
池化层(pooling layer) & 感受野(Receptive Field) & 神经网络的基本组成
目录(1)本文涉及的函数(2)池化层(3)感受野(4)代码示例(含注释)承接上两篇博客:卷积层(空洞卷积对比普通卷积)、激活函数层(1)本文涉及的函数import torchimport torch.nn as nnfrom torch import autogradnn.MaxPool1d# 1 维最大池化(max pooling)操作nn.MaxPool2d...
目录
承接上两篇博客:卷积层(空洞卷积对比普通卷积)、激活函数层
(1)本文涉及的函数
import torch
import torch.nn as nn
from torch import autograd
- nn.MaxPool1d # 1 维最大池化(max pooling)操作
- nn.MaxPool2d # 1 维最大池化(max pooling)操作
- nn.MaxPool3d # 1 维最大池化(max pooling)操作
- nn.MaxUnPool1d # Maxpool1d 的逆过程
- nn.MaxUnPool2d # Maxpool2d 的逆过程
- nn.MaxUnPool3d # Maxpool3d 的逆过程
- nn.AvgPool1d # 1 维的平均池化(average pooling)
- nn.AvgPool2d # 2 维的平均池化(average pooling)
- nn.AvgPool3d # 3 维的平均池化(average pooling)
- nn.FractionalMaxPool2d # 2 维的分数最大池化
- nn.LPPool2d # 2 维的幂平均池化
- nn.AdaptiveMaxPool1d # 1 维的自适应最大池化
- nn.AdaptiveMaxPool2d # 2 维的自适应最大池化
- nn.AdaptiveAvgPool1d # 1 维的自适应平均池化
- nn.AdaptiveAvgPool2d # 2 维的自适应平均池化
最大池化的公式:
torch.nn.MaxPool1d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, # ceil_mode=False)
输入参数说明:
- kernel_size(int or tuple) - max pooling 的窗口大小
- stride(int or tuple, optional) - max pooling 的窗口移动的步长。默认值是 kernel_size
- padding(int or tuple, optional) - 输入的每一条边补充 0 的层数
- dilation(int or tuple, optional) – 一个控制窗口中元素步幅的参数
- return_indices - 如果等于 True,会返回输出最大值的序号,对于上采样操作会有帮助
- ceil_mode - 如果等于 True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作
(2)池化层
在卷积网络中,通常会在卷积层之间增加池化(Pooling)层,以降低特征图的参数量,提升计算速度,增加感受野,是一种降采样操作。 池化是一种较强的先验,可以使模型更关注全局特征而非局部出现的位置,这种降维的过程可以保留一些重要的特征信息,提升容错能力,并且还能在一定程度上起到防止过拟合的作用。
在物体检测中,常用的池化有最大值池化(Max Pooling)与平均值池化(Average Pooling)。池化层有两个主要的输入参数,即核尺寸 kernel_size与步长stride。如图1 所示为一个核尺寸与步长都为2的最大值池化过程,以左上角为例,9、20、15与26进行最大值池化,保留 26。
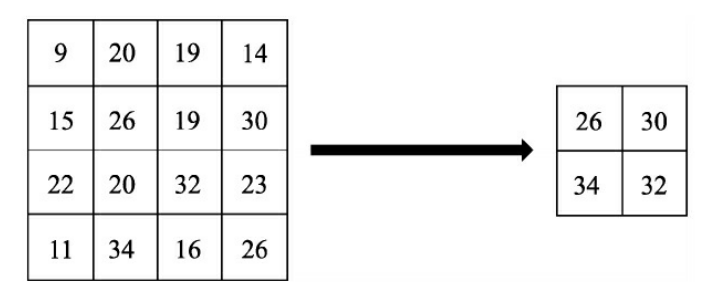
图1 池化过程示例
(3)感受野
感受野(Receptive Field)是指特征图上的某个点能看到的输入图像的区域,即特征图上的点是由输入图像中感受野大小区域的计算得到的。举个简单的例子,如图2 所示为一个三层卷积网络,每一层的卷 积核为3×3,步长为1,可以看到第一层对应的感受野是3×3,第二层是 5×5,第三层则是7×7。
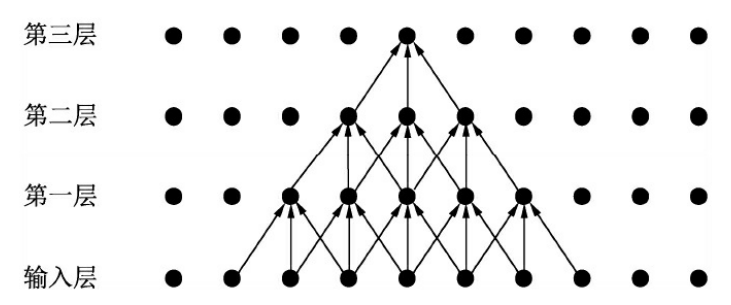
图2 感受野示意图
卷积层和池化层都会影响感受野,而激活函数层通常对于感受野没有影响。对于一般的卷积神经网络,感受野可由下面两个公式计算得出。
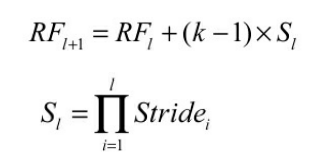
其中,RF(l+1)与RF(l)分别代表第(l+1)层与第(l)层的感受野,k代表第(l+1)层卷积核的大小,S(l)代表前(l)层的步长之积。注意,当前层的步长并不影响当前层的感受野。
