
DeepSpeed-Train 分布式模型训练(小白入门)
DeepSpeed 是一个基于 PyTorch 构建的深度学习优化库。它提供了一系列先进的技术,使得用户能够训练参数量高达数万亿的模型,并显著提升训练和推理的速度与效率。DeepSpeed 的核心目标是让大规模模型训练变得更加普惠和高效。
一、DeepSpeed-Train概述
随着深度学习模型的规模日益增大,训练这些庞大的模型对计算资源和内存的需求也急剧增加。传统的训练方法往往受限于单个 GPU 的内存容量,难以有效扩展。为了应对这一挑战,微软推出了 DeepSpeed 库,这是一个专注于深度学习优化,特别是大规模模型训练和推理的开源库。DeepSpeed 旨在提高训练和推理的效率、速度和规模,同时降低所需的硬件门槛。
1.1 什么是 DeepSpeed-Train?
DeepSpeed 是一个基于 PyTorch 构建的深度学习优化库。它提供了一系列先进的技术,使得用户能够训练参数量高达数万亿的模型,并显著提升训练和推理的速度与效率。DeepSpeed 的核心目标是让大规模模型训练变得更加普惠和高效。
1.2 DeepSpeed-Train 的核心技术与特性
DeepSpeed 的强大功能主要源于其集成的多种优化技术:
a) ZeRO (Zero Redundancy Optimizer): 这是 DeepSpeed 的核心创新之一。ZeRO 旨在消除内存冗余,通过在数据并行进程中对模型状态(参数、梯度、优化器状态)进行分区,从而显著降低每个 GPU 的内存占用。
- ZeRO-1: 对优化器状态进行分区。
- ZeRO-2: 对优化器状态和梯度进行分区。
- ZeRO-3: 对优化器状态、梯度和模型参数进行分区。
- ZeRO-Offload: 将部分模型状态(优化器状态、梯度甚至参数)卸载到 CPU 内存或 NVMe SSD,进一步突破 GPU 内存的限制。
b) 3D 并行 (3D Parallelism): DeepSpeed 将常见的并行训练策略整合并优化,实现了高效的 3D 并行:
- 数据并行 (Data Parallelism): 将数据分发到不同设备,每个设备拥有完整的模型副本。
