
基于机器学习的网络入侵检测二元分类模型构建与性能评估(NSL-KDD数据集)
该项目是一个基于NSL-KDD数据集的网络入侵检测系统,主要采用机器学习方法对网络流量数据进行使用了多种机器学习模型,如逻辑回归、线性SVM、多项式核SVM、高斯核SVM、决策树、随机森林、朴素贝叶斯和K近邻算法训练二元分类(正常/异常)模型及预测,最后比较了各个算法的检测效果。
简介
该项目是一个基于NSL-KDD数据集的网络入侵检测系统,主要采用机器学习方法对网络流量数据进行使用了多种机器学习模型,如逻辑回归、线性SVM、多项式核SVM、高斯核SVM、决策树、随机森林、朴素贝叶斯和K近邻算法训练二元分类(正常/异常)模型及预测,最后比较了各个算法的检测效果。
实现步骤
- 加载和导入数据:
- 导入所需的Python库,如numpy、pandas、matplotlib等,以及sklearn中的各种机器学习算法和评估指标。
- 读取KDDTrain+.txt和KDDTest+.txt文件作为训练集和测试集,并给数据列添加对应的标签。
- 数据预处理:
- 检查并打印训练集和测试集中重复的数据行数。
- 将攻击类别转化为二元分类:‘normal’ 和 ‘abnormal’,并将原始攻击类别列删除。
- 对分类特征(如protocol_type, service, flag)进行标签编码。
- 特征选择:
- 使用mutual_info_classif方法计算特征与目标变量之间的互信息,并根据结果选择最重要的20个特征。
-
数据标准化:
选定筛选后的特征子集后,对训练集和测试集的特征进行标准化处理,使用MinMaxScaler将所有特征缩放到[0, 1]区间内。 -
模型初始化与训练:
- 初始化多种分类模型,包括逻辑回归、支持向量机(线性核、多项式核、高斯核)、决策树、随机森林、朴素贝叶斯和K近邻。
- 对每个模型进行训练,使用训练好的模型在测试集上进行预测。
- 性能评估:
- 计算并存储每个模型在测试集上的准确率、精确度和召回率。
实现代码
导入必要的库和数据
# 导入和加载数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split,StratifiedKFold,GridSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier,VotingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import GridSearchCV,RandomizedSearchCV
from sklearn.svm import SVC
from sklearn import metrics
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import make_scorer, roc_auc_score
import scipy
from scipy import stats
import warnings
warnings.filterwarnings("ignore")
from sklearn.preprocessing import StandardScaler
# 设置列标签
columns = (['duration'
,'protocol_type'
,'service'
,'flag'
,'src_bytes'
,'dst_bytes'
,'land'
,'wrong_fragment'
,'urgent'
,'hot'
,'num_failed_logins'
,'logged_in'
