
基于python+随机森林+机器学习的济南民宿数据可视化分析与价格预测系统(爬虫+NLP情感分析)
近年来,随着共享经济的发展,民宿行业迅速崛起,成为旅游住宿的热门选择。尤其在一线及二线城市,民宿作为酒店的替代选项,受到了越来越多消费者的青睐。济南作为中国北方历史文化名城和重要旅游城市,民宿行业的发展亦呈现出蓬勃趋势。相较于传统酒店,民宿在价格、环境及个性化服务等方面更具优势,吸引了众多游客的关注。然而,民宿市场的快速扩张也带来了房源价格浮动不定、服务质量参差不齐等问题。因此,如何通过数据分析与
🔥作者:雨晨源码🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python实战项目案例
💕💕文末获取源码
文章目录
本次文章主要是介绍基于python+随机森林+机器学习的济南民宿数据可视化分析与价格预测系统的功能,
济南民宿数据可视化分析与价格预测系统-系统前言简介
- 近年来,随着共享经济的发展,民宿行业迅速崛起,成为旅游住宿的热门选择。尤其在一线及二线城市,民宿作为酒店的替代选项,受到了越来越多消费者的青睐。济南作为中国北方历史文化名城和重要旅游城市,民宿行业的发展亦呈现出蓬勃趋势。相较于传统酒店,民宿在价格、环境及个性化服务等方面更具优势,吸引了众多游客的关注。然而,民宿市场的快速扩张也带来了房源价格浮动不定、服务质量参差不齐等问题。因此,如何通过数据分析与机器学习算法预测民宿价格、分析用户评论情感,从而为用户和房主提供决策支持,成为了一个重要的研究方向。
- 随着互联网技术的普及和大数据的广泛应用,数据可视化和机器学习技术在商业领域的应用越来越深入。通过数据挖掘和机器学习算法,可以从海量数据中发现潜在的市场规律和趋势,帮助商家优化定价策略,也能为消费者提供更具参考性的选择依据。本课题基于Python、Django、Vue等技术框架,设计并实现了一个针对济南民宿市场的数据可视化分析及价格预测系统。该系统通过爬取美团平台的民宿数据,结合用户评论情感分析和随机森林模型,对房源价格进行预测,并使用Echarts对数据进行可视化展示,为用户提供直观且有效的决策参考。
