
RK3568 AI模型部署笔记
使用正点原子的RK3568开发板进行深度学习开发和部署。
RK3568 AI模型部署笔记
前言
使用正点原子的RK3568开发板进行深度学习开发和部署。主要参考正点原子资料和RK官方资料。
一、AI训练-部署-硬件三者关系

每个硬件平台都有自己的一套部署框架,这些部署框架可以借助模型转换工具,将不同的训练框架模型转换成可以在自己的部署框架和硬件平台上运行的模型。
例如在Rockchip(RK)的硬件平台下,其可以使用rknn-toolkit(2)进行模型转换,得到RKNN框架模型,最后在开发板中使用rknn-toolkit-lite(2)和rknpu(2)进行实现。如下所示。
不同版本的模型转换器rknn-toolkit可以转换的AI训练框架不同,要注意版本匹配。
二、RKNN-toolkit2文件介绍
目前最新版本为RKNN-Toolkit2 2.3.0版,以此版本进行介绍。地址:https://github.com/airockchip/rknn-toolkit2
2.1 文件内容介绍

RKNN-Toolkit2 2.3.0文件内容如下:
autosparsity:一个软件包,支持PyTorch模型的稀疏训练和推理。
doc:doc下是RKNN Toolkit2的手册
res:存放一下照片png
rknn-toolkit2:模型转换工具,里面有rknn-toolkit2的一些不同版本安装环境和例程,支持python3.6-3.12,有x86版本和ARM64版本
rknn-toolkit2-lite2:提供python接口,用于部署RKNN模型,里面有例程和安装环境,支持python3.7-3.12,安装在开发板中
rknpu2:里面有例程和runtime, Runtime 为 Rockchip NPU 平台提供 C/C++ 编程接口,帮助用户部署 RKNN 模型。安装在开发板中
2.2 安装RKNN-toolkit2
可以去doc文件夹中查看文档,很详细,强烈推荐,可以结合正点原子的 RK3568 AI 例程测试手册。《02_Rockchip_RKNPU_User_Guide_RKNN_SDK_V2.3.0_CN》中介绍的是linux安装方法,本人是在VMWare下安装的Ubuntu,VMWare是不支持CUDA相关驱动,只能使用CPU版本的TensorFlow、 PyTorch和mxnet。我按照步骤安装的是GPU版本,但使用时会自动使用cpu。
①创建一个python3.8的conda虚拟环境,py3.8是官方推荐的
②进入虚拟环境,安装依赖包,我是py3.8,使用cp38,使用国内源清华源。
③安装 RKNN-Toolkit2,我选择的是cp38,一定要检验whl文件的MD5验证码。建议使用国内源。

之前MD5出错,安装失败,然后MD5验证无误后重新下载,不清楚为啥,说已经安装了rknn-toolkit2,所以我强制重新安装。使用国内源。
python中导入无误。但是GPU版本的torch无法使用,如下: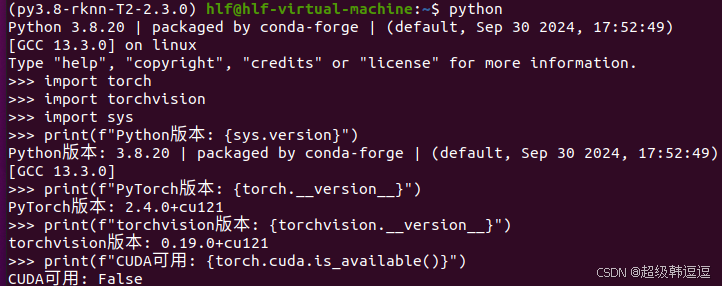
且这个2.3.0版本差了很多库没有安装,tensorflow,torchvision等不在requirements文件中,需自己下载。导致无法运行examples文件中的示例。为了确定rknn-toolkit2可以在Ubuntu上运行,需要运行实例。
选择一个pytorch实例resnet18
(py3.8-rknn-T2-2.3.0) hlf@hlf-virtual-machine:~/rknn-toolkit2-2.3.0/rknn-toolkit2/examples/pytorch/resnet18$ ls
dataset.txt labels.txt model_config.yml README.md space_shuttle_224.jpg test.py
由README.md 可知,需要从torchvision中导入resnet18模型,torch2.4.0对应的是torchvision0.19.0,因为只能使用cpu,所以没有指定cuda版本,但我下载了GPU版本的torch,应该默认下载GPU版本的torchvision ,pip下载如下:
pip install torchvision==0.19.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
还需要从官网下载resnet18模型,很慢,我直接取消了,科学上网下载到windows,然后ftp到指定目录:~/.cache/torch/hub/checkpoints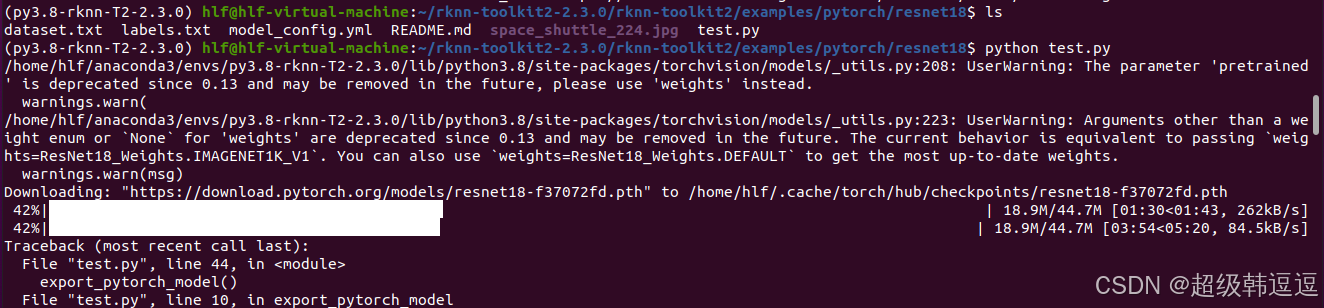
再次运行,如下:
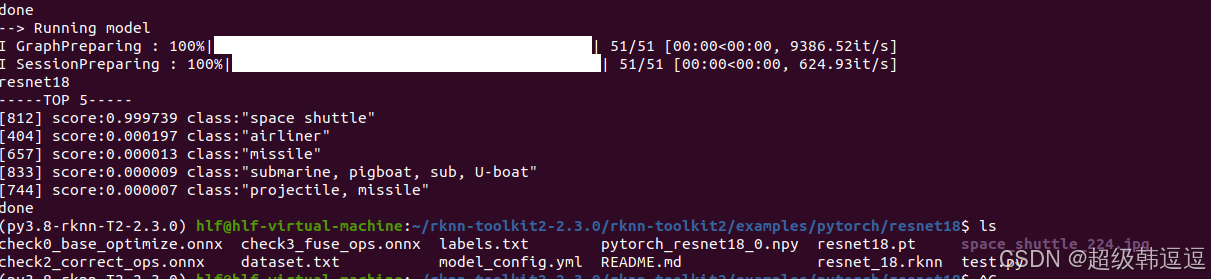
可以看到预测成功了,而且resnet18文件夹中多了一些onnx、rknn文件。
2.3开发板端RKNPU环境
rknn-toolkit2文件中的rknpu2文件夹中有配套的rknpu,最好使用同一套(同一版本)的rknn-toolkit2、rknn-toolkit2和rknpu2。
2.3.1 NPU驱动版本确认
root@ATK-DLRK3568:/# cat /sys/kernel/debug/rknpu/version
RKNPU driver: v0.8.2
官方建议RKNPU驱动版本>=0.9.2。 在 rknn-llm/doc/Rockchip_RKLLM_SDK_CN_1.1.4.pdf中有提到驱动更新,但是内核需要是5.10或6.1.
