
微小目标检测:《RFLA: Gaussian Receptive Field based Label Assignment for Tiny Object Detection》
微小的物体以其极其有限的像素数量为特点,在计算机视觉社区中始终是一个难以破解的难题。微小目标检测 (TOD) 是最具挑战性的任务之一,由于微小目标缺乏区分特征,通用目标检测器通常无法在 TOD 任务中提供令人满意的结果。
1、背景
微小的物体以其极其有限的像素数量为特点,在计算机视觉社区中始终是一个难以破解的难题。微小目标检测 (TOD) 是最具挑战性的任务之一,由于微小目标缺乏区分特征,通用目标检测器通常无法在 TOD 任务中提供令人满意的结果。
2、面临的问题
一般的目标检测在预测框和gt匹配时,选择基于IOU或者基于centerness。即根据预测框和gt之间的框交占比或者距离来决定gt和哪个预测框进行匹配。匹配成功的为正样本,不成功的为负样本。
但是在小样本检测中,gt的面积非常小,如果预测框和gt在位置上有一点偏移,在面积上就没有重叠,IOU=0,此时就会被视为负样本。或者预测框比较大,而gt比较小,即使有重叠,IOU计算结果也很小,再经过IOU阈值过滤,也容易被过滤掉视为负样本。
总之现有的预测框和gt分配高度依赖bbox的重叠的IOU,而小目标由于本身面积很小,容易造成IOU很小甚至为0,故在训练中缺少足够的正样本。
在目标检测训练过程中,若因预测框与真实框(GT)的IoU过小导致正样本不足,会引发以下问题:
- 模型学习困难与梯度失衡
• 定位损失失效:仅正样本参与定位损失(如CIoU Loss)的计算。若正样本不足,大量预测框因IoU过低被标记为负样本,导致模型无法通过梯度更新有效优化边界框位置。
• 置信度学习混乱:所有样本均参与置信度损失(BCE Loss),但负样本数量远多于正样本时,模型会倾向于将所有预测框的置信度压低(“背景偏向”),降低对真实目标的敏感度。- 小目标检测性能下降
• 微小目标漏检:微小目标的覆盖区域有限,若其与Anchor的宽高比超出阈值(如YOLOv5的1/4至4范围),或IoU未达匹配标准,则无法生成足够正样本,导致模型难以学习其特征。
示例:一个8×8像素的小目标,若其宽高与预设Anchor的比值超过4,则被排除在正样本外,模型可能完全忽略该目标。- 负样本主导训练过程
• 梯度淹没问题:负样本占比过高时,置信度损失的梯度会被大量负样本主导,导致模型更关注“抑制背景”而非“增强目标信号”,最终降低召回率(Recall)。
实验数据:在YOLOv3中,若正负样本比例失衡至1:100,模型可能完全无法收敛。- 收敛速度与泛化能力受限
• 收敛缓慢:正样本不足时,模型需通过少量样本反复调整参数,导致训练周期延长。例如,YOLOv5通过跨分支、跨网格策略将单个目标的正样本数量提升至27个,但若IoU未达标,这些扩展机制将失效,显著拖慢训练进度。
• 过拟合风险:模型可能仅依赖少数正样本的噪声数据拟合,降低对复杂场景的泛化能力。- 预测框定位偏差放大
• 边界模糊问题:若正样本不足,模型难以通过损失函数修正预测框的偏移。例如,YOLOv5通过限制预测框中心偏移范围(-0.5至1.5)扩展正样本,但IoU过低的预测框无法触发该机制,导致定位误差累积。解决方案与优化方向
- 动态标签分配:采用RFLA等策略,基于高斯感受野度量特征点与GT的相似性,替代固定IoU阈值,提升微小目标的匹配灵活性。
- 损失函数改进:引入Focal Loss或GFL(Generalized Focal Loss),降低简单负样本的权重,缓解梯度失衡。
