
项目快过(图像超分|知识蒸馏)| SRModelCompression | Compressing Deep Image Super-resolution Models
项目地址:https://github.com/Pikapi22/SRModelCompression论文地址:https://arxiv.org/pdf/2401.00523发表时间:2024年2月21日深度学习技术已被应用于图像超分辨率(SR)领域,在重建性能方面取得了显著的进展。现有的技术通常采用高度复杂的模型结构,这将导致较大的模型规模和缓慢的推理速度。这往往导致高能耗,并限制了其在实际应

项目地址:https://github.com/Pikapi22/SRModelCompression
论文地址:https://arxiv.org/pdf/2401.00523
发表时间:2024年2月21日
深度学习技术已被应用于图像超分辨率(SR)领域,在重建性能方面取得了显著的进展。现有的技术通常采用高度复杂的模型结构,这将导致较大的模型规模和缓慢的推理速度。这往往导致高能耗,并限制了其在实际应用中的采用。为了解决这个问题,这项工作采用了一个三阶段的工作流来压缩深度SR模型,这大大降低了它们的内存需求。通过使用新设计的蒸馏损失进行教师知识蒸馏来保持恢复性能。我们已经将这种方法应用于两种流行的图像超分辨率网络,SwinIR和EDSR,以证明其有效性。由此得到的紧凑模型SwinIRmini和EDSRmini与原始版本相比,模型大小和浮点操作(FLOPs)分别减少了89%和96%。与原始模型和其他常用的SR方法相比,它们还保持了具有竞争力的超分辨率性能。
本项目主要是分享了一种模型压缩思路:先模型剪枝(得到学生模型的结构)、在进行知识蒸馏;同时分享了,模型稀疏化训练配置(用于模型剪枝后生成学生模型的结构)代码、知识蒸馏代码。本文并为展示图像超分领域另3个常见数据集(BSD100、Urban100、Manga109)的精度信息,个人猜测应该是有所下降。但分享的相关代码还是及其有效的。1、整体设计
1.1 技术pipeline
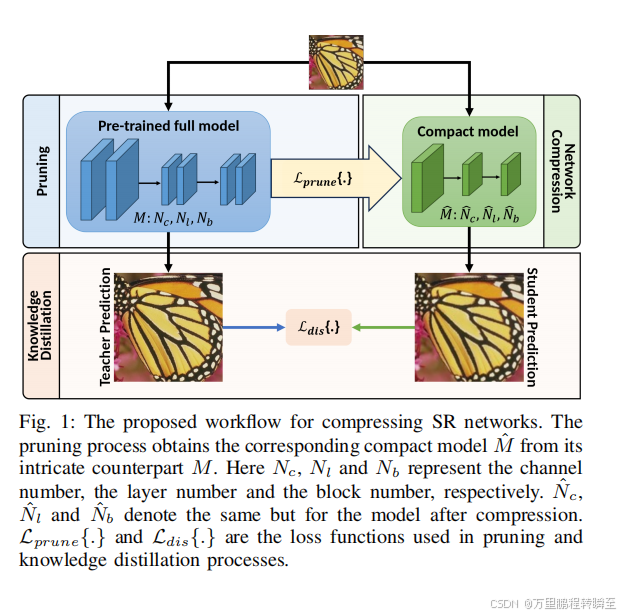
在此背景下,我们针对图像的超分辨率,提出了一种新的网络压缩框架,如图1所示,它集成了模型剪枝和知识蒸馏,在保持SR性能的同时显著降低了模型的复杂度。该方法首先将稀疏性诱导优化应用于原始网络,然后基于一种新的参数分布分析方法将其压缩为一个紧凑的模型。然后通过改进损失的知识精馏,进一步提高了压缩模型的性能。据我们所知,这是第一次尝试结合剪枝和蒸馏技术来进行SR模型压缩。我们已经将其应用于两种流行的SR模型,EDSR和SwinIR,它们所产生的紧凑模型实现了显著的模型大小和FLOPs(高达96%)的减少,显著优于其他具有类似复杂度数字的SR方法。