2.3.2 NPU连板环境
RKNN-Toolkit2 的连板调试功能要求板端已安装 RKNPU2 环境,并且启动 RKNN Server 服务。以下是RKNPU2 环境中的2个基本概念:
- RKNN Server:一个运行在开发板上的后台代理服务,用于接收PC通过 USB 传输过来的数据,然后执行板端 Runtime 对应的接口,并返回结果给 PC。
- RKNPU2 Runtime 库
librknnrt.so: 是用于 RK3562 / RK3566 / RK3568 / RK3576 / RK3588 板端的 Runtime 库。
librknnmrt.so: 是用于 RV1103 / RV1103B / RV1106 / RV1106B板端的 Runtime 库。
如果板端没有安装 RKNN Server, Runtime 库不存在,或者 RKNN Server 和 Runtime 库的版本不一致,都需要重新安装或更新。
root@ATK-DLRK3568:/# strings /usr/bin/rknn_server | grep -i "rknn_server version"
rknn_server version: 2.3.0 (e80ac5c build@2024-11-07T12:52:53)
root@ATK-DLRK3568:/# strings /usr/lib/librknnrt.so | grep -i "librknnrt version"
librknnrt version: 1.5.0 (e6fe0c678@2023-05-25T08:09:20)
rknn_server 是 2.3.0,librknnrt.so 是1.5.0 不一致,要更新。
adb连接:
官方linux流程如下: Runtime 为 Rockchip NPU 平台提供 C/C++ 编程接口
root@ATK-DLRK3568:/# strings /usr/bin/rknn_server | grep -i "rknn_server version"
rknn_server version: 2.3.0 (e80ac5c build@2024-11-07T12:52:53)
root@ATK-DLRK3568:/# strings /usr/lib/librknnrt.so | grep -i "librknnrt version"
librknnrt version: 2.3.0 (c949ad889d@2024-11-07T11:35:33)
这样保证 RKNN Server 、 Runtime 库的版本、 RKNN-Toolkit2 的版本是一致的,都是2.3.0版本。
2.3.3 交叉编译器中的NPU驱动
安装正点原子的AI测试手册下载正点原子的交叉编译器,可以看到,其里面也有相关软件包。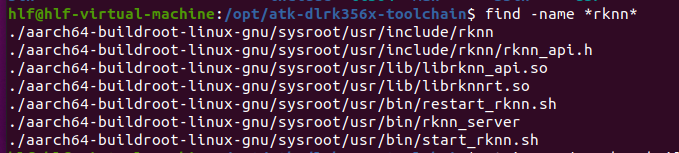
但是其版本低了-1.3.0版,而开发板上是2.3.0版本,这里应该需要更新,从开发板更新到ubunut的交叉编译器文件中,adb pull命令。
2.4 安装rknn-toolkit-lite2
正点原子的 rk3568 的 linux 系统出厂系统的根文件系统是 buildroot 构建的, 所以对Python 的支持没那么好, 不过正点原子对 python 推理的主要相关库做了适配.需要用到的文件都在rknn-toolkit-lite2文件夹中。
rknn-toolkit-lite2支持python3.7-3.12
root@ATK-DLRK3568:/userdata# python --version
Python 3.8.6
开发板是py3.8,所以安装cp38.whl,如下: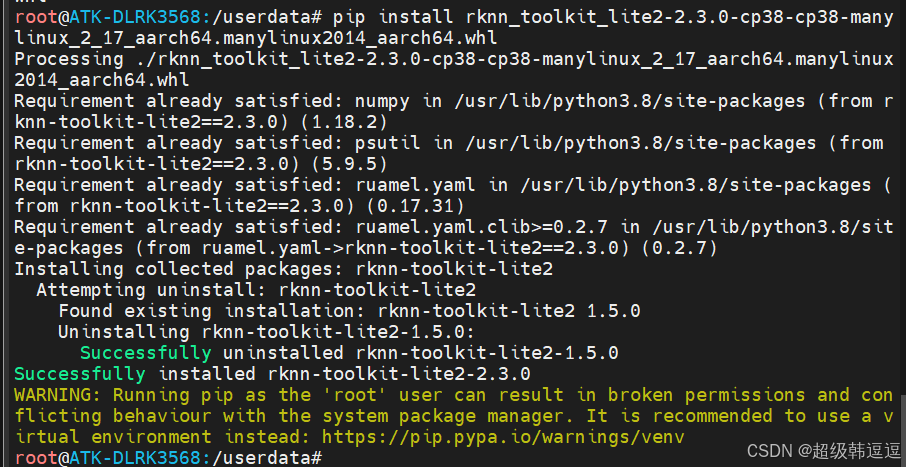
将resent18例程拷贝到开发板
结果如下:
root@ATK-DLRK3568:/userdata# cd resnet18/
root@ATK-DLRK3568:/userdata/resnet18# ls
README.md resnet18_for_rk3576.rknn synset_label.py
resnet18_for_rk3562.rknn resnet18_for_rk3588.rknn test.py
resnet18_for_rk3566_rk3568.rknn space_shuttle_224.jpg
root@ATK-DLRK3568:/userdata/resnet18# python test.py
W rknn-toolkit-lite2 version: 2.3.0
--> Load RKNN model
done
--> Init runtime environment
I RKNN: [14:47:23.279] RKNN Runtime Information, librknnrt version: 2.3.0 (c949ad889d@2024-11-07T11:35:33)
I RKNN: [14:47:23.280] RKNN Driver Information, version: 0.8.2
I RKNN: [14:47:23.280] RKNN Model Information, version: 6, toolkit version: 2.3.0(compiler version: 2.3.0 (c949ad889d@2024-11-07T11:39:30)), target: RKNPU lite, target platform: rk3566, framework name: PyTorch, framework layout: NCHW, model inference type: static_shape
W RKNN: [14:47:23.309] query RKNN_QUERY_INPUT_DYNAMIC_RANGE error, rknn model is static shape type, please export rknn with dynamic_shapes
W Query dynamic range failed. Ret code: RKNN_ERR_MODEL_INVALID. (If it is a static shape RKNN model, please ignore the above warning message.)
done
--> Running model
resnet18
-----TOP 5-----
[812] score:0.999680 class:"space shuttle"
[404] score:0.000249 class:"airliner"
[657] score:0.000013 class:"missile"
[466] score:0.000009 class:"bullet train, bullet"
[895] score:0.000008 class:"warplane, military plane"
done
使用space_shuttle_224.jpg,得到结果是 score:0.999680 class:“space shuttle”,结果正确。
三、深度学习训练环境
我是在windows使用GPU进行模型训练,在Ubuntu中使用rknn-toolkit2进行模型转换。所以需要在Windows下安装anaconda和torch等包。我只要是使用pytorch,以此为例。rk官方建议模型训练环境和模型转换环境中使用的资源包的版本要一致,rknn-toolkit2的环境如下: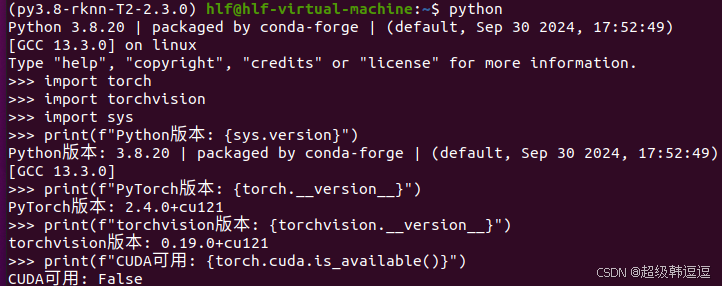
3.1 安装Anaconda
比较简单
3.2 查看NVIDIA驱动
驱动决定cuda的最高版本,可能需要更新NVIDIA驱动
3.3 安装pytorch环境
要在conda中新建虚拟环境,为了与模型转换环境一致,故指定为py3.8,torch2.4.0,cu12.1,torchvision0.19.0
去pytorch官网查看版本下载方式:https://pytorch.org/get-started/previous-versions/
pip下载如下:
# CUDA 12.1
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu121
torch = =2.4.0 torchvision==0.19.0 torchaudio= =2.4.0是版本号
https://download.pytorch.org/whl/cu121 中的cu121代表cuda12.1
–index-url https://download.pytorch.org/whl/cu121 代表去pytorch官网下载,比较慢
可以科学上网,直接下载whl文件,如下: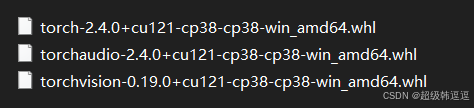
pip install /path/to/文件名.whl
使用上面的命令安装后,测试pytorch-gpu,如下,深度学习GPU很重要,1050不太行。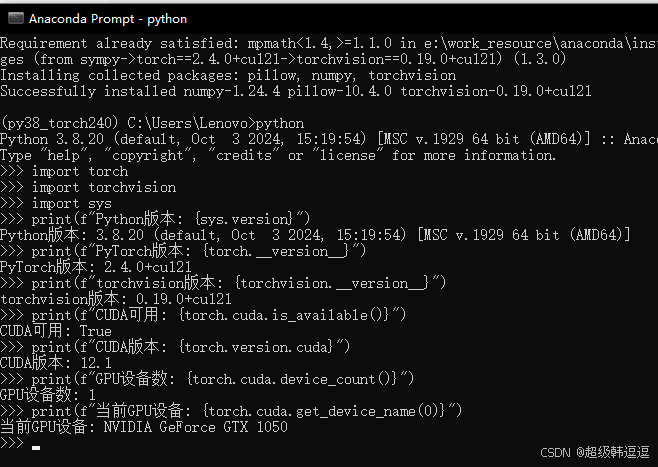
四、模型训练
以正点原子提供的yolov5-7.0为例,在Windows下的GPU-torch环境进行训练。
powershell命令:
PS xx\7-测试PyTorch-GPU1.13.0\yolov5-7.0-mytest1\yolov5-7.0> python train.py --data coco128.yaml --weights [string]::Empty --cfg yolov5s.yaml --img 640 --epoch 1
报错:ImportError: Bad git executable.
因为没有下载git,直接在windows下下载git即可,不需要在conda虚拟环境中下载。
报错:‘FreeTypeFont’ object has no attribute ‘getsize’
该错误是由于 Pillow 库版本升级后移除了 getsize() 方法,我的pillow是10.4.0,所以需要修改yolo5的代码
将91行代码替换后无误。
w, h = font.getsize(text)
↓ 替换
self.font = ImageFont.load_default()
left, top, right, bottom = self.font.getbbox(label) # 返回 (left, top, right, bottom)
w, h = right - left, bottom - top # 计算宽度和高度
保存.pt/ .pth文件看6.8 TorchScript格式的PyTorch模型文件(.pt/pth)
五、模型部署
使用RK官方提供的rknn_model_zoo软件包,介绍如何快速上手模型转换、模型连板运行、模型评估和模型板端部署,具体的代码本章节没有分析。
5.1 模型转换+推理
阅读README.MD可知,需要下载mobilenetv2-12.onnx 到指定位置。
然后执行命令如下,执行命令有使用说明,参数默认值可以在mobilenet.py 的parser.parse_args()查看和更改。
python mobilenet.py --model ../model/mobilenetv2-12.onnx --target rk3568
生成mobilenet_v2.rknn 文件。执行该命令后模型是在电脑模拟器上进行推理,因为–npu_device_test 的 default=False
//mobilenet.py
parser.add_argument('--npu_device_test', action='store_true',
default=False, help='Connected npu device run')
//执行代码
ret = rknn.init_runtime()
//输出结果
--> Init runtime environment
I Target is None, use simulator!
......
