
rl与深度学习_DeepMind的惊人混合与匹配RL技术
rl与深度学习 #1研究论文解释混合搭配-强化学习的代理课程[ arxiv ]如今使用的强化学习技术非常快速,并且使用基于梯度的策略优化,可以在不那么复杂的环境中立即获得结果。基于渐变的策略是竞争性的而不是协作的。那么,如果对于需要执行具有复杂任务的代理的更加复杂的环境,我们需要长期的结果,该怎么办?在许多世界环境中,我们无法修改环境,并且无法在现实世界中执行...
rl与深度学习
#1研究论文解释
混合搭配-强化学习的代理课程[ arxiv ]

如今使用的强化学习技术非常快速,并且使用基于梯度的策略优化,可以在不那么复杂的环境中立即获得结果。
基于渐变的策略是竞争性的而不是协作的。
那么,如果对于需要执行具有复杂任务的代理的更加复杂的环境,我们需要长期的结果,该怎么办?
在许多世界环境中,我们无法修改环境,并且无法在现实世界中执行强化学习非常耗时。 因此为了解决这个问题,本文试图在课程学习和人口基础培训的帮助下解决这个问题。
在你开始前
课程学习[ 论文 ]
使用转移学习设计一个任务序列,以便代理进行培训,以提高最终性能或学习速度。
基于人口的神经网络培训[ DeepMind Blog ]
PBT可以在训练时修改网络的超参数。
主要思想
Mix&Match论文背后的主要思想是
生成RL代理的多种变体,其中我们没有能力根据培训复杂性来修改安排的任务,而只能使用一种MIX&MATCH代理,该MIX&MATCH代理是通过根据策略生成过程利用结构上不同的不同代理来构造的。
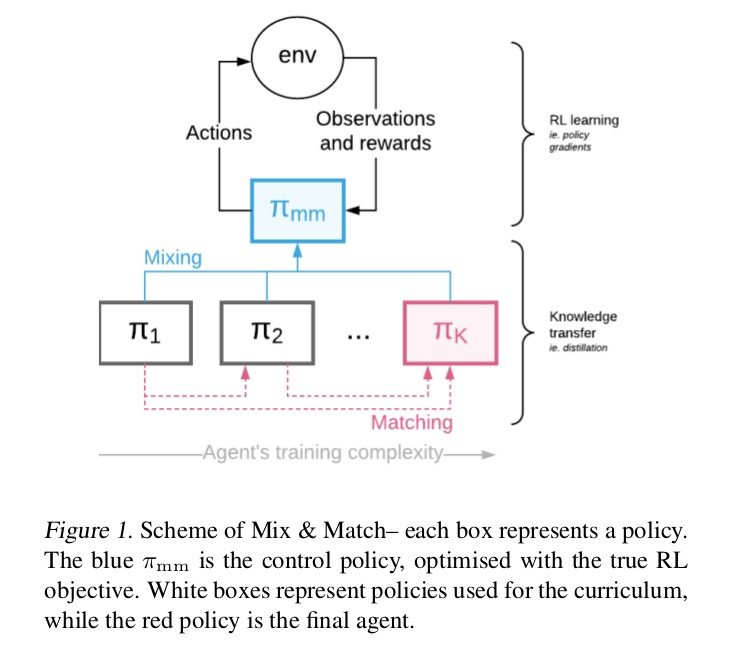
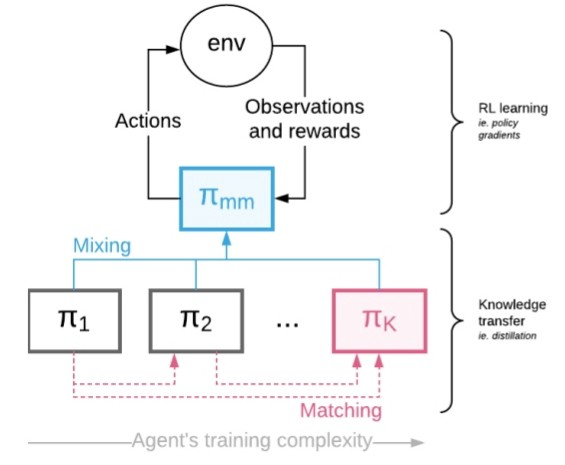
MIX和MATCH框架
按学习复杂性排列的多个代理(如上所示)被视为一个混合策略的混合与匹配代理。
知识转移 (即蒸馏)的完成方式是使复杂的代理人与较早的代理人相匹配。
控制混合系数 ,以便最终使用复杂的目标代理来产生经验。
方法细节
假设我们给了一个可训练代理1序列( 具有相应的策略π1,…,πK,每个参数都带有一些可以共享某些参数的θi⊂θ )
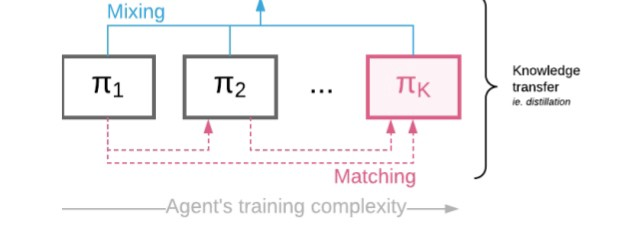
目的是训练πK,同时所有剩余的智能体都在那儿诱导更快/更轻松的学习。
让我们介绍一下分类随机变量' c'〜Cat(1,…,K |α) 概率质量函数p(c = i)=αi )