核心就是:先剪枝,再知识蒸馏。
模型剪枝:1、进行稀疏化训练=》2、根据参数分布分析进行剪枝
1.2 网络结构
图2显示了一种常用的用于图像超分辨率的高级网络架构。它包括三个整体模块:浅层特征提取模块、深度特征提取模块和图像重建模块。浅层特征提取模块通常采用少量的卷积层来提取包含基本低频信息的浅层特征。网络的核心在于深度特征提取模块,该模块细致地获得复杂而高的高级特征,在塑造系统的整体性能和能力方面发挥着关键作用。最终,浅层和深层特征在重建模块内收敛,以促进创建高质量的图像重建。由于网络结构(主要在深度特征提取模块中)由一堆基本处理块组成,其复杂性和性能与通道数Nc、每个块内的层计数(不包括输出前的卷积层)Nl和这些块的总数Nb密切相关。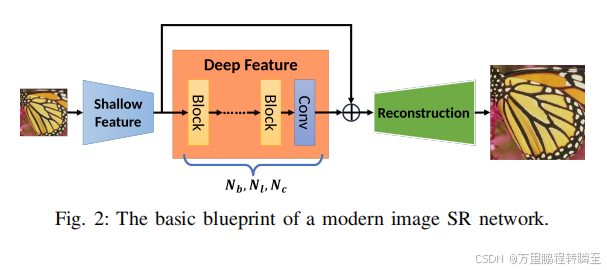
2、核心操作
2.1 模型剪枝
为了获得一个模型的压缩版本,从原始的预先训练过的模型开始,并使用以下损失函数对其进行微调。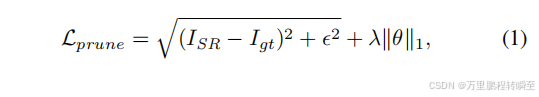
其中 I g t I_{gt} Igt表示地面真实目标图像, I S R I_{SR} ISR对应超分辨输出,ϵ设置为10−3,λ>0为正则化常数,设置为 1 0 − 4 10^{−4} 10−4。初始模型的参数用θ表示,∥·∥1为L1范数正则化项,可促进网络稀疏性。这种稀疏性信息可以作为去除网络中冗余层的指导。我们采用OBProx-SG来进行梯度优化。最终,得到了一个密度比d,即非零参数的比值。与在[32,33]中采用的方法相比,他们计算了每一层的密度比,我们计算了整个深度特征模块。然后,我们将在降低复杂性的下一步中使用这个比率。
其实质是先对原始模型进行稀疏化训练,使用L1正则化方法,是大量参数为0;然后计算非0参数的比例,然后进行全局剪枝;
2.2 网络压缩
与[33]中描述的方法相反,压缩只关注channel,这里我们进一步分析了三个超参数Nc(通道的数量)、Nl(层数)和Nb(深度特征提取块的数量)。具体来说,我们考虑了深度特征提取模块PDF的模型参数的总数,它可以大约写成: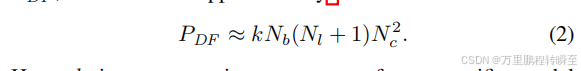
这里,k是一个特定模型结构的近似常数。利用在模型剪枝阶段计算的密度比d,通过更新这三个关键超参数以满足以下要求,我们可以得到一个紧凑的模型: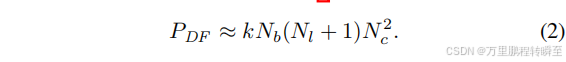
这里的本质就是模型剪枝过程中对layer的选择、网络结构的选择、block数量的选择;很花哨,作用应该不大。使用正常剪枝代码即可。
2.3 知识蒸馏