--> PostProcess
-----TOP 5-----
[494] score=0.98 class="n03017168 chime, bell, gong"
[653] score=0.01 class="n03764736 milk can"
[469] score=0.00 class="n02939185 caldron, cauldron"
[505] score=0.00 class="n03063689 coffeepot"
[463] score=0.00 class="n02909870 bucket, pail"
执行模型连板运行,前提是RKNN-Toolkit2 的连板调试功能要求板端已安装 RKNPU2 环境,并且启动 RKNN Server 服务,开启adb。
python mobilenet.py --model ../model/mobilenetv2-12.onnx --target rk3568 --npu_device_test
//执行代码
ret = rknn.init_runtime(target=args.target)
//输出结果
--> Init runtime environment
adb server version (41) doesn't match this client (40); killing...
* daemon started successfully
adb: unable to connect for root: closed
I target set by user is: rk3568
I Get hardware info: target_platform = rk3568, os = Linux, aarch = aarch64
I Check RK3568 board npu runtime version
I Starting ntp or adb, target is RK3568
I Start adb...
-> PostProcess
-----TOP 5-----
[494] score=0.99 class="n03017168 chime, bell, gong"
[653] score=0.00 class="n03764736 milk can"
[469] score=0.00 class="n02939185 caldron, cauldron"
[505] score=0.00 class="n03063689 coffeepot"
[747] score=0.00 class="n04023962 punching bag, punch bag, punching ball, punchball"
可以看到,两者的结果相同,精度不同。但转换的模型是一致的。
5.2 模型评估
RKNN提供(模拟器和板端)精度评估、耗时评估和内存评估的功能,辅助RKNN模型的优化和部署。
精度评估 --accuracy_analysis
内存评估 --eval_memory
耗时评估 --eval_perf
python mobilenet.py --model ../model/mobilenetv2-12.onnx --target rk3568 --eval_memory --accuracy_analysis --eval_perf
具体是模拟器还是板端,建议去看mobilenet.py中的代码。
5.3 板端部署-c/c++
在rknn_model_zoo工程下的build-linsx.sh 脚本中指定gcc交叉编译器路径,这里的交叉编译器的正点原子的,可以看其AI例程测试手册。
export GCC_COMPILER=/opt/atk-dlrk356x-toolchain/bin/aarch64-buildroot-linux-gnu
执行以下命令,输出相应文件
./build-linux.sh -t rk3568 -a aarch64 -d mobilenet
//结果
-- Installing: /home/hlf/rknn_model_zoo-main/install/rk356x_linux_aarch64/rknn_mobilenet_demo/model/bell.jpg
-- Installing: /home/hlf/rknn_model_zoo-main/install/rk356x_linux_aarch64/rknn_mobilenet_demo/model/synset.txt
-- Installing: /home/hlf/rknn_model_zoo-main/install/rk356x_linux_aarch64/rknn_mobilenet_demo/model/mobilenet_v2.rknn
-- Installing: /home/hlf/rknn_model_zoo-main/install/rk356x_linux_aarch64/rknn_mobilenet_demo/lib/librknnrt.so
-- Installing: /home/hlf/rknn_model_zoo-main/install/rk356x_linux_aarch64/rknn_mobilenet_demo/lib/librga.so
板端操作:
//ubnutu
adb push install/rk356x_linux_aarch64/rknn_mobilenet_demo/ /userdata
//开发板
adb shell
cd /userdata/rknn_mobilenet_demo
export LD_LIBRARY_PATH=./lib
./rknn_mobilenet_demo model/mobilenet-v2.rknn model/bell.jpg
//结果
rknn_run
[494] score=0.993227 class=n03017168 chime, bell, gong
[469] score=0.002560 class=n02939185 caldron, cauldron
[747] score=0.000466 class=n04023962 punching bag, punch bag, punching ball, punchball
[792] score=0.000466 class=n04208210 shovel
[618] score=0.000405 class=n03633091 ladle
5.4 板端部署-python
之前在2.4 安装rknn-toolkit-lite2 中,在开发板中下载了rknn-toolkit-lite2的examples中的resnet18,我们以这个为模板,用python运行mobilenet_v2.rknn。
新建一个/userdata/rknn_mobilenet_lite文件夹,将/userdata/rknn_mobilenet_demo/model下的bell.jpg和mobilenet_v2.rknn cp过来,将/userdata/resnet18中的文件也cp过来,resnet18中rknn文件用不上。
root@ATK-DLRK3568:/userdata/rknn_mobilenet_lite# ls
bell.jpg README.md synset_label.py test.py
mobilenet_v2.rknn space_shuttle_224.jpg synset_label.pyc
因为resnet18和mobilenetv2的数据集是一样的,看/userdata/rknn_mobilenet_demo/model/synset.txt 和synset_label.py 可知。所以 synset_label.py无需修改,需修改test.py,导入的rknn模型要改,space_shuttle_224.jpg 可以直接用,bell.jpg 则需要resize成224x224.
RK3566_RK3568_RKNN_MODEL = 'mobilenet_v2.rknn'
ori_img = cv2.imread('./bell.jpg')
ori_img = cv2.resize(ori_img,(224,224))
运行:
python test.py
//结果
resnet18
-----TOP 5-----
[494] score:0.982004 class:"chime, bell, gong"
[469] score:0.006837 class:"caldron, cauldron"
[442] score:0.001906 class:"bell cote, bell cot"
[653] score:0.001435 class:"milk can"
[744] score:0.001080 class:"projectile, missile"
可以看到,c部署的结果(0.993227)是优于python部署的结果(score:0.982004),应该是buildroot对python的支持不怎么好。
六、模型转换
流程图: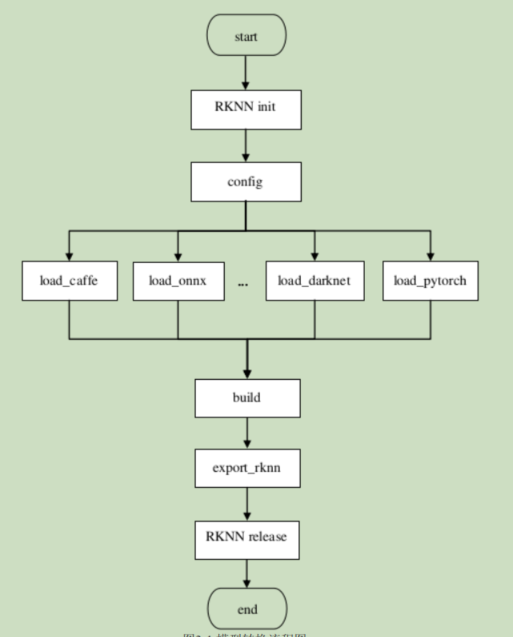
6.1 rknn.config()的标准化参数
在模型转换之前,用户需要进行一些配置以确保模型转换的正确性和性能。配置参数通过 rknn.config() 接口设置。rknn.config()里有两个参数: 均值mean_values和标准差std_values, 这两个参数用于对输入的图片数据进行特征缩放, 使得输入的图片数据位于较小的范围之内。 经过这两个参数特这个缩放后, 新的输入数据:
// 新数据 =(原数据- 均值) / 标准差
标准化的值 = (X - mean_values)/std_values
// 若均值mean_values = 127.5, 标准差std_values = 127.5, 则经过特征缩放后, 输入的数据被归一化到[-1,1]之间, 输入的图片数据, 最小是0, 最大是255, 代入以上计算公式:
标准化的值 = (0 - 127.5)/127.5 = -1
标准化的值 = (255 - 127.5)/127.5 = 1
这里的mean_values和std_values不是随便设置的,要与模型训练时的预处理操作一致。
一般原则:
