
Transformer学习与基础实验3——transformer应用举例演示——英汉翻译(1. 数据准备与处理)
中英文语料库分词、预处理多进程处理大型中文语料库的jieba分词算法以提高效率构造语料库词典创建训练数据集Dataset和Dataloader
上一篇:http://Transformer学习与基础实验2——Transformer结构
数据集介绍
名称:中文-英语句子对数据集 cmn-eng.zip
来源:
下载链接:https://www.manythings.org/anki/cmn-eng.zip,
下载后其中的cmn.txt即为原始数据集文件

拓展:更多不同语言的双语语句对数据集下载:http://www.manythings.org/anki/
现将cmn.txt的最后一列数据删除,得到cmn_processed.txt,准备进行中英文语句的分词,得到初步处理的双语序列。

预处理PreProcess
句子分词
直接上演示代码:
import torch
from torch.utils.data import Dataset, DataLoader
import jieba
import re
# 假设cmn_processed.txt文件已经被加载到变量text中
texts = """
Hi. 嗨。
Hi. 你好。
Run. 你用跑的。
Stop! 住手!
Wait! 等等!
Wait! 等一下!
Begin. 开始!
Hello! 你好。
I try. 我试试。
I won! 我赢了。
Oh no! 不会吧。
Cheers! 乾杯!
Got it? 知道了没有?
"""
# 分割文本为两个句子(双语)
texts_list = texts.strip().split('\n')
sentences_en = []
sentences_cn = []
for texts in texts_list:
en, cn = texts.split('\t')
sentences_en.append(en)
sentences_cn.append(cn)
print(sentences_en) # ['Hi.', 'Hi.', 'Run.', 'Stop!', 'Wait!', 'Wait!', 'Begin.', 'Hello!', 'I try.', 'I won!', 'Oh no!', 'Cheers!', 'Got it?']
print(sentences_cn) # ['嗨。', '你好。', '你用跑的。', '住手!', '等等!', '等一下!', '开始!', '你好。', '我试试。', '我赢了。', '不会吧。', '乾杯!', '知道了没有?']
# 中文分词器
def cn_tokenizer_op(sentence: str):
return jieba.lcut(sentence)
# 英文分词器
def en_tokenize_op(sentence: str):
sentence = sentence.rstrip()
return [tok.lower() for tok in re.findall(r'\w+|[^\w\s]', sentence)]
# 分词器测试
print(cn_tokenizer_op(sentences_cn[-1])) # ['知道', '了', '没有', '?']
print(en_tokenize_op(sentences_en[-1])) # ['got', 'it', '?']
words_list_cn = [cn_tokenizer_op(sentence) for sentence in sentences_cn]
words_list_en = [en_tokenize_op(sentence) for sentence in sentences_en]
print(words_list_cn) # [[......], ......, ['我', '试试', '。'], ['我', '赢', '了', '。'], ['不会', '吧', '。'], ['乾杯', '!'], ['知道', '了', '没有', '?']]
