

sql 机器学习
If you’ve been studying data science, it’s likely you know how to perform machine learning tasks in languages like Python, R, and Julia. But what can you do when speed is the key, the hardware is limited, or the company you work for treats SQL as the only option for predictive analytics? In-database machine learning is the answer.
如果您一直在研究数据科学,那么您很可能知道如何使用Python , R和Julia这样的语言执行机器学习任务。 但是,当速度是关键,硬件有限或您工作的公司将SQL视为预测分析的唯一选择时,您该怎么办? 数据库内机器学习就是答案。
We’ll use Oracle Cloud for this article. It’s free, so please register and create an instance of the OLTP database (Version 19c, has 0.2TB of storage). Once done, download the cloud wallet and establish a connection through SQL Developer — or any other tool.
本文将使用Oracle Cloud 。 它是免费的,因此请注册并创建OLTP数据库实例(版本19c,具有0.2TB的存储空间)。 完成后,下载云钱包并通过SQL Developer或任何其他工具建立连接。
This will take you 10 minutes at least but is a fairly straightforward thing to do, so I won’t waste time on it.
这至少要花10分钟,但这是一件很简单的事情,所以我不会在上面浪费时间。
We’ll use Oracle Machine Learning (OML) to train a classification model on the well-known Iris dataset. I’ve chosen it because it doesn’t require any preparation — we only need to create the table and insert the data.
我们将使用Oracle Machine Learning(OML)在著名的Iris数据集上训练分类模型。 我选择它是因为它不需要任何准备-我们只需要创建表并插入数据即可。
Let’s do that next.
让我们接下来做。
资料准备 (Data preparation)
As mentioned, we need to create a table for holding the Iris dataset, and then we need to load data to it. OML requires one column to be used as row ID (sequence), so let’s keep that in mind:
如前所述,我们需要创建一个表来保存虹膜数据集,然后将数据加载到该表中。 OML需要将一列用作行ID(序列),因此请记住这一点:
CREATE SEQUENCE seq_iris;
CREATE TABLE iris_data(
iris_id NUMBER DEFAULT seq_iris.NEXTVAL,
sepal_length NUMBER,
sepal_width NUMBER,
petal_length NUMBER,
petal_width NUMBER,
species VARCHAR2(16)
);Awesome! Now we can download the data and load it:
太棒了! 现在我们可以下载数据并加载它:
When a modal window pops-up simply provide a path to the downloaded CSV and click Next a couple of times. SQL Developer should get things right without your assistance.
弹出模式窗口时,只需提供下载的CSV的路径,然后单击几次Next 。 SQL Developer应该在没有您帮助的情况下正确解决问题。
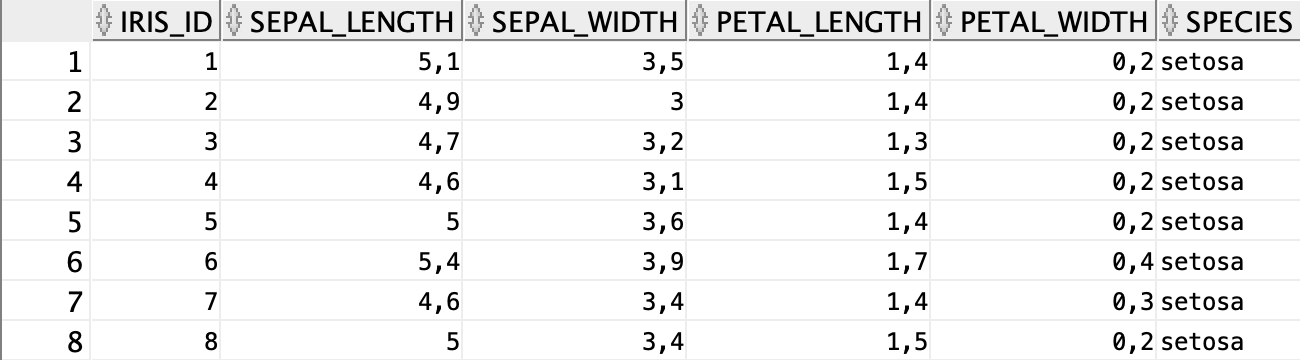
Once done, we have our dataset loaded and prepared:
完成后,我们将加载并准备好数据集:
Let’s continue with the fun part now.
现在让我们继续有趣的部分。
模型训练 (Model training)
Now we can get our hands dirty with the fun stuff, and that’s training the classification model. This is broken down into multiple steps, such as train/test split, model training, and model evaluation. Let’s start with the simplest one.