在得到紧凑的模型后,我们采用类似于[33]的知识蒸馏方法,利用预先训练好的原始模型作为“教师”来指导训练过程,进一步提高了剪枝模型的性能。具体来说,知识蒸馏的总损失总额如下: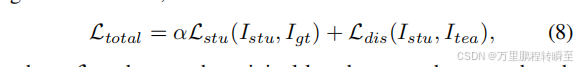
其中, L s t u L_{stu} Lstu表示地面真实的 I g t I_{gt} Igt和学生模型的预测Istu(用于训练原始的完整的SR模型)之间的原始损失,α是一个可调的权重, I d i s I_{dis} Idis代表学生 L s t u L_{stu} Lstu和老师的预测 L t e a L_{tea} Ltea之间的损失。在这项工作中,蒸馏损失, I d i s I_{dis} Idis,计算如下: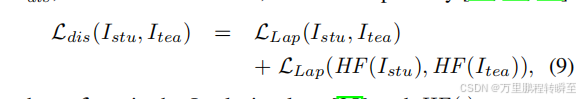
其中, L L a p L_{Lap} LLap为拉普拉斯损失[35],HF(·)表示由5×5高斯模糊核函数提取的高频特征。包括高频特性损失,以进一步提高输出的锐度和整体质量。
通过所设计的蒸馏loss,可以发现没有完全使用教师网络的输出来引导学生网络,还引用了教师网络输出的边缘信息(HF函数的输出)进行引导。
3、实践效果
为了证明工作流程的有效性,将其应用于两种流行的图像超分辨率模型: EDSR [10]和SwinIR [16]。前者是一种广泛使用的基于cnn的模型,而SwinIR是基于transformer的,并提供了最先进的SR性能。紧凑的模型是从他们现有的轻量级版本,EDSR_baseline和SwinIR_lightweight(LW),由他们的原始作者报告。我们将我们的紧凑型模型分别称为EDSRmini和SwinIRmini。
3.1 实验超参数
训练集:DIV2K [36],为模型修剪和知识蒸馏
具体来说,使用来自DIV2K数据集的100幅图像进行模型剪枝操作,并在知识蒸馏步骤中使用整个DIV2K。
训练期间,AdaMax优化器,β1 = 0.9和β2 = 0.99, 超参数α设置为0.1。
为了压缩SwinIR模型,通过对SwinIR_LW网络进行稀疏化训练100个周期,得到了约为0.089的密度,并将其作为压缩率。
在此基础上,计算SwinIRmini的ˆNc、ˆNl和ˆNb。它们的值分别为24、4和3。SwinIRmini的结果参数总数为98.8K(SwinIR_LW为878K)。
同样,通过优化EDSR_baseline网络,其密度约为0.03,EDSRmini的ˆNc、ˆNl和ˆNb分别计算为16、1和8,总参数为49.6K(EDSR_baseline为1.37M)。
这里一共隐含2点知识:
1、进行模型剪枝中的稀疏化训练时,只需要应用少部分数据即可,不需要全部数据(原始数据的)