print(words_list_en) # [[......], ......, ['i', 'try', '.'], ['i', 'won', '.'], ['oh', 'no', '.'], ['cheers', '!'], ['got', 'it', '?']]中文分词使用的接口说明:
jieba.lcut 是 jieba 库中的一个方法,用于对中文文本进行分词。jieba 是一个非常流行的中文分词Python库,它支持三种分词模式:全模式、精确模式和搜索引擎模式。lcut 方法是精确模式的快捷方式,它直接返回一个列表,列表中的元素是分词后的结果。
单、多进程处理,保存最后的分词结果到文件中(参考)
读取双语语句数据集文件,所有句子对保存在lines列表中,列表的每个元素为一个“二元组”(英文句子,中文句子):
txt_path = "cmn_processed.txt"
# 读取文件
with open(txt_path, "r", encoding="utf-8") as f:
lines = f.readlines()
lines = [line.strip().split("\t") for line in lines]
n = len(lines)分词处理操作,英文、中文分词的结果分别保存在list1和list2:
def pre_process_data(sentences_list, l, r, list1, list2):
print(f"Process {l} - {r} ......\n")
for i in tqdm(range(l, r)):
en_sentence = en_tokenize_op(sentences_list[i][0])
ch_sentence = cn_tokenizer_op(sentences_list[i][1])
list1[i] = en_sentence
list2[i] = ch_sentence如果单进程处理所有的中文分词(将近3万个句子),中文句子分词需要花费很多时间。
创建两个列表用于分别保存中英分词结果,执行pre_process_data(lines, 0, n, list1, list2),处理完毕后保存两个列表中的内容到本地文件中以供下次直接使用。
这里介绍本地多进程(使用多块CPU)处理,现在的Windows电脑一般都能开二三十个并行的多进程,还是能很快处理完成这近3万个句子对的分词处理的。
多进程处理的pipeline图:

代码实现:
if __name__ == '__main__':
from multiprocessing import Process, Manager, cpu_count
# 创建Manager 对象并创建两个共享列表
English_sentences = Manager().list()
Chinese_sentences = Manager().list()
# 初始化两个列表
for i in range(n):
English_sentences.append([])
Chinese_sentences.append([])
# 定义进程数
num_processes = cpu_count()
# 计算每个进程的任务处理范围
l = 0
r = n // num_processes
scope_list = [(l, r)]
for _ in range(num_processes - 2):
l = r
r = l + n // num_processes
scope_list.append((l, r))
# 最后一个进程处理范围
l = scope_list[-1][1]
r = n
scope_list.append((l, r))
print(scope_list)
# 创建进程
processes = [Process(target=pre_process_data, args=(lines, l, r, English_sentences, Chinese_sentences)) for l, r in scope_list]
for p in processes:
p.start()
for p in processes:
p.join()
print("All process done!")
print("Example of pre-processed data:")
print(English_sentences[-1])
print(Chinese_sentences[-1])将分词结果写入到文件中(同时统计两种语言语料的最大单词个数):
max_len_en = -1
max_len_ch = -1
dir_saved = "./datas"
cn_path = os.path.join(dir_saved, "cmn_chinese.txt")
en_path = os.path.join(dir_saved, "cmn_english.txt")
with open(cn_path, "w", encoding="utf-8") as f1, open(en_path, "w", encoding="utf-8") as f2:
for i in range(n):
en_sentence = "\t".join(English_sentences[i])
ch_sentence = "\t".join(Chinese_sentences[i])
f1.write(ch_sentence + "\n")
f2.write(en_sentence + "\n")
max_len_en = max(max_len_en, len(English_sentences[i]))
max_len_ch = max(max_len_ch, len(Chinese_sentences[i]))
print(f"Max length of English sentence: {max_len_en}")
print(f"Max length of Chinese sentence: {max_len_ch}")保存到文件

处理好的句子分词的文件:
cmn.txt的中文句子经过jieba分词得到的结果存放的文件![]() https://download.csdn.net/download/qq_61784003/90217428
https://download.csdn.net/download/qq_61784003/90217428
cmn.txt的英文句子经过分词、转为小写处理得到的结果存放的文件![]() https://download.csdn.net/download/qq_61784003/90217431
https://download.csdn.net/download/qq_61784003/90217431
训练数据集获取
上述程序仅供参考,本文提供处理好的分词结果文件cmn_chinese.txt和cmn_english.txt,可直接跳过上述步骤使用处理好的文件。
上述处理得到的还是字符串形式的数据,接下来需要转换为模型可以学习的数学表达的形式。
从保存了已分词的句子语料库文件中读取数据
本文以英汉翻译为例,所以源语言、目标语言分别为英语、汉语。
import os
import numpy as np
# 定义数据集
class CmnDataset:
def __init__(self, data_path: str):
self.data_path = data_path
self.en_sents = []
self.cn_sents = []
self.load_data()
def load_data(self):
cn_path = os.path.join(self.data_path, "cmn_chinese.txt")
en_path = os.path.join(self.data_path, "cmn_english.txt")
sign_split = '\t'
with open(cn_path, "r", encoding="utf-8") as f:
for line in f:
self.cn_sents.append(line.strip().split(sign_split))
with open(en_path, "r", encoding="utf-8") as f:
for line in f:
self.en_sents.append(line.strip().split(sign_split))
assert len(self.en_sents) == len(self.cn_sents), "The number of English and Chinese sentences is not equal."