现在,我们可以将有趣的东西弄脏,这就是训练分类模型的方法。 这分为多个步骤,例如训练/测试拆分,模型训练和模型评估。 让我们从最简单的一个开始。
训练/测试拆分 (Train/test split)
Oracle likes this step done with two views — one for training data and one for testing data. We can easily create those with a bit of PL/SQL magic:
Oracle喜欢用两个视图完成此步骤-一个用于培训数据,一个用于测试数据。 我们可以用一点PL / SQL魔术轻松地创建它们:
BEGIN
EXECUTE IMMEDIATE
‘CREATE OR REPLACE VIEW
iris_train_data AS
SELECT * FROM iris_data
SAMPLE (75) SEED (42)’;
EXECUTE IMMEDIATE
‘CREATE OR REPLACE VIEW
iris_test_data AS
SELECT * FROM iris_data
MINUS
SELECT * FROM iris_train_data’;
END;
/This script does two things:
该脚本有两件事:
-
Creates a train view — has 75% of data (
SAMPLE (75)) split at the random seed 42 (SEED (42))创建一个火车视图 -在随机种子42(
SEED (42))处拆分了75%的数据(SAMPLE (75)SEED (42)) -
Creates a test view — as a difference of the entire dataset and the training view
创建一个测试视图 -作为整个数据集和训练视图的区别
Our data is stored in views named iris_train_data and iris_test_data — you guess which one holds what.
我们的数据存储在名为iris_train_data和iris_test_data ,您可能会猜中哪一个。
Let’s quickly check how many rows are in each:
让我们快速检查每一行中有多少行:
SELECT COUNT(*) FROM iris_train_data;>>> 111
SELECT COUNT(*) FROM iris_test_data;>>> 39We are ready to train the model, so let’s do that next.
我们已经准备好训练模型了,接下来让我们开始。
模型训练 (Model training)
The easiest method for model training is through DBMS_DATA_MINING package, with a single procedure execution, and without the need for creating additional settings tables.
最简单的模型训练方法是通过DBMS_DATA_MINING包,只需执行一个过程,而无需创建其他设置表。
We’ll use the Decision Tree algorithm to train our model. Here’s how:
我们将使用决策树算法来训练我们的模型。 这是如何做:
DECLARE
v_setlst DBMS_DATA_MINING.SETTING_LIST;
BEGIN
v_setlst(‘PREP_AUTO’) := ‘ON’;
v_setlst(‘ALGO_NAME’) := ‘ALGO_DECISION_TREE’;
DBMS_DATA_MINING.CREATE_MODEL2(
‘iris_clf_model’,
‘CLASSIFICATION’,
‘SELECT * FROM iris_train_data’,
v_setlst,
‘iris_id’,
‘species’
);
END;
/The CREATE_MODEL2 procedure (curious why it wasn’t named CREATE_MODEL_FINAL_FINAL89) accepts a lot of parameters. Let’s explain the ones we entered:
CREATE_MODEL2过程(很好奇为什么未将其命名为CREATE_MODEL_FINAL_FINAL89 )接受很多参数。 让我们解释一下我们输入的内容:
-
iris_clf_model— simply the name of your model. Can be anythingiris_clf_model—只是模型的名称。 可以是任何东西 -
CLASSIFICATION— type of machine learning task we’re doing. Must be uppercase for some reasonCLASSIFICATION-我们正在执行的机器学习任务的类型。 由于某种原因必须大写 -
SELECT * FROM iris_train_data— specifies where the training data is storedSELECT * FROM iris_train_data—指定训练数据的存储位置 -
v_setlst— above declared settings list for our modelv_setlst模型的声明设置列表上方 -
iris_id— name of the sequence type column (each value is unique)iris_id—序列类型列的名称(每个值都是唯一的) -
species— name of the target variable (what we’re trying to predict)species-目标变量的名称(我们正在尝试预测的变量)
Executing this block will take a second or two, but once done it’s ready for evaluation!
执行此块将需要一两秒钟,但是一旦完成,就可以进行评估了!