通过上述公式求取出的感受野通常很大,而实际的有效感受野 (Effective Receptive Field)往往小于理论感受野。从图2 也可以看出,虽然第三层的感受野是7×7,但是输入层中边缘点的使用次数明显比中间点要少,因此做出的贡献不同。经过多层的卷积堆叠之后,输入层对于特征图点做出的贡献分布呈高斯分布形状。
理解感受野是理解卷积神经网络工作的基础,尤其是对于使用 Anchor作为强先验区域的物体检测算法,如Faster RCNN和SSD,如何设置Anchor的大小,Anchor应该对应在特征图的哪一层,都应当考虑感受野。通常来讲,Anchor的大小应该与感受野相匹配,尤其是有效的感受野,过大或过小都不好。
在卷积网络中,有时还需要计算特征图的大小,一般可以按照下面的公式进行计算。
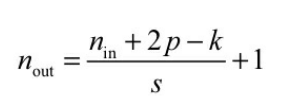
其中,N(in)与N(out)分别为输入特征图与输出特征图的尺寸,p代表这一 层的padding大小,k代表这一层的卷积核大小,s为步长。
(4)代码示例(含注释)
import torch
import torch.nn as nn
from torch import autograd
# torch.nn.MaxPool1d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False,
# ceil_mode=False)
# 参数:
# kernel_size(int or tuple) - max pooling 的窗口大小
# stride(int or tuple, optional) - max pooling 的窗口移动的步长。默认值是 kernel_size
# padding(int or tuple, optional) - 输入的每一条边补充 0 的层数
# dilation(int or tuple, optional) – 一个控制窗口中元素步幅的参数
# return_indices - 如果等于 True,会返回输出最大值的序号,对于上采样操作会有帮助
# ceil_mode - 如果等于 True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作
# # 对于输入信号的输入通道,提供 1 维最大池化(max pooling)操作
mp = nn.MaxPool1d(3, stride=1)
input = autograd.Variable(torch.Tensor([[20, 16, 50, 10, 20],
[20, 16, 10, 10, 20],
[20, 16, 60, 10, 20],
[20, 16, 15, 10, 20],
[20, 16, 22, 10, 20]]))
output = mp(input)
print(output)
# # 对于输入信号的输入通道,提供 2 维最大池化(max pooling)操作
mp = nn.MaxPool2d((3, 2), stride=(2, 1))
input = autograd.Variable(torch.Tensor([[[20, 16, 50, 10, 20],
[20, 16, 10, 10, 20],
[20, 16, 60, 10, 20],
[20, 16, 15, 10, 20],
[20, 16, 22, 10, 20]],
[[20, 16, 50, 10, 20],
[20, 16, 10, 10, 20],
[20, 16, 60, 10, 20],
[20, 16, 15, 10, 20],
[20, 16, 22, 10, 20]]]))
output = mp(input)
print(output)
# 对于输入信号的输入通道,提供 3 维最大池化(max pooling)操作
# pool of square window of size=3, stride=2
m = nn.MaxPool3d(3, stride=2)
# pool of non-square window
m1 = nn.MaxPool3d((3, 2, 2), stride=(2, 1, 2))
input = torch.randn(20, 16, 50, 44, 31)
output = m(input)
output1 = m1(input)
print(output.size())
print(output1.size())
# =========================================================== #
# Maxpool1d 的逆过程,不过并不是完全的逆过程,因为在 maxpool1d 的过程中,一些最大值的已经丢失。
# MaxUnpool1d 输入 MaxPool1d 的输出,包括最大值的索引,并计算所有 maxpool1d 过程中非最大值被设置为零的部分的反向。
pool = nn.MaxPool1d(2, stride=2, return_indices=True)
