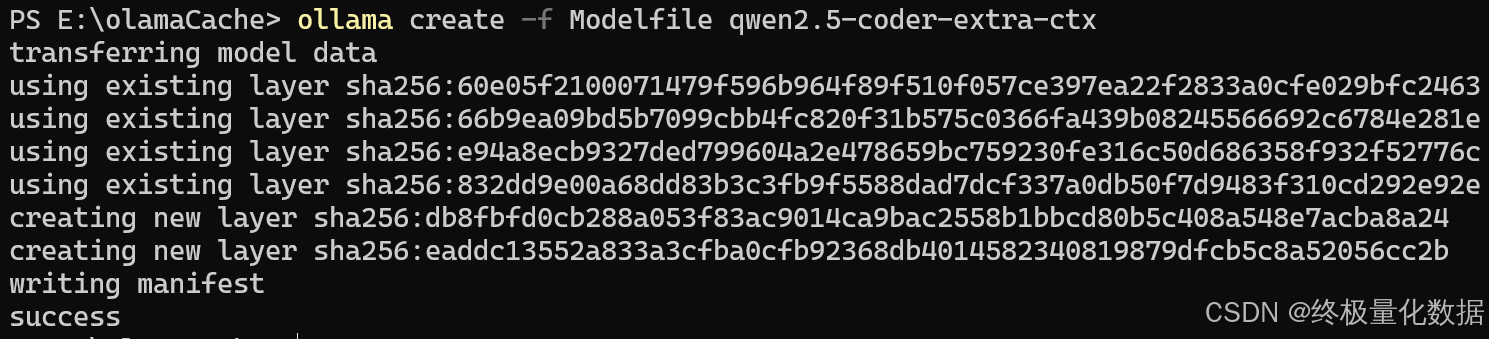
转换成功后,我们查看模型列表
ollama list
也可以从模型缓存目录查看到
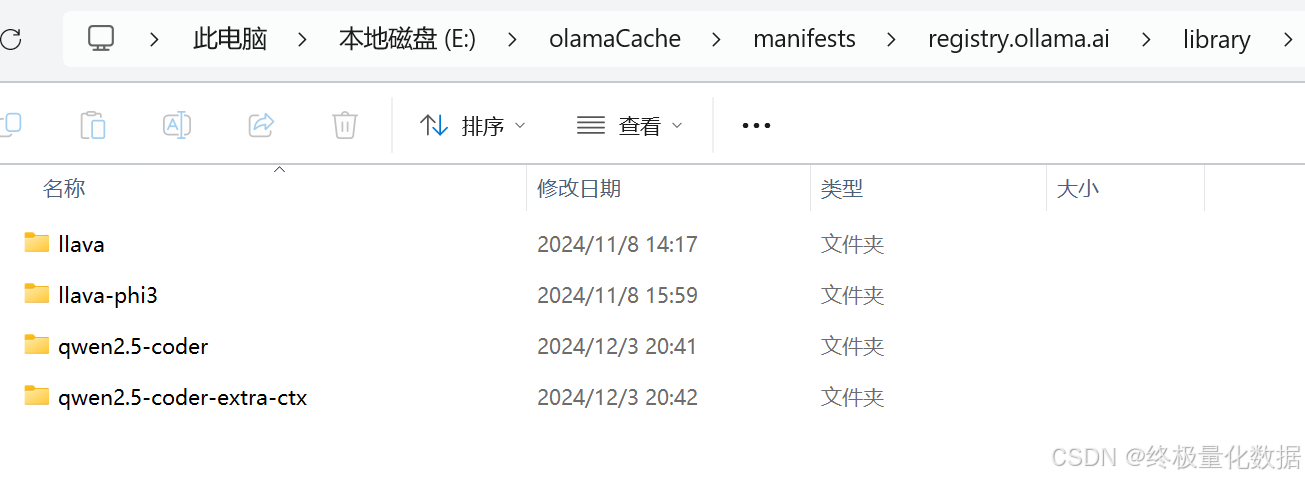
2.3 模型运行
测试模型运行,我们定义下调用函数,在python环境测试
def test_ollama():
url = 'http://localhost:11434/api/chat'
data = {
"model": "qwen2.5-coder-extra-ctx",
"messages": [
{ "role": "user", "content": 'ai coding'}
],
"stream": False
}
response = requests.post(url, json=data)
if response.status_code == 200:
text = response.json()['message']['content']
print(text)
else:
print(f'{response.status_code},失败')如果没什么问题,就可以在 bolt.new 中调用了
今天的大模型介绍就到这里了,感谢能看到这里的朋友😉
本次的分享就到这里,【终极量化数据】致力于为大家分享技术干货😎
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正😅
受益的朋友或对技术感兴趣的伙伴记得点赞关注支持一波🙏
也可以搜索关注我的微信公众号【终极量化数据】,留言交流🙏

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)