模型评估 (Model evaluation)
Let’s use this script to evaluate our model:
让我们使用此脚本评估模型:
BEGIN
DBMS_DATA_MINING.APPLY(
‘iris_clf_model’,
‘iris_test_data’,
‘iris_id’,
‘iris_apply_result’
);
END;
/It applies iris_clf_model to the unseen test data iris_test_data and stores evaluation results into a iris_apply_result table. Here’s how this table looks like:
它将iris_clf_model应用于看不见的测试数据iris_test_data并将评估结果存储到iris_apply_result表中。 该表的外观如下:
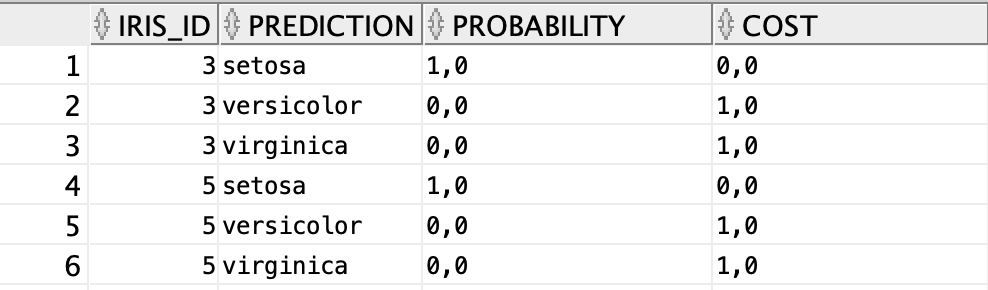
It has many more rows (39 x 3), but you get the point. This still isn’t the most straightforward thing to look at, so let’s show the results in a slightly different way:
它有更多的行(39 x 3),但是您明白了。 这仍然不是最简单的方法,因此让我们以稍微不同的方式显示结果:
DECLARE
CURSOR iris_ids IS
SELECT DISTINCT(iris_id) iris_id
FROM iris_apply_result
ORDER BY iris_id;
curr_y VARCHAR2(16);
curr_yhat VARCHAR2(16);
num_correct INTEGER := 0;
num_total INTEGER := 0;
BEGIN
FOR r_id IN iris_ids LOOP
BEGIN
EXECUTE IMMEDIATE
‘SELECT species FROM
iris_test_data
WHERE iris_id = ‘ || r_id.iris_id
INTO curr_y;
EXECUTE IMMEDIATE
‘SELECT prediction
FROM iris_apply_result
WHERE iris_id = ‘ || r_id.iris_id ||
‘AND probability = (
SELECT MAX(probability)
FROM iris_apply_result
WHERE iris_id = ‘ || r_id.iris_id ||
‘)’ INTO curr_yhat;
END;
num_total := num_total + 1;
IF curr_y = curr_yhat THEN
num_correct := num_correct + 1;
END IF;
END LOOP;
DBMS_OUTPUT.PUT_LINE(‘Num. test cases: ‘
|| num_total);
DBMS_OUTPUT.PUT_LINE(‘Num. correct : ‘
|| num_correct);
DBMS_OUTPUT.PUT_LINE(‘Accuracy : ‘
|| ROUND((num_correct / num_total), 2));
END;
/Yes, it’s a lot, but the script above can’t be any simpler. Let’s break it down:
是的,很多,但是上面的脚本再简单不过了。 让我们分解一下:
-
CURSOR— gets all distinct iris_ids (because we have them duplicated iniris_apply_resultstableCURSOR—获取所有不同的iris_id(因为我们将它们复制到iris_apply_results表中 -
curr_y,curr_yhat,num_correct,num_totalare variables for storing actual species and predicted species at every iteration, number of correct classifications, and total number of test itemscurr_y,curr_yhat,num_correct,num_total是用于存储每次迭代时的实际种类和预测种类,正确分类的数量以及测试项目总数的变量 -
For every unique
iris_idwe get the actual species (fromiris_test_data, where ids match) and the predicted species (where prediction probability is the highest iniris_apply_resultstable)对于每个唯一的
iris_id我们获得实际种类(从ids匹配的iris_test_data中获得)和预测的种类(其中iris_apply_results表中的预测概率最高) - Then it’s easy to check if the actual and predicted values are identical — which indicates the classification is correct 然后,很容易检查实际值和预测值是否相同-这表明分类是正确的
-
Variables
num_totalandnum_correctare updated at every iteration每次迭代都会更新变量
num_total和num_correct - Finally, we print the model’s performance to the console 最后,我们将模型的性能打印到控制台
Here’s the output for this script:
这是此脚本的输出:

Awesome! To interpret:
太棒了! 解释:
- The test set has 39 cases 测试集有39个案例
- Of these 39, 37 were classified correctly 在这39个中,有37个被正确分类
- Which results in the 95% accuracy 准确率达到95%
And that’s pretty much it for the model evaluation.
这几乎足以用于模型评估。
你走之前 (Before you go)
And there you have it — machine learning project written from scratch in SQL. Not all of us have the privilege to work with something like Python on our job, and if a machine learning task comes on your desk you now know how to solve it via SQL.
一切就在这里-用SQL从头开始编写的机器学习项目。 并非所有人都有特权在我们的工作中使用Python之类的东西,并且如果您的办公桌上出现了机器学习任务,您现在知道如何通过SQL解决它。
This was just a simple classification task, of course, and scripts can be improved further, but you get the point. I hope you’ve managed to follow along. For any questions and comments, please refer to the comment section.
当然,这只是一个简单的分类任务,脚本可以进一步改进,但是您明白了。 希望您能继续努力。 如有任何疑问和意见,请参阅评论部分。
Thanks for reading.
谢谢阅读。
Originally published at https://www.betterdatascience.com on September 6, 2020.
最初于 2020年9月6日 发布在 https://www.betterdatascience.com 上。
翻译自: https://towardsdatascience.com/machine-learning-with-sql-its-easier-than-you-think-c6aae9064d5a
sql 机器学习








 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)