- 流水线并行 (Pipeline Parallelism): 将模型的不同层分配到不同设备,数据按流水线方式流经各设备。DeepSpeed 提供了高效的流水线调度策略。
- 张量并行/模型并行 (Tensor/Model Parallelism): 将模型(或其层内操作)的计算分割到不同设备上。
c) DeepSpeed Inference: 针对大规模模型的推理场景,DeepSpeed 也提供了显著的优化。它利用 ZeRO 的思想以及定制化的 CUDA Kernel,实现了比标准 PyTorch 推理更高的吞吐量和更低的延迟,尤其是在多 GPU 环境下。
d) 混合精度训练 (Mixed Precision Training): 支持使用 FP16(半精度浮点数)进行训练,减少内存占用并加速计算,同时通过动态损失缩放等技术保持训练稳定性。
e) 高效的 IO 操作: 优化了模型加载和检查点保存的效率,尤其是在需要处理大量参数和优化器状态时。
1.3 DeepSpeed-Train 的优势
- 极致的内存优化: 通过 ZeRO 技术,显著降低了训练大规模模型所需的 GPU 内存。
- 卓越的训练速度: 结合多种并行策略和优化技术,大幅提升了训练吞吐量。
- 支持超大规模模型: 使训练万亿级参数模型成为可能。
- 易用性: 提供了简洁的 API,可以轻松集成到现有的 PyTorch 训练脚本中,通常只需修改几行代码。
- 推理加速: 为大型模型提供高效的推理解决方案。
- 灵活性: 用户可以根据需求选择和组合不同的优化技术。
1.4 应用场景
- 训练大型语言模型 (LLM): 如 GPT 系列、BLOOM 等。
- 训练大型视觉模型: 如 Vision Transformer 等。
- 多模态大模型训练: 结合文本、图像等多种模态的模型。
- 需要突破单 GPU 内存限制的任何深度学习任务。
- 对大型模型进行低延迟、高吞吐量的推理部署。
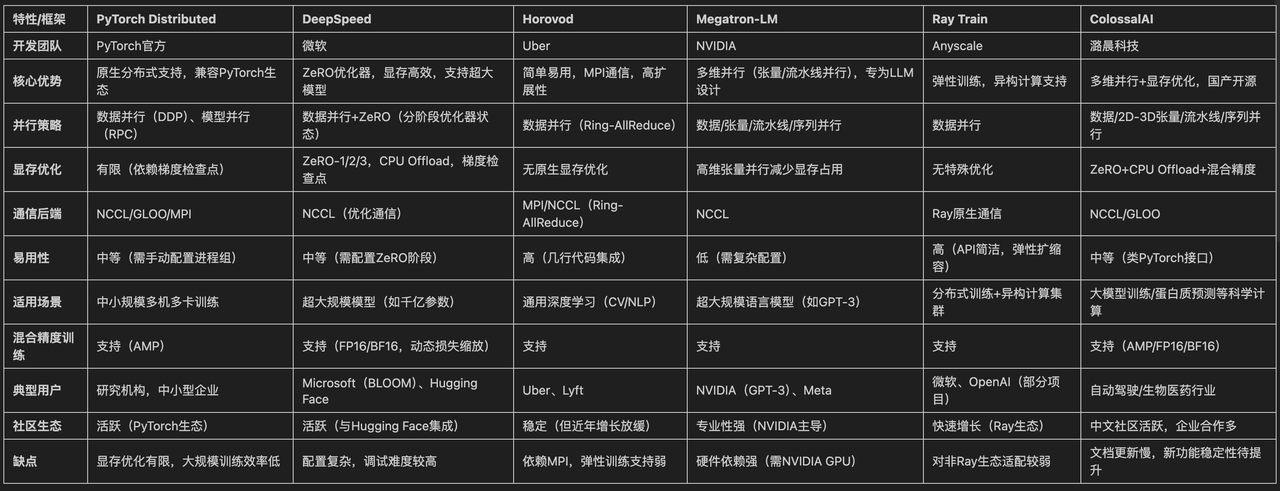
1.5 分布式微调框架对比

二、deepspeed-Train 基础环境准备
2.1 服务器资源准备
4台 ECS 带A10 显卡的服务器,系统 ubuntu 22.04 可以练习 qwen2.5 14b
2 台 ECS 可以练习 qwen2.5 7b 推荐 3b 规模