给定时间的政策:
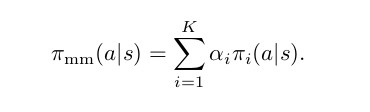
混合匹配的目的是允许课程学习,因此我们需要c的概率质量函数(pmf)随时间变化。 最初,pmf应该具有α1 = 1,并且在训练即将结束时αK = 1,因此允许制定从简单π1到目标πK的政策课程。
现在,应该以这种方式进行培训,以最大程度地长期提高性能,并与这些梯度不同地一起共享知识。
为了解决此问题,我们将使用类似于蒸馏的成本(D) ,它将策略统一在一起。
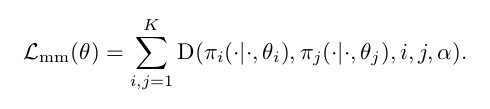
我们考虑的最终优化问题只是原始L ^ RL 损失 (如下)的加权和,应用于控制策略π^ mm和知识转移损失:
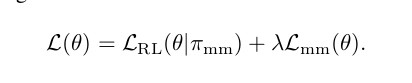
现在,让我们在步骤→中了解混合匹配架构→
政策混合
为了减少差异,策略混合将通过显式混合来完成。
知识传输
为简单起见,我们考虑K = 2的情况。考虑确保最终策略(π2)与更简单的策略(π1)匹配,同时可以访问控制策略中的样本(πmm )的问题 。
为简单起见,我们直接定义轨迹的M&M损失 ,并从控制策略中采样轨迹(s∈S) 。 引入了1-α项,因此当我们切换到π2时,蒸馏成本就消失了。
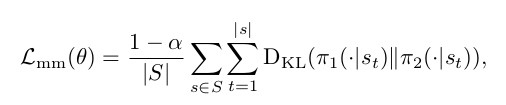
通过训练调整α(alpha)
α是总体质量函数方程(第一方程 )中使用的变量。
所提出的方法的重要组成部分是如何通过时间设置α值。 为简单起见,让我们再次考虑K = 2的情况,其中一个只需要一个α(因为c现在来自伯努利分布),我们
视为时间t的函数。
在线超参数调整→由于α随时间变化,因此无法使用典型的超参数调整技术,因为可能值的空间在时间步长上呈指数关系(α=(α(1),···,α(T))∈4 Tk− 1,
其中4 k表示ak维单形)。
为了解决此问题,我们使用了基于人口的培训 (PBT)。
基于人口的培训和M&M
基于人口的训练 (PBT)保持大量经过并行训练的代理 ,以便在训练时通过时间优化超参数,并定期相互查询以检查他们相对于他人的表现如何。 性能不佳的代理会复制更强的代理的权重(神经网络参数),并对它们的超参数进行本地修改。
PBT在整个训练过程中修改超参数的能力使发现强大的自适应策略(例如自动调整的学习速率退火计划)成为可能 。