- 本系统的亮点在于结合了多种先进技术手段,包括爬虫技术、机器学习、评论情感分析、词云图生成和Echarts可视化展示。首先,系统通过Python爬虫技术实时获取美团平台的民宿信息,确保数据的时效性与完整性;其次,利用随机森林算法对房价进行预测,模型表现出较高的预测精度;另外,系统通过对用户评论进行情感分析,并生成词云图,帮助用户从评论中快速提炼出关键信息。这些功能不仅为用户提供了直观的数据展示,还通过机器学习算法实现了对市场趋势的预测,具有较高的实用价值。
济南民宿数据可视化分析与价格预测系统-开发技术与环境
-
亮点(爬虫【美团】、机器学习、评论情感分析、随机森林预测模型、词云图、Echarts可视化)
-
开发技术:Python(语言)、Django框架(后端)、Vue(前端)、Echarts
-
机器学习算法:随机森林预测模型、情感分析
-
软件工具:Pycharm、VsCode
-
数据库:MySQL
济南民宿数据可视化分析与价格预测系统-功能介绍
1、民宿数据管理:房源爬虫信息列表展示。
2、评论数据管理:
3、评论情感分析:机器学习训练,分析评论积极还是消极。
4、词云:评论词云图。
5、可视化分析:基本统计、评论数量、民宿评分统计、情感分析统计、每月。
6、民宿价格预测:随机森林预测模型。
济南民宿数据可视化分析与价格预测系统-视频演示
【数据分析】基于机器学习+随机森林的广州民宿价格预测分析与可视化系统 酒店民宿消费数据可视化分析系统
济南民宿数据可视化分析与价格预测系统-演示图片
1.用户端页面:
☀️登录☀️
☀️首页☀️
☀️民宿数据管理☀️
☀️可视化展示☀️
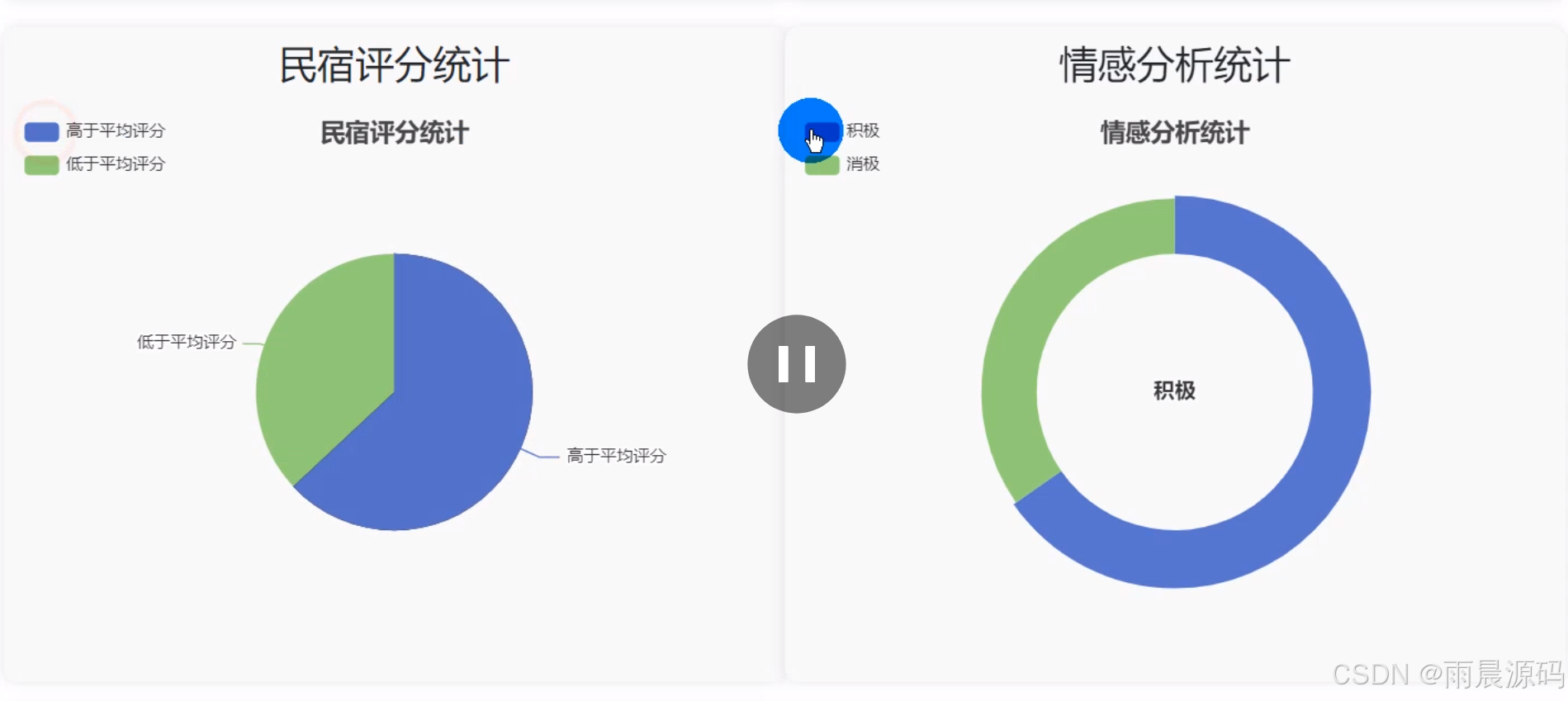
