
opencv 叠加两张图_利用OpenCV 识别两张相似的图片
Background:在我们项目中,用到U-net,我们对训练样本图片使用labelme进行标定,对标定生成的json文件labelme_json_to_dataset生成标注图像,由于小伙伴将生成标注图像文件夹(如图1)里的图1:蓝框-转换后的图片图2:红框原始图片蓝框里的图片(看起来和原始图片一模一样,后来发现其每个pixel对应的RGB值相较于原始图片都发生了变化)替换了原始未标注前的图片(
Background:
在我们项目中,用到U-net,我们对训练样本图片使用labelme进行标定,对标定生成的json文件labelme_json_to_dataset生成标注图像,由于小伙伴将生成标注图像文件夹(如图1)里的
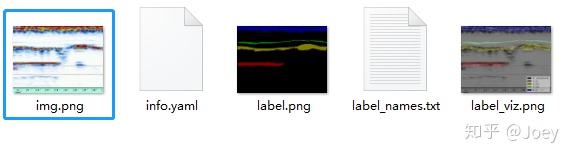
蓝框里的图片(看起来和原始图片一模一样,后来发现其每个pixel对应的RGB值相较于原始图片都发生了变化)替换了原始未标注前的图片(图2:红框里图片),导致我们没办法判别蓝框内图片的具体类,由于图片太多,人工去一一比对,耗时耗力(主要是因为懒QAQ),我们就准备用蓝框里的图片和每个类别里的原始图片进行一一比对(如果相似,则原始图片的类别也是蓝色框内图片的类别),但是由于蓝框内图片相较于原始图片像素值有了较大的改变(具体像素值变化很小,所以看起来和原始图片一模一样),没办法通过比较像素值来判断图片是否相似,故我们想尝试其他的方法去识别两张相识的图片,然后我看到了这个
Python+Opencv识别两张相似图片-CDA数据分析师官网cda.pinggu.org
里面介绍了四种方法识别两张相似图片。
在图像识别中,HOG特征,LBP特征,Haar特征[1],颜色特征,纹理特征,形状特征,空间关系特征等,都可以用来描述图片。
一些概念:
- 图像指纹:就是将图像按照一定的哈希算法,经过运算后得出的一组二进制数字。可以想象成人的指纹。
- 汉明距离[2]:就是一组二进制数据变成另一组二进制数据所需的步骤数。如:101到100的汉明距离就是1
- 平均哈希法(aHash)
此算法基于比较灰度图每个像素与平均值来实现。
具体步骤如下:
- 缩放图片,一般大小为8*8,64个像素值
- 转化为灰度图
- 计算平均值:计算灰度处理后图片所有像素点的平均值(可直接使用numpy中的mean()计算)
- 比较像素灰度值:遍历灰度图每个像素,如果高于平均值记为1,否则为0
- 得到信息指纹:组合64个bit位, 顺序随意保持一致性
2. 感知哈希算法(pHash)
平均哈希算法过于严格,不够精确,更适合搜索缩略图,为了获得更精确的结果可以选择感知哈希算法,它采用的是DCT(离散余弦变换)来降低频率的方法。
具体步骤如下:
- 缩小图片:32 * 32是一个较好的大小,这样方便DCT计算
- 转化为灰度图
- 计算DCT:利用Opencv中提供的dct()方法,注意输入的图像必须是32位浮点型,所以先利用numpy中的float32进行转换
- 缩小DCT:DCT计算后的矩阵是32 * 32,保留左上角的8 * 8,这些代表的图片的最低频率
- 计算平均值:计算缩小DCT后的所有像素点的平均值
- 进一步减小DCT:大于平均值记录为1,反之记录为0
- 得到信息指纹:组合64个信息位,顺序随意保持一致性
- 最后比对两张图片的指纹,获得汉明距离即可
3. 直方图计算法
计算两张图相应直方图的重合度
计算方法如下:
其中
代码如下:
import cv2
import numpy as np
import os
from matplotlib import pyplot as plt
def classify_gray_hist(image1, image2, size=(256, 256)):
image1 = cv2.resize(image1, size)
image2 = cv2.resize(image2, size)
hist1 = cv2.calcHist([image1], [0], None, [256], [0.0, 255.0])
hist2 = cv2.calcHist([image2], [0], None, [256], [0.0, 255.0])
plt.plot(range(256), hist1, 'r')
plt.plot(range(256), hist2, 'b')
plt.show()
#计算直方图的重合度
degree = 0
for i in range(len(hist1)):
if hist1[i] != hist2[i]:
degree = degree + (1 + abs(hist1[i] - hist2[i]) / max(hist1[i], hist2[i]))
else:
degree = degree + 1
degree = degree / len(hist1)
return degree
# 计算单通道的直方图的相似值
def calculate(image1,image2):
hist1 = cv2.calcHist([image1],[0],None,[256],[0.0,255.0])
hist2 = cv2.calcHist([image2],[0],None,[256],[0.0,255.0])
# 计算直方图的重合度
degree = 0
for i in range(len(hist1)):
if hist1[i] != hist2[i]:
degree = degree + (1 - abs(hist1[i] - hist2[i]) / max(hist1[i], hist2[i]))
else:
degree = degree + 1
degree = degree/len(hist1)