def __len__(self):
return len(self.en_sents)
def __getitem__(self, idx):
"""返回索引为idx的英文和中文句子"""
return self.en_sents[idx], self.cn_sents[idx]
def get_src2trg(self, language_src='en'):
"""返回源序列和目标序列"""
if language_src == 'en':
return self.en_sents, self.cn_sents
else:
return self.cn_sents, self.en_sents
# 定义数据集路径
data_path = "./datas"
# 实例化数据集
datasets = CmnDataset(data_path)
# 尝试打印数据集中的数据
for en_sent, cn_sent in datasets:
print("en_sent:", en_sent)
print("cn_sent:", cn_sent)
break构造词典(词汇表)
将每个词元映射到从0开始的数字索引中(为节约存储空间,可过滤掉词频低的词元),词元和数字索引所构成的集合叫做词典(vocabulary)。另外,词典需要加入一些特殊词元(开始、结束、填充、未知填充符),这里使用了4个特殊词元:
<unk>:未知词元(unknown),将出现次数少于一定频率的单词统一判定为未知词元;
<bos>:起始词元(begin of sentence),用来标注一个句子的开始;
<eos>:结束词元(end of sentence),用来标注一个句子的结束;
<pad>:填充词元(padding),当句子长度不够时将句子填充至统一长度;
以“What are you doing? Where are you going?”为例,该语料库生成的词典(含特殊词元)可以为:
{"<pad>": 0, "<bos>": 1, "<eos>": 2, "<unk>": 3, "are": 4, "you": 5, "?": 6, "where": 7, "what": 8, "going": 9, "doing": 10}
代码实现:
class Vocab:
"""通过词频字典,构建词典"""
special_tokens = ['<pad>', '<bos>', '<eos>','<unk>']
def __init__(self, dict_word2count: dict, min_freq=1):
"""
:param dict_word2count: 字典,key为词元,value为词频
:param min_freq: 指定需要保留的词频最小值
"""
self.word2idx = {}
for idx, tok in enumerate(self.special_tokens):
self.word2idx[tok] = idx
# 根据词频构建词典,过滤掉词频低于min_freq的词元
dict_word2count = {
w: c
for w, c in dict_word2count.items() if c >= min_freq
}
# 将词典中的词元和数字索引进行映射,得到词元到数字索引的映射(关键点)
idx = len(self.word2idx) # 比如有4个特殊词元,那么从第5个开始就是普通词元(数字索引为4开始)
for w in dict_word2count.keys():
self.word2idx[w] = idx
idx += 1
# 将词典中的词元和数字索引进行反转,得到数字索引到词元的映射
self.idx2word = {idx: word for word, idx in self.word2idx.items()}
self.bos_idx = self.word2idx['<bos>']
self.eos_idx = self.word2idx['<eos>']
self.pad_idx = self.word2idx['<pad>']
self.unk_idx = self.word2idx['<unk>']
def _word2idx(self, word):
"""单词映射至数字索引"""
if word not in self.word2idx:
return self.unk_idx
return self.word2idx[word]
def _idx2word(self, idx):
"""数字索引映射至单词"""
if idx not in self.idx2word:
raise ValueError('input index is not in vocabulary.')