- Anchor优化:通过k-means聚类和遗传算法调整Anchor尺寸分布,使其更贴合数据集中目标的大小特征。
总结来看,正样本不足会直接影响模型对目标位置和置信度的学习能力,尤其对微小目标和复杂场景的检测性能造成严重损害。YOLOv5通过宽高比匹配、跨网格扩展等策略缓解该问题,但在极端IoU条件下仍需结合更灵活的分配机制和损失设计。
也就是微小目标检测的训练不能通过简单的IOU来进行标签gt分配,
3、论文核心IDEA
在论文中有几个关键点:
- 在《Luo, W., Li, Y., Urtasun, R., Zemel, R.: Understanding the effective receptive field in deep convolutional neural networks. Advances in Neural Information Processing Systems 29 (2016)》中理论分析,当将特征点的感受野重新映射回输入图像时,有效的感受野实际上是高斯分布的,而标注的通常是矩形bbox,和高斯分布的bbox差距导致不匹配问题。
- 基于IOU的gt分配通常无法匹配小目标,导致小目标被划分为负样本而得不到学习,损害了模型对小目标检测的能力。
为此提供了两种手段:
- 引入了一种基于高斯分布的新型先验(类似bbox标注,只不过换成了高斯分布)
- 构建了一种更有利于微小目标的基于高斯感受野的标签分配 (RFLA) 策略
- 使用感受野距离(RFD)匹配高斯分布的特征点和高斯分布的gt
3.1 基于高斯分布的有效感受野
上面已经讨论了基于IOU进行预测框和gt匹配会带来的问题,所以这里提出了新的RFLA匹配策略,匹配之前就是转换为高斯分布。
在此之前,需要了解两个感念,理论感受野TRF和有效感受野ERF,在文章《对深度学习中感受野的理解》有详细的介绍,不再赘述。
论文的逻辑就是使用每个特征点在原图上的有效感受野(高斯分布)和gt的高斯分布进行匹配,实现标签的分配。那么问题是如何计算有效感受野?在上句文章中知道,理论感受野是可以计算出来的,但是有效感受野受到激活函数、网络结构等多方面影响,不方便计算。所以论文中直接:
- 使用特征点的位置 ( x n , y n ) (x_n,y_n) (xn,yn)作为2D高斯分布的平均向量
- 使用理论感受野半径的一般近似作为有效感受野的半径 e r n er_n ern
- 使用 e r n er_n ern的平方作为标准方形卷积核的高斯分布协方差
总之有效感受野通过特征点位置和理论感受野信息,建模为高斯分布 N e ( μ e , ∑ e ) N_e(μ_e,∑_e) Ne(μe,∑e),其中: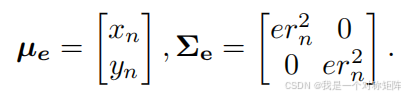
3.2 将gt建模为高斯分布
得到高斯分布的有效感受野,接下来的关键步骤是测量特征点的 ERF 与某个 gt 的匹配程度。则也需要将gt建模为高斯分布。
已知gt bbox的位置和长宽 ( x g , y g , w g , h g ) (x_g,y_g,w_g,h_g) (xg,yg,wg,hg),则将其建模为标准的二维高斯分布 N g ( μ g , ∑ g ) N_g(μ_g,∑_g) Ng(μg,∑g):
3.3 感受野距离(Receptive Field Distance,RFD)
现在特征点和gt都建模为高斯分布了,那么面对输入图经过模型后得到的众多高斯特征点和高斯gt,如何度量匹配程度?