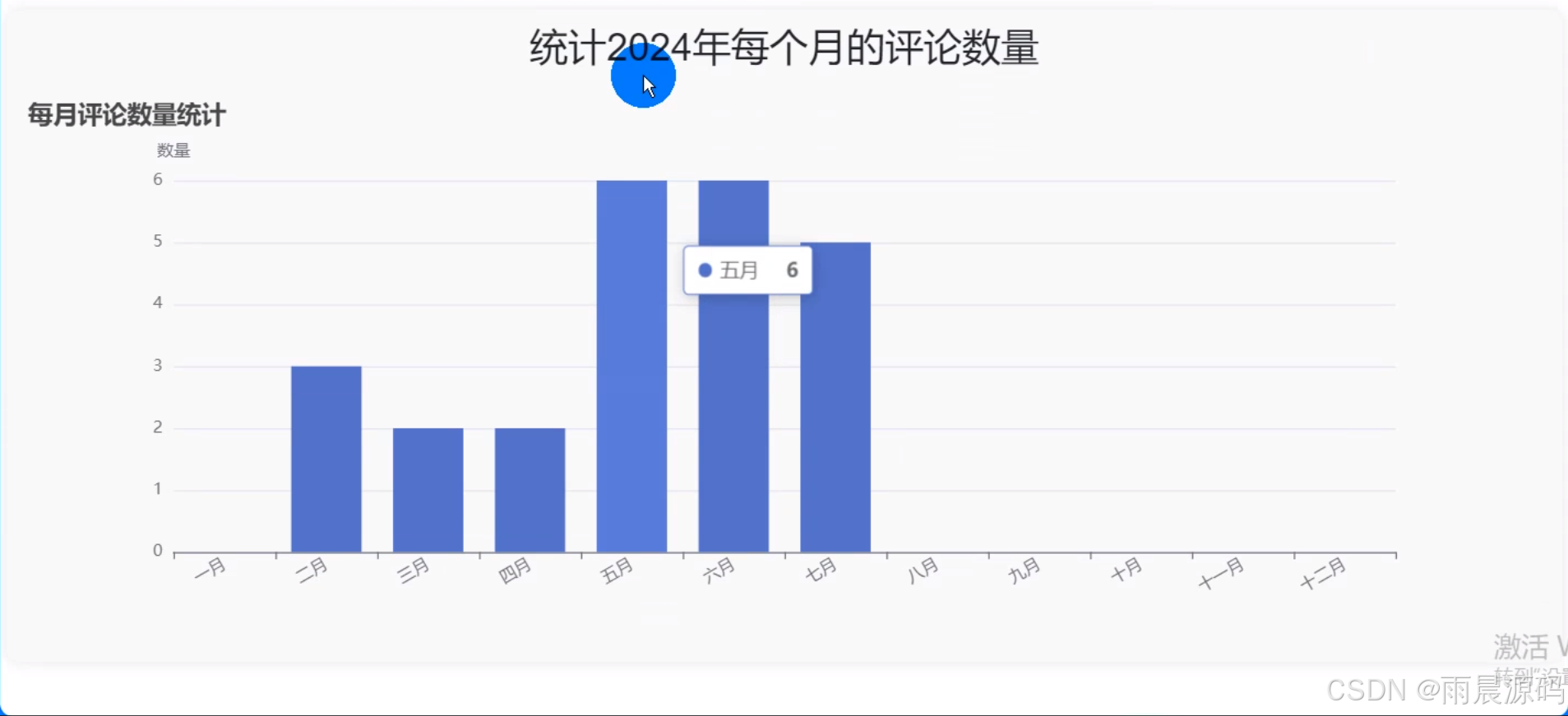
☀️民宿价格预测☀️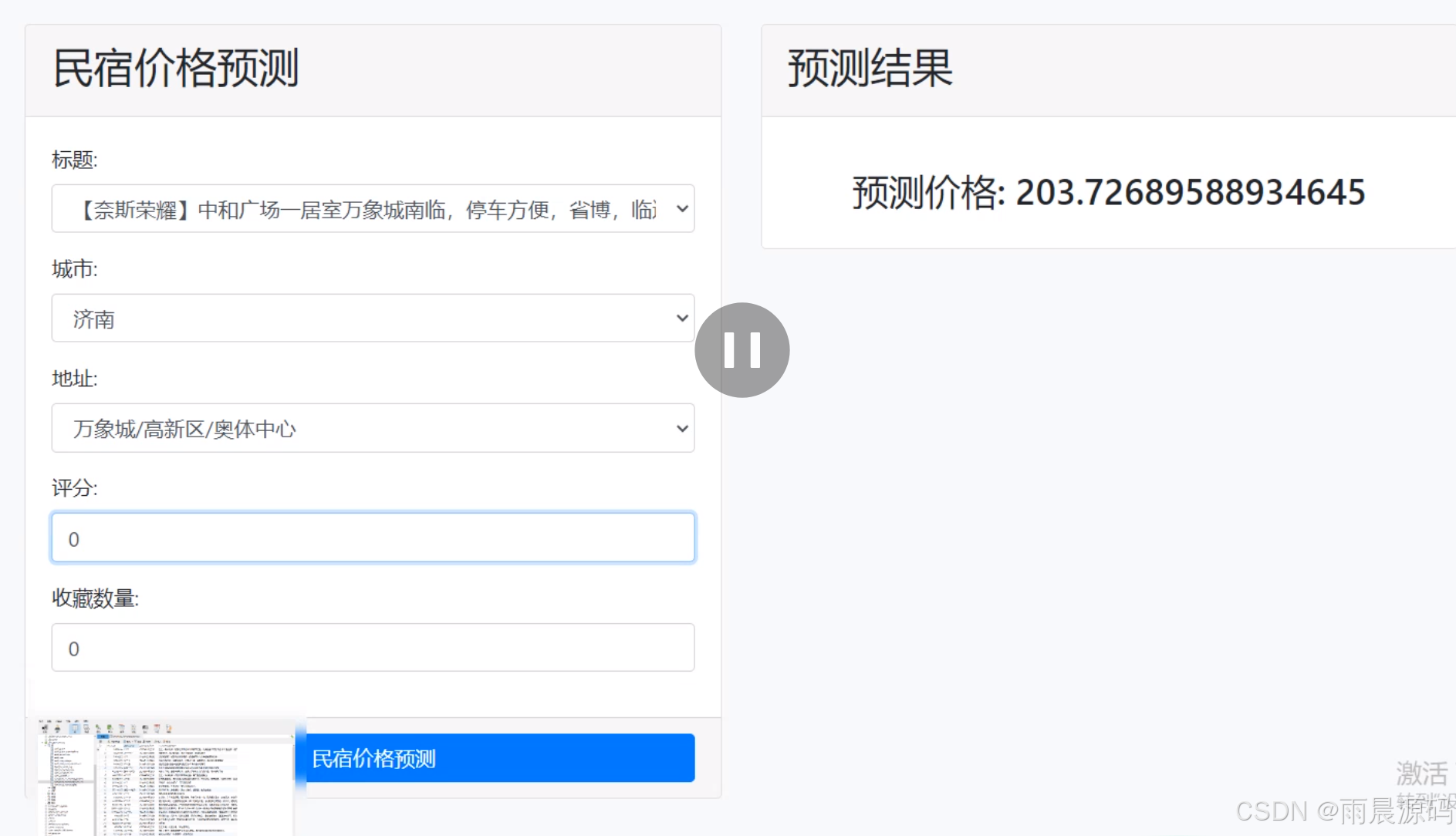
☀️词云图☀️
☀️NLP评论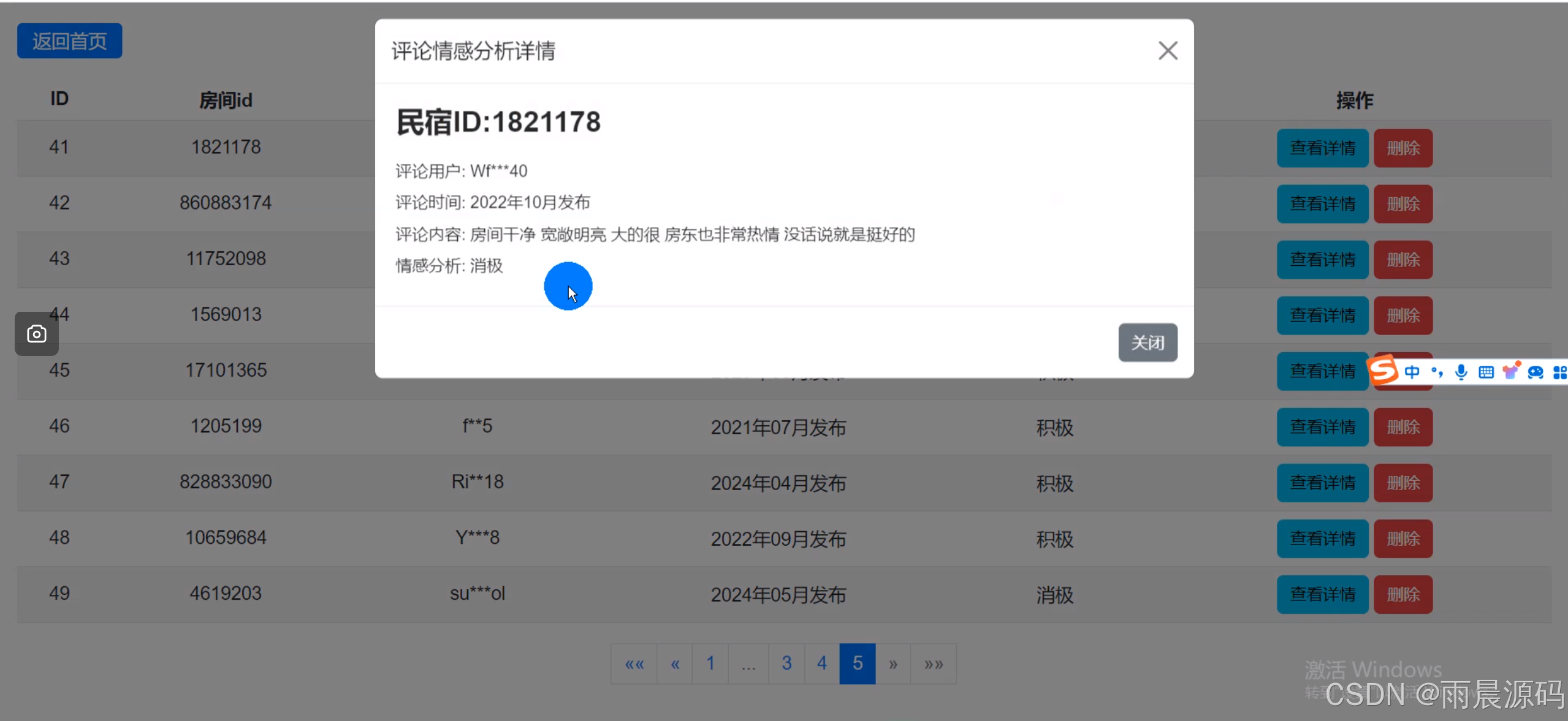
情感分析☀️
济南民宿数据可视化分析与价格预测系统-代码展示
1.数据爬虫【代码如下(示例):】
if not os.path.exists('dataset'):
os.mkdir('dataset')
# 创建csv文件
if not os.path.exists('./dataset/minsu_list.csv'):
minsu_list = pd.DataFrame(columns=['room_id', 'title', 'urls', 'city', 'address', 'score', 'collections', 'price', 'img'])
minsu_list.to_csv('./dataset/minsu_list.csv', encoding='utf-8-sig', index=False)
citys = [
# {'chongqing': '重庆'},
# {'chengdu': '成都'}, {'shanghai': '上海'}, {'guangzhou': '广州'}, {'shenzhen': '深圳'},
# {'hangzhou': '杭州'}, {'suzhou': '苏州'}, {'nanjing': '南京'}, {'wuhan': '武汉'},
# {'xian': '西安'},
# {'changsha': '长沙'}, {'qingdao': '青岛'}, {'dalian': '大连'}, {'xiamen': '厦门'}, {'tianjin': '天津'},