unpool = nn.MaxUnpool1d(2, stride=2)
input = autograd.Variable(torch.Tensor([[[1, 2, 3, 4, 5, 6, 7, 8]]]))
output, indices = pool(input)
print(output, indices)
out_unpool = unpool(output, indices)
print(out_unpool)
# Maxpool2d
# Maxpool3d
# =========================================================== #
# torch.nn.AvgPool1d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True)
# 在由多个输入平面组成的输入信号上应用一维平均池化。
# # 参数:
# kernel_size(int or tuple) - 池化窗口大小
# stride(int or tuple, optional) - max pooling 的窗口移动的步长。默认值是 kernel_size
# padding(int or tuple, optional) - 输入的每一条边补充 0 的层数
# dilation(int or tuple, optional) – 一个控制窗口中元素步幅的参数
# return_indices - 如果等于 True,会返回输出最大值的序号,对于上采样操作会有帮助
# ceil_mode - 如果等于 True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作
ap = nn.AvgPool1d(3, stride=2)
output = ap(autograd.Variable(torch.Tensor([[[1, 2, 3, 4, 5, 6, 7, 8, 10]]])))
print(output)
# torch.nn.AvgPool2d: 对信号的输入通道,提供 2 维的平均池化(average pooling)
# torch.nn.AvgPool3d: 对信号的输入通道,提供 3 维的平均池化(average pooling)
# =========================================================== #
# torch.nn.FractionalMaxPool2d
# 在由多个输入平面组成的输入信号上应用 2D 分数最大池化。
# # params
# kernel_size(int or tuple) - 最大池化操作时的窗口大小。可以是一个数字(表示 K*K 的窗口),也可以是一个元组(kh*kw)
# output_size - 输出图像的尺寸。可以使用一个 tuple 指定(oH,oW),也可以使用一个数字 oH 指定一个 oH*oH 的输出。
# output_ratio – 将输入图像的大小的百分比指定为输出图片的大小,使用一个范围在(0,1)之间的数字指定
# return_indices - 默认值 False,如果设置为 True,会返回输出的索引,索引对 nn.MaxUnpool2d 有用。
# # pool of square window of size=3, and target output size 3*2
m = nn.FractionalMaxPool2d(3, output_size=(3, 2))
# # pool of square window and target output size being half of input image size
m1 = nn.FractionalMaxPool2d(3, output_ratio=(0.5, 0.5))
input = autograd.Variable(torch.Tensor([[[20, 16, 50, 10, 20],
[20, 16, 10, 10, 20],
[20, 16, 11, 10, 20],
[20, 16, 15, 10, 20],
[20, 16, 22, 10, 20]],
[[20, 16, 50, 10, 20],
[20, 16, 10, 10, 20],
[20, 16, 12, 10, 20],
[20, 16, 15, 10, 20],
[20, 16, 22, 10, 20]]]))
output = m(input)
output1 = m1(input)
print(output)
print(output1)