一般模型在训练的时候, 输入的数据进行了什么预处理, 在模型推理的时候, 也要对输入的数据进行什么样的预处理, 训练和推理的数据要保持一致, 如: RGB通道排序、 标准化/归一化范围、 数据矩阵表示(是NHWC还是NCHW) 等等, 要尽量保持一致, 否则, 可能会影响模型推理的准确度。更多细节参考《03_Rockchip_RKNPU_API_Reference_RKNN_Toolkit2_V2.3.0_CN》的2.2 模型配置。
rknn.config(mean_values=[123.675, 116.28, 103.53],
std_values=[58.395, 58.395, 58.395],
target_platform='rk3568')
mean_values和std_values的选择看6.6
6.2 标准化
标准化通常是指将特征数据缩放到均值为0、 标准差为1的分布中, 即: 将特征数据变换为服从均值为0,标准差为1的标准正态分布(记为N ( 0 , 1 )) 。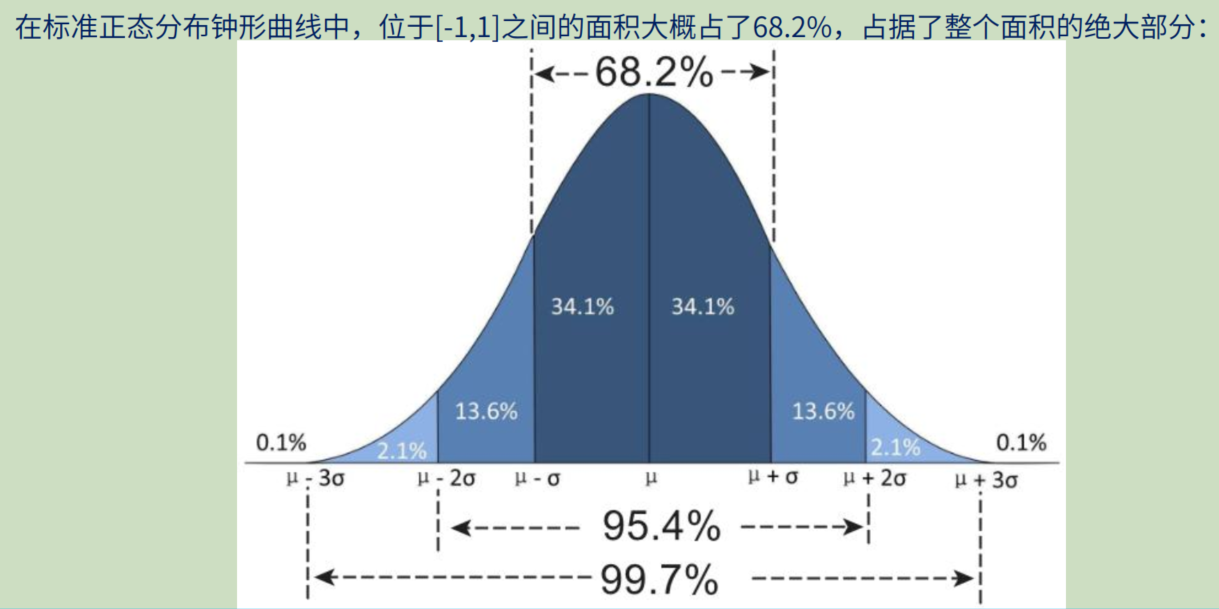
特点:
不强制将数据限制在固定范围(如[-1, 1]),而是保留异常值的影响。
适用于数据服从正态分布(或接近正态分布)的情况。
对距离敏感的算法(如SVM、线性回归、PCA)效果较好。
常见场景
标准化比较适合用于数据量非常庞大, 且特征的最大值和最小值未知的场合, 或者存在极端的最大最小值, 又或者数据存在孤立点的场合。或算法假设数据符合标准正态分布时。
6.3 归一化
归一化通常是指将数据缩放到特定的范围, 从广义上来说, 可以是各种范围, 常见的, 就是缩放到[0, 1]或者[-1, 1]的范围。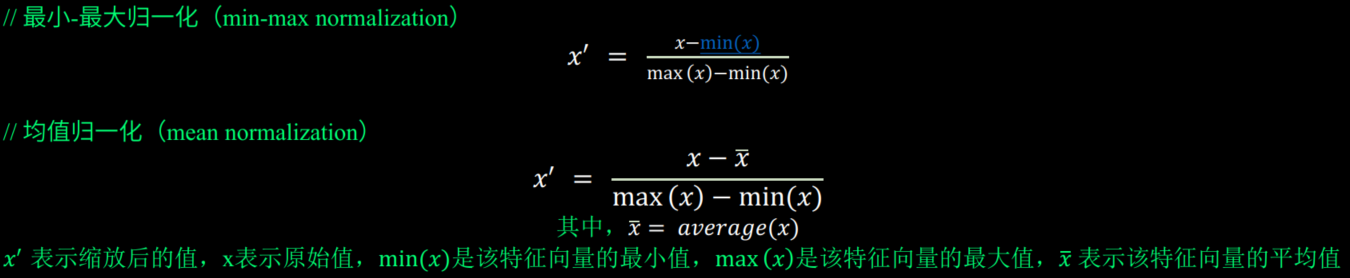
特点:
对异常值敏感(极端值会导致其他数据被压缩)。
适用于数据分布无明确假设,或需要固定范围的场景(如图像像素值[0, 255]→[0, 1])。
常见场景
常用于神经网络、KNN、聚类等算法。
数据尺度一致但范围不同(如不同传感器的读数),归一化可以利用特征的最大值和最小值, 将特征缩放到[0,1]区间。 如果知道了特征数据的最小值和最大值, 可以考虑使用归一化。
6.4 标准化和归一化的选择
我们使用标准化/归一化的目的, 就是为了消除数据特征之间的量纲影响, 使得不同指标之间具有可比性,否则量纲大的数据在神经网络中占主导地位,量纲小的数据往往被忽略,这不利于模型的训练,各种数据应该同等对待,或者人为设置权重,而不是随量纲大小而变化。
一般原则:
① 当在应用场景里能够确定最小值和最大值时, 可以使用归一化, 否则就直接使用标准化;
② 若实在是不知道什么时候使用归一化, 那就直接使用标准化。
6.5 批标准化(Batch Normalization,BN)
批标准化是指:在训练时, 计算每个小批次(mini-batch) 的训练数据的均值和标准差, 使得该小批次的数据具有零均值和单位方差, 然后使用计算得到的均值和方差对数据进行标准化。引入可学习的参数a、b进行缩放和平移, y=ax+b.
训练和推理不一致:训练时使用小批量的均值和方差,推理时使用整个数据集的均值和方差。
且每个小批次(mini-batch) 的数据的均值和标准差是不一样的, 原则上是:
① 在训练期间, 记录每个小批次的数据的均值和标准差;
② 训练完毕后, 计算所有小批次的数据的均值和标准差的平均值, 得到新的均值和新的标准差;
③ 使用新的均值和标准差作为数据预处理的标准化参数
但实际上, 很多模型在使用批标准化时并未记录每个小批次的数据的均值和标准差, 这就无法计算平均的均值和标准差。
6.6 mean_values与std_values的选择
①q:模型训练往往是一个个batch的批标准化,但一般不会记录每个小批次的数据的均值和标准差, 这就无法计算平均的均值和标准差?
②q:在进行模型推理的时候,一般只是用一张图片而已,那么mean_values与std_values是这张图片的值还是整个数据集的值?
ans:因为批标准化是使得输入符合标准正态分布,而标准正态分布中的数据有68.2%在[-1, 1]中,那么,我们直接设置mean_values = 127.5, 标准差std_values = 127.5, 则经过特征缩放后, 输入的数据被归一化到[-1,1]之间,这样虽然不够准确,但无论对于单个图片还是是整个数据集,其精度不会差。
首选,和训练时的预处理一致
其次,127.5
以几个预训练模型为例子, 讲解rknn.config()中的参数mean_values和std_values怎么配置。
mobilenetV1的模型:
https://www.tensorflow.org/lite/models/convert/metadata?hl=zh-cn
官网:其训练的时候为127.5,所以我们配置rknn.config()的时候mean_values和std_values也设置为127.5.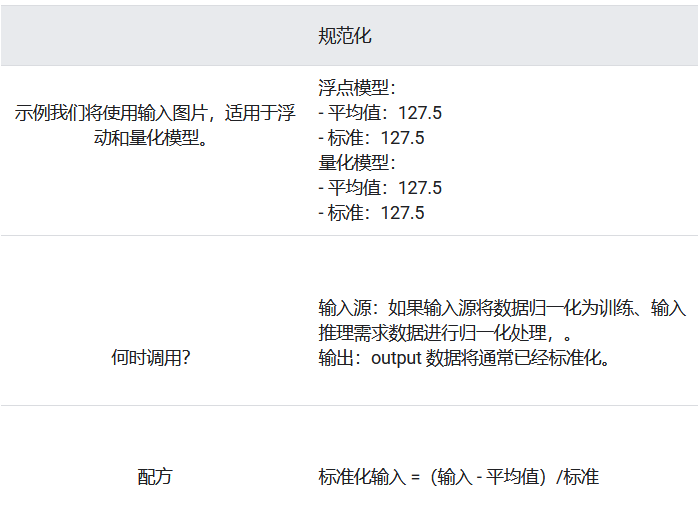
ssd_mobilenet_v1模型:
https://github.com/chuanqi305/MobileNet-SSD/blob/master/train.prototxt
官网:其训练的时候scale = 1 / 127.5 = 0.007843,即y = (x-m)*scale,mean_values和std_values设置为127.5.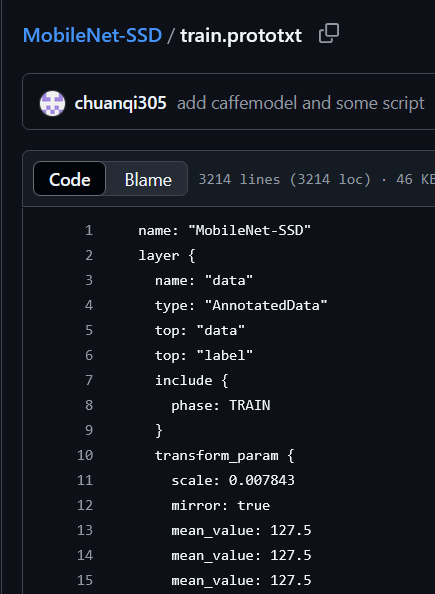
shufflenetv2模型:
https://github.com/Randl/ShuffleNetV2-pytorch/blob/master/data.py
源码:
__imagenet_stats = {'mean': [0.485, 0.456, 0.406],
'std': [0.229, 0.224, 0.225]}
因为该模型使用的是ImageNet数据集,ImageNet数据集的平均值(mean)和标准差(std)如下:
RGB通道均值(mean):
[0.485, 0.456, 0.406]
对应像素范围[0, 1];若输入为[0, 255],则需乘以255换算为(123.675, 116.28, 103.53)。
RGB通道标准差(std):
[0.229, 0.224, 0.225]
同理,[0, 255]范围下为(58.395, 57.12, 57.375)。
所以说rknn.config中,mean_values = [[123.675, 116.28, 103.53]],std_values=[[58.395, 57.12, 57.375]],或者相近的值也可以。
6.7 模型加载接口rknn.load_pytorch()
用户需要使用相应的加载接口导入不同框架模型文件。本人主要使用pytorch进行训练,故以rknn.load_pytorch() 为例。
ret =rknn.load_pytorch(model, input_size_list)
//从当前目录加载resnet18模型
ret = rknn.load_pytorch(model='./resnet18.pt',input_size_list=[[1,3,224,224]])
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
参数
model: PyTorch模型文件(.pt后缀)路径,而且需要是torchscript格式的模型。
input_size_list:每个输入节点对应的shape,所有输入shape放在一个列表中。
其中,
pt文件,保存完整模型(含网络结构、参数)或仅模型参数(state_dict),支持优化器状态、训练进度等元数据的存储。.pth与.pt无本质区别,均为PyTorch官方推荐的后缀。
TorchScript,是PyTorch的中间表示(IR)格式,可将动态图模型转换为静态图形式,实现脱离Python环境的高效推理。支持跨平台部署,通过C++/Java等语言加载(如libtorch库)。跨框架转换桥梁,作为中间格式转换为ONNX或TensorFlow Serving支持的模型(如ONNX需通过TorchScript导出),结合量化工具(如torch.quantization)生成轻量化推理模型。
6.8 TorchScript格式的PyTorch模型文件(.pt/pth)
trace模式,适用于无复杂控制流的模型,输入维度固定,需确保输入张量维度与模型匹配,如[1, 3, 224, 224]
torch.save(model, "original_model.pth") //保存完整模型
example_input = torch.rand(1, 3, 224, 224) // 根据模型输入调整维度
traced_model = torch.jit.trace(model, example_input) //model为完整模型
traced_model.save("traced_model.pt") //保存TorchScript模型
6.9 rknn.build()构建RKNN模型
用户加载原始模型后,下一步就是通过 rknn.build() 接口构建RKNN模型。
ret = rknn.build(do_quantization, dataset,rknn_batch_size)
//构建RKNN模型, 并且做量化
ret = rknn.build(do_quantization=True, dataset='./dataset.txt')
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
参数:
do_quantization: 该参数控制是否对模型进行量化,建议设置为 True 。量化可以减小模型的大小和提高在RKNPU上的性能。
dataset: 该参数指定用于量化校准的数据集,数据集的格式是文本文件。
rknn_batch_size:模型的输入Batch参数调整。默认值为None。如果大于1,则可以在一次推理中同时推理多帧输入图像或输入数据。
6.10 rknn.export_rknn() 导出RKNN模型
用户通过 rknn.build() 接口构建了 RKNN 模型后,可以通过 rknn.export_rknn() 接口导出RKNN模型文件( .rknn 后缀),以便后续模型的部署。