,'num_compromised'
,'root_shell'
,'su_attempted'
,'num_root'
,'num_file_creations'
,'num_shells'
,'num_access_files'
,'num_outbound_cmds'
,'is_host_login'
,'is_guest_login'
,'count'
,'srv_count'
,'serror_rate'
,'srv_serror_rate'
,'rerror_rate'
,'srv_rerror_rate'
,'same_srv_rate'
,'diff_srv_rate'
,'srv_diff_host_rate'
,'dst_host_count'
,'dst_host_srv_count'
,'dst_host_same_srv_rate'
,'dst_host_diff_srv_rate'
,'dst_host_same_src_port_rate'
,'dst_host_srv_diff_host_rate'
,'dst_host_serror_rate'
,'dst_host_srv_serror_rate'
,'dst_host_rerror_rate'
,'dst_host_srv_rerror_rate'
,'attack'
,'level'])
# 从文件中读取训练集和测试集
df_train=pd.read_csv('../input/nslkdd/KDDTrain+.txt',header=None,names=columns)
df_test=pd.read_csv('../input/nslkdd/KDDTest+.txt',header=None,names=columns)
数据内容如下所示:
| duration | protocol_type | service | flag | src_bytes | dst_bytes | land | wrong_fragment | urgent | hot | ... | dst_host_same_srv_rate | dst_host_diff_srv_rate | dst_host_same_src_port_rate | dst_host_srv_diff_host_rate | dst_host_serror_rate | dst_host_srv_serror_rate | dst_host_rerror_rate | dst_host_srv_rerror_rate | attack | level | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | tcp | ftp_data | SF | 491 | 0 | 0 | 0 | 0 | 0 | ... | 0.17 | 0.03 | 0.17 | 0.00 | 0.00 | 0.00 | 0.05 | 0.00 | normal | 20 |
| 1 | 0 | udp | other | SF | 146 | 0 | 0 | 0 | 0 | 0 | ... | 0.00 | 0.60 | 0.88 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | normal | 15 |
| 2 | 0 | tcp | private | S0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0.10 | 0.05 | 0.00 | 0.00 | 1.00 | 1.00 | 0.00 | 0.00 | neptune | 19 |