这样,性能较差的代理将用于探索超参数空间。
因此,我们需要定义两个功能 →
评估→衡量当前特工的实力
浏览 →定义如何激发超参数。
注意:请记住,PBT代理是MIX&MATCH代理,它已经是组成代理的混合物。
现在,根据我们感兴趣的问题的特征,我们应该使用下面提到的两种方案之一。
- 如果通过从简单模型切换到更复杂的模型来提高模型的性能,则
a)为评估提供混合政策的绩效(即,奖励k集)。
b)对于α的探索功能,我们随机添加或减去一个固定值(在0和1之间截断)。 因此,一旦切换到更复杂的设备具有显着的好处-PBT将自动执行。
2.通常,我们通常希望从不受约束的体系结构切换到某些特定的,受严重约束的体系结构(在这种体系结构中,切换可能不会带来明显的性能优势)。
当从构成单任务策略训练多任务策略时,我们可以使eval成为独立的评估工作,该评估工作仅查看具有αK = 1的代理的性能。
这样,我们可以直接针对感兴趣模型的最终性能进行优化,但要以PBT需要额外评估为代价。
实验内容
让我们测试并分析我们的新M&M方法在所有情况下是否都能正常工作。 现在,我们将考虑3套强化学习实验,这些实验可以扩展到大型复杂的操作空间,代理架构的复杂性和学习多任务策略。
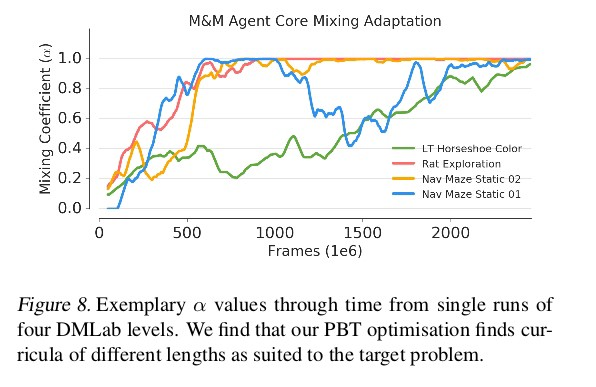
在所有过程中,我们将α初始化为0左右,并通过
时间。
注意 →即使在实验部分中我们使用K = 2,实际的课程也会通过π1和π2混合而潜在地无限次遍历。
除非另有说明,否则评估函数将返回控制策略最近30集的平均奖励。
DeepMind Lab的环境套件为RL代理提供了一系列具有挑战性的3D,基于第一人称视角的任务(请参阅附录)。 代理可以60 fps的速度感知基于96×72像素的RGB观察结果,并且可以移动,旋转,跳转和标记内置机器人 。
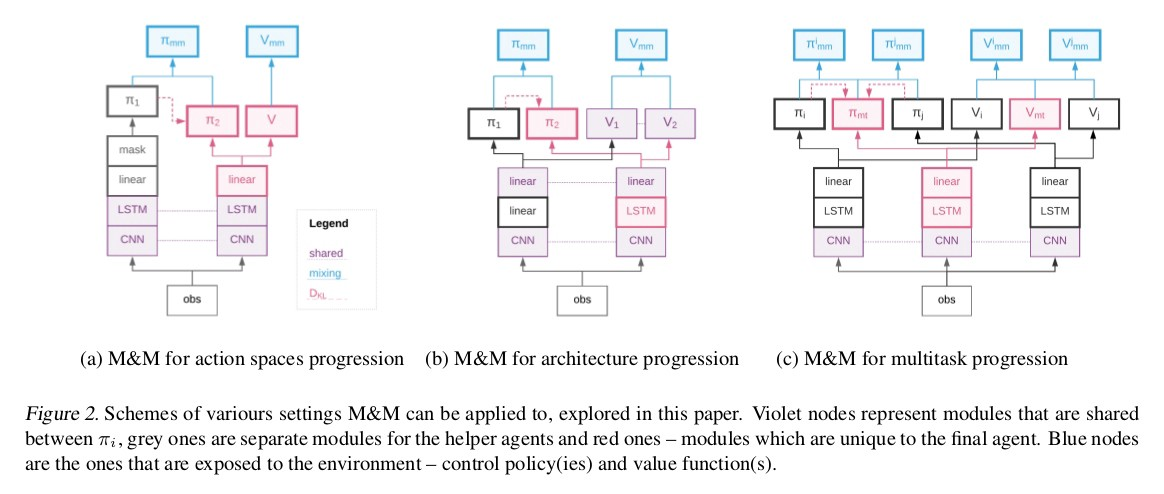
1.课程超过所使用的动作
动作空间是复杂的,以6维向量表示,其中两个动作组具有很高的分辨率( 旋转和向上/向下动作 ),其余四个是低分辨率动作( 向前,向后或根本不移动,射击或不射击等) )。
在这里,我们用9个行动来构建π1,简单的策略(小动作空间)。
与使用对角高斯分布的连续控制研究相似,我们使用因式分解策略π2(a 1,a 2,…,a 6 | s):= j = 1 π̂ j(aj | s),我们称之为大行动空间。