ret = rknn.export_rknn(export_path, cpp_gen_cfg)
//将构建好的RKNN模型保存到当前路径的resnet_18.rknn
ret = rknn.export_rknn('./resnet_18.rknn')
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
参数如下:
export_path: 导出模型文件的路径。
cpp_gen_cfg: 该参数决定是否在导出模型的同时生成 C++ 部署示例。
七、模型推理
原始模型转换为RKNN模型后,可在模拟器或开发板上进行推理,对推理结果进行后处理检验其是否正确。
注意:使用rknn.load_rknn()加载的RKNN模型仅限于连接NPU硬件进行推理或获取性能数据等,不能用于模拟器或精度分析等。
ret = rknn.load_rknn(path=‘./mobilenet_v1.rknn’)
7.1 初始化运行时环境init_runtime()
在模型推理或性能评估之前,必须先初始化运行时环境,明确模型的运行平台(具体的目标硬件平台或软件模拟器)。
res = init_runtime(
target: Any | None = None,
device_id: Any | None = None,
perf_debug: bool = False,
eval_mem: bool = False,
async_mode: bool = False,
core_mask: int = NPU_CORE_AUTO,
fallback_prior_device: str = "cpu")
参数:
target:目标硬件平台。默认值为None,即在PC使用工具时,模型在模拟器上运行。 注: target设为None时,需要先调用build或hybrid_quantization接口才可让模型在模拟器上运行。即使用rknn.load_rknn()不能用于模拟器或精度分析等。
device_id:设备编号,如果PC连接多台设备时,需要指定该参数,设备编号可以通过“list_devices”接口查看。默认值为None。
perf_debug:进行性能评估时是否开启debug模式。在debug模式下,可以获取到每一层的运行时间,否则只能获取模型运行的总时间。默认值为False。
eval_mem:是否进入内存评估模式。进入内存评估模式后,可以调用eval_memory接口获取模型运行时的内存使用情况。默认值为False。
async_mode:是否使用异步模式。默认值为False。(前版本该参数暂不支持)
core_mask:设置运行时的NPU核心。
例程:
//模型在模拟器上运行
ret = rknn.init_runtime()
//模型在目标硬件平台上运行
ret = rknn.init_runtime(target="rk3568")
//模型在目标硬件平台上运行,并开启debug模型性能模式,获取到每一层的运行时间
ret = rknn.init_runtime(target="rk3568",perf_debug=True)
//模型在目标硬件平台上运行,并开启debug模型性能模式,获取到每一层的运行时间,开启内存评估模式
ret = rknn.init_runtime(target="rk3568",perf_debug=True,eval_mem=True)
7.2 推理接口 rknn.inference()
在进行模型推理前,必须先构建或加载一个RKNN模型。 rknn.inference() 对当前模型进行推理,并返回推理结果。如果初始化运行环境时有设置target为Rockchip NPU设备,得到的是模型在硬件平台上的推理结果。如果没有设置target,得到的则是模型在模拟器上的推理结果。
outputs = inference(
inputs: Any,
data_format: Any | None = None,
inputs_pass_through: Any | None = None,
get_frame_id: bool = False)
参数:
inputs:待推理的输入列表,格式为ndarray。
data_format:输入数据的layout列表, “nchw”或“nhwc”,只对4维的输入有效。默认值为None,表示所有输入的layout都为NHWC。
inputs_pass_through:输入的透传列表。默认值为None,表示所有输入都不透传。非透传模式下,在将输入传给NPU驱动之前,工具会对输入进行减均值、除方差等操作;而透传模式下,不会做这些操作,而是直接将输入传给NPU。
# Set inputs
img = cv2.imread('../model/bell.jpg')
img = cv2.resize(img, (224, 224))
img = np.expand_dims(img, 0) //img shape (1, 224, 224, 3) ,nhwc
outputs = rknn.inference(inputs=[img],data_format='nhwc')
scores = softmax(outputs[0]) //将原始分数转换为概率值(总和为1)。
# print the top-5 inferences class
scores = np.squeeze(scores) //去除长度为1的维度
a = np.argsort(scores)[::-1] //返回从小到大排序的索引,[::-1]反转后变为降序。
print('-----TOP 5-----')
for i in a[0:5]:
print('[%d] score=%.2f class="%s"' % (i, scores[i], labels[i]))
print('done')
八、模型评估
RKNN提供(模拟器和板端)精度评估、耗时评估和内存评估的功能,辅助RKNN模型的优化和部署。
精度评估 --accuracy_analysis
内存评估 --eval_memory
耗时评估 --eval_perf
8.1 耗时评估 rknn.eval_perf()
模型必须运行在与PC连接的RK3568等上。如果调用“init_runtime”的接口来初始化运行环境时设置perf_debug为False,则获得的是模型在硬件上运行的总时间;如果设置perf_debug为True,除了返回总时间外,还将返回每一层的耗时情况。性能评估结果各字段说明可见RK_user_guide手册3.2.3模型性能评估。
perf_detail = eval_perf(
is_print: bool = True,
fix_freq: bool = True)
//对模型性能进行评估
ret = rknn.init_runtime(target=platform, perf_debug=True)
perf_detail = rknn.eval_perf()
参数 :
is_print:是否打印性能信息,默认值为True。
fix_freq:是否固定硬件设备的频率,默认值为True。
返回值:
perf_result:性能信息(字符串)。
8.2 内存评估rknn.eval_memory()
获取模型在硬件平台运行时的内存使用情况。模型必须运行在与PC连接的RV1103 / RV1103B / RV1106 / RV1106B / RK3562 / RK3566 /
RK3568 / RK3576 / RK3588上。且初始化时 rknn.init_runtime() 的 eval_mem 参数设置为 True ,将输出各部分内存消耗情况。
memory_detail = eval_memory(is_print: bool = True)
#对模型内存使用情况进行评估
ret = rknn.init_runtime(target=platform, eval_mem=True)
memory_detail = rknn.eval_memory()
参数 is_print:是否以规范格式打印内存使用情况,默认值为True。
#结果
--> Eval Memory
======================================================
Memory Profile Info Dump
======================================================
NPU model memory detail(bytes):
Weight Memory: 3.52 MiB #运行时模型权重的内存占用。
Internal Tensor Memory: 1.63 MiB #运行时模型中间tensor内存占用。
Other Memory: 84.94 KiB #运行时其他的内存占用
Total Memory: 5.23 MiB #运行时的总内存占用,即权重、中间tensor和其他的内存占用之和。
INFO: When evaluating memory usage, we need consider
the size of model, current model size is: 3.67 MiB
======================================================
8.3 精度评估rknn.accuracy_analysis()
该接口的功能是进行浮点、量化推理并产生每层的数据,并进行量化精度分析。推理并产生快照,也就是dump出每一层的tensor数据。会dump出包括fp32(浮点模型)和quant(量化模型)两种数据类型的快照,用于计算量化误差。
ret = accuracy_analysis(
inputs: Any,
output_dir: str = './snapshot',
target: Any | None = None,
device_id: Any | None = None)
//设置了target,则会获取NPU运行时每一层的结果,并进行精度的分析。进行模拟器和NPU的对比
ret = rknn.accuracy_analysis(inputs=['../model/bell.jpg'], target=args.target)
if ret != 0:
print('Accuracy analysis failed!')