| 3 | 0 | tcp | http | SF | 232 | 8153 | 0 | 0 | 0 | 0 | ... | 1.00 | 0.00 | 0.03 | 0.04 | 0.03 | 0.01 | 0.00 | 0.01 | normal | 21 |
| 4 | 0 | tcp | http | SF | 199 | 420 | 0 | 0 | 0 | 0 | ... | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | normal | 21 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 125968 | 0 | tcp | private | S0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0.10 | 0.06 | 0.00 | 0.00 | 1.00 | 1.00 | 0.00 | 0.00 | neptune | 20 |
| 125969 | 8 | udp | private | SF | 105 | 145 | 0 | 0 | 0 | 0 | ... | 0.96 | 0.01 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | normal | 21 |
| 125970 | 0 | tcp | smtp | SF | 2231 | 384 | 0 | 0 | 0 | 0 | ... | 0.12 | 0.06 | 0.00 | 0.00 | 0.72 | 0.00 | 0.01 | 0.00 | normal | 18 |
| 125971 | 0 | tcp | klogin | S0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0.03 | 0.05 | 0.00 | 0.00 | 1.00 | 1.00 | 0.00 | 0.00 | neptune | 20 |
| 125972 | 0 | tcp | ftp_data | SF | 151 | 0 | 0 | 0 | 0 | 0 | ... | 0.30 | 0.03 | 0.30 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | normal | 21 |
125973 rows × 43 columns
数据格式如下所示: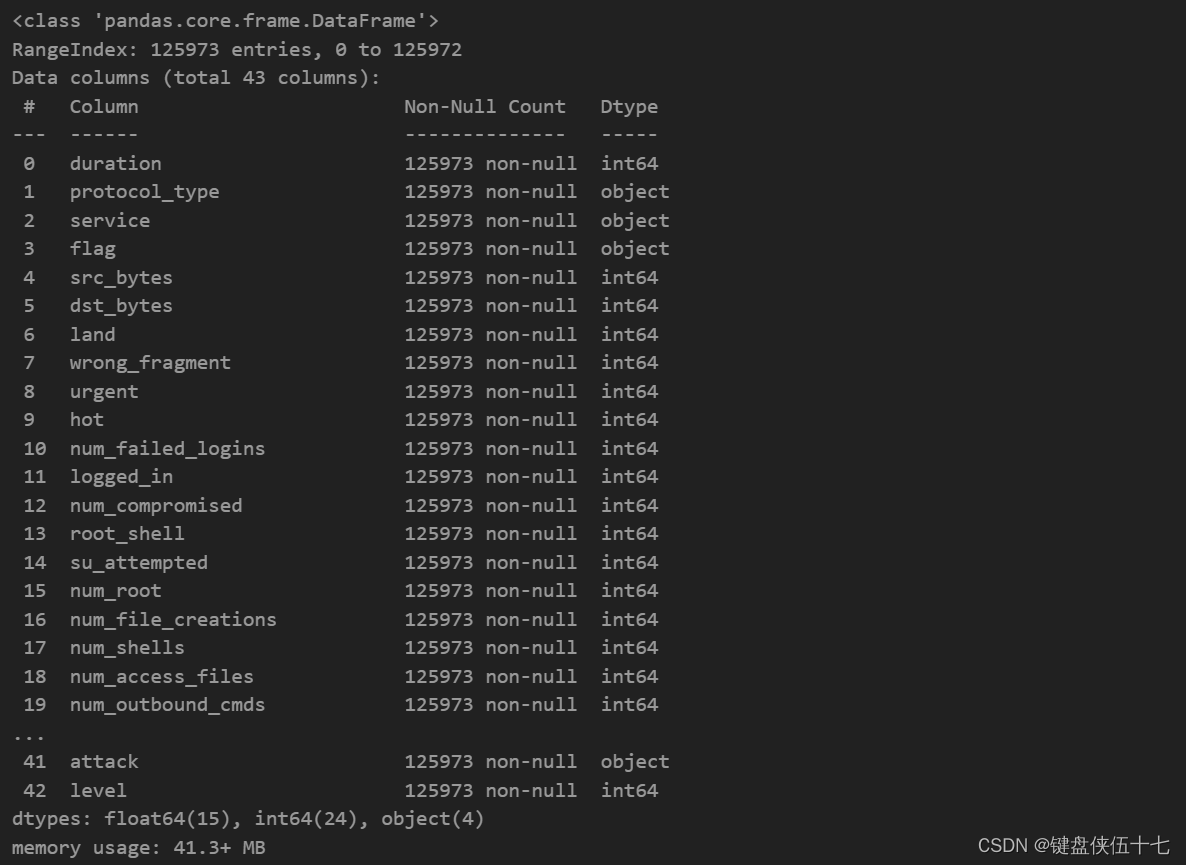
检查训练集和测试集中重复数据的数量。
# 检查并打印训练集中重复数据的数量
print(df_train.duplicated().sum())
# 检查并打印测试集中重复数据的数量
print(df_test.duplicated().sum())
0
0
计算DataFrame中每个列的空值数量
df_train.isnull().sum()
检查异常值
绘制所有列的箱线图以查看异常值
# 绘制箱线图
df_train.plot(kind='box', subplots=1, layout=(15, 3), figsize=(20, 40))
plt.show()

计算并返回训练数据集中‘attack’列中各标签的出现次数
df_train['attack'].value_counts()