为了能够混合这两个策略,我们将π1动作映射到π2的动作空间中的对应策略上。
代理网络之间的值混合如下图所示。
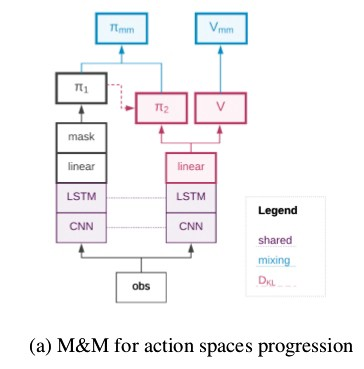
该论文还讨论了Shared Head和Masked KL技术,但两者都比M&M磨损。
结果
我们看到,与大型行动空间相比,小型行动空间可加快学习速度,但会影响最终的表现。
应用于此设置的“混合与匹配”获得了两全其美的优势,学习速度很快,并且超过了大型动作空间的最终表现。

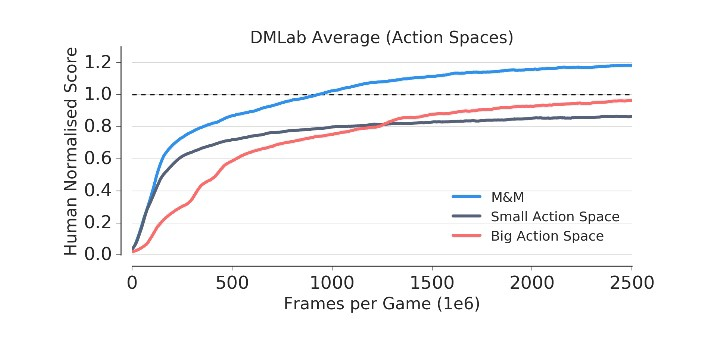
空间实验。
在绘制随时间变化的α时(图5左),我们看到主体在早期就完全切换到大动作空间,因此表明小动作空间仅对学习的初始阶段有用。 通过查看代理商通过培训采取的行动有多不同,可以进一步确认这一点。
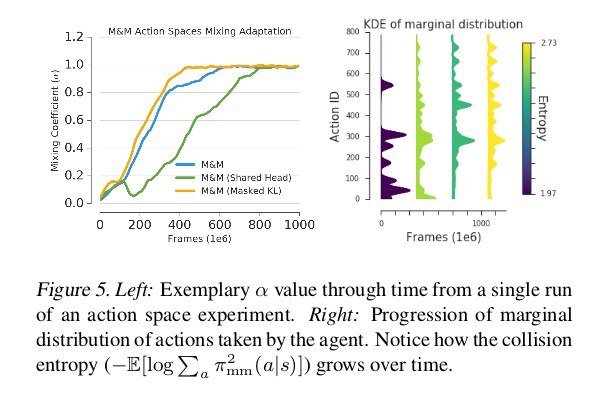
图5(右)显示了动作的边际分布如何随时间演变,我们看到新动作是通过训练解锁的,而且最终的分布比初始的更熵,这意味着更多的熵导致更多的稳定性。
2.关于代理架构的课程
我们用处理后的卷积信号的线性投影代替LSTM。 我们共享卷积模块以及策略/价值函数预测。
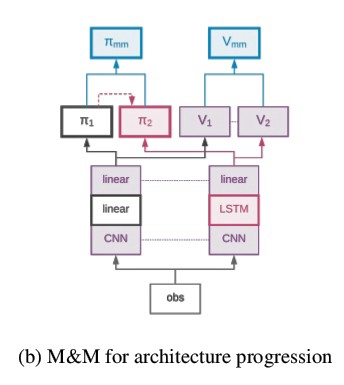
实验集中于各种导航任务 。
一方面,被动策略(只能由前馈策略表示)应该合理地学习以四处移动和探索,而另一方面,需要循环网络(具有内存)以最大化最终性能。学习导航新的迷宫布局(“探索较小的对象位置”)或避免(寻找)通过迷宫探索的不成功(成功)路径。
结果
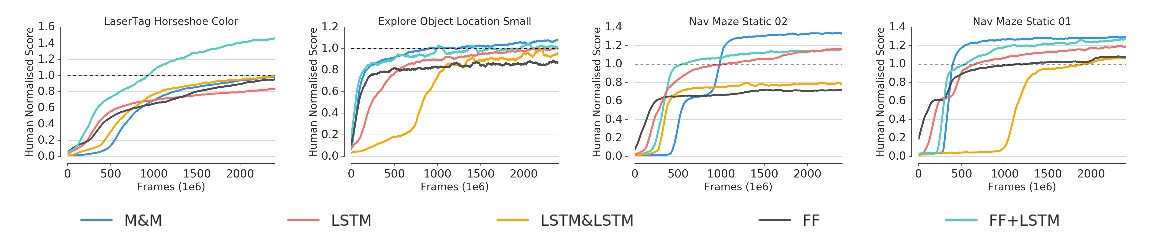
M&M应用于LSTM和FF的过渡,导致最终性能的显着提高。 但不如FF对手快。
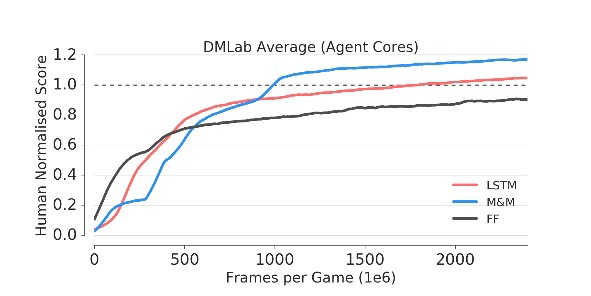
图8导致两个观察结果
- 由于游戏级别的复杂性,绿色曲线切换到LSTM较晚。
- 如果需要,模型(蓝色曲线)可以切换回混合策略。
3.多任务课程
作为概念的最终证明,我们考虑学习能够同时解决多个RL问题的单个策略的任务。 这类任务的基本方法是在混合环境中训练模型,或者等效地在多个环境中并行训练共享模型。
这种培训可能有两个缺点:
→它在很大程度上取决于奖励规模,并且会偏向
高回报的环境。
