
基于matlab神经网络的车牌识别案例
基于matlab神经网络的车牌识别案例
这是一份课程大作业
完整报告由此下载:
https://download.csdn.net/download/qq_44955826/88215701
一、项目背景
汽车牌照自动识别是现代社会智能交通系统的重要功能,是图像处理和模式识别技术研究的热点,在停车场按时计费,小区门禁、交通违章抓拍等领域具有非常广泛的应用。
同时汽车牌照自动识别技术也属于有规范标准的特定字符识别技术(如:身份证号码识别,快递地址识别)(反例:手写字符识别)中的一种,对其的研究也可以促进有规范标准的特定字符识别技术的发展。
二、理论基础
1、车牌定位
车牌区域具有明显的特点(见下方的车牌尺寸图),因此可以根据车牌的颜色、字体、形状等信息进行车牌定位。本案例采用彩色像素点统计的方法分割出合理的车牌区域。下面以蓝底白字的普通车牌为例说明彩色像素点统计的分割方法:
假设经拍摄采集得到了包含车牌的RGB彩色图像,水平方向记为y,垂直方向记为x,则:首先,确定车牌底色RGB各分量分别对应的颜色范围;其次,在y方向统计此颜色范围内的像素点数量,设定合理的阈值,确定车牌在y 方向的合理区域;然后,在分割出的y方向区域内统计x方向此颜色范围内的像素点数量,设定合理的阈值进行定位;最后,根据x、y方向的范围来确定车牌区域实现定位。这其中阈值的设定是关键,但往往采用试错法,由经验确定。
2、图像处理
-
图像灰度化
车牌图像的采集一般是通过数码相机或者摄像机来进行,得到的图片一般是RGB图像,即真彩图像。根据三基色原理,每一种颜色都可以由红、绿、蓝三种基色按不同的比例构成,所以车牌图像的每个像素都由3个数值来指定红、绿、蓝的颜色分量。灰度图像实际上是一个数据矩阵I,该矩阵每个元素的数值代表一定范围内的亮度值,矩阵I可以是整型也可以是双精度,通常0代表黑色,255代表白色。在MATLAB中,一幅RGB图像可以用uint8、uintl6或者双精度等类型的mxnx3矩阵来描述,其中m和n分别表示图像的宽度和高(长)度。
在RGB模型中,如果R=G=B,则表示一种灰度颜色。其中,R=G=B的值叫做灰度值, 由彩色转为灰度的过程叫作图像灰度化处理。因此,灰度图像是指只有强度信息而没有颜色信息的图像。一般而言,可采用加权平均值法对原始RGB图像进行灰度化处理,该方法的主要思想是从原图像中取R、G、B各层像素值经加权求和得到灰度图的亮度值。在现实生活中,人眼对绿色(G)敏感度最高,对红色(R)敏感度次之,对蓝色(B)敏感度最低,因此为了选择合适的权值对象使之能够输出合理的灰度图像,权值系数应该满足 G>R>B。实验和理论证明,当R、G、B的权值系数分别选择0.299、0.587和0.114时,能够得到最适合人眼观察的灰度图像。
-
图像二值化