用于计算数据框 df_train 中指定列 ‘attack’ 中不同值的出现次数,并以降序排列。这里没有参数传递,函数直接返回一个 Series 对象,其中包含各标签的计数。这个操作对于了解数据的分布非常有用,特别是当需要了解数据集中各类攻击的相对频率时。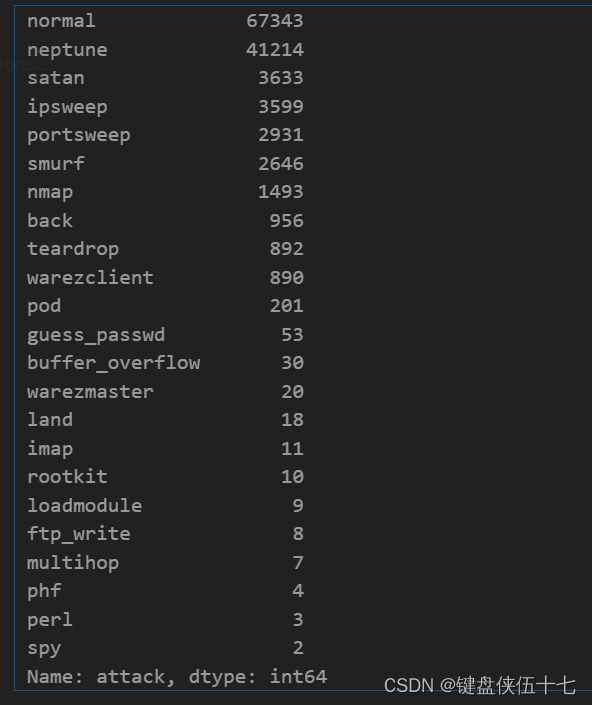
将数据集中的异常类别转换为单一的异常类
该代码块主要对训练集和测试集进行处理,将原始攻击类别转化为二元分类:
正常(normal)和异常(abnormal)。这有助于简化后续的模型训练和评估过程。
# 将训练集中的攻击类别转化为二元分类
df_train["binary_attack"]=df_train.attack.map(lambda a: "normal" if a == 'normal' else "abnormal")
# 删除原始的攻击类别列
df_train.drop('attack',axis=1,inplace=True)
# 将测试集中的攻击类别转化为二元分类
df_test["binary_attack"]=df_test.attack.map(lambda a: "normal" if a == 'normal' else "abnormal")
# 删除测试集中的原始攻击类别列
df_test.drop('attack',axis=1,inplace=True)
df_train.select_dtypes(['object']).columns
Index([‘protocol_type’, ‘service’, ‘flag’, ‘binary_attack’], dtype=‘object’)
数据编码
该代码块主要功能是对给定的数据集的几个指定列进行标签编码。
使用的是sklearn库中的preprocessing模块的LabelEncoder类。
from sklearn import preprocessing
le=preprocessing.LabelEncoder() # 创建标签编码器实例
clm=['protocol_type', 'service', 'flag', 'binary_attack'] # 需要进行标签编码的列名列表
for x in clm: # 遍历列名列表
df_train[x]=le.fit_transform(df_train[x]) # 对训练数据集的指定列进行标签编码
df_test[x]=le.fit_transform(df_test[x]) # 对测试数据集的指定列进行标签编码
数据分割
对输入的数据集进行处理,分割为训练集和测试集的特征和标签。
主要步骤包括:
- 从训练集数据框(df_train)中去除标签列(‘binary_attack’),保留其余特征列,得到训练集的特征(x_train);
- 从训练集数据框(df_train)中提取标签列(‘binary_attack’),得到训练集的标签(y_train);
- 从测试集数据框(df_test)中去除标签列(‘binary_attack’),保留其余特征列,得到测试集的特征(x_test);
- 从测试集数据框(df_test)中提取标签列(‘binary_attack’),得到测试集的标签(y_test)。
# 分割训练集的特征和标签
x_train=df_train.drop('binary_attack',axis=1)
y_train=df_train["binary_attack"]
# 分割测试集的特征和标签
x_test=df_test.drop('binary_attack',axis=1)
y_test=df_test["binary_attack"]
特征工程
计算特征与目标变量之间的互信息。
:param x_train: 训练集的特征矩阵,其中每一列是一个特征。