→易于训练的环境为模型提供了大量更新,因此也可能使解决方案偏向于自身。
让我们看一下结果:
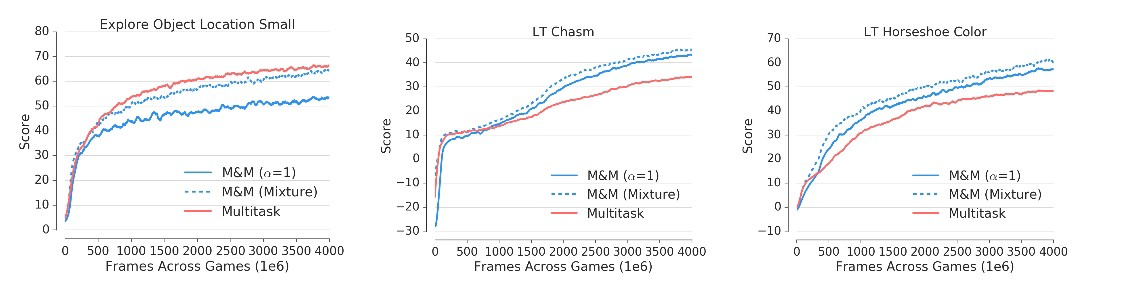
一种是“ 探索小物体位置” ,它具有较高的奖励和陡峭的初始学习曲线(许多奖励信号来自收集苹果)。
在剩下的两个问题中,训练很困难,代理正在与其他漫游器以及复杂的机制进行交互(收取奖金,标记楼层等)。
多任务解决方案专注于解决导航任务,而在更具挑战性的问题上却表现较差。
为了将M&M应用于此问题,我们在每个环境中构造一个代理
(每个人在前面的部分中充当π1),然后集中所有“多任务”代理 (前面的部分中的π2)。 至关重要的是,代理共享卷积层,但具有独立的LSTM。
培训是以多任务方式完成的,但是每种环境中的控制策略仍然是特定于任务的πi(专家)和πmt(集中代理)之间的混合。
由于切换到集中式策略不再有益,因此我们使用
πmt(即中央策略)的性能作为PBT的优化标准(评估),而不是控制策略。
我们分别评估混合物和集中剂的性能。 图9示出了所提出的方法的每任务性能。 人们会注意到性能更加统一-
M&M代理学会了在两个具有挑战性的激光标签环境中发挥良好的性能,同时在单个导航任务中略微牺牲了性能。
取得成功的原因之一是,知识转移是在政策空间中完成的,这对奖励规模不变。 当代理商切换到使用后,仍然可以只专注于高回报的环境
只有中央政策,这种在M&M培训中的归纳偏差可以确保更高的最低分数。
结论
随着时间的流逝,该混合物的成分权重将进行调整,以使在训练结束时,我们剩下由最复杂的药物组成的单一活性成分。 也,
在复杂环境中的改进和加速性能。
代理的集合通过使用
混合政策。
可以通过共享的经验或共享的建筑元素,也可以通过类似蒸馏的KL匹配损失,在组件之间共享信息。
我每周都会发布2个帖子,所以不要错过本教程。
有任何意见或有任何疑问,请在评论中写下。
拍(多次)! 分享它! 跟着我!
乐于助人。 荣誉.....
您会喜欢的以前的故事:
翻译自: https://hackernoon.com/deepminds-amazing-mix-match-rl-techique-a6f8ce6ac0b4
rl与深度学习

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 0
0 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)