exit(ret)
在output_dir文件夹中会有许多输出结果,可以看RK_API手册的2.13量化精度分析和user_guide手册的3.2模型评估。
当量化模型推理结果有问题,可以使用 rknn.accuracy_analysis() 接口进行精度分析,查看每层算子的精度。完整的精度分析包括模拟器精度分析结果和板端精度分析结果,同时模拟器和板端的精度分析结果都分为完整模型推理结果对比和逐层推理结果对比。通过这些数据及对比结果,我们可以查找问题的所在之处。
output_dir:输出目录,所有快照都保存在该目录。默认值为’./snapshot’。
如果没有设置target,在output_dir下会输出:
- simulator目录:保存整个量化模型在simulator上完整运行时每一层的结果(已转成float32);
- golden目录:保存整个浮点模型在simulator上完整跑下来时每一层的结果(也称golden结果);
- error_analysis.txt:记录simulator上量化模型逐层运行时每一层的(simulator目录中)结果与simulator上golden浮点模型逐层运行时每一层的(golden目录中)结果的余弦距离(entire_error cosine),以及量化模型取上一层的(golden目录中)浮点结果作为输入时,输出与浮点模型的余弦距离(single_error cosine)
如果有设置target,则在output_dir里还会多输出:
- runtime目录:保存整个量化模型在NPU上完整运行时每一层的结果(已转成float32)。
- error_analysis.txt:在上述记录的内容的基础上,还会记录量化模型在simulator上逐层运行时每一层的(golden目录中)结果与NPU上逐层运行时每一层的(runtime目录中)结果的余弦距离(entire_error cosine)等信息,更详细的信息请查看error_analysis.txt文件。
error_analysis.txt文件中:
- simulator_error:
entire: 从输入层到当前层 (simulator目录中)simulator 结果与 (golden 目录中)golden 结果对比的余弦距离和欧氏距离。这些误差会逐层累积。
single: 量化模型取上一层的(golden 目录中)浮点结果作为输入时, simulator上的量化结果与 golden 结果对比的余弦距离和欧氏距离。更能反映模拟器单层的准确性。 - runtime_error:
entire: 从输入层到当前层板端实际推理( runtime目录中)结果与 ( golden 目录中)golden 结果对比的余弦距离和欧氏距离。这些误差会逐层累积。
single: 当前层使用 ( golden 目录中)golden 输入时,板端当前层实际推理结果与 golden 结果对比的余弦距离和欧氏距离。更能反映模拟器单层的准确性。
余弦距离越小(cosine_norm) , 表明量化后的精度下降得越厉害,越大越好。
欧式距离越大(eculidean_norm) , 表明量化后的精度下降得越厉害,越小越好。
九、模型量化
模型的量化, 主要是指将模型中的权重和激活值, 由浮点数据转换成低比特(更低位宽) 的定点数据。 通过模型的量化, 有效减小模型的大小和计算强度, 有效地减少模型的内存占用, 这非常有利于模型在边缘终端设备上进行部署。但量化实际上是以牺牲模型精度为前提来提高模型在嵌入式设备上的运行效率和性能的。
9.1 量化方法
模型的量化方法主要有两种:
① 先基于各个深度学习框架训练得到一个没有量化的模型, 再通过rknn-toolkit(2)工具来进行量化。
量化方式: 训练后静态量化
支持的量化精度类型: int16, int8, uint8
支持的量化粒度: per-tensor(或 per-layer)
② 使用各个深度学习框架导出量化后的模型, 再通过rknn-toolkit工具直接把该已经量化的模型转换为RKNN模型。
量化方式: 训练后静态量化、 量化感知训练(QAT)
支持的量化精度类型: int8, uint8
支持的深度学习框架: PyToch(v1.9.0)、 ONNX(Onnxruntime v1.5.1)、 Tensorflow、 TFLite
注意:方法②受限严重,故一般使用方法①
rknn-toolkit2 2.3.0版支持的量化数据类型为INT8。也支持混合量化: 模型的某些层可以采用不同的量化精度类型(多于1种量化精度类型)
例如:
uint8进行定点量化, 可表示范围为 [0,255]
int8进行定点量化, 可表示范围为[-127,127]
int16同理
不同的数据类型的表示范围和精度完全不同, 简单地做类型转换显然是不行的,量化的本质就是对float32进行缩放, 即: Q=R/S+Z
R 表示真实的浮点值,Q 表示量化后的定点值,Z 表示 0 浮点值对应的量化定点值,S 则为缩放因子。
理论上, 模型推理的准确度(不过也和具体的硬件NPU有关) :
flaot32类型 > int16类型 > int8类型 >uint8类型
均匀/非均匀量化 ,也称线性/非线性量化
按照量化级的划分方式来分, 假设现在要把FP32映射到int8, 那么有:
均匀量化: 动态范围被均匀地划分为128份, 其中128表示量化级。
非均匀量化: 动态范围的划分不均匀, 一般用类似指数的曲线进行量化或者使用Kmeans对网络权重和特征进行聚类。
对称/非对称量化
根据Z(零点)的不同, 我们又分为对称量化和非对称量化
symmetric quantization(对称量化): FP32的0点被映射到了int的0点
asymmetric quantization(非对称量化): FP32的0点没有映射到int的0点
对称量化是非对称量化的简化版本,理论上非对称量化能够更好的处理数据分布不均匀的情况,因此实践中大多采用非对称量化方案。
Per-Layer量化和Per-Channel量化
Per-Layer量化将网络层的所有通道作为一个整体进行量化,所有通道共享相同的量化参数。 Per-Channel量化将网络层的各个通道独立进行量化,每个通道有自己的量化参数,提供更好的量化效果。
注: RKNN-Toolkit2中的Per-Channel量化中只针对权重进行Per-Channel量化,激活值和中间值仍为PerLayer量化。
总结:好的量化要权衡模型大小和精度。
9.2 量化误差
因为RK3568仅支持线性非对称的INT8量化,以线性非对称量化为例,浮点数量化为有符号定点数的计算原理如下:
量化会造成模型一定程度的精度丢失。根据公式(6-1)可知,量化误差来源于舍入误差和截断误差,即[.]和clamp运算。四舍五入的计算方式会产生舍入误差,。当浮点数过大,比例因子过小时,容易导致量化定点数超出截断范围,产生截断误差。理论上,比例因子的增大可以减小截断误差,但会造成舍入误差的增大。因此为了权衡两种误差,需要设计合适的比例因子和零点,来减小量化误差。
9.3 量化配置
RKNN-Toolkit2中量化的配置方法在rknn.config()和rknn.build()接口实现。其中量化方法配置由rknn.config()接口实现,量化开关和校正集路径的选择由rknn.build()接口实现。
rknn.config()接口包含以下相关量化配置项:
quantized_dtype:选择量化类型,目前RK3568仅支持线性非对称的INT8量化,默认为asymmetric_quantized-8。
quantized_algorithm:选择量化算法,包括Normal, KL-Divergence和MMSE量化算法。可选值为normal, kl_divergence和mmse, 默认为normal。
quantized_method:选择Per-Layer和Per-Channel量化。可选值为layer和channel,默认为channel。
在RKNN_MODEL_ZOO的源码中有:
rknn.config
:param quantized_dtype: quantize data type, currently support: w8a8, w8a16, w16a16i, w16a16i_dfp. default is w8a8.
:param quantized_algorithm: currently support: normal, mmse (Min Mean Square Error), kl_divergence. default is normal.
:param quantized_method: quantize method, currently support: layer, channel. default is channel.
quantized_dtype显示有4种,RKNN_API手册中介绍:w8a8=asymmetric_quantized-8
quantized_dtype:量化类型,目前支持的量化类型有w8a8、 w4a16、 w8a16、 w4a8、w16a16i和w16a16i_dfp。默认值为w8a8。
w8a8:权重为8bit非对称量化精度,激活值为8bit非对称量化精度。 ( RK2118不支持)
w4a16:权重为4bit非对称量化精度,激活值为16bit浮点精度。 (仅RK3576支持)
w8a16:权重为8bit非对称量化精度,激活值为16bit浮点精度。 (仅RK3562支持)
w4a8:权重为4bit非对称量化精度,激活值为8bit非对称量化精度。 (暂不支持)
w16a16i:权重为16bit非对称量化精度,激活值为16bit非对称量化精度。 (仅RV1103/RV1106支持)
w16a16i_dfp:权重为16bit动态定点量化精度,激活值为16bit动态定点量化精度。 (仅RV1103/RV1106支持)
quantized_algorithm建议:
量化算法运行速度:Normal>KL-Divergence>MMSE
①Normal量化算法不会产生截断误差,但对异常值很敏感,因为大异常值可能会导致舍入误差过大。
②KL-Divergence量化算法通过最小化浮点数和定点数之间的分布差异,能够更好地适应非均匀的数据分布并缓解少数异常值的影响
③MMSE量化算法通过最小化浮点数与量化反量化后浮点数的均方误差损失,确定量化范围的最大值和最小值,在一定程度上缓解大异常值带来的量化精度丢失问题。
rknn.build()接口包含以下相关量化配置项:
do_quantization:是否开启量化,默认为False。
dataset:量化校正集的路径,默认为空。
dataset建议:
①normal量化算法的特点是速度较快,推荐量化数据量一般为20-100张左右,更多的数据量下精度未必会有进一步提升。
②mmse量化算法由于采用暴力迭代的方式,速度较慢,但通常会比normal具有更高的精度,推荐量化数据量一般为20-50张左右,用户也可 以根据量化时间长短对量化数据量进行适当增减。
③kl_divergence量化算法所用时间会比normal多一些,但比mmse会少很多,在某些场景下( feature分布不均匀时)可以得到较好的改善效果,推荐量化数据量一般为20-100张左右
④量化校正集用于计算激活值的量化范围,在选择量化校正集时应覆盖模型实际应用场景的不同数据分布,增加量化校正集数量会增加量化算法的运行时间但不一定能提高量化精度。
9.4 混合量化
混合量化对模型不同层采用不同的量化数据类型,将不适合量化的层使用较高精度的数据类型表达,例如, 某些层的权重和激活值采用uint8量化精度类型, 某些层的权重和激活值采用int16量化精度类型,以此缓解模型量化精度损失的问题,但混合精度量化会增加额外开销,并且需要用户确定不同层的量化数据类型。
RKNN-Toolkit2提供了两种混合量化功能:
①将指定的量化层改成非量化层,如用 FLOAT16 进行计算。 (因NPU上非量化算力较低,所以推理速度会有一定降低)。
在rknn.hybrid_quantization_step1()生成的modelname.quantization.cfg的custom_quantize_layers下进行修改。
②每一层的量化参数也可以进行修改。 (量化参数不建议修改)
在modelname.quantization.cfg的quantize_parameters中修改。
q:混合量化是为了提高模型精度,accuracy_ananlysis()函数使用测试集可提供了详细的数据分析。使用accuracy_ananlysis()测试集的影响,输出的结果是测试集上的数据。rknn.build()也受校正数据集的影响,用校正数据集输出的rknn模型来分析测试集的结果,那么这两个数据集应该是什么关系呢?一致or包含?还是无关?测试集的结果能否代替整个数据集的结果?