# {'zhengzhou': '郑州'}, {'jinan': '济南'}, {'fuzhou': '福州'}, {'ningbo': '宁波'}, {'changchun': '长春'},
# {'hefei': '合肥'}, {'haerbin': '哈尔滨'}, {'shenyang': '沈阳'}, {'nanning': '南宁'}, {'wulumuqi': '乌鲁木齐'},
# {'lanzhou': '兰州'}, {'guiyang': '贵阳'}, {'kunming': '昆明'}, {'lasa': '拉萨'}, {'nanchang': '南昌'},
# {'huhehaote': '呼和浩特'}, {'yinchuan': '银川'}, {'xining': '西宁'}, {'taiyuan': '太原'}, {'haikou': '海口'},
# {'shijiazhuang': '石家庄'}, {'taipei': '台北'}, {'hongkong': '香港'}, {'macau': '澳门'}
{'guangzhou': '广州'}]
# 循环所有城市
for city in citys:
# 获取城市名
city_name = list(city.values())[0]
# 获取城市拼音
city_pinyin = list(city.keys())[0]
for i in range(0, 200):
url = f'https://minsu.dianping.com/{city_pinyin}/pn{i + 1}/'
driver.get(url)
js = "var q=document.documentElement.scrollTop=100000"
driver.execute_script(js)
time.sleep(3)