return degree
# 通过得到每个通道的直方图来计算相似度
def classify_hist_with_split(image1,image2,size = (256,256)):
# 将图像resize后,分离为三个通道,再计算每个通道的相似值
image1 = cv2.resize(image1,size)
image2 = cv2.resize(image2,size)
sub_image1 = cv2.split(image1)
sub_image2 = cv2.split(image2)
sub_data = 0
for im1,im2 in zip(sub_image1,sub_image2):
sub_data += calculate(im1,im2)
sub_data = sub_data/3
return sub_data
# 平均哈希算法计算
def classify_aHash(image1,image2):
image1 = cv2.resize(image1, (8, 8))
image2 = cv2.resize(image2, (8, 8))
gray1 = cv2.cvtColor(image1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(image2, cv2.COLOR_BGR2GRAY)
hash1 = getHash(gray1)
hash2 = getHash(gray2)
return Hamming_distance(hash1, hash2)
# 感知哈希算法
def classify_pHash(image1,image2):
image1 = cv2.resize(image1, (32, 32))
image2 = cv2.resize(image2, (32, 32))
gray1 = cv2.cvtColor(image1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(image2, cv2.COLOR_BGR2GRAY)
# 将灰度图转为浮点型,再进行dct变换
dct1 = cv2.dct(np.float32(gray1))
dct2 = cv2.dct(np.float32(gray2))
# 取左上角的8*8,这些代表图片的最低频率
# 这个操作等价于c++中利用opencv实现的掩码操作
# 在python中进行掩码操作,可以直接这样取出图像矩阵的某一部分
dct1_roi = dct1[0:8, 0:8]
dct2_roi = dct2[0:8, 0:8]
hash1 = getHash(dct1_roi)
hash2 = getHash(dct2_roi)
return Hamming_distance(hash1, hash2)
# 输入灰度图,返回hash
def getHash(image):
avreage = np.mean(image)
hash = []
for i in range(image.shape[0]):
for j in range(image.shape[1]):
if image[i, j] > avreage:
hash.append(1)
else:
hash.append(0)
return hash
# 计算汉明距离
def Hamming_distance(hash1,hash2):
num = 0
for index in range(len(hash1)):
if hash1[index] != hash2[index]:
num += 1
return num
if __name__ == "__main__":
path1 = r"C:UserschenxuDesktopimageimage_25.png"
path2 = r"C:UserschenxuDesktopori_matchcold_welding"
file_lst = os.listdir(path2)
image_total = len(file_lst)
image1 = cv2.imread(path1)
for image_num in range(1,image_total+1):
addr2 = path2 + "/" + str(image_num) + ".png"
image2 = cv2.imread(addr2)
# degree = classify_gray_hist(image1, image2)
# degree = classify_hist_with_split(image1, image2)
# degree = classify_aHash(image1, image2) #平均哈希算法计算
degree = classify_pHash(image1, image2)
print(image_num)
print("-----")
print(degree)
print("================")经过反复的实验,发现对于我的需求,使用平均哈希法(aHash)效果最好,下面是针对我们的需求具体的代码:
import csv
import glob
import os
import cv2
import numpy as np
try:
from scipy.misc import imread
except ImportError:
from imageio import imread
root_dir_1 = "C:/Users/chenxu/Desktop/image" #目录1:无标签数据
root_dir_2 = "C:/Users/chenxu/Desktop/ori_match/" #目录2:有标签数据
suffix = ".png"
