
课程笔记:2-大数据-hadoop安装配置
目前,已经基本完成Hadoop的配置操作,可以从node1将hadoop安装文件夹远程复制到node2、node3。以root身份,在node1、node2、node3三台服务器上均执行如下命令。以root身份,在node1、node2、node3三台服务器上均执行如下命令。datanode数据存放node1、node2、node3的/data/dn。4.7、在node1、node2和node3配
课程笔记:2-大数据-hadoop安装配置
https://www.bilibili.com/video/BV1WY4y197g7/?p=26&spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=da662397baf344a1d3a9cc0b314d7aa0
一、下载解压
1、hadoop下载
官网:https://hadoop.apache.org
课程里给的包:链接: https://pan.baidu.com/s/1x-6qsqcTOjdORUmz2u_T9A?pwd=r5i3 提取码: r5i3
2、上传hadoop到服务器
3、解压到/export/server/
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server/
二、安装配置
1、解压缩安装包到/export/server/中
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server
2、构建软链接
cd /export/server
ln -s /export/server/hadoop-3.3.4 hadoop
3、进入hadoop安装包内,查看hadoop包结构
cd hadoop
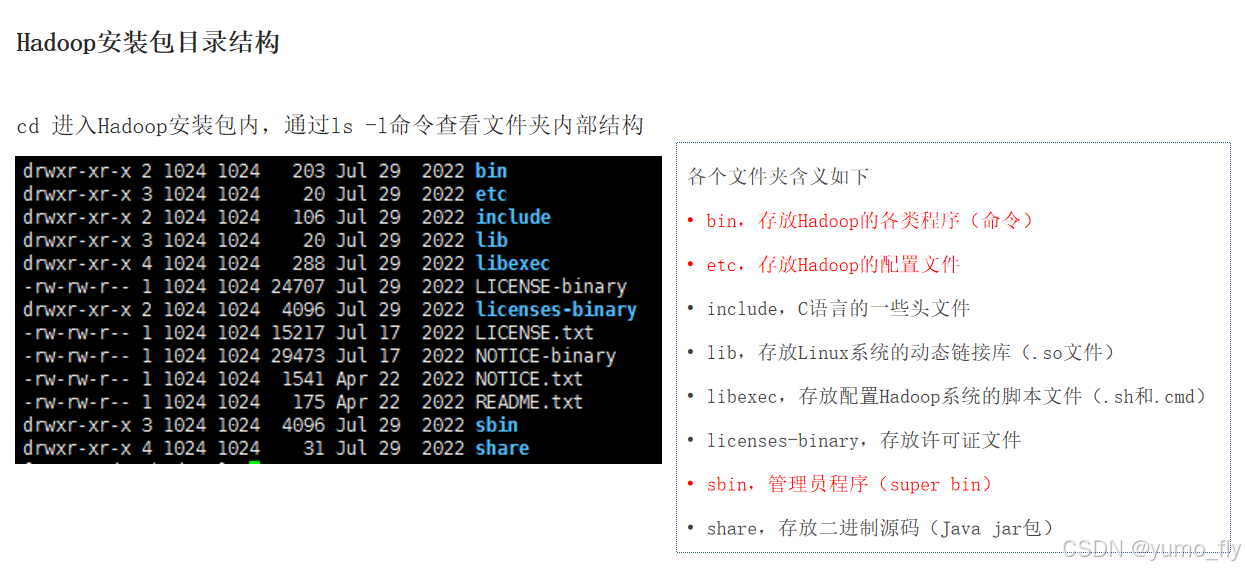

4、修改配置
4.1、配置workers文件
# 进入配置文件目录
cd etc/hadoop
# 编辑workers文件
vim workers
# 填入如下内容
node1
node2
node3
4.2、配置hadoop-env.sh文件
# 填入如下内容
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
4.3、配置core-site.xml文件
在文件内部填入如下内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
4.4、配置hdfs-site.xml文件
# 在文件内部填入如下内容
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>
4.5、准备数据
namenode数据存放node1的/data/nn
datanode数据存放node1、node2、node3的/data/dn
4.6、分发hadoop文件夹
目前,已经基本完成Hadoop的配置操作,可以从node1将hadoop安装文件夹远程复制到node2、node3
分发