:param y_train: 训练集的目标变量向量。
from sklearn.feature_selection import mutual_info_classif
# 使用mutual_info_classif计算特征与目标变量的互信息
mutual_info = mutual_info_classif(x_train, y_train)
# 将计算结果转换为pandas Series,方便后续处理
mutual_info = pd.Series(mutual_info)
# 设置Series的索引为特征名,这样可以方便地与特征矩阵相对应
mutual_info.index = x_train.columns
# 按照互信息值降序排序,使得最重要的特征排在前面
mutual_info.sort_values(ascending=False)
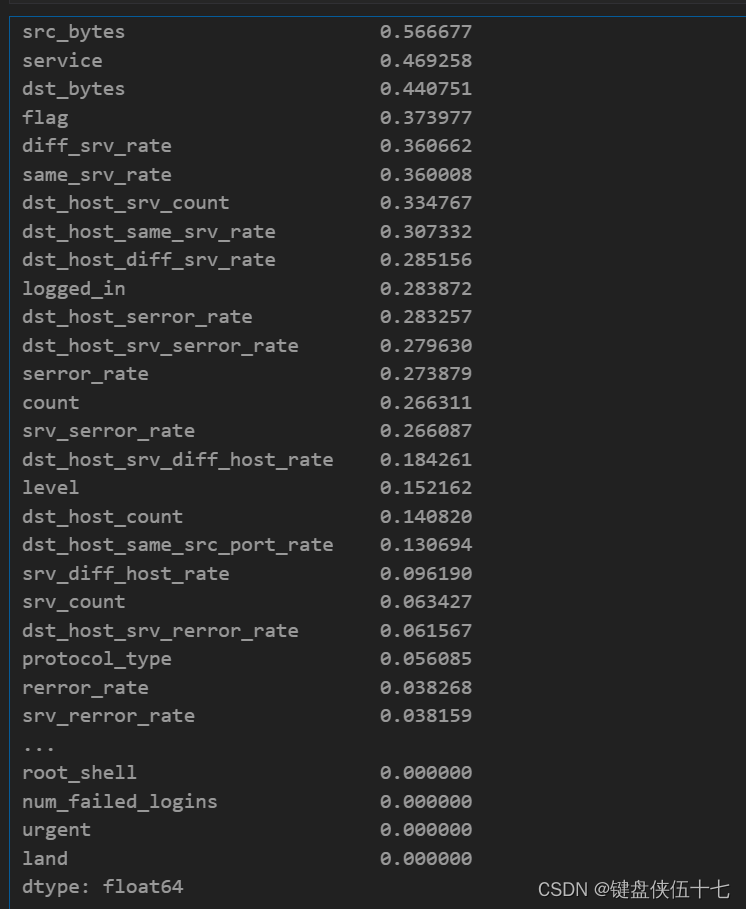
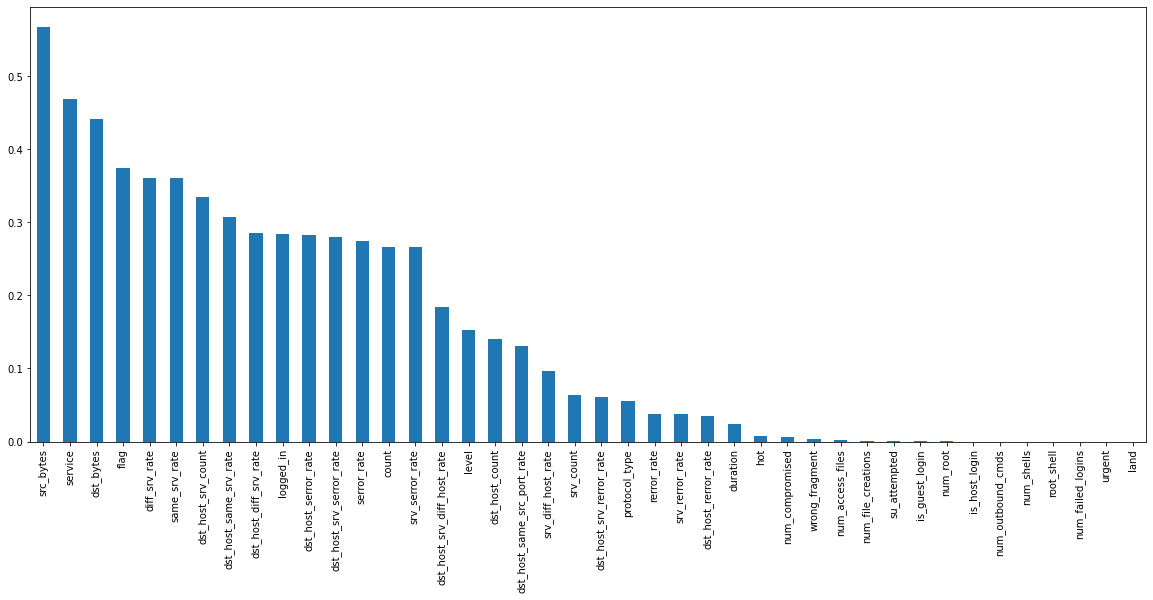
绘制相互信息的柱状图
对名为mutual_info的数据结构(假设为DataFrame)按值进行降序排序,
然后使用bar方法绘制柱状图。figsize(图形大小)参数设置为(20, 8),以确保图形足够大,
便于细节查看和展示。该图形可用于展示不同变量间的相互信息量,帮助分析者理解变量间的关联程度。
mutual_info.sort_values(ascending=False).plot.bar(figsize=(20, 8));
# 选择最重要的20个特征进行筛选
from sklearn.feature_selection import SelectKBest
# 使用mutual_info_classif方法评估特征重要性,选择最重要的20个特征
sel_five_cols = SelectKBest(mutual_info_classif, k=20)
# 对训练数据进行特征选择
sel_five_cols.fit(x_train, y_train)
# 获取选择出的特征的列名
x_train.columns[sel_five_cols.get_support()]
Index([‘service’, ‘flag’, ‘src_bytes’, ‘dst_bytes’, ‘logged_in’, ‘count’,
‘serror_rate’, ‘srv_serror_rate’, ‘same_srv_rate’, ‘diff_srv_rate’,
‘srv_diff_host_rate’, ‘dst_host_count’, ‘dst_host_srv_count’,
‘dst_host_same_srv_rate’, ‘dst_host_diff_srv_rate’,
‘dst_host_same_src_port_rate’, ‘dst_host_srv_diff_host_rate’,
‘dst_host_serror_rate’, ‘dst_host_srv_serror_rate’, ‘level’],
dtype=‘object’)
为了确保训练集和测试集在进行模型训练和评估前,其特征维度和类型保持一致,只包含对模型有意义或者相关的特征,从而提高模型的准确性和泛化能力。
# 将训练集和测试集的数据调整为只包含指定的列
col=['service', 'flag', 'src_bytes', 'dst_bytes', 'logged_in',
'same_srv_rate', 'diff_srv_rate', 'dst_host_srv_count',