h_list = driver.find_elements(By.XPATH, '//*[@id="J-ProductList"]/div/div[2]/div/div/div/div/div')
# 所有列表节点对象
for h in h_list:
try:
room_id = h.find_element(By.XPATH, './div[1]/div/a').get_attribute('href')
room_id = room_id.split('housing/')[-1]
room_id = room_id.split('/')[0]
title1 = h.find_element(By.XPATH, './div[1]/div/a/figure/figcaption/div[1]').text
address1 = h.find_element(By.XPATH, './div[1]/div/a/figure/figcaption/div[2]/div[2]').text
img = h.find_element(By.XPATH, './div[1]/div/a/figure/div/div[1]/div/div[1]/div/div/div[2]/div/div/img').get_attribute('src')
url1 = h.find_element(By.XPATH, './div[1]/div/a').get_attribute('href')
score = h.find_element(By.XPATH, './div[1]/div/a/figure/div/span/span').text
price1 = h.find_element(By.CLASS_NAME, 'product-card__price__latest').text
# 把price1中的¥符号去掉
price1 = price1.replace('¥', '')
collections1 = h.find_element(By.XPATH, './div[1]/div/a/figure/div/div[2]/span').text
data = {
'room_id': room_id,
'title': title1,
'urls': url1,
'city': city_name,
'address': address1,
'score': score,
'collections': collections1,
'price': price1,
'img': img,
}
2.机器学习模型【代码如下(示例):】
# 读取数据
data = pd.read_csv("output/minsu.csv")
print(data.columns)
# 提取特征和目标变量
X = data[['id', 'score', 'collections', ]]
y = data['price']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, y_pred)
print("均方误差 (MSE):", mse)
# 预测价格
id = 16
collections= 20
score = 3.5
price = model.predict([[id, collections, score, ]])
#把price转化为整数
price = price.astype(int)
print(f"预测价格: {price[0]:.2f}")
joblib.dump(model, '价格.pkl')
print("模型已保存。")
济南民宿数据可视化分析与价格预测系统-结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python实战项目集
💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)