3 台 ECS 可以练习 qwen2.5 7b
可以按照实际情况选择,笔者使用的是 4 节点微调训练 qwen2.5 14b。单机 A10 14b 规模的模型微调任务肯定没法完成。重点是利用 deepspeed 的分布式能力完成微调。
详细的申请流程和注意事项请参考我之前写的一篇里面有介绍
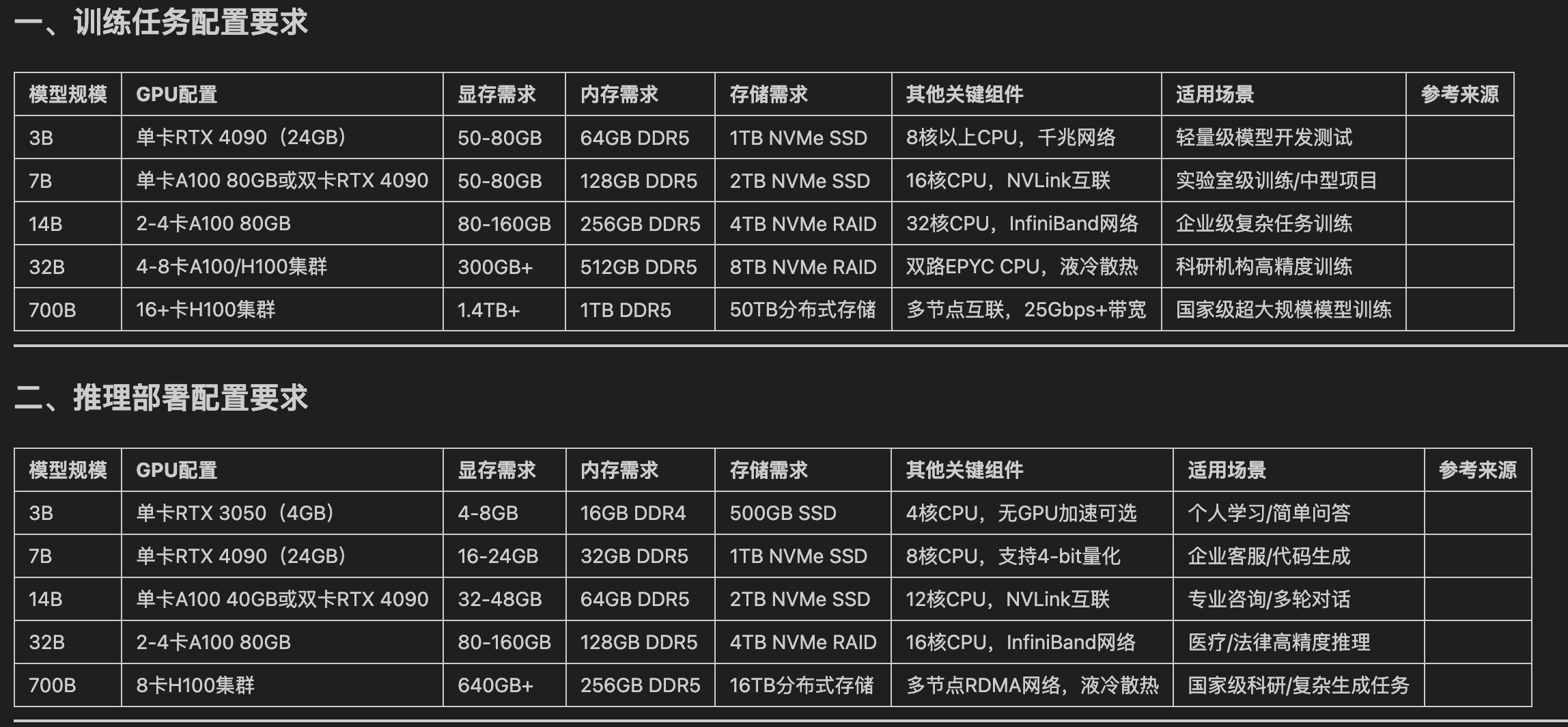
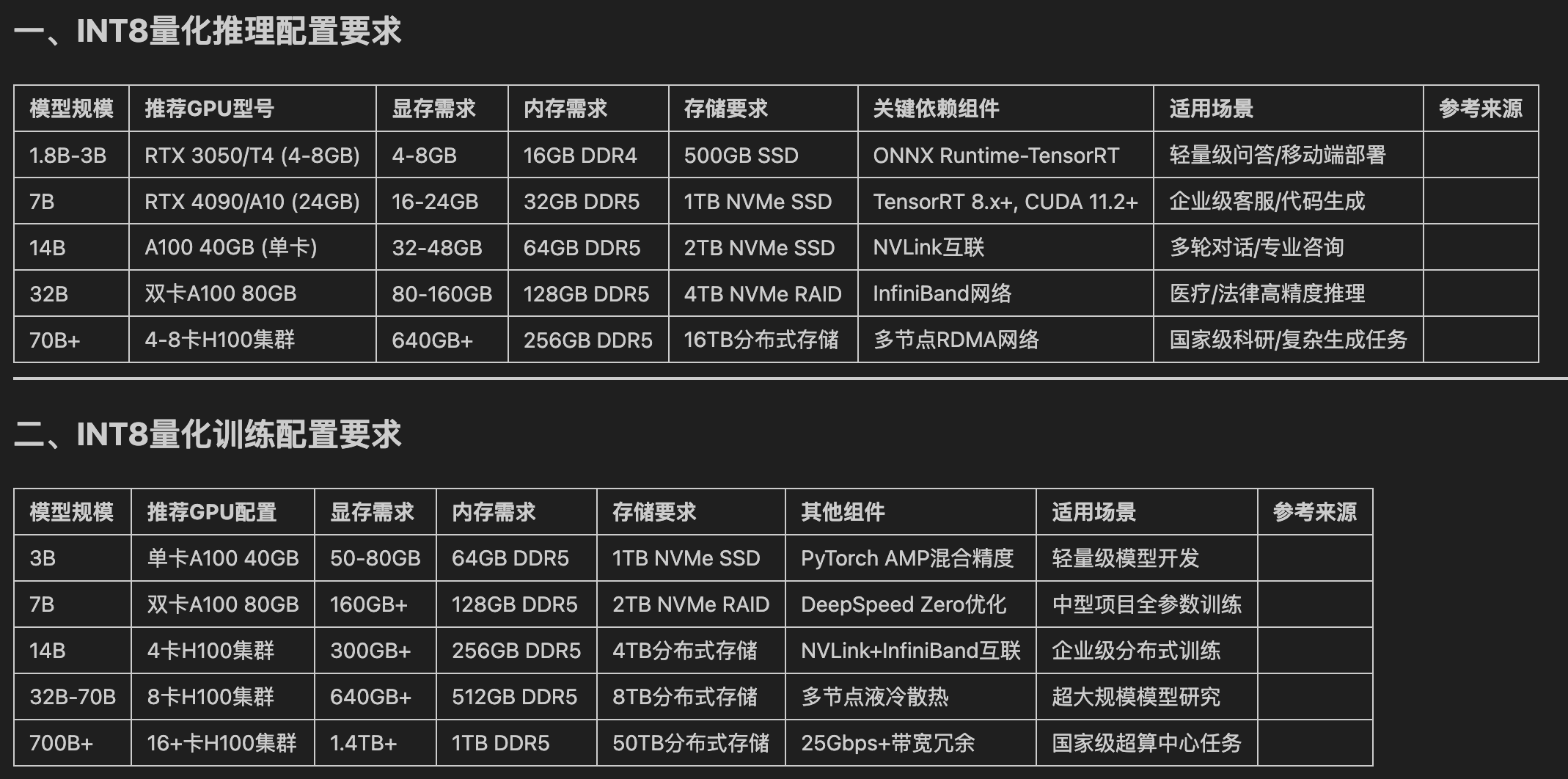
int8 量化过后的资源需求
2.2 基础环境配置
所有节点都需要配置
sudo apt update && sudo apt upgrade -y
sudo apt install -y git curl wget tmux htop ncdu unzip build-essential unzip rsync pdsh
sudo apt-get update && sudo apt-get install ninja-build
sudo hostnamectl set-hostname --static "te1"
echo "172.18.81.129 te1" >> /etc/hosts
echo "172.18.81.130 te2" >> /etc/hosts
echo "172.18.81.131 te3" >> /etc/hosts
echo "172.18.81.132 te4" >> /etc/hosts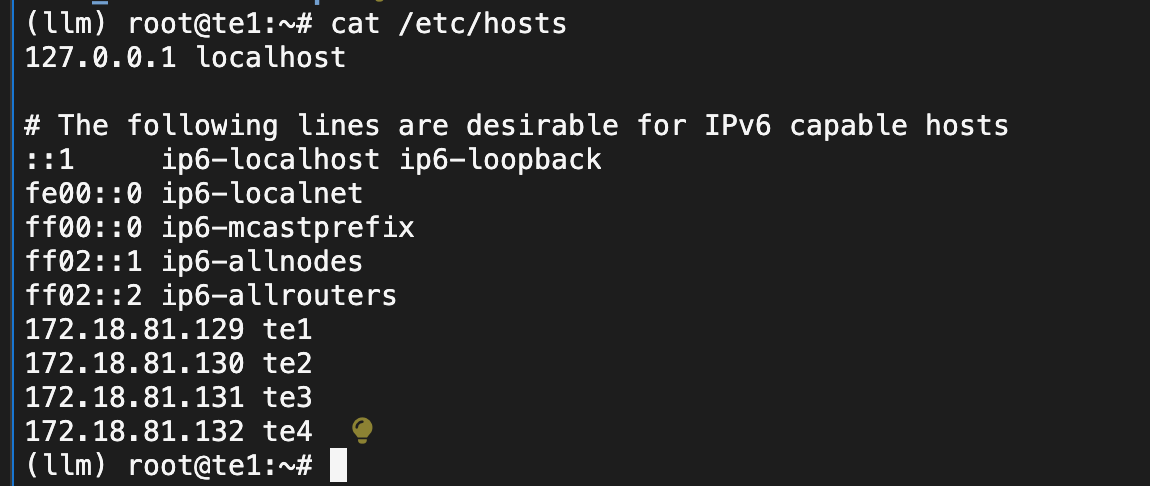
2.3 跨节点授信访问
1) 节点配置可用密码 ssh 登录访问
echo "PermitRootLogin yes" >> /etc/ssh/sshd_config
systemctl restart sshd# 配置 ssh 远程登录密码
passd# 主节点 te1执行 授信访问
cd ~/.ssh
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
ssh-copy-id -i ~/.ssh/id_rsa.pub root@te1
ssh-copy-id -i ~/.ssh/id_rsa.pub root@te2