'dst_host_same_srv_rate', 'dst_host_diff_srv_rate']
# 调整训练集特征矩阵,仅包含指定的列
x_train=x_train[col]
# 调整测试集特征矩阵,也仅包含指定的列
x_test=x_test[col]
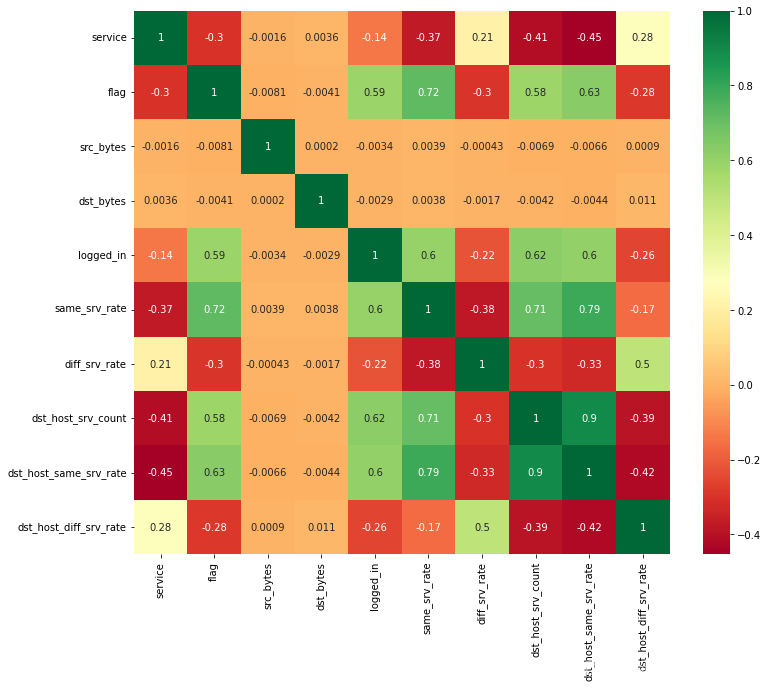
生成并显示一个热力图,用于可视化x_train数据集的协方差矩阵。
# 创建一个新的图形窗口,设置其宽度和高度
plt.figure(figsize=(12,10))
# 生成热力图,显示元素值,使用'RdYlGn'颜色映射
p=sns.heatmap(x_train.corr(), annot=True, cmap='RdYlGn')
数据缩放
对机器学习模型的输入数据(训练集和测试集)进行标准化处理,使得数据的范围在0到1之间,以提升模型的性能和稳定性。
# 导入MinMaxScaler类,用于数据的标准化处理
from sklearn.preprocessing import MinMaxScaler
# 实例化MinMaxScaler对象,用于后续的数据转换
scaler = MinMaxScaler()
# 对训练集数据进行标准化处理,转换后的数据范围在[0, 1]之间
x_train = scaler.fit_transform(x_train)
# 对测试集数据进行标准化处理,同样的转换确保训练集和测试集的特征缩放一致
x_test = scaler.fit_transform(x_test)
二元分类模型训练及预测
# 初始化各种模型并将它们以名称为键存储在一个字典中
models = {}
# 初始化逻辑回归模型
from sklearn.linear_model import LogisticRegression
models['Logistic Regression'] = LogisticRegression()
# 初始化线性支持向量机模型
from sklearn.svm import LinearSVC
models['Support Vector Machines linear'] = LinearSVC()
# 初始化多项式核支持向量机模型
models['Support Vector Machines plonomial'] = SVC(kernel='poly')
# 初始化高斯核支持向量机模型,通过调整C参数来避免过拟合
models['Support Vector Machines RBf'] = SVC(C=100.0)
# 初始化决策树模型,限制树的最大深度为3
from sklearn.tree import DecisionTreeClassifier
models['Decision Trees'] = DecisionTreeClassifier(max_depth=3)
# 初始化随机森林模型
from sklearn.ensemble import RandomForestClassifier
models['Random Forest'] = RandomForestClassifier()
# 初始化朴素贝叶斯模型
from sklearn.naive_bayes import GaussianNB
models['Naive Bayes'] = GaussianNB()
# 初始化K最近邻模型,选择20个最近邻点
from sklearn.neighbors import KNeighborsClassifier
models['K-Nearest Neighbor'] = KNeighborsClassifier(n_neighbors=20)