2、模型剪枝中模型结构比较重要
该评估是在Set5 [37]和Set14 [38]数据集上进行的,这些数据通常用于对超分辨率模型进行基准测试。两种广泛使用的质量指标,峰值信噪比(PSNR)和结构相似度(SSIM)[39],被用来衡量模型的性能。所有实验均使用NVIDIA RTX 3090 GPU进行。
3.2 定量分析
表一总结了我们的方法与一些现有的深度SR方法之间的定量比较的结果。值得注意的是,所有基准结果的性能结果和复杂性数据都取自它们的原始论文。可以观察到,所得到的紧凑模型EDSRmini和SwinIRmini提供的模型尺寸比基线模型EDSR_baseline和SwinIR_LW要小得多,分别为4%和11%。它们还需要更少的flop,分别占基线的4%和11%。然而,与原始模型相比,EDSRmini和SwinIRmini的平均性能损失最小,分别为0.34 dB和0.26 dB。 通过表格就可以发现,作者选择的基线模型(原创者提出),就已经比全量模型要轻量很多,而且他们也是降低了30倍(EDSR)与10倍(SwinIR)的flop,PSNR在set14上的下降量与本论文作者的量级相同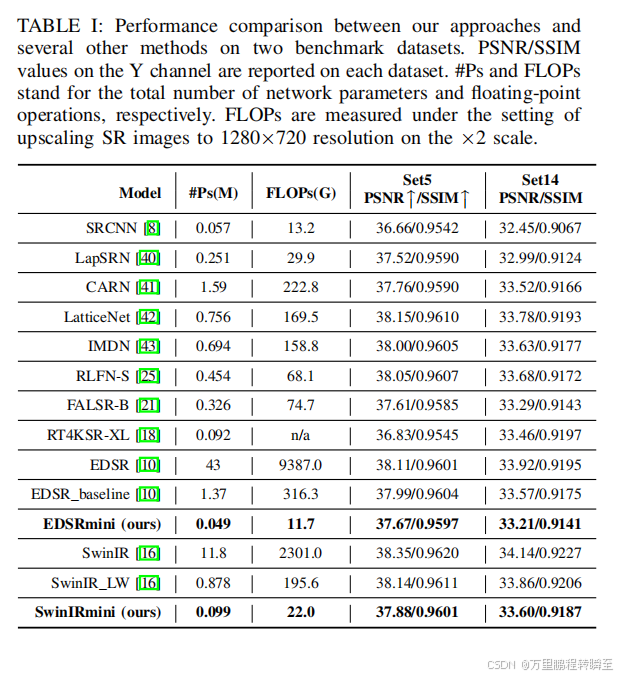
从这图4的2子图中都可以看出,EDSRmini和SwinIRmini在复杂性和性能之间实现了优越的权衡。例如,SwinIRmini在相当数量的参数上比RT4KSR-XL高出近0.6 dB。整体来看本文作者方法是将原先已经被高度压缩的模型,进行了二次压缩;二次压缩后PSNR下降量与第一次压缩近乎是等比例的(这十分难得)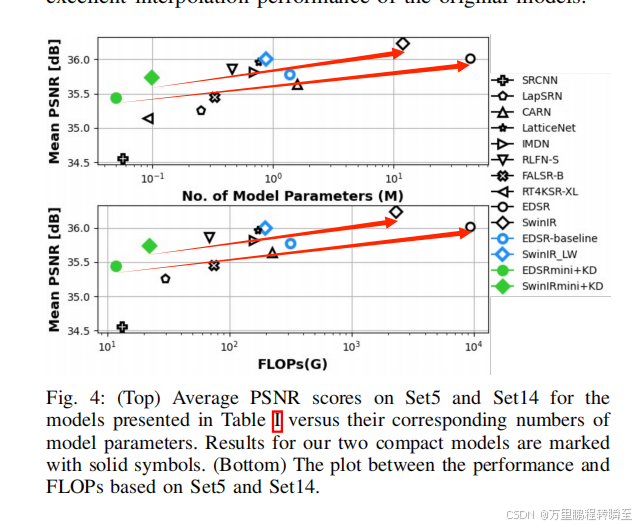
3.3 定性评价
图3显示了使用我们的紧凑模型及其相应的原始版本的SR输出示例,以进行可视化比较。紧凑模型和其对应模型产生的结果在很大程度上无法区分,证明了我们的复杂性降低方法的有效性。该方法不仅显著减少了参数和流量的数量,而且保持了原模型良好的插值性能。
4、代码分析
打开 https://github.com/Pikapi22/SRModelCompression ,下载项目代码
4.1 稀疏化训练配置
这里并没有提供模型剪枝的代码,只是提供了模型稀疏化训练的配置文件。主要观察网络结构配置与train配置,原始信息来自options\train\SwinIR\prune_SwinIRlight_SRx2.yml
# network structures
network_g:
type: SwinIR
upscale: 2
in_chans: 3
img_size: 64
window_size: 8
img_range: 1.