作者研究了三种高斯分布之间的三种经典距离:Wasserstein 距离、K-L散度、J-S散度。高斯分布之间的 J-S 散度没有闭式解,在逼近其解时将引入大量的计算,因此不使用 J-S 散度。
论文中经过一通分析后,选择了K-L散度作为度量方法。
3.4 分层标签分配(Hierarchical Label Assignment,HLA)
无论使用何种度量方法,总会得到匹配分数。比如基于IOU的匹配结果可能是0~1之间的任意值,而基于感受野距离的匹配方法,也会得到连续的值。一般的方法可能会设置IOU阈值,比如设置IOU阈值=0.5,则匹配计算小于0.5的特征点和gt就认为匹配失败,将特征点框分入负样本中。
前面已经分析了,微小目标一点偏差就可能导致匹配值很小,使用基于阈值来划分正样本负样本,是不利用训练的,所以论文使用分层标签分配。
HLA分为两个阶段,逐步为每个目标分配正样本:
第一阶段:初步分配
- 计算RFD得分:对每个特征点与GT(Ground Truth)之间的感受野距离(RFD)进行计算。RFD是基于高斯感受野与GT的高斯分布之间的相似性(如Wasserstein距离或K-L散度)计算的。
- 排序与分配:对每个GT,将其对应的特征点按RFD得分从高到低排序,选择前 k k k个特征点作为正样本,并生成初步分配结果 r 1 r_1 r1和对应的掩码 m m m。
第二阶段:补充分配
- 衰减有效半径:为了进一步提高召回率并缓解异常值的影响,通过乘以一个阶段因子 β \beta β(通常设置为0.9)来略微衰减有效半径 e r n ern ern。
- 重复排序策略:基于衰减后的有效半径,重复第一阶段的排序策略,为每个GT补充一个正样本,得到补充分配结果 r 2 r_2 r2。
- 最终分配结果:将两个阶段的分配结果 r 1 r_1 r1和 r 2 r_2 r2合并,得到最终的正样本分配结果 r r r。
第一阶段很好理解,就是将和gt得分最高的K个特征点作为匹配的正样本。
第二阶段中降低了半径,根据公式降低了高斯分布的方差,则其范围变大。然后再次距离得分,给每个gt分配一个特征点,注意如果重复了则不作数,如已经分配了[a,b,c,d]特征点给gt1,二阶段又分配a,则gt1匹配的特征点仍然是[a,b,c,d]。公式如下,r1是一阶段分配特征点,r2是二阶段分配特征点,m是已分配特征点的掩码(比如:[a,b,c,d][1,1,1,1]+[a][0]=[a,b,c,d],再比如[a,b,c,d][1,1,1,1]+[e][1]=[1,b,c,d,e],e在第一次没有分配故m=0,第二次中1-m=1)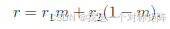
掩码的存在避免了已分配足够样本的 GT 引入过多的低质量样本。
3.5 总流程
具体流程如下,输入图像经过特征提取得到特征图,特征点建模为高斯分布ERF,gt也建模为高斯分布。然后计算gt和特征点之间的距离,使用HLA进行匹配。最终得到正负样本对。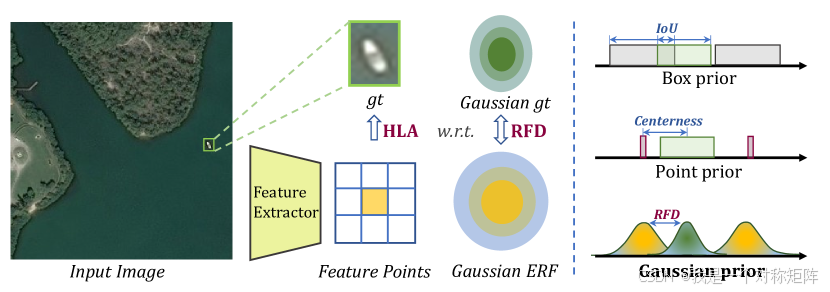
4、实验效果
论文给出了很多实验数据,这里仅给出消融实验,可以看到基于IOU的GIOU和高斯距离度量算法的差异还是蛮大的。而高斯分布+一阶段HLA效果直接翻倍。
但是注意,以上算法都是针对微小目标检测的痛点设计的,对于大尺寸目标不一定有用。
基于此有如下想法:
- 特征点的高斯分布形状都一样(从定义可以看到之和半径r相关,同一层的理论感受野都一样,所以协方差矩阵一样),是否可以在anchor基础上进行高斯建模,加入anchor形状信息,和gt的形状相关的高斯分布进行相似性计算?
- 在相似性计算时,特征点高斯形状都一样,不变的是位置,是否可以仅通过欧氏距离计算有效感受野中心和gt bbox中心的距离,基于距离矩阵使用HLA分配策略进行分配呢?这样是否也会有效果,和基于高斯建模的相似性度量有多大差异?
5、引用
RFLA: Gaussian Receptive Field based Label Assignment for Tiny Object Detection

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)