ssh-copy-id -i ~/.ssh/id_rsa.pub root@te3
ssh-copy-id -i ~/.ssh/id_rsa.pub root@te4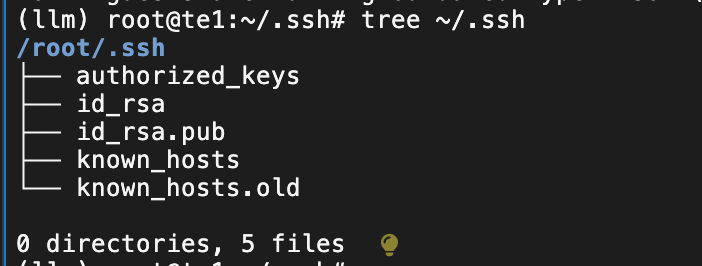
2) 节点配置可用密码 ssh 登录访问
验证pdsh 跨节点访问问题
pdsh -S -w te1,te2,te3,te4 hostname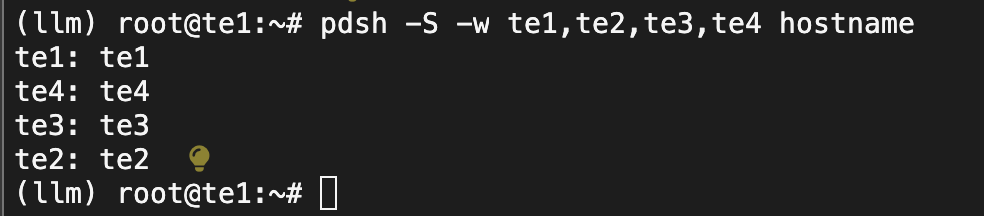
表示授信成功,te1主节点可以免密访问其它的节点
2.4 检测 NCCL 环境
test/test_multinode.py
deepspeed --hostfile=hostfile --master_addr=te1 test/test_multinode.pyimport torch
import torch.distributed as dist
import os
def main():
dist.init_process_group(backend='nccl')
rank = dist.get_rank()
world_size = dist.get_world_size()
# 简单的广播操作
tensor = torch.tensor([rank]).cuda()
dist.broadcast(tensor, src=0)
print(f"Rank {rank}/{world_size} received tensor: {tensor.item()}")
if __name__ == "__main__":
main()
dist.destroy_process_group()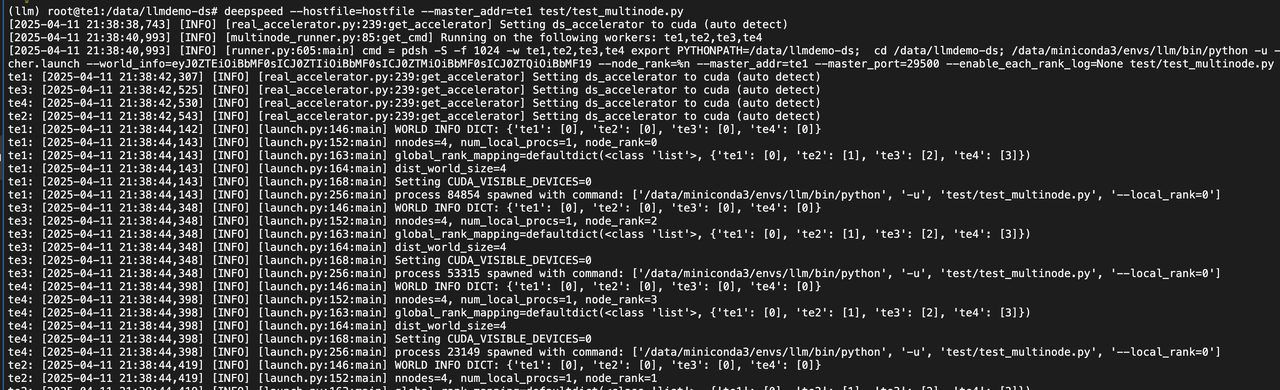
2.5 检查deepspeed分布式环境
test/hostfile
te1 slots=1
te2 slots=1
te3 slots=1
te4 slots=1
# test_multinode_enhanced.py
# deepspeed --hostfile=hostfile --master_addr=te1 test_multinode_enhanced.py
import torch