ans:在选择量化校正集时应覆盖模型实际应用场景的不同数据分布,即不同类别的数据集都添加一些,确保雨露均沾。测试集也应包含各个不同类别的数据,既然二者都包含了各个类别的数据,那么这两个数据集不同,更能体现模型泛化能力和精度。除非某些类别精度较差,我们可以围绕这些类别进行混合量化。有一个整体和局部的区别,至于那个更好?需要实验验证。
9.5 混合量化函数
①使用混合量化功能时,第一阶段调用的主要接口是hybrid_quantization_step1,用于生成临时模型文件(<model_name>.model)、数据文件(<model_name>.data)和量化配置文件(<model_name>.quantization.cfg)。
ret=hybrid_quantization_step1(
dataset: str = 'dataset.txt',
rknn_batch_size: Any | None = None,
proposal: bool = False,
proposal_dataset_size: int = 1,
custom_hybrid: Any | None = None
)
ret = rknn.hybrid_quantization_step1(dataset='./dataset.txt', proposal=True)
if ret != 0:
print('hybrid_quantization_step1 failed!')
exit(ret)
print('done')
参数:
dataset:量化校正数据集,同RKNN.build
rknn_batch_size:见构建RKNN模型的rknn_batch_size说明。
proposal:产生混合量化的配置建议值。 默认值为False。
proposal_dataset_size: proposal使用的dataset的张数。默认值为1。 因为proposal功能比较耗时,所以默认只使用1张,也就是dataset里的第一张。
custom_hybrid:用于根据用户指定的多组输入和输出名,选取混合量化对应子图。
其产生混合量化的配置建议值,是根据dataset的proposal_dataset_size个数据提出的,有局限性,proposal_dataset_size可以设置的大一些。
② hybrid_quantization_step2用于使用混合量化功能时生成RKNN模型。
ret = hybrid_quantization_step2(
model_input: Any,
data_input: Any,
model_quantization_cfg: Any)
ret = rknn.hybrid_quantization_step2(model_input='./mobilenetv2-12.model',data_input='./mobilenetv2-12.data',
model_quantization_cfg='./mobilenetv2-12.quantization.cfg')
if ret != 0:
print('hybrid_quantization_step2 failed!')
exit(ret)
print('done')
参数 :
model_input: hybrid_quantization_step1生成的临时模型文件(<model_name>.model)路径。
data_input: hybrid_quantization_step1生成的数据文件(<model_name>.data)路径。
model_quantization_cfg: hybrid_quantization_step1生成并经过修改后的模型量化配置文件(<model_name>.quantization.cfg)路径。
9.5 混合量化步骤
本人以rknn-toolkit2-2.3.0/rknn-toolkit2/examples/functions/hybrid_quant 和 rknn_model_zoo-main/examples/mobilenet 这两文件为参考。
为了突出混合量化后对模型精度的提升,需要先记录混合量化前accuracy_ananlysis()的结果,或者rknn.inference() 的结果也行,代码如下。
其中ret = rknn.build(do_quantization=do_quant, dataset=DATASET_PATH),dataset有20张图片。
ret = rknn.accuracy_analysis(inputs=inputs_list, target=args.target),inputs有4张图片,我认为,最好是每个类别的照片都有。
# Build model
print('--> Building model')
do_quant = True
ret = rknn.build(do_quantization=do_quant, dataset=DATASET_PATH)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Accuracy analysis
if args.accuracy_analysis:
inputs_list = ['../model/bell.jpg',
'../../../datasets/imagenet/ILSVRC2012_img_val_samples/ILSVRC2012_val_00000011.JPEG',
'../../../datasets/imagenet/ILSVRC2012_img_val_samples/ILSVRC2012_val_00045561.JPEG',
'../../../datasets/imagenet/ILSVRC2012_img_val_samples/ILSVRC2012_val_00017912.JPEG']
print('--> Accuracy analysis')
ret = rknn.accuracy_analysis(
inputs=inputs_list, target=args.target)
if ret != 0:
print('Accuracy analysis failed!')
exit(ret)
print('done')
error_analysis.txt 部分结果如下,在runtime_error的enc中,下面这些的layer误差较大。建议使用float16运算。
layer_name simulator_error runtime_error
entire single entire single_sim
cos euc cos euc cos euc cos euc
---------------------------------------------------------------------------------------------------------------
........
[Clip] 317 0.99995 | 3.0455 0.99995 | 3.0455 0.99993 | 3.4390 0.99994 | 3.2604
[Clip] 320 0.99951 | 18.696 0.99954 | 18.145 0.99951 | 18.738 1.00000 | 1.5393
[Clip] 325 0.99860 | 23.443 0.99977 | 9.4888 0.99859 | 23.477 1.00000 | 1.0993
[Clip] 328 0.99814 | 15.536 0.99957 | 7.4565 0.99813 | 15.549 0.99999 | 1.1741
以 [Clip] 317 0.99995 | 3.0455 0.99995 | 3.0455 0.99993 | 3.4390 0.99994 | 3.2604 为例,介绍一下。
其中,317是该卷积层的输入input,netron结构图如下,有些layer在simulator_error中有数据,在runtime_error中没有数据,我也不清楚是什么layer,混合量化关注runtime_error有的layer即可。可以看到在统一量化中,rknn模型每个layer的input,output,weight都是int8,但bias是float32.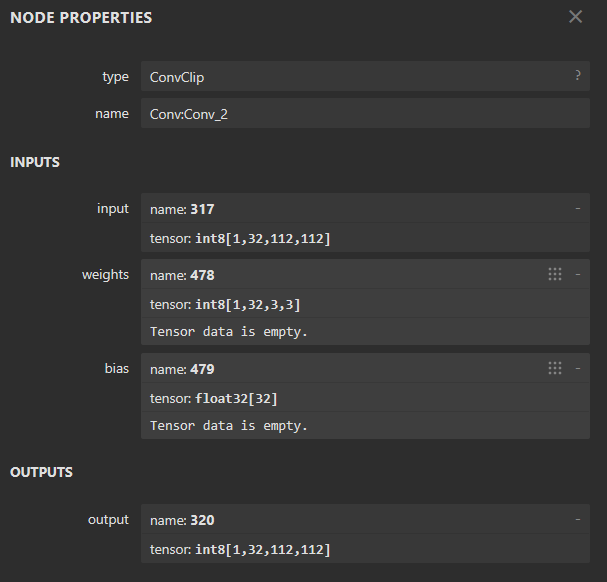
①加载原始模型,生成量化配置文件、临时模型文件和数据文件。
# Build model
print('--> hybrid_quantization_step1')
ret = rknn.hybrid_quantization_step1(dataset=DATASET_PATH, proposal=True,proposal_dataset_size=20)
if ret != 0:
print('hybrid_quantization_step1 failed!')
exit(ret)
print('done')
其中, ret = rknn.hybrid_quantization_step1(dataset=DATASET_PATH, proposal=True,proposal_dataset_size=20)的dataset是一致的,也是20张图片,对20张图片都进行运行推荐。
量化配置文件(<model_name>.quantization.cfg)结果如下:
custom_quantize_layers: # 0.990652859210968
'452': float16 # 0.9907999038696289
'618': float16
。。。。。。
quantize_parameters:
input:
qtype: asym
qmethod: layer
dtype: float32
min:
- -2.1179039478302
max:
- 2.640000104904175
scale: []
zero_point: []
ori_min:
- -2.1179039478302
ori_max:
- 2.640000104904175
。。。。。。
可知直接使用其推荐的layer修改建议,也可以根据error_analysis.txt 中的结果,修改如下。我使用其推荐layer修改。
custom_quantize_layers:
'317': float16
'320': float16
'325': float16
'328': float16
quantize_parameters:
。。。。。。
②生成 RKNN 模型。具体的接口调用流程如下:
还需要在hybrid_quantization_step2之后进行accuracy_analysis,和之前统一量化进行对比。
ret = rknn.hybrid_quantization_step2(model_input='./mobilenetv2-12.model',data_input='./mobilenetv2-12.data',
model_quantization_cfg='./mobilenetv2-12.quantization.cfg')
if ret != 0:
print('hybrid_quantization_step2 failed!')
exit(ret)
ret = rknn.export_rknn(args.output_path)
if ret != 0:
print('Export rknn model failed!')