depths: [6, 6, 6, 6]
embed_dim: 60
num_heads: [6, 6, 6, 6]
mlp_ratio: 2
upsampler: 'pixelshuffledirect'
resi_connection: '1conv'
# path
path:
pretrain_network_g: experiments/pretrained_models/002_lightweightSR_DIV2K_s64w8_SwinIR-S_x2.pth
strict_load_g: true #false
resume_state: ~
# training settings
train:
ema_decay: 0.999
optim_g:
type: OBProxSG
lr: !!float 5e-3
lambda_: !!float 1e-4
# L1 regularization weight
epochSize: 32592
# number of batches per epoch: num_iter_per_epoch*(dataset_opt['batch_size_per_gpu'] * opt['world_size'])
eps: 0.0001
# one from AdaCoF
Np: 25
# int(args.epochs / 10) one from AdaCoF
scheduler:
type: MultiStepLR
milestones: ~
gamma: 0.5
total_iter: 500000
warmup_iter: -1 # no warm up
# losses
pixel_opt:
type: CharbonnierLoss
loss_weight: 1.0
reduction: mean
可以发现,其是配置optim为OBProxSG,基于lambda_设置l1正则化参数,然后对模型进行稀疏化训练。得出模型的稀疏率,基于稀疏率重新设计了模型结构。
4.2 知识蒸馏配置
信息来自:options\train\SwinIR\distill_SwinIRmini_SRx2_scratch_kd.yml
其中最为重要的是model_type配置为SRModelKD,这是一个作者自行实现的SRModel类。
然后就是tea_network_g与tea_path配置了教师模型参数
network_g配置了学生模型参数,dis_opt与stu_opt设置了蒸馏loss与学生模型loss。这些配置项将在SRModelKD类中生效。
# general settings
name: train_SwinIRmini_SRx2_scratch_P64W8_DIV2K_B16G1_MultiLapLoss
model_type: SRModelKD
scale: 2
num_gpu: auto
manual_seed: 0
# teacher network structures
tea_network_g:
type: SwinIR
upscale: 2
in_chans: 3
img_size: 64
window_size: 8
img_range: 1.
depths: [6, 6, 6, 6]
embed_dim: 60
num_heads: [6, 6, 6, 6]
mlp_ratio: 2
upsampler: 'pixelshuffledirect'
resi_connection: '1conv'
# teacher path
tea_path:
pretrain_network_g: experiments/pretrained_models/002_lightweightSR_DIV2K_s64w8_SwinIR-S_x2.pth
strict_load_g: false
resume_state: ~
# student network structures
network_g:
type: SwinIR
upscale: 2
in_chans: 3
img_size: 64
window_size: 8
img_range: 1.
depths: [4, 4, 4]
embed_dim: 24
num_heads: [6, 6, 6]
mlp_ratio: 2
upsampler: 'pixelshuffledirect'
resi_connection: '1conv'
# path
path:
pretrain_network_g: ~
strict_load_g: false
resume_state: ~
# training settings
train:
ema_decay: 0.999
optim_g:
type: Adam
lr: !!float 1e-4
weight_decay: 0
betas: [0.9, 0.999]
scheduler:
type: MultiStepLR
milestones: [250000, 400000, 450000]
gamma: 0.5
total_iter: 800000
warmup_iter: -1 # no warm up
# distill losses
dis_opt:
type: MultiLapLoss
loss_weight: 1
reduction: mean
# student losses
stu_opt:
type: L1Loss
loss_weight: 0.1
reduction: mean
4.3 知识蒸馏代码
完整代码在 basicsr\models\sr_kd_model.py 中,以下是进行了删减的,只列出了关键代码。
如教师模型的创建与加载、蒸馏loss的创建、蒸馏loss与学生loss的应用等。
import torch
from collections import OrderedDict
from os import path as osp
from tqdm import tqdm
from torch.nn import functional as F
from basicsr.archs import build_network
from basicsr.losses import build_loss
from basicsr.metrics import calculate_metric
from basicsr.utils import get_root_logger, imwrite, tensor2img
from basicsr.utils.registry import MODEL_REGISTRY
from .base_model import BaseModel
@MODEL_REGISTRY.register()
class SRModelKD(BaseModel):
"""Base SR model for single image super-resolution."""