import torch.distributed as dist
import os
import time
def main():
# 初始化分布式环境
dist.init_process_group(backend='nccl')
rank = dist.get_rank()
world_size = dist.get_world_size()
local_rank = int(os.environ['LOCAL_RANK'])
device = torch.device(f'cuda:{local_rank}')
# 打印设备信息
print(f"Rank {rank}/{world_size} (local_rank {local_rank}) using {torch.cuda.get_device_name(device)}")
# 带宽测试
if rank == 0:
data = torch.randn(1000000, device=device)
dist.send(data, dst=1)
print(f"Rank 0 sent {data.numel()} elements to Rank 1")
elif rank == 1:
data = torch.empty(1000000, device=device)
dist.recv(data, src=0)
print(f"Rank 1 received {data.numel()} elements from Rank 0")
# 同步所有节点
dist.barrier()
# 集体通信测试
tensor = torch.tensor([local_rank], device=device)
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
print(f"Rank {rank} all_reduce result: {tensor.item()}")
if __name__ == "__main__":
main()
dist.destroy_process_group()
执行命令测试:
(llm) root@te1:/data/llmdemo-ds# deepspeed --hostfile=test/hostfile --master_addr=te1 test/test_multinode_enhanced.py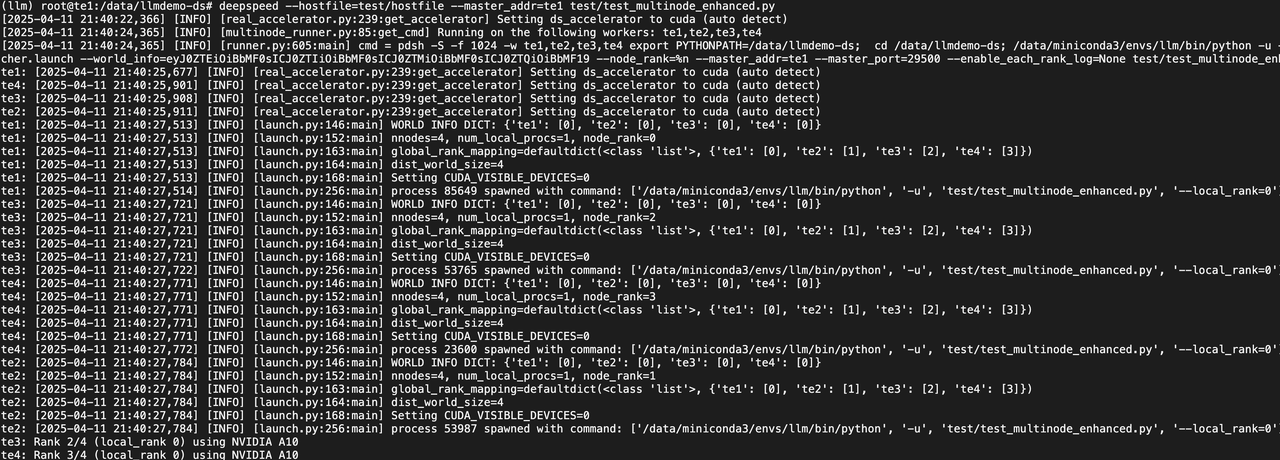
三、deepspeed模型训练
利用DeepSpeed ZeRO-3 结合 LoRA 来优化
3.1 代码准备
https://github.com/497429018/llmdemo-ds.git![]() https://github.com/497429018/llmdemo-ds.git
https://github.com/497429018/llmdemo-ds.git
代码工程结构
3.2 开始训练
(llm) root@te1:/data/llmdemo-ds# bash run.sh 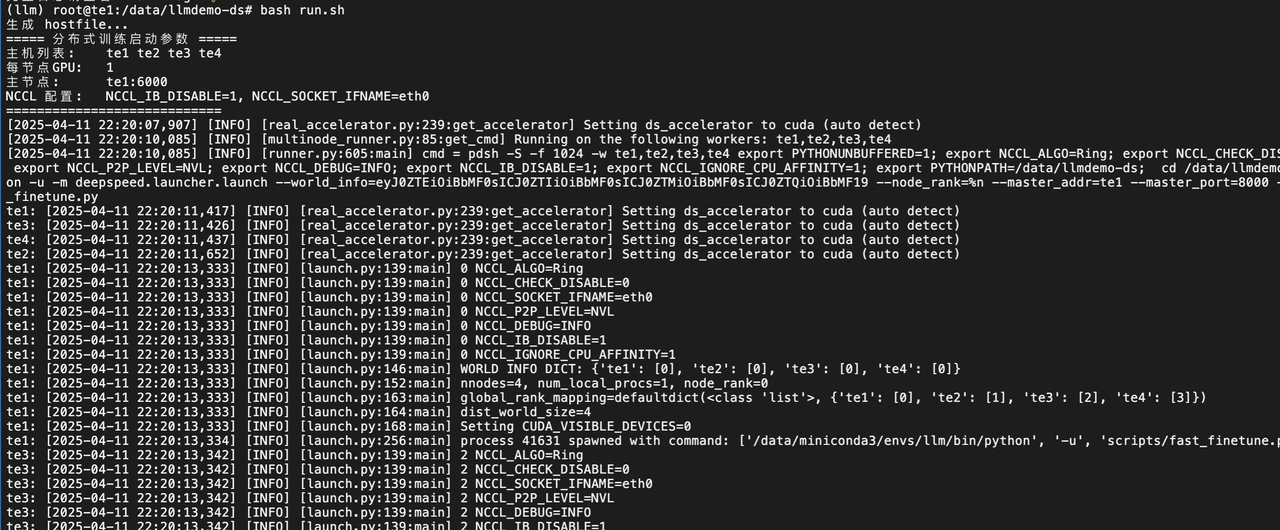
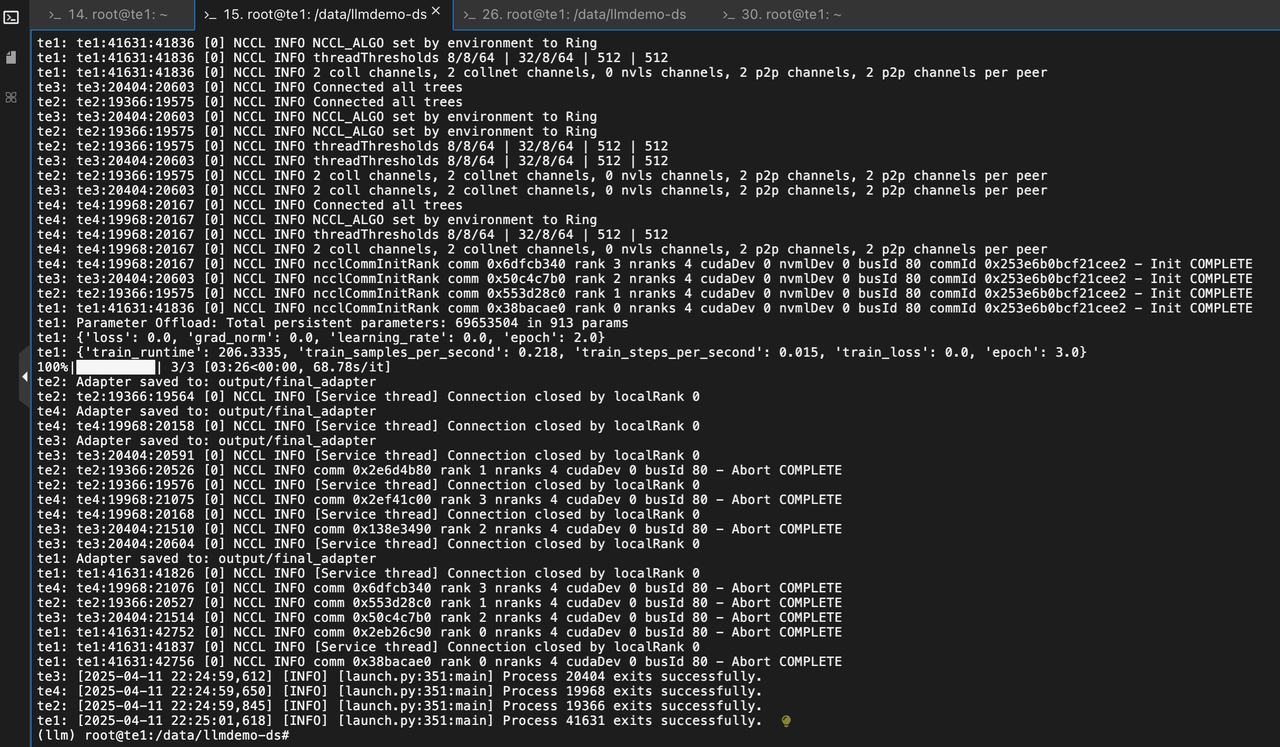
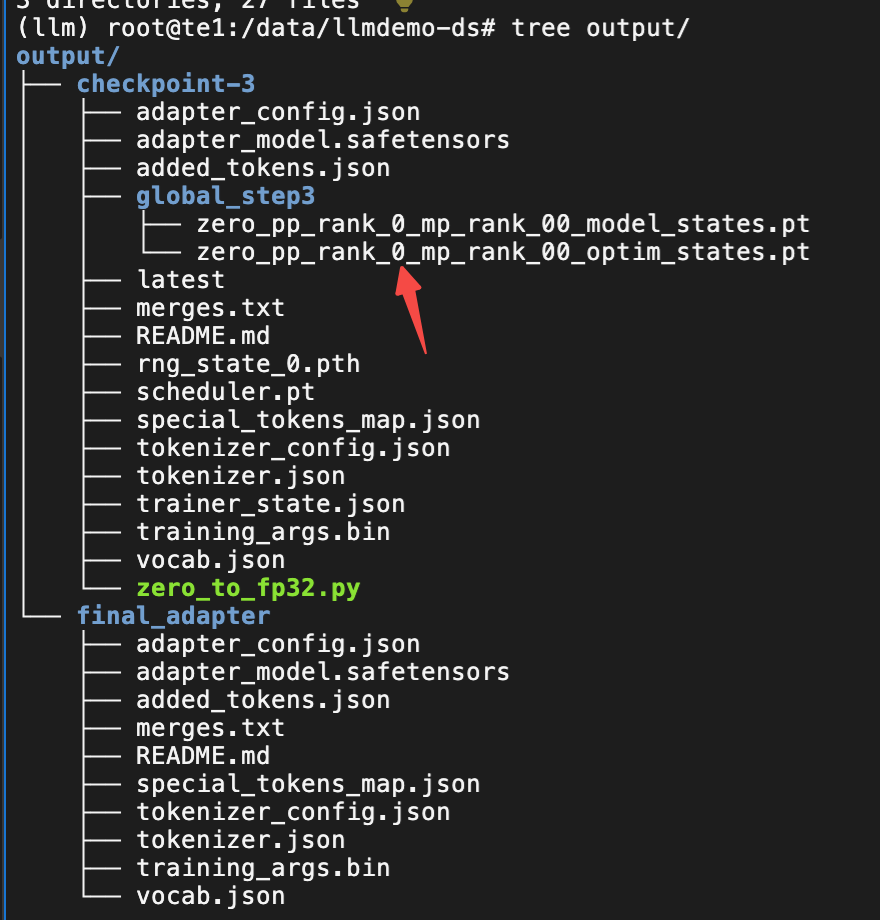
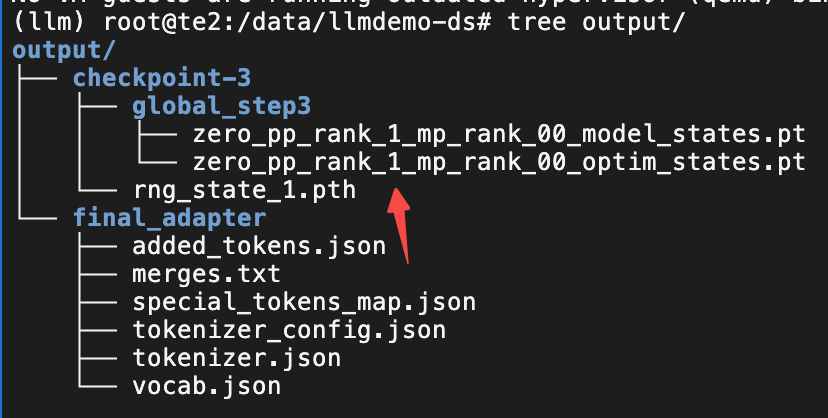
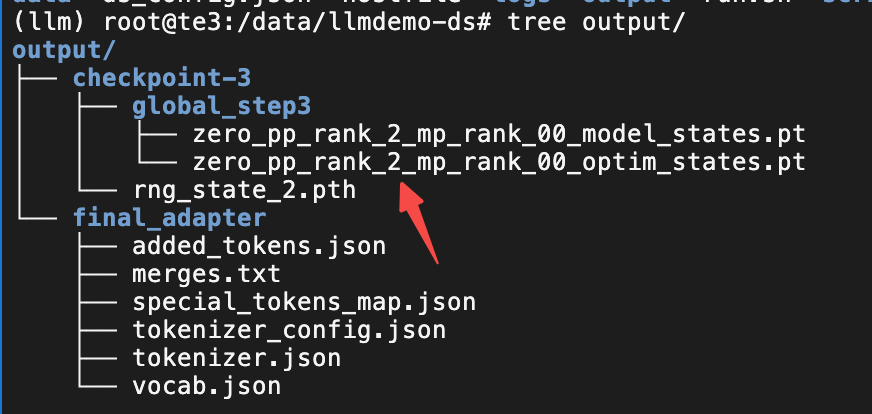
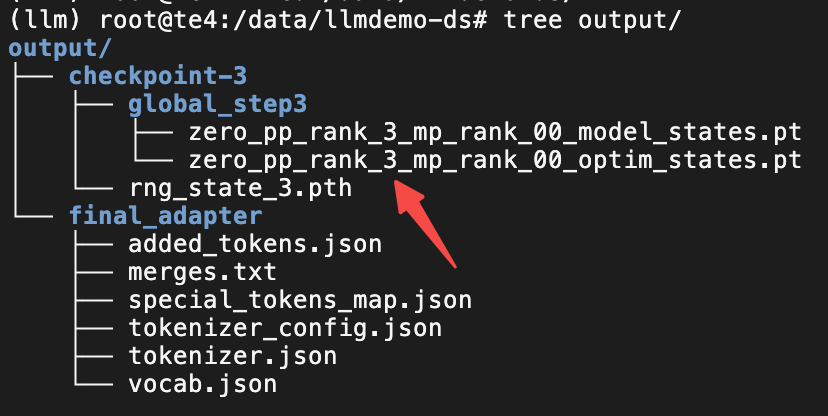
3.3 测试验证
目前是没有明显的报错且看目录结构的文件都已经顺利的生成了。接下来就是要验证模型是否符合预期。
A10 24Gi显存没法,测试 14b 规模的模型。报错了
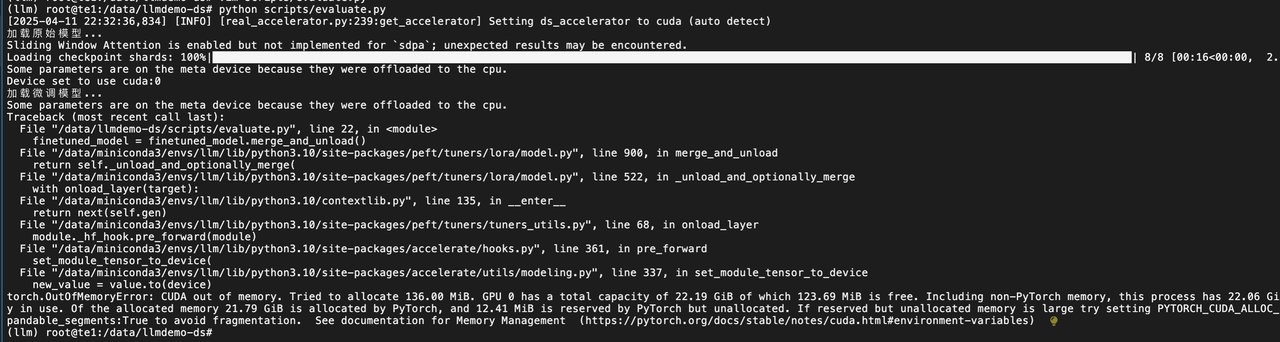
需要用到分布式 模型部署能力。实现的方式有很多种。这里我的目标是为了训练微调,就采用最简单的方法验证。微调后的模型
(留个坑等待补充。。。 Spot ECS 回收了 没脾气了,要重新调试推理模型部署了)
四、小结
DeepSpeed 分布式能力,实现A10 显卡 微调训练 14B 规模的模型。从基础环境准备,分布式环境配置测试。再到分布式训练,无数次改参数,不让 显存oom。未来希望能结合Megatron-LM正真实现3D 并行。