exit(ret)
模型大小对比:
14M 4月 9 16:08 mobilenetv2-12.onnx
4.9M 4月 17 09:46 mobilenet_v2_mix.rknn //混合量化
3.7M 4月 16 15:57 mobilenet_v2.rknn //统一int8量化
error_analysis.txt对比:
统一int8量化
layer_name simulator_error runtime_error
entire single entire single_sim
cos euc cos euc cos euc cos euc
---------------------------------------------------------------------------------------------------------------
[Input] input 1.00000 | 0.0 1.00000 | 0.0
[exDataConvert] input_int8 0.99999 | 2.0815 0.99999 | 2.0815
[Conv] 474
[Clip] 317 0.99995 | 3.0455 0.99995 | 3.0455 0.99993 | 3.4390 0.99994 | 3.2604
[Conv] 477
[Clip] 320 0.99951 | 18.696 0.99954 | 18.145 0.99951 | 18.738 1.00000 | 1.5393
[Conv] 480 0.99836 | 24.715 0.99976 | 9.4394 0.99835 | 24.763 1.00000 | 0.6997
[Conv] 483
[Clip] 325 0.99860 | 23.443 0.99977 | 9.4888 0.99859 | 23.477 1.00000 | 1.0993
[Conv] 486
[Clip] 328 0.99814 | 15.536 0.99957 | 7.4565 0.99813 | 15.549 0.99999 | 1.1741
[Conv] 489 0.99712 | 16.303 0.99978 | 4.4839 0.99713 | 16.275 1.00000 | 0.3148
。。。。。。
[Conv] output_mm 0.99331 | 12.933 0.99992 | 1.4133 0.99203 | 14.847 1.00000 | 0.2007
[Reshape] output_int8 0.99331 | 12.933 0.99993 | 1.3043
[exDataConvert] output 0.99331 | 12.933 0.99993 | 1.3043 0.99203 | 14.847 1.00000 | 0.0
混合量化
layer_name simulator_error runtime_error
entire single entire single_sim
cos euc cos euc cos euc cos euc
------------------------------------------------------------------------------------------------------------------------
[Input] input 1.00000 | 0.0 1.00000 | 0.0 1.00000 | 0.0949 1.00000 | 0.0949
[exDataConvert] input_int8__float16 1.00000 | 0.0949 1.00000 | 0.0949
[Conv] 474 1.00000 | 0.0954 1.00000 | 0.0954
[Clip] 317 1.00000 | 0.0853 1.00000 | 0.0625 1.00000 | 0.0853 1.00000 | 0.0013
[Conv] 477 1.00000 | 0.6922 1.00000 | 0.6563
[Clip] 320 1.00000 | 0.6021 1.00000 | 0.1168 1.00000 | 0.6020 1.00000 | 0.0037
[Conv] 480 1.00000 | 0.7416 1.00000 | 0.2274 1.00000 | 0.7416 1.00000 | 0.0063
[Conv] 483 1.00000 | 0.9626 1.00000 | 0.1933
[Clip] 325 1.00000 | 0.7154 1.00000 | 0.0914 1.00000 | 0.7154 1.00000 | 0.0092
[Conv] 486 1.00000 | 0.6301 1.00000 | 0.1400
[Clip] 328 1.00000 | 0.4545 1.00000 | 0.0521 1.00000 | 0.4544 1.00000 | 0.0003
[Conv] 489 1.00000 | 0.4913 1.00000 | 0.0925 1.00000 | 0.4914 1.00000 | 0.0018
[exDataConvert] 489__int8 0.99990 | 3.0202 0.99990 | 2.9799 0.99990 | 3.0201 1.00000 | 0.5118
。。。。。。
[Conv] output_mm 0.99913 | 4.7023 0.99992 | 1.4133 0.99918 | 4.6359 1.00000 | 0.2007
[Reshape] output_int8 0.99913 | 4.7023 0.99993 | 1.3043
[exDataConvert] output 0.99913 | 4.7023 0.99993 | 1.3043 0.99918 | 4.6359 1.00000 | 0.0
其中,exDataConvert是float与int的转换层,是混合量化后新添加的。
可以看出,混合量化模型的内存大小变大了,但精度提升了。模型变大了,运行所需时间必然也会变长。
使用https://netron.app/ netron官网查看mobilenet_V2_mix.rknn模型,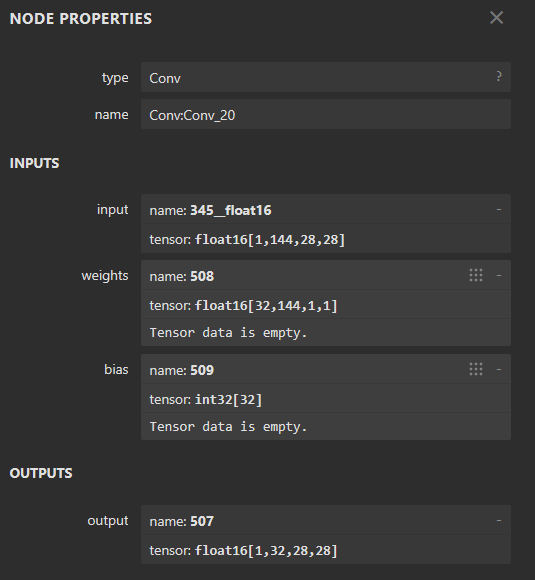
可以看到,layer的weight为了配合input(float)也变成了float类型,但bias变成了int类型。
十、物体识别 c API 部署
这里是对5.3 板端部署-c/c++ 的解析。使用的例程是rknn_model_zoo-main/examples/mobilenet
因为模型c API部署代码和模型本身有精密联系,如果实际使用的模型和mobilenet相似,可以参考mobilenet c API例程实现自己模型的部署。当然,如果已经对rk例程中各种函数有一定的了解,可以不用关心是否模型相似。
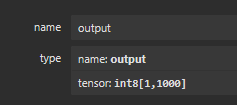
使用mobilenet进行物体识别,输入[1,3,224,224],输出[1,1000]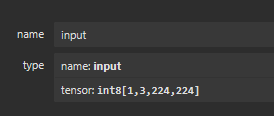
详细请看:
build-linux.sh 解析
CMakeLists.txt解析
main.cc解析
执行命令:./build-linux.sh -t rk3568 -a aarch64 -d mobilenet
10.1 build-linux.sh
build-linux.sh 解析
build-linux.sh 的目的是设置一系列配置信息,如下:
BUILD_DEMO_NAME=mobilenet
BUILD_DEMO_PATH=examples/mobilenet/cpp
TARGET_SOC=rk356x
TARGET_ARCH=aarch64
BUILD_TYPE=Release
ENABLE_ASAN=OFF
DISABLE_RGA=OFF
DISABLE_LIBJPEG=OFF
INSTALL_DIR=/home/hlf/rknn_model_zoo-main/install/rk356x_linux_aarch64/rknn_mobilenet_demo
BUILD_DIR=/home/hlf/rknn_model_zoo-main/build/build_rknn_mobilenet_demo_rk356x_linux_aarch64_Release
CC=/opt/atk-dlrk356x-toolchain/bin/aarch64-buildroot-linux-gnu-gcc
CXX=/opt/atk-dlrk356x-toolchain/bin/aarch64-buildroot-linux-gnu-g++
随后 在/home/hlf/rknn_model_zoo-main/build/build_rknn_mobilenet_demo_rk356x_linux_aarch64_Release路径下执行cmake,配置信息如下:
cmake ../../examples/mobilenet/cpp \
-DTARGET_SOC=rk356x\
-DCMAKE_SYSTEM_NAME=Linux \
-DCMAKE_SYSTEM_PROCESSOR=aarch64\
-DCMAKE_BUILD_TYPE=Release\
-DENABLE_ASAN=OFF\
-DDISABLE_RGA=OFF\
-DDISABLE_LIBJPEG=OFF\
-DCMAKE_INSTALL_PREFIX=/home/hlf/rknn_model_zoo-main/install/rk356x_linux_aarch64/rknn_mobilenet_demo
在/home/hlf/rknn_model_zoo-main/build/build_rknn_mobilenet_demo_rk356x_linux_aarch64_Release路径下执行make 和 make install
目标转移到 examples/mobilenet/cpp/CMakeLists.txt
10.2 CMakeLists.txt
CMakeLists.txt解析
build-linux.sh 最终结果是执行cmake命令,故需要分析examples/mobilenet/cpp/CMakeLists.txt。
examples/mobilenet/cpp/CMakeLists.txt中添加了子目录3rdparty和utils,其内部的CMakeLists.txt执行了一些环境配置,重点是可执行文件rknn_mobilenet_demo,其源文件为 main.cc和examples/mobilenet/cpp/rknpu2/mobilenet.cc,main.cc中有main()函数,这是可执行文件rknn_mobilenet_demo开始运行的起点。执行rknn_mobilenet_demo就是运行main.cc的main()函数。
add_executable(${PROJECT_NAME}
main.cc
rknpu2/mobilenet.cc
)
目标转移到 rknn_model_zoo-main/examples/mobilenet/cpp/main.cc
10.3 main.cc
main.cc解析
使用C API来实现rknn模型的调用。main.cc中的代码主要和模型有关,特别是前处理和后处理部分,中间的模型init、run、reference都是通用的。mobilenet的最后输出是tensor: int8[1,1000],所以需要softmax,get_topk_with_indices获取前topk个数据。里面的函数很多,具体实现有源码可以参考。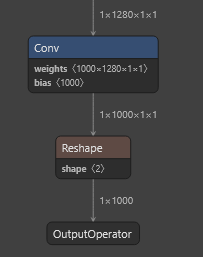
十一、语义分割 c API 部署
使用的例程是rknn_model_zoo-main/examples/ppseg
PaddleSeg的输入为[1,3,512,512],输出为[1,19,512,512].
build-linux.sh 和 CMakeLists.txt 已经在物体识别c API部署中解析了一次,大差不差,CMakeLists.txt中添加了一些库。主要关心main.cc中的实现。
详情:rk3568-ppseg-main.cc
这是一个很好的语义分割模板。

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)