根据提供的模型集合,分别训练每个模型,作出预测,并计算与存储各个模型的准确度、精确度和召回率。
使用的指标来自sklearn.metrics模块,包括:accuracy_score(准确率)、precision_score(精确度)、recall_score(召回率)。
三个字典accuracy、precision、recall用于存储每个模型对应的指标结果。
from sklearn.metrics import accuracy_score, precision_score, recall_score
accuracy, precision, recall = {}, {}, {}
for key in models.keys():
# 对当前循环到的模型进行训练
models[key].fit(x_train, y_train)
# 使用训练好的模型对测试集进行预测
predictions = models[key].predict(x_test)
# 计算并存储当前模型的准确率、精确度和召回率
accuracy[key] = accuracy_score(predictions, y_test)
precision[key] = precision_score(predictions, y_test)
recall[key] = recall_score(predictions, y_test)
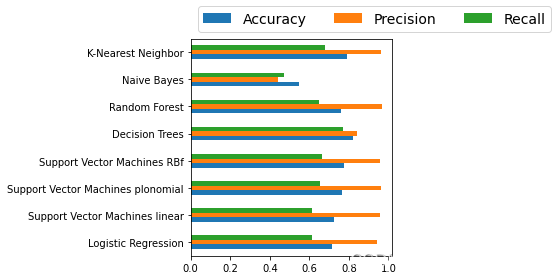
根据提供的模型准确度、精确度和召回率生成一个DataFrame
df_model = pd.DataFrame(index=models.keys(), columns=['Accuracy', 'Precision', 'Recall'])
# 初始化DataFrame,设置索引为模型名称,列名为Accuracy, Precision, Recall
df_model['Accuracy'] = accuracy.values()
# 将accuracy字典的值赋给DataFrame的Accuracy列
df_model['Precision'] = precision.values()
# 将precision字典的值赋给DataFrame的Precision列
df_model['Recall'] = recall.values()
# 将recall字典的值赋给DataFrame的Recall列
df_model
# 输出生成的DataFrame
| Accuracy | Precision | Recall | |
|---|---|---|---|
| Logistic Regression | 0.717042 | 0.943569 | 0.611111 |
| Support Vector Machines linear | 0.723873 | 0.955617 | 0.615630 |
| Support Vector Machines plonomial | 0.764372 | 0.962723 | 0.653822 |
| Support Vector Machines RBf | 0.772933 | 0.957368 | 0.663977 |
| Decision Trees | 0.823013 | 0.840902 | 0.769579 |
| Random Forest | 0.762287 | 0.969622 | 0.650276 |
| Naive Bayes | 0.546265 | 0.440634 | 0.471463 |