六、补充(阿里云可复用环境)
主要解决从 0 开始构建训练环境的麻烦和低效。在申请了 ECS 过后,要安装很多依赖,上传代码,基础模型等等。等所有的都配置好了一小时都过去了。所以还是需要更加低成本的方式。留存训练环境和数据等等,做好可复用。
当然如果后续采用容器方式去作为训练的基础和可以实现很便捷的方式快速构建训练环境。当前方法只针对 ECS 环境
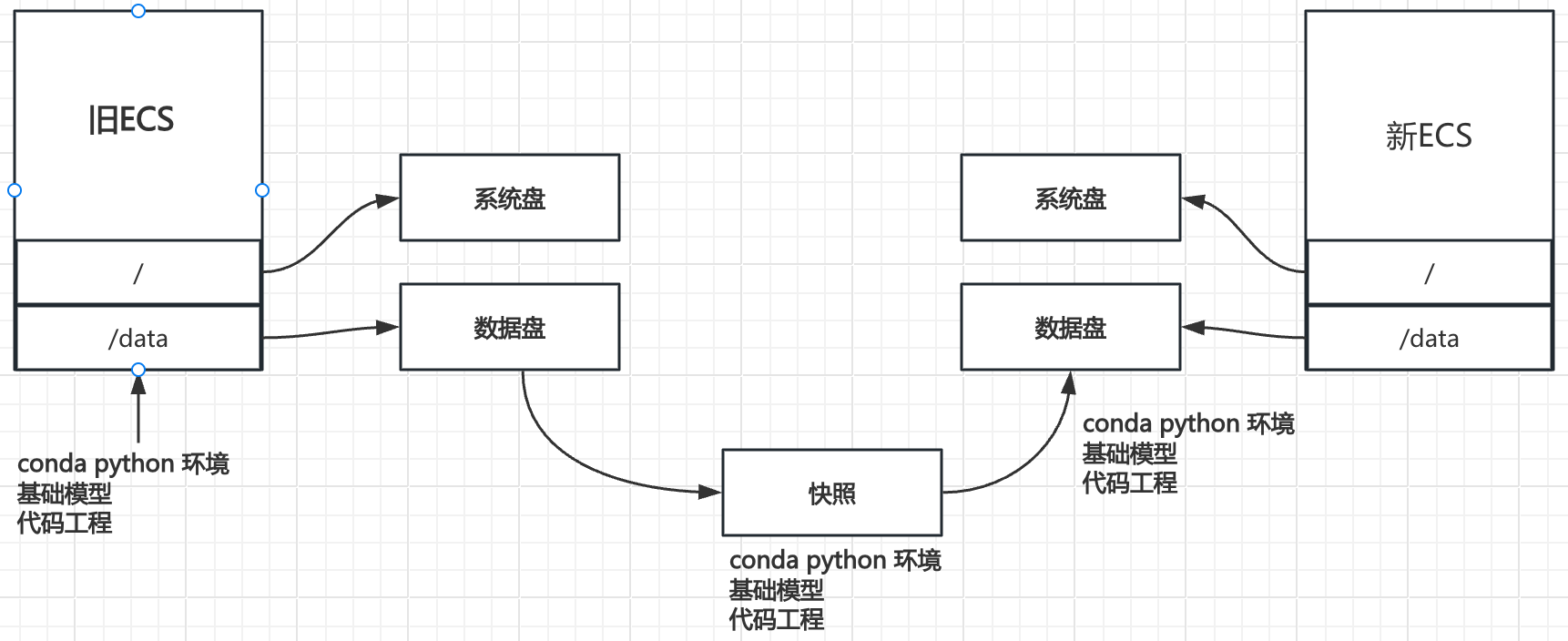
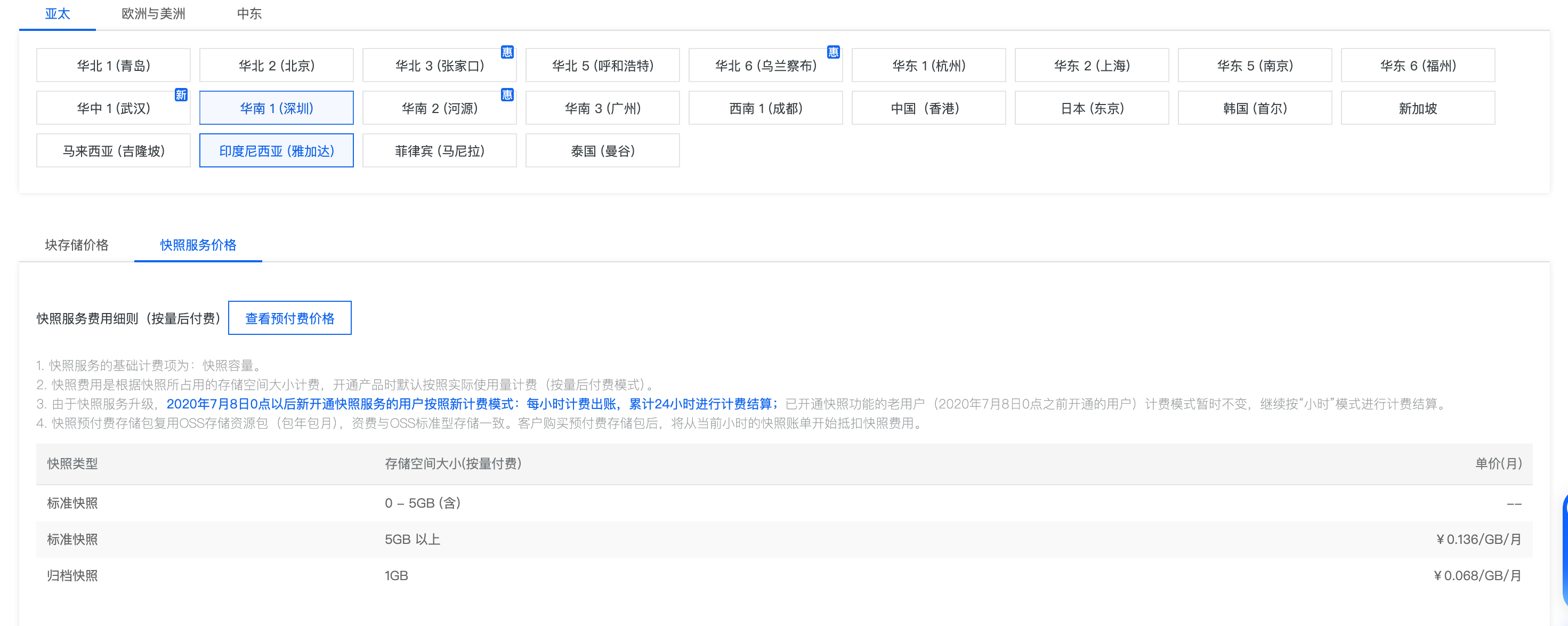
资费 在雅加达地区 120Gi 快照 一个月 8 块钱左右 非常便宜。这样就用了自己的一直留存随时可用的环境。
6.1 准备基准 ECS
创建 ECS 40Gi 系统盘和 120Gi 数据盘
6.2 canda 和基础模型构建
将 conda 和基础模型存储到 /data目录
还可以将调试代码也存放到/data 目录
# 安装 conda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O /data/Miniconda3.sh
bash /data/Miniconda3.sh -b -p /data/miniconda3
echo 'export PATH="/data/miniconda3/bin:$PATH"' >> ~/.bashrc
source /data/miniconda3/bin/activate
source ~/.bashrc
# 安装 conda 训练环境
conda create -n llm python=3.10 -y
conda activate llm
echo 'conda activate llm' >> ~/.bashrc
source ~/.bashrcsudo mkdir -p /data/models
huggingface-cli download Qwen/Qwen2.5-7B --resume-download --local-dir /data/models/qwen2.5-7b
huggingface-cli download Qwen/Qwen2.5-14B --resume-download --local-dir /data/models/qwen2.5-14b6.3 制作环境快照