# =========================================================== #
# torch.nn.LPPool2d(norm_type, kernel_size, stride=None, ceil_mode=False)
# 对输入信号提供 2 维的幂平均池化操作。
# f(X) = \sqrt[p]{\sum_{x \in X} x^{p}}
# 当 p 为无穷大的时候时,等价于最大池化操作
# 当 p=1 时,等价于平均池化操作
# # power-2 pool of square window of size=3, stride=2
m = nn.LPPool2d(2, 3, stride=2)
# # pool of non-square window of power 1.2
m1 = nn.LPPool2d(1.2, (3, 2), stride=(2, 1))
input = autograd.Variable(torch.Tensor([[[21, 16, 50, 10, 20],
[20, 16, 10, 10, 20],
[20, 16, 11, 10, 20],
[20, 16, 15, 10, 20],
[20, 16, 22, 10, 20]],
[[20, 16, 50, 10, 20],
[20, 16, 10, 10, 20],
[20, 16, 12, 10, 20],
[20, 16, 15, 10, 20],
[20, 16, 22, 10, 20]]]))
output = m(input)
output1 = m1(input)
print(output)
print(output1)
# =========================================================== #
# torch.nn.AdaptiveMaxPool1d(output_size, return_indices=False)
# 对输入信号,提供 1 维的自适应最大池化操作
# 对于任何输入大小的输入,可以将输出尺寸指定为 H,但是输入和输出特征的数目不会变化。
# # 参数:
# output_size: 输出信号的尺寸
# return_indices: 如果设置为 True,会返回输出的索引。对 nn.MaxUnpool1d 有用,默认值是 False
m = nn.AdaptiveAvgPool1d(5) # target output size of 5
input = autograd.Variable(torch.randn(1, 64, 8))
output = m(input)
print(output.size())
# torch.nn.AdaptiveMaxPool2d(output_size, return_indices=False)
# 对输入信号,提供 2 维的自适应最大池化操作
# 对于任何输入大小的输入,可以将输出尺寸指定为 H*W,但是输入和输出特征的数目不会变化。
# # params
# output_size: 输出信号的尺寸,可以用(H,W)表示 H*W 的输出,也可以使用数字 H 表示 H*H 大小的输出
# return_indices: 如果设置为 True,会返回输出的索引。对 nn.MaxUnpool2d 有用,默认值是 False
m = nn.AdaptiveMaxPool2d((5, 7)) # target output size of 5x7
input = autograd.Variable(torch.randn(1, 64, 8, 9))
m1= nn.AdaptiveMaxPool2d(7) # target output size of 7x7 (square)
input1 = autograd.Variable(torch.randn(1, 64, 10, 9))
output = m(input)
output1 = m1(input1)
print(output.size())
print(output1.size())
# =========================================================== #
# torch.nn.AdaptiveAvgPool1d(output_size)
# 对输入信号,提供 1 维的自适应平均池化操作
# 对于任何输入大小的输入,可以将输出尺寸指定为 H*W,但是输入和输出特征的数目不会变化。
# output_size: 输出信号的尺寸
# target output size of 5
m = nn.AdaptiveAvgPool1d(5)
input = autograd.Variable(torch.randn(1, 64, 8))
output = m(input)
print(output.size())
# torch.nn.AdaptiveAvgPool2d(output_size
# 对输入信号,提供 2 维的自适应平均池化操作
>>>本文参考:Pytoch官方文件 &&《深度学习之PyTorch物体检测实战》
>>>如有疑问,欢迎评论区一起探讨

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)