return self.idx2word[idx]
def encode(self, word_or_words):
"""将单个单词或单词数组映射至单个数字索引或数字索引数组"""
if isinstance(word_or_words, list) or isinstance(word_or_words, np.ndarray):
return [self._word2idx(i) for i in word_or_words]
return self._word2idx(word_or_words)
def decode(self, idx_or_idxs):
"""将单个数字索引或数字索引数组映射至单个单词或单词数组"""
if isinstance(idx_or_idxs, list) or isinstance(idx_or_idxs, np.ndarray):
return [self._idx2word(i) for i in idx_or_idxs]
return self._idx2word(idx_or_idxs)
def __len__(self):
return len(self.word2idx)
# 使用collections中的Counter和OrderedDict统计英/汉语每个单词在整体文本中出现的频率。
# 构建词频字典,然后再将词频字典转为词典。
# 其中,收录所有源语言词元的词典为src_vocab,收录所有目标语言词元的词典为tgt_vocab。
# 在分配数字索引时有一个小技巧:常用的词元对应数值较小的索引(即词频越大的单词的索引越小),这样可以节约空间。为什么?
# Counter:这是一个用于计数的字典子类,可以快速统计可哈希对象的出现次数。
# OrderedDict:这是一个保留插入顺序的字典,可以高效地按插入顺序保存键值对。
from collections import Counter, OrderedDict
def build_vocab(dataset: CmnDataset):
# 源/目标语言单词的列表,用于存放组成句子的词元(会存放重复的词元,便于词频统计)
src_words, tgt_words = [], []
for src, trg in zip(*dataset.get_src2trg(language_src='en')): # 将句子中的单词拆分为词元,并添加到列表中
src_words.extend(src)
tgt_words.extend(trg)
# 使用 Counter 统计 src_words 和 tgt_words 中每个单词的出现频率,并将结果转换为元组列表
# 即Counter(src_words).items()的结果为 [(词元1, 词元1的词频), (词元2, 词元2的词频), ...]
src_count_dict = OrderedDict(sorted(Counter(src_words).items(), key=lambda t: t[1], reverse=True))
tgt_count_dict = OrderedDict(sorted(Counter(tgt_words).items(), key=lambda t: t[1], reverse=True))
return Vocab(src_count_dict, min_freq=2), Vocab(tgt_count_dict, min_freq=2)
src_vocab, trg_vocab = build_vocab(datasets)
print('Unique tokens in src vocabulary:', len(src_vocab))
print('Unique tokens in tgt vocabulary:', len(trg_vocab))输出:
Unique tokens in src vocabulary: 4456
Unique tokens in tgt vocabulary: 8013
可以通过IDE的调试功能看看处理得到的两个vocab对象的数据(重点是其中的id2word和word2id两个字典对象):
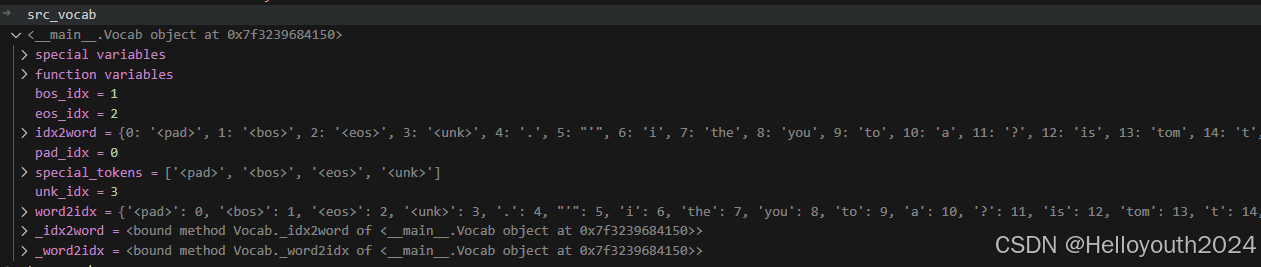

通过Vocab创建词典后,我们可以实现词元与数字索引之间的互相转换。我们可以通过调用enocde函数,返回输入词元或者词元序列对应的数字索引或数字索引序列,反之亦然,我们同样可以通过调用decode函数,返回输入数字索引或数字索引序列对应的词元或词元序列。
使用collections中的Counter和OrderedDict统计英/汉语每个单词在整体文本中出现的频率。构建词频字典,然后再将词频字典转为词典。其中,收录所有源语言词元的词典为src_vocab,收录所有目标语言词元的词典为tgt_vocab。
提出疑问Q1:实际代码实现中,会在分配数字索引时遵循一个原则:常用的词元对应数值较小的索引(即词频越大的单词的索引越小),也即上述代码中的OrderedDict(sorted(Counter(src_words).items(), key=lambda t: t[1], reverse=True))的操作,为什么?