target_lst = []
token2target = {}
data = []
# 平均哈希算法计算
def classify_aHash(image1,image2):
image1 = cv2.resize(image1, (8, 8))
image2 = cv2.resize(image2, (8, 8))
gray1 = cv2.cvtColor(image1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(image2, cv2.COLOR_BGR2GRAY)
hash1 = getHash(gray1)
hash2 = getHash(gray2)
return Hamming_distance(hash1, hash2)
def classify_pHash(image1,image2):
image1 = cv2.resize(image1, (32, 32))
image2 = cv2.resize(image2, (32, 32))
gray1 = cv2.cvtColor(image1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(image2, cv2.COLOR_BGR2GRAY)
# 将灰度图转为浮点型,再进行dct变换
dct1 = cv2.dct(np.float32(gray1))
dct2 = cv2.dct(np.float32(gray2))
# 取左上角的8*8,这些代表图片的最低频率
# 这个操作等价于c++中利用opencv实现的掩码操作
# 在python中进行掩码操作,可以直接这样取出图像矩阵的某一部分
dct1_roi = dct1[0:8, 0:8]
dct2_roi = dct2[0:8, 0:8]
hash1 = getHash(dct1_roi)
hash2 = getHash(dct2_roi)
return Hamming_distance(hash1, hash2)
# 输入灰度图,返回hash
def getHash(image):
avreage = np.mean(image)
hash = []
for i in range(image.shape[0]):
for j in range(image.shape[1]):
if image[i, j] > avreage:
hash.append(1)
else:
hash.append(0)
return hash
# 计算汉明距离
def Hamming_distance(hash1,hash2):
num = 0
for index in range(len(hash1)):
if hash1[index] != hash2[index]:
num += 1
return num
if __name__ == "__main__":
file_lst = os.listdir(root_dir_1)
image_nums = len(file_lst) #未标记图片总数
for img_num in range(image_nums):
addr1 = root_dir_1 + '/' + "image_" + str(img_num) + suffix
img_1 = cv2.imread(addr1)
label = 0 #找到相应类别标记位
target_lst = [] #存储对应7种分类对应数字名
for dir_name in glob.glob(os.path.join(root_dir_2, "*")):
target = os.path.split(dir_name)[-1] #依次取每个类别下图片与未分类图片进行比较
if target not in target_lst: #若相似度很高,则将未分类图片标记为此分类图片对应的类别
target_lst.append(target)
token2target[len(target_lst)-1] = target
for img_name in glob.glob(os.path.join(dir_name, "*" + suffix)):
img_2 = cv2.imread(img_name)
degree = classify_aHash(img_1, img_2) #degree越小,相似度越高
num = len(target_lst) - 1
if degree < 3: #degree=0,1,2,若限制degree=0,会有很多图片无法匹配到相应类别
d1 = tuple(str(num))
data.append(d1)
label = 1
break
if label == 1:
break
if label == 0:
d2 = tuple("N") #如果没发现相应的分类,则标记为N
data.append(d2)
print(data)
print(token2target)
print(data)
#将生成data导出为CSV
with open("./pic_match.csv", "w", newline="", encoding='utf-8-sig') as datacsv:
csvwriter = csv.writer(datacsv, dialect=("excel"))
csvwriter.writerows(data)参考
- ^https://www.cnblogs.com/ranjiewen/p/5873514.html
- ^https://zh.wikipedia.org/wiki/%E6%B1%89%E6%98%8E%E8%B7%9D%E7%A6%BB

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)