
图机器学习——5.11 图神经网络:网络训练与数据集划分
网络训练整体的训练可以分为基于有监督的标签训练,及无监督的训练。有监督训练可以有如下标签:基于节点标签yvy_vyv:如引文网络中,节点属于哪个学科领域;边标签yuvy_{uv}yuv:如交易网络中,边缘是否欺诈;图标签yGy_{G}yG:如分子图中,图的药物相似度。无监督训练:节点水平yvy_vyv:如聚类系数、PageRank、…;边水平yuvy_{uv}yuv:如隐藏两个节点之间的
·
网络训练
整体的训练可以分为基于有监督的标签训练,及无监督的训练。
- 有监督训练可以有如下标签:
- 基于节点标签yvy_vyv:如引文网络中,节点属于哪个学科领域;
- 边标签yuvy_{uv}yuv:如交易网络中,边缘是否欺诈;
- 图标签yGy_{G}yG:如分子图中,图的药物相似度。
- 无监督训练:
- 节点水平yvy_vyv:如聚类系数、PageRank、…;
- 边水平yuvy_{uv}yuv:如隐藏两个节点之间的边,预测是否应该有链接;
- 图水平yGy_{G}yG:如预测两个图是否同构。
为了训练网络,我们需要有明确的损失函数,其实这些损失函数与常用深度学习中的损失函数是一致的。例如:针对分类问题可以用交叉熵(Cross Entropy);针对回归问题可以用均方误差(Mean Squared Error)。只是样本标签的具体构造需要根据实际的任务来定。
- 节点标签:yvy_vyv
- 边标签:yuvy_{uv}yuv
- 图标签:yGy_{G}yG
它们都是向量的形式,一个样本有一个标签(同样也可以有 NNN 个数据点)。
同样地,评价指标也可以根据具体的任务(分类/回归),按照传统的机器学习策略类比进行设计(可以理解成完全一样)。
数据集划分
不同于传统数据集中,训练集、验证集与测试集的划分(由于基于样本独立的假设,因此可以很轻松地随机划分)。图类型数据往往具有相依结构与信息。因此,对于图数据的划分通常有两种方式:
- Transductive setting:可以在所有拆分的数据集(训练、验证和测试集)中观察到输入的完整图。这种方式只是拆分(节点)对应标签。
- Inductive setting:将不同数据集划分之间的边删除,以得到多个图。
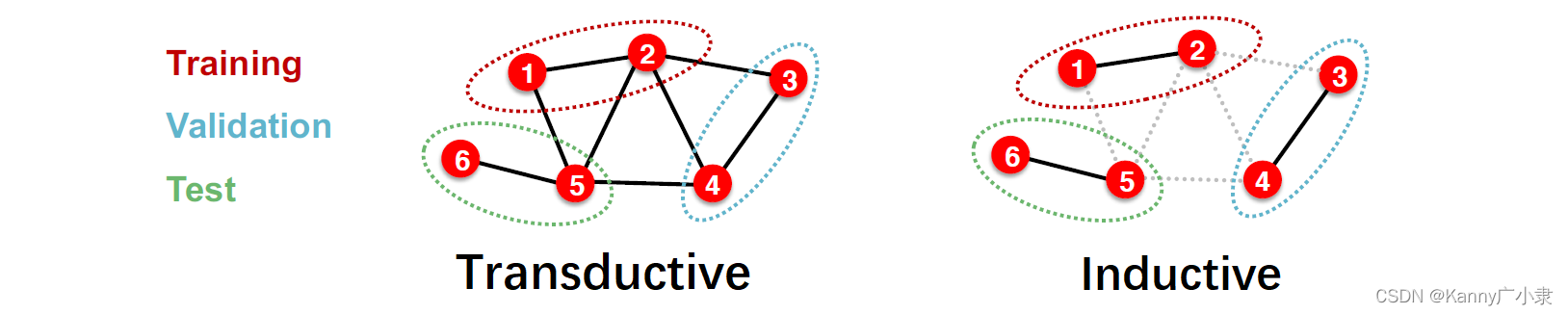
两者的适用情况如下:
- Transductive setting
- 数据集由一张图组成
- 在所有数据集拆分中都可以观察到整个图,因此只需拆分标签
- 仅适用于节点/边缘预测任务
- Inductive setting
- 数据集由多个图组成
- 每个划分的集合只能观察数据集合内的图结构。任务本身需要推广到看不见的图
- 适用于节点/边/图任务

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)