def __init__(self, opt):
super(SRModelKD, self).__init__(opt)
# define teacher network 教师模型的创建与加载 -----------------------
self.net_g_tea = build_network(opt['tea_network_g'])
self.net_g_tea = self.model_to_device(self.net_g_tea)
self.print_network(self.net_g_tea)
# load teacher pretrained models
load_path_tea = self.opt['tea_path'].get('pretrain_network_g', None)
if load_path_tea is not None:
param_key = self.opt['tea_path'].get('param_key_g', 'params')
self.load_network(self.net_g_tea, load_path_tea, self.opt['tea_path'].get('strict_load_g', True), param_key)
else:
raise ValueError(f'Please load teacher model')
# define student network
self.net_g = build_network(opt['network_g'])
self.net_g = self.model_to_device(self.net_g)
self.print_network(self.net_g)
# load student pretrained models
load_path = self.opt['path'].get('pretrain_network_g', None)
if load_path is not None:
param_key = self.opt['path'].get('param_key_g', 'params')
self.load_network(self.net_g, load_path, self.opt['path'].get('strict_load_g', True), param_key)
if self.is_train:
self.init_training_settings()
def init_training_settings(self):
self.net_g.train()
train_opt = self.opt['train']
self.ema_decay = train_opt.get('ema_decay', 0)
if self.ema_decay > 0:
logger = get_root_logger()
logger.info(f'Use Exponential Moving Average with decay: {self.ema_decay}')
# define network net_g with Exponential Moving Average (EMA)
# net_g_ema is used only for testing on one GPU and saving
# There is no need to wrap with DistributedDataParallel
self.net_g_ema = build_network(self.opt['network_g']).to(self.device)
# load pretrained model
load_path = self.opt['path'].get('pretrain_network_g', None)
if load_path is not None:
self.load_network(self.net_g_ema, load_path, self.opt['path'].get('strict_load_g', True), 'params_ema')
else:
self.model_ema(0) # copy net_g weight
self.net_g_ema.eval()
if train_opt.get('dis_opt'):
#蒸馏loss的创建 -----------------------
self.distill_loss_fn = build_loss(train_opt['dis_opt']).to(self.device)
else:
self.distill_loss_fn = None
if train_opt.get('stu_opt'):
self.student_loss_fn = build_loss(train_opt['stu_opt']).to(self.device)
else:
self.student_loss_fn = None
if self.distill_loss_fn is None or self.student_loss_fn is None:
raise ValueError('Please check losses.')
# set up optimizers and schedulers
self.setup_optimizers()
self.setup_schedulers()
def optimize_parameters(self, current_iter):
self.optimizer_g.zero_grad()
self.output = self.net_g(self.lq)
self.output_tea = self.net_g_tea(self.lq)
l_total = 0
loss_dict = OrderedDict()
#优化器中,蒸馏loss与学生loss的应用
# distill loss
distill_loss = self.distill_loss_fn(self.output, self.output_tea)
l_total += distill_loss
loss_dict['distill_loss'] = distill_loss
# student loss
student_loss = self.student_loss_fn(self.output, self.gt)
l_total += student_loss
loss_dict['student_loss'] = student_loss
loss_dict['l_total'] = l_total
l_total.backward()
self.optimizer_g.step()
self.log_dict = self.reduce_loss_dict(loss_dict)
if self.ema_decay > 0:
self.model_ema(decay=self.ema_decay)

在这里,我们一起交流AI,学习AI,用AI改变世界。如有AI产品需求,可访问讯飞开放平台,www.xfyun.cn。
更多推荐



 24
24 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)