| K-Nearest Neighbor | 0.788946 | 0.962002 | 0.680358 |
使用条形图可视化模型数据。
# 绘制条形图
ax = df_model.plot.barh()
# 设置图例
ax.legend(
ncol=len(models.keys()), # 根据模型数量确定图例列数
bbox_to_anchor=(0, 1), # 将图例位置设置在绘图区右上角
loc='lower left', # 位置细节调整,将图例放置在左下角
prop={'size': 14} # 设置图例文字大小
)
# 调整布局,确保图表各部分之间没有空隙
plt.tight_layout()
遍历所有模型并绘制ROC曲线
from sklearn.metrics import plot_roc_curve
# 遍历所有模型并绘制ROC曲线
for key in models.keys():
plot_roc_curve( models[key], x_test, y_test)
"""
plot_roc_curve函数用于绘制ROC(受试者操作特性)曲线。
参数:
models[key]:表示模型,从字典models中通过key获取对应的模型。
x_test:测试集的特征向量。
y_test:测试集的真实标签。
返回值:
无返回值,直接在图形窗口中绘制ROC曲线。
"""
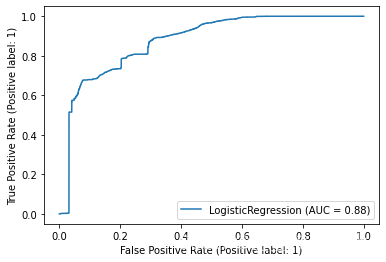
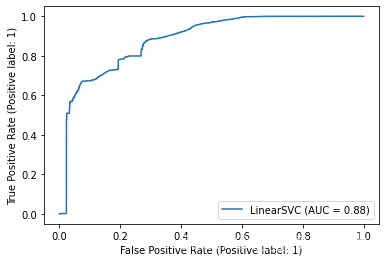
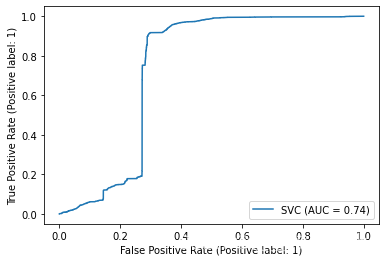
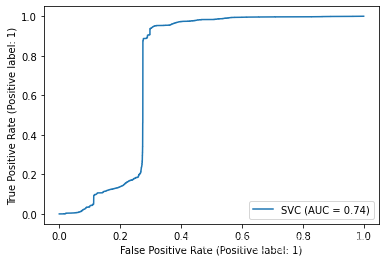
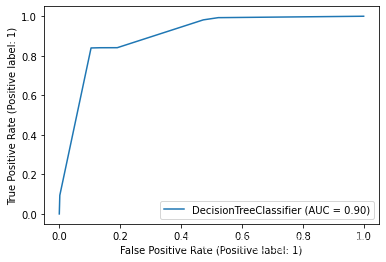
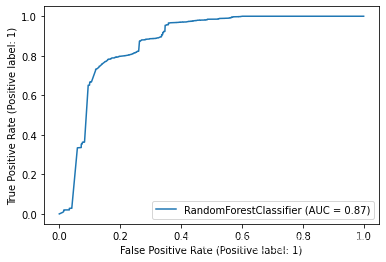
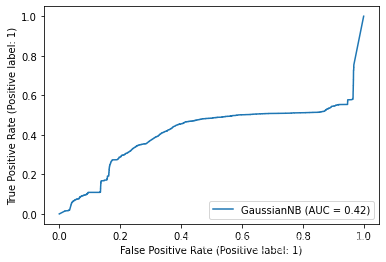
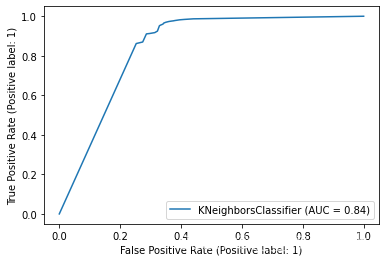
不难得出,随机森林和决策树分类器对于NSL-KDD数据集来说有较好的分类效果。
优化建议
- 平衡数据处理:
- NSL-KDD数据集中各类别的样本分布可能存在不均衡情况,应考虑使用欠采样、过采样或SMOTE等方法来平衡正负样本。
- 特征工程改进:
- 除了基于互信息的选择外,可以尝试其他特征选择方法,例如递归特征消除(RFE)、基于卡方检验的选择等,以及探索更高阶的交互特征。
- 可以进一步研究数据集中的特征关联性和冗余性,减少共线性特征的影响。
- 模型调优:
- 对于每个模型,通过GridSearchCV或RandomizedSearchCV进行参数网格搜索,寻找最优超参数组合,提高模型性能。
- 考虑集成学习方法,比如AdaBoost、BaggingClassifier或者StackingClassifier,结合多个基础模型提升整体表现。
- 评估指标:
- 由于这是一个二分类问题且可能涉及类不平衡,仅依赖准确率评价模型效果可能不够全面。应引入F1分数、AUC-ROC曲线等相关指标进行综合评估。
- 模型解释性:
- 引入模型可解释性技术,例如SHAP值、LIME等,帮助理解模型在各个特征上的重要性,以及为何做出特定预测,增加系统的透明度和可信度。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 33
33 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)