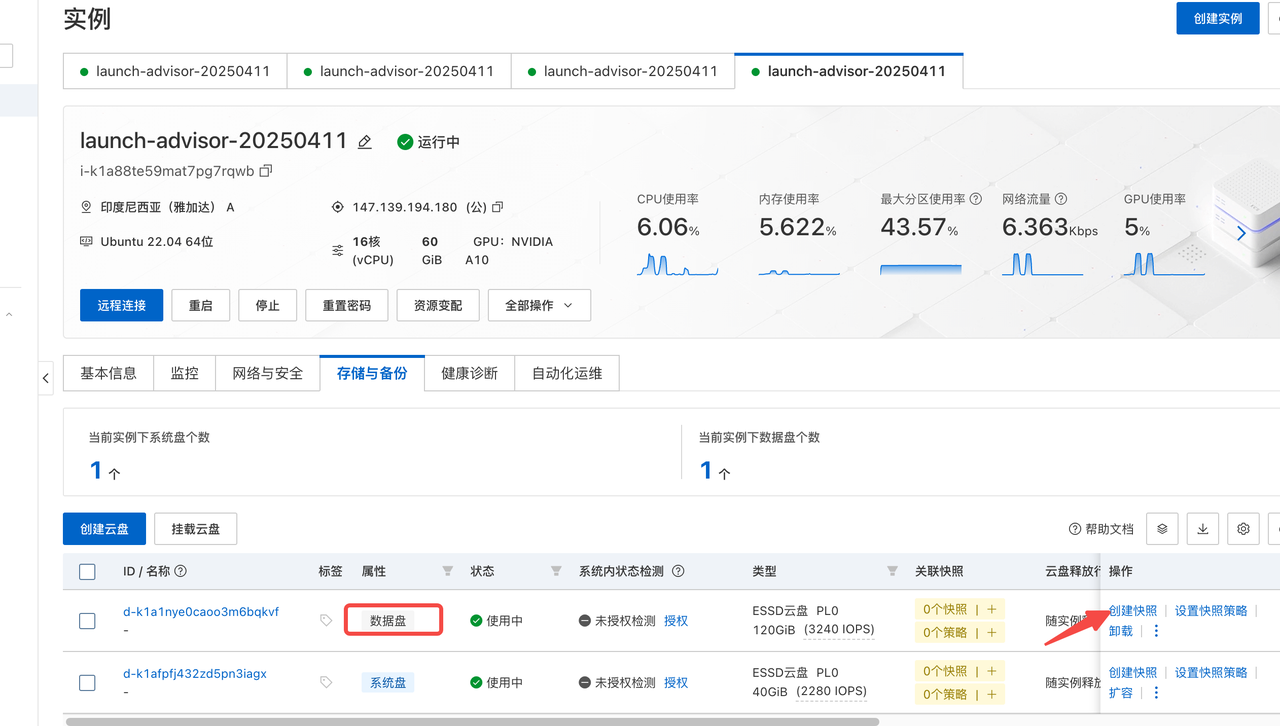
6.4 还原环境
在选择数据盘时 一定要选择用快照创建磁盘。这样是可以直接保存快照数据的
且快照价格也便宜一些。
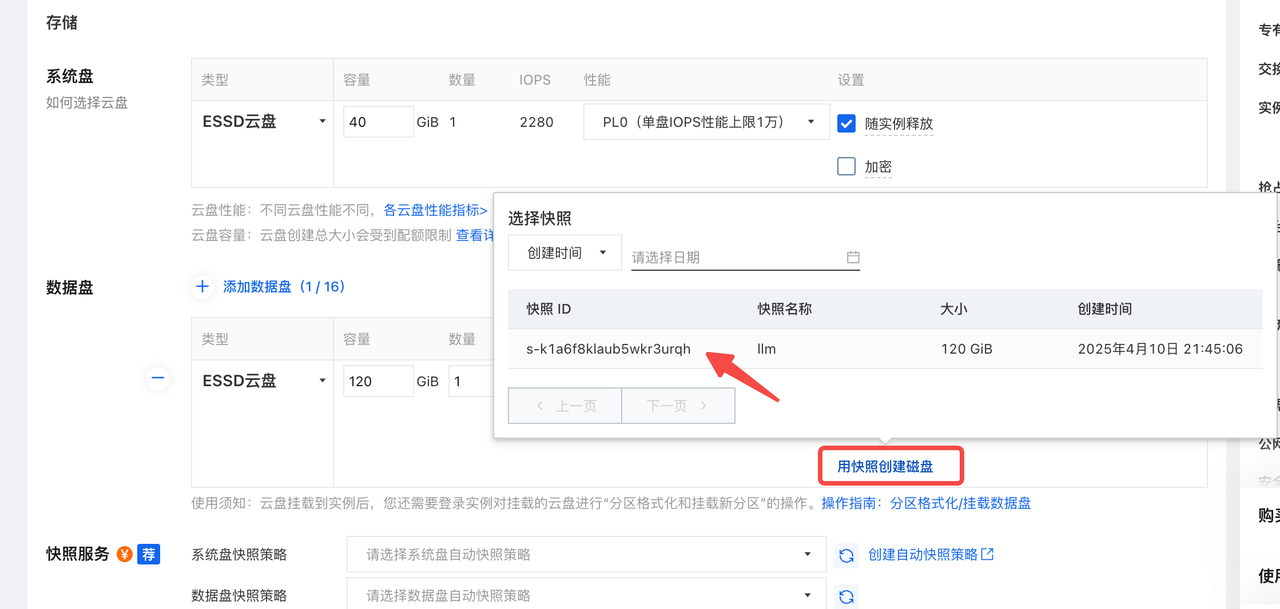
注意:需要自己去挂载数据盘
fdisk -l
mkdir /data
mount /dev/vdb1 /data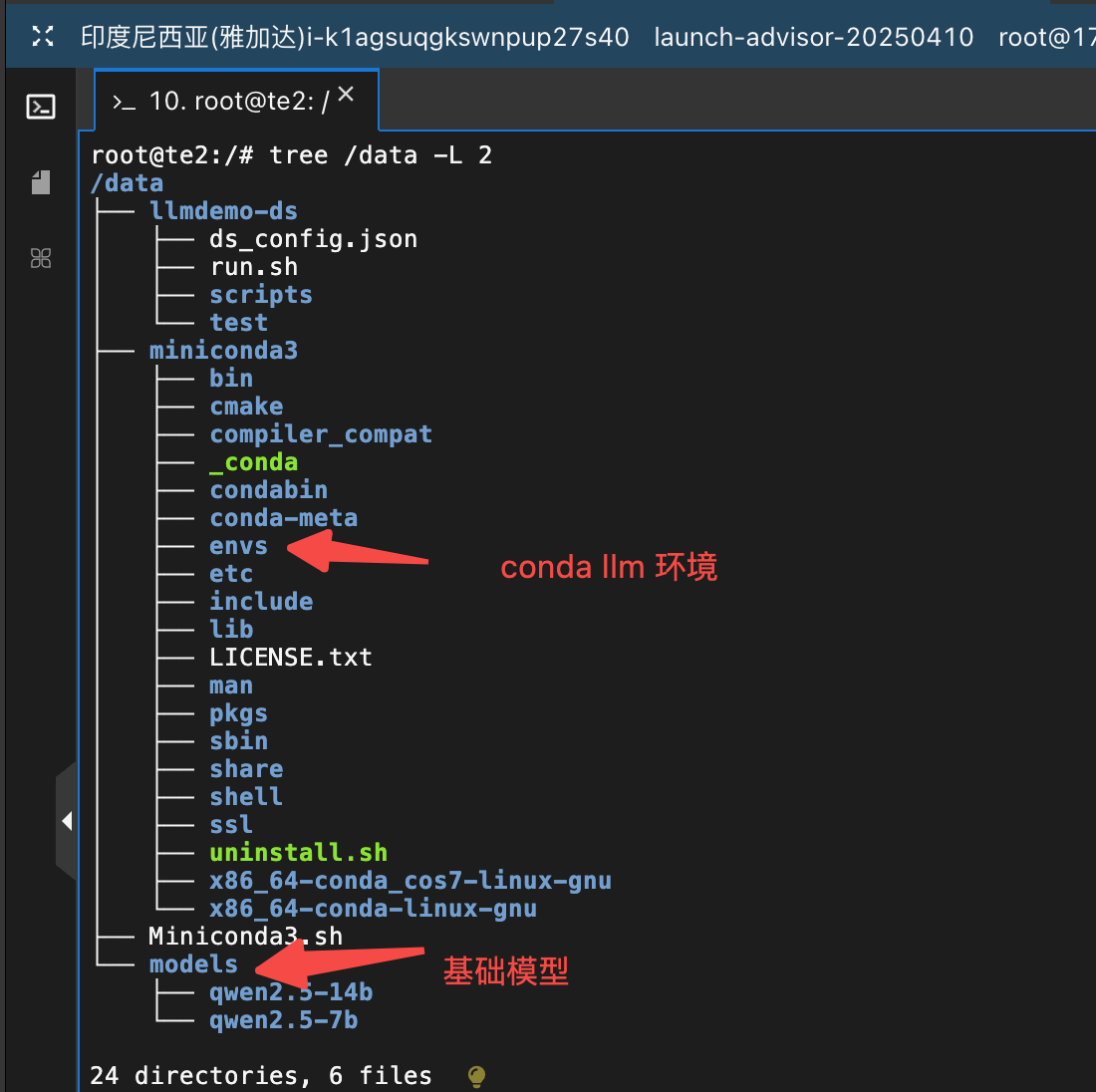
问题
GPU占用清理进程
nvidia-smi
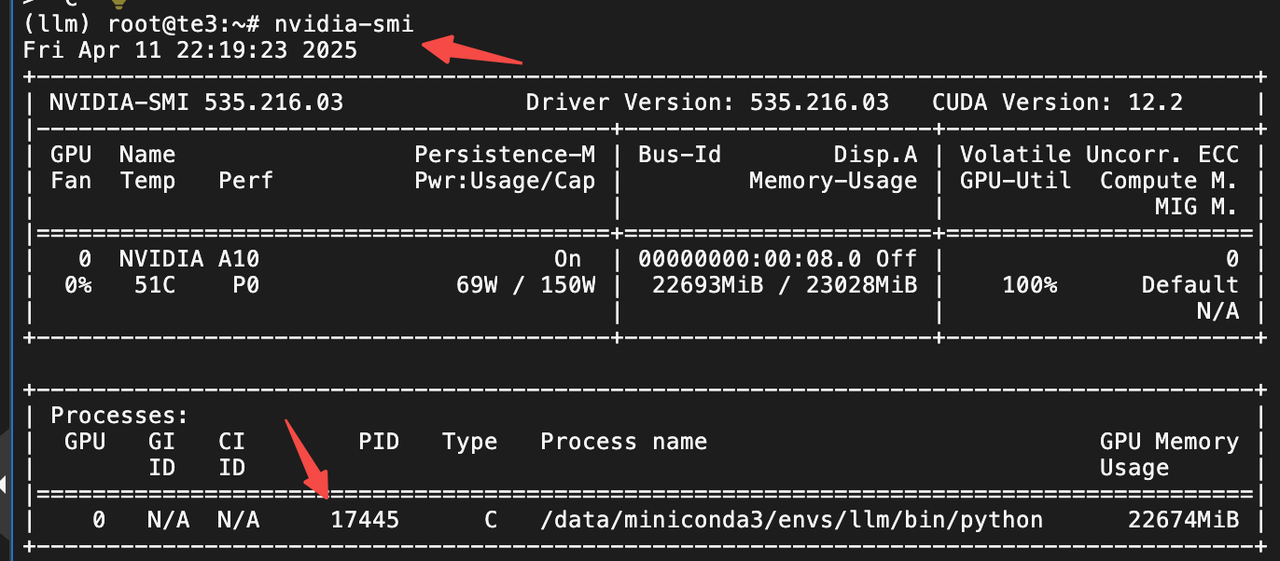
kill -9 PID
参考:
Latest News - DeepSpeedDeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.![]() https://www.deepspeed.ai/https://github.com/NVIDIA/Megatron-LM
https://www.deepspeed.ai/https://github.com/NVIDIA/Megatron-LM![]() https://github.com/NVIDIA/Megatron-LMhttps://github.com/microsoft/LoRA
https://github.com/NVIDIA/Megatron-LMhttps://github.com/microsoft/LoRA![]() https://github.com/microsoft/LoRA
https://github.com/microsoft/LoRA
https://zhuanlan.zhihu.com/p/624412809![]() https://zhuanlan.zhihu.com/p/624412809
https://zhuanlan.zhihu.com/p/624412809

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)