灰度图像二值化在图像处理的过程中有着很重要的作用,图像二值化处理不仅能使数据量大幅减小,还能突出图像的目标轮廓,便于进行后续的图像处理与分析。对车牌灰度图像而言,所谓的二值化处理就是将其像素点的灰度值设置为0或255,从而让整幅图片呈现非黑既白的效果。因此,对灰度图像进行适当的阈值选取,可以在图像二值化的过程中保留某些关键的图像特征。在车牌图像二值化的过程中,灰度大于或等于阈值的像素点被判定为目标区域,其灰度值用255表示;否则这些像素点被判定为背景或噪声而排除在目标区域以外,其灰度值用0表示。
图像二值化是指在整幅图像内仅保留黑、白二值的数值矩阵,每个像素取两个离散数值(0或1)之一,其中0代表黑色,1代表白色。
在车牌图像处理系统中,进行图像二值过程的关键是选择合适的阈值,使得车牌字符与背景能够得到有效分割。不同的阈值设定方法对车牌图像进行处理也会产生不同的二值化处理结果:阈值设置得过小,则容易误分割,产生噪声,影响二值变换的准确度;阈值设置得过大,则容易过分割,降低分辨率,使非噪声信号被视为噪声而被过滤,造成二值变换的目标损失。
-
图像滤波处理
图像滤波能够在尽量保留图像细节特征的条件下对噪声进行抑制,是图像预处理的常用操作之一,其处理效果的好坏将直接影响后续图像分割和识别的有效性和稳定性。
均值滤波也称为线性滤波,是图像滤波最常用的方法之一,采用的主要方法为领域平均法。该方法对滤波像素的位置(x,y)选择一个模板,该模板由其近邻的若干像素组成,求出模板中所包含像素的均值,再把该均值赋予当前像素点(x,y),将其作为处理后的图像在该点上的灰度值g(x,y),即![]() ,M为该模板中包含当前像素在内的像素总个数。采集车牌图像的过程往往会受到多种噪声的污染,进而会在将要处理的车牌图像上呈现一些较为明显的孤立像素点或像素块。在一般情况下,在研究目标车牌时所出现的图像噪声都是无用的信息,而且还会对目标车牌的检测和识别造成干扰,极大地降低了图像质量,影响图像增强、图像分割、特征提取、图像识别等后继工作的进行。因此,在程序实现中为了能有效地进行图像去噪,并且能有效地保存目标车牌的形状、大小及特定的几何和拓扑结构特征,本案例采用均值滤波来对车牌图像进行去噪处理。
,M为该模板中包含当前像素在内的像素总个数。采集车牌图像的过程往往会受到多种噪声的污染,进而会在将要处理的车牌图像上呈现一些较为明显的孤立像素点或像素块。在一般情况下,在研究目标车牌时所出现的图像噪声都是无用的信息,而且还会对目标车牌的检测和识别造成干扰,极大地降低了图像质量,影响图像增强、图像分割、特征提取、图像识别等后继工作的进行。因此,在程序实现中为了能有效地进行图像去噪,并且能有效地保存目标车牌的形状、大小及特定的几何和拓扑结构特征,本案例采用均值滤波来对车牌图像进行去噪处理。
3、字符提取
-
阈值分割原理