创建模型训练用的数据迭代器dataloader
将翻译句子对(英语-中文)分别转为数字序列,所转换后的序列对构建为数据加载器并设置分批操作。主要操作:
-
字符串单词转为数字表示后,整个句子前后分别添加开始和结束标识符的数字索引表示;
-
源序列/目标序列会统一输入长度为max_len,对于个别长度超出max_len - 2的序列其实会先进行截断再进行①中的操作(可以通过提前获得最长序列的长度l_max,并将max_len设置为l_max + 2以避免这个操作);
-
对于长度不满max_len - 2的序列,再添加开始、结束标志后,会继续在序列末尾填充若干的填充pad标识以使最终的序列的长度为max_len。
pytorch代码:
import torch
from torch.utils.data import Dataset, DataLoader
class CmnTranslationDataset(Dataset):
def __init__(self, dataset: CmnDataset, src_vocab: Vocab, tgt_vocab: Vocab, max_len=50):
self.dataset = dataset
self.src_vocab = src_vocab
self.tgt_vocab = tgt_vocab
self.max_len = max_len
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
src_sent, tgt_sent = self.dataset[idx]
# 将句子转换为索引序列
src_indexes = self.src_vocab.encode(src_sent)
tgt_indexes = self.tgt_vocab.encode(tgt_sent)
# 截断句子,使其长度不超过最大长度
seq_len_max = self.max_len - 2
src_indexes = src_indexes[:seq_len_max]
tgt_indexes = tgt_indexes[:seq_len_max]
# 添加起始和结束标记,并对句子进行填充
src_indexes = [self.src_vocab.bos_idx] + src_indexes + [self.src_vocab.eos_idx]
tgt_indexes = [self.tgt_vocab.bos_idx] + tgt_indexes + [self.tgt_vocab.eos_idx]
num_pad = self.max_len - len(src_indexes)
if num_pad > 0:
src_indexes = src_indexes + [self.src_vocab.pad_idx] * num_pad
num_pad = self.max_len - len(tgt_indexes)
if num_pad > 0:
tgt_indexes = tgt_indexes + [self.tgt_vocab.pad_idx] * num_pad
return {
'src_indexes': torch.tensor(src_indexes, dtype=torch.long),
'tgt_indexes': torch.tensor(tgt_indexes, dtype=torch.long)
}
if __name__ == '__main__':
# 实例化数据集
translation_dataset = CmnTranslationDataset(datasets, src_vocab, trg_vocab)
# 创建DataLoader实例
batch_size = 32
dataloader = DataLoader(translation_dataset, batch_size=batch_size, shuffle=True)
# 测试数据加载器
for batch in dataloader:
print(batch['src_indexes'].shape, batch['tgt_indexes'].shape)
break # 只打印一个批次的数据输出:
torch.Size([32, 50]) torch.Size([32, 50])
下一篇预告:Transformer学习与基础实验4——transformer应用举例演示——英汉翻译(2. 模型搭建、训练、推理)
关注微信公众号——分享之心,后台回复:Transformer,获取该系列实验的所有源码(包含mindspore和pytorch两个框架的版本)、文档、模型结构图(部分帮助理解的流程图)文件(.drawio文件、PPT文件)。
注:对于源码,部分源文件中的“通过sys模块添加系统路径使得可以正确加载自定义的模块”部分需要根据实际运行机器的路径进行修改,本地安装好第三方依赖包(如pytorch、jieba等)后可以直接运行。


技术共进,成长同行——讯飞AI开发者社区
更多推荐


 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)