
大数据2_05_hadoop3.x集群配置
5 hadoop3集群配置步骤1:配置nodepad++,可以在windows系统下修改linux内的文件。步骤2:集群规划hadoop102hadoop103hadoop104namenodesecondrynamenodedatanodedatanodedatanoderesourcemanagernodemanagernodemanagernodemanager步骤3:在hadoop102上
·
5 hadoop3集群配置
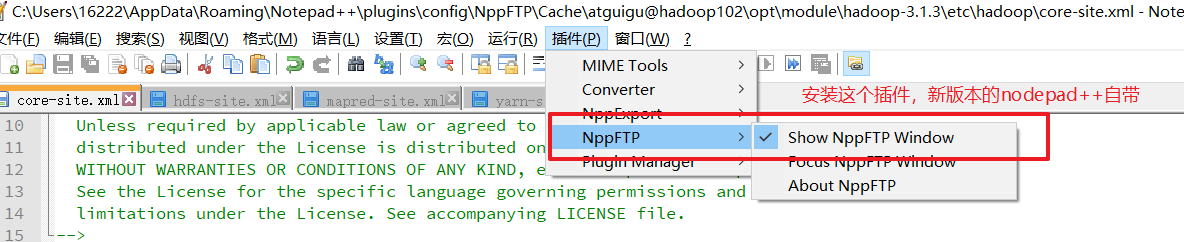
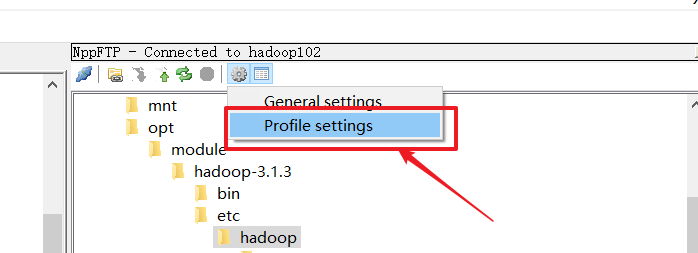
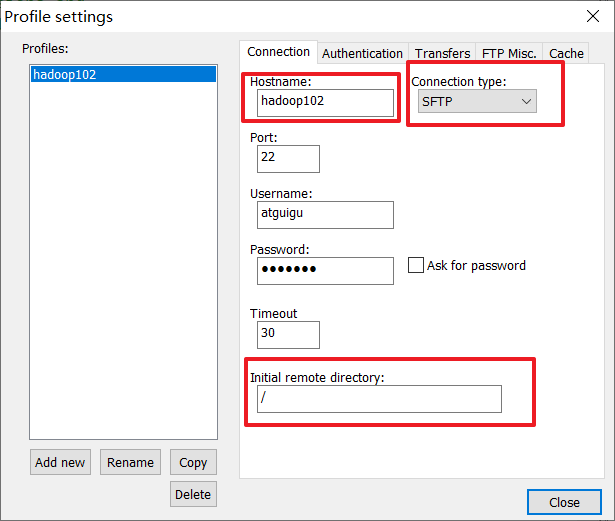
步骤1:配置nodepad++,可以在windows系统下修改linux内的文件。
步骤2:集群规划
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| namenode | secondrynamenode | |
| datanode | datanode | datanode |
| resourcemanager | ||
| nodemanager | nodemanager | nodemanager |
步骤3:在hadoop102上修改5个文件:core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml workers
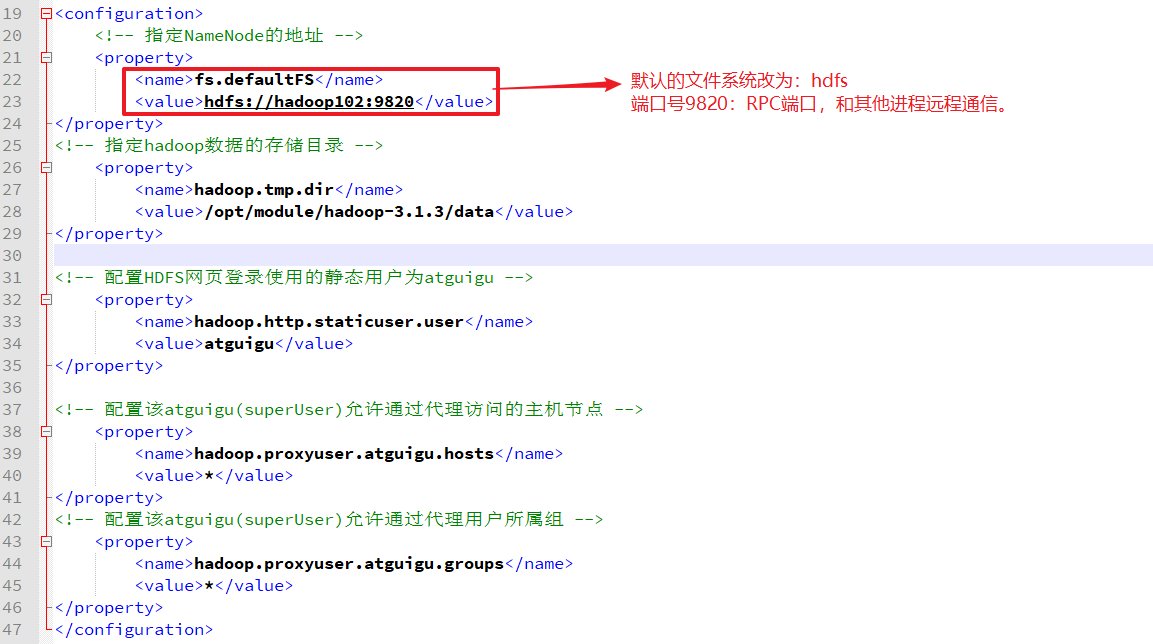
- core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9820</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
</configuration>
- hdfs-site.xml
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
- mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- yarn-site.xml
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
- workers
hadoop102
hadoop103
hadoop104
步骤4:配置完集群后,就要分发/opt/module/hadoop3.1.3/etc/到其他节点
xsync /opt/module/hadoop3.1.3/etc/
步骤5:在hadoop102初始化namenode
不是初次初始化namenode时,需要删除/opt/module/hadoop3.1.3/data/ 和/opt/module/hadoop3.1.3/logs;然后再执行hdfs namenode -format命令。
hdfs namenode -format
步骤6:启动集群
# 群起hdfs(在hadoop102上)
start-dfs.sh
# 群起yarn(在hadoop103上)
start-yarn.sh
步骤7:web查看集群信息
- 查看hdfs节点信息
hadoop102:9870 #前提是配置了Windows下的C:\Windows\System32\drivers\etc\hosts
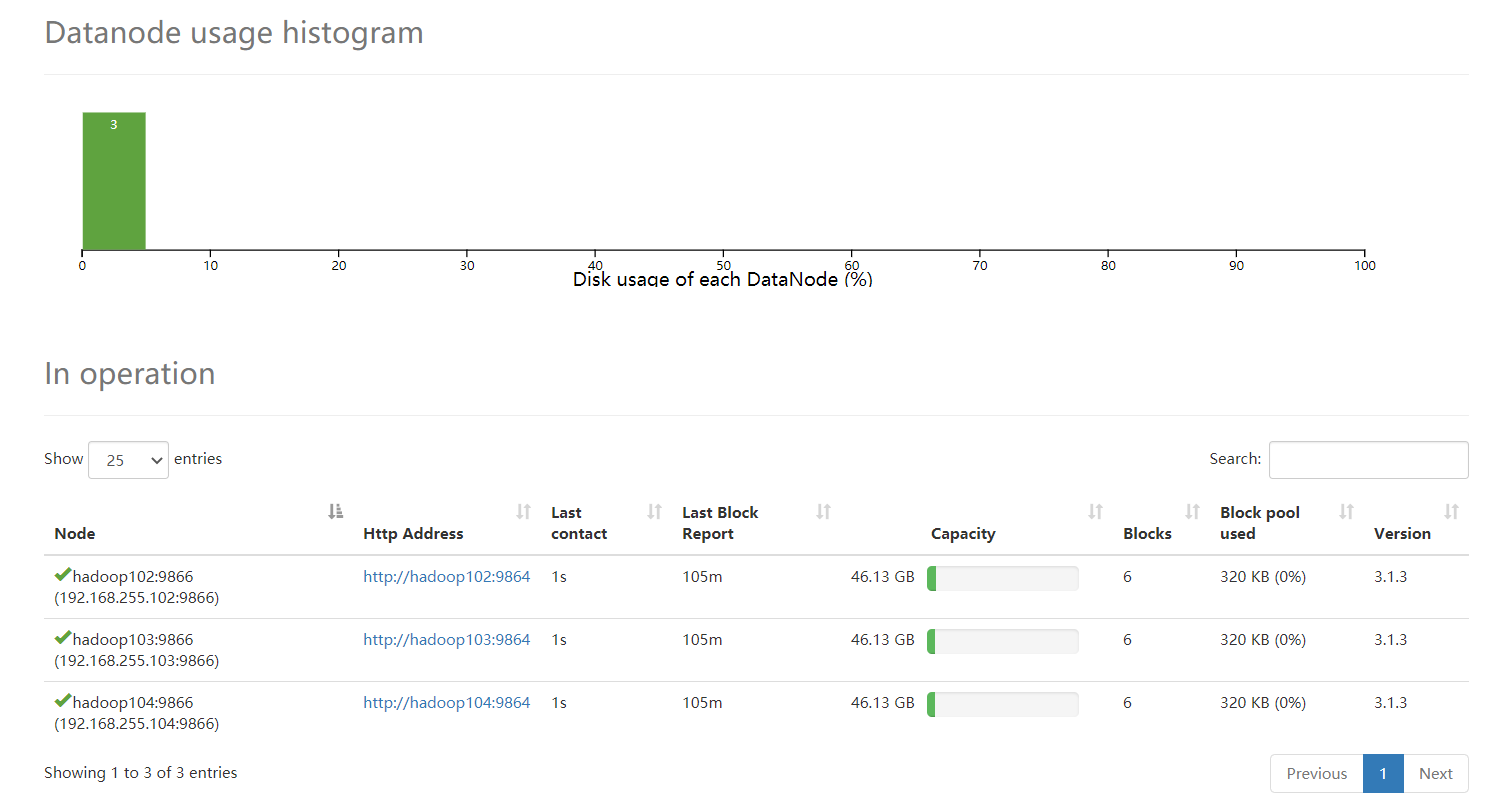
步骤8:测试集群
- 上传一个文件到HDFS
# 方式1:采用web点击上传本地文件
# 方式2:
hdfs dfs -put /home/atguigu/test.txt /wcinput
- 执行MapReduce作业
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /output
此时HDFS内的/wcinput内有三个文件。那么就会同时统计这三个文件的wordcount

运行结果:


技术共进,成长同行——讯飞AI开发者社区
更多推荐


 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)