# 在node1执行如下命令
cd /export/server
scp -r hadoop-3.3.4 node2:`pwd`/
scp -r hadoop-3.3.4 node3:`pwd`/
在node2执行,为hadoop配置软链接
# 在node2执行如下命令
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop
在node3执行,为hadoop配置软链接
# 在node3执行如下命令
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop
4.7、在node1、node2和node3配置同样的环境变量
vim /etc/profile
# 在/etc/profile文件底部追加如下内容
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5、 权限管理
5.1、配置文件夹权限
以root身份,在node1、node2、node3三台服务器上均执行如下命令
# 以root身份,在三台服务器上均执行
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
6、授权为hadoop用户
以root身份,在node1、node2、node3三台服务器上均执行如下命令
# 以root身份,在三台服务器上均执行
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
7、格式化整个文件系统
格式化namenode,在node1执行
# 确保以hadoop用户执行
su - hadoop
# 格式化namenode
hadoop namenode -format
三、启动
1、一键启动、停止
# 一键启动hdfs集群,在node1执行
start-dfs.sh
# 一键关闭hdfs集群
stop-dfs.sh
# 如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行
/export/server/hadoop/sbin/start-dfs.sh
/export/server/hadoop/sbin/stop-dfs.sh
2、独立启动、停止
hdfs --daemon stop namenode
hdfs --daemon stop datanode
hdfs --daemon stop secondarynamenode
hdfs --daemon start namenode
hdfs --daemon start datanode
hdfs --daemon start secondarynamenode
启动完成后,可以在浏览器打开:
http://node1:9870,即可查看到hdfs文件系统的管理网页。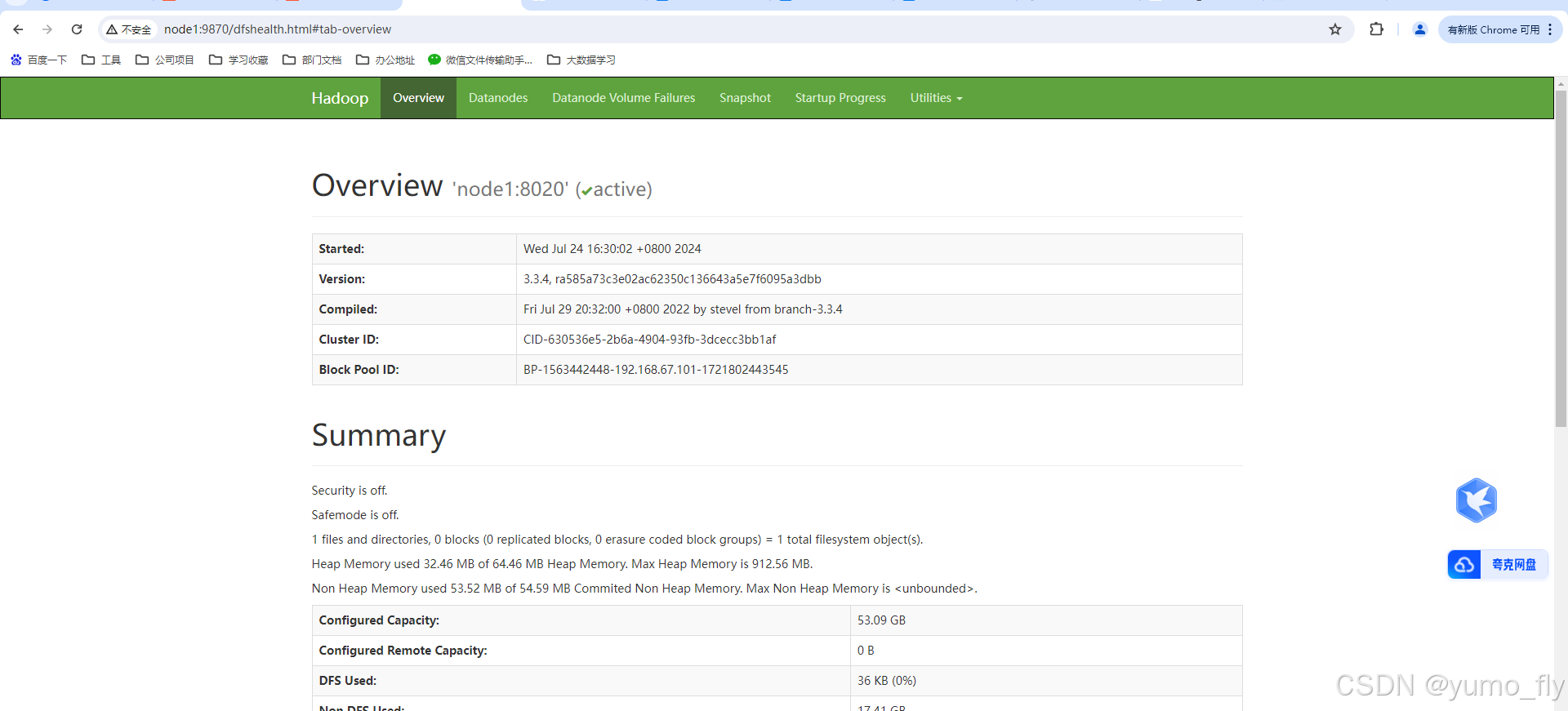
上一篇:课程笔记:1-大数据前置虚拟机主机配置
下一篇:课程笔记:3-大数据-hadoop-hdfs常用命令

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)