阈值分割算法是图像分割中应用场景最多的算法之一。简单地说,对灰度图像进行阈值分割就是先确定一个处于图像灰度取值范围内的阈值。然后将图像中各个像素的灰度值与这个阈值比较,并根据比较的结果将对应的像素划分为两类:像素灰度大于阈值的一类和像素灰度值小于阈值的另一类,灰度值等于阈值的像素可以归入这两类之一。分割后的两类像素一般分属图像的两个不同区域,所以达到了区域分割的目的。由此可见,阀值分割算法主要有以下两个步骤。
(1)确定需要进行分割的阀值。
(2)将阈值与像素点的灰度值比较,以分割图像的像素。
在以上步骤中,确定阈值是分割的关键,如果能确定一个合适的阈值,就可以准确地将图像分割开来。阈值确定后,将阈值与像素点的灰度值比较和分割可对各像素点进行处理,通过分割的结果可直接得到目标图像区域。在选择阈值方法来分割灰度图像时,一般会对图像的灰度直方图分布进行某些分析,或者建立一定的图像灰度模型来进行处理。
-
对车牌阈值化分割
车牌字符图像的分割即将车牌的整体区域分割成单字符区域,以便后续进行识别。车牌字符分割的难点在于字符与噪声粘连,以及字符断裂等因素的影响。均值滤波是典型的线性滤波算法,它是指在图像上对像素进行模板移动扫描,该模板包括了像素周围的近邻区域,通过模板中像素的平均值来代替原来的像素值,实现去噪的效果。为了从车牌图像中直接提取目标字符,最常用的方法是设定一个阀值T,用T将图像 的像素分成两部分:大于T的像素集合和小于T的像素集合,得到二值化图像。因此,本案例采用均值滤波算法来对车牌字符图像进行滤波去噪,采用阈值分割进行车牌字符的分割。
-
字符归一化处理
字符图像归一化是简化计算的方式之一,车牌字符分割后往往会出现大小不一致的情况,因此可采用基于图像放缩的归一化处理方式将字符图像进行尺寸放缩以得到统一大小的字符图像,便于后续的字符识别。
为最大限度上防止伪造车牌,公安部为现行车牌开发了一种特殊字体,以黑体为基本字体进行了一定的改进,使得目前通用的电脑上的任何字体都不与其完全吻合,只在公安交警部门或指定的车牌制作单位的输出设备上可以输出。同时也规定了车牌各部位的尺寸 。这种有规范标准的特定字符极大地降低了字符识别与归一化的复杂度,提高了识别与归一化准确率。
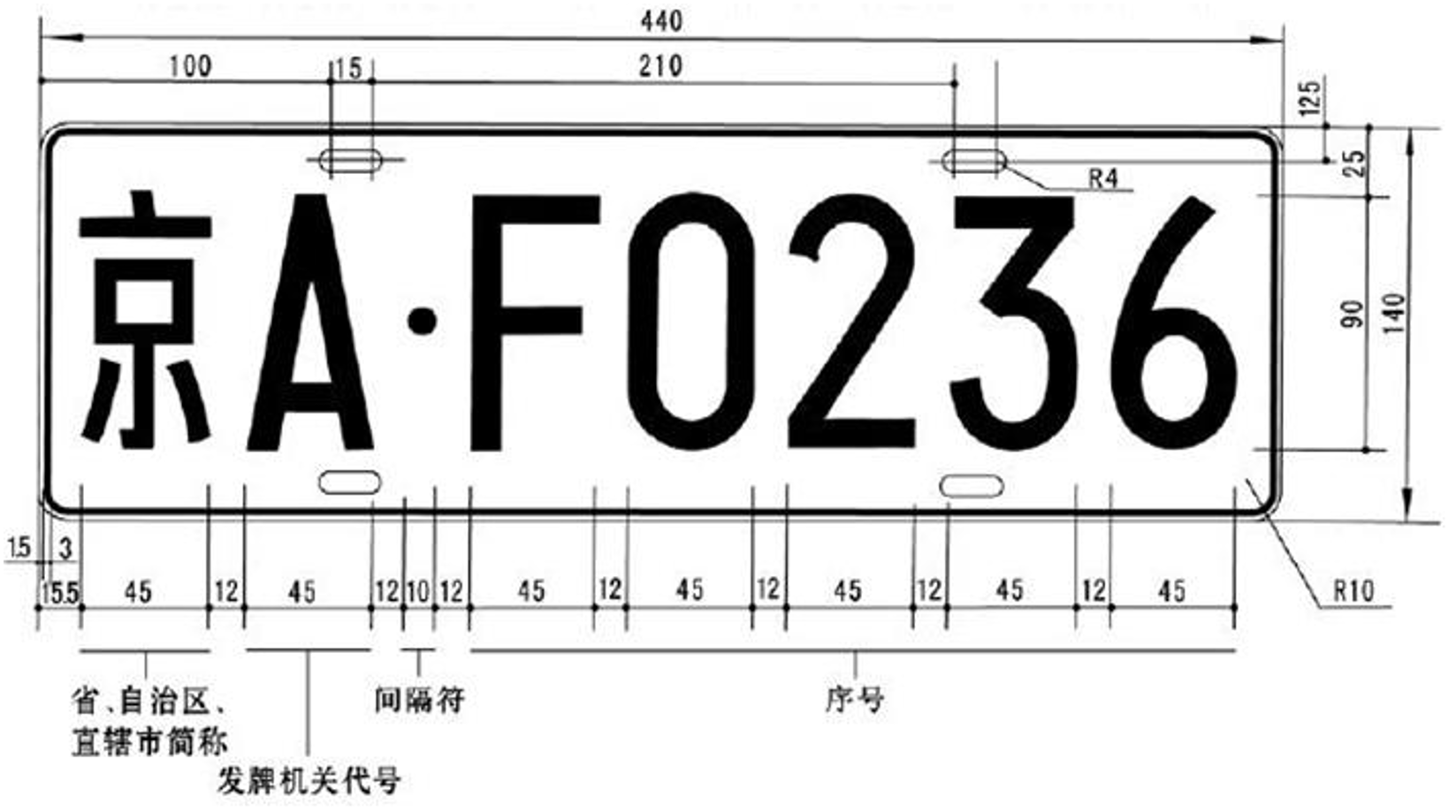
由于车牌上的汉字,字母与数字的大小和比例均相同。本案例在分割出字符之后,将字符的在高度上像素信息用20个像素点表示,以实现归一化。
4、字符识别
车牌字符识别方法基于模式识别理论,常用的有模板匹配和神经网络等方法。
-
模板匹配
模板匹配方法是数字图像处理中的最常用的识别方法之一。该方法将图像看作是一个二维矩阵,通过在待匹配图像上滑动一个预定义的模板,计算每个位置上的像素值与模板像素值之间的相似度,从而找到与模板最匹配的位置。
-
神经网络
神经网络的理论基础源自生物学中神经元的运作方式。神经元接收来自其他神经元的输入信号,并通过细胞体内的复杂计算过程将这些信号加权相加,再通过一个非线性的激活函数(如sigmoid函数)进行处理,最终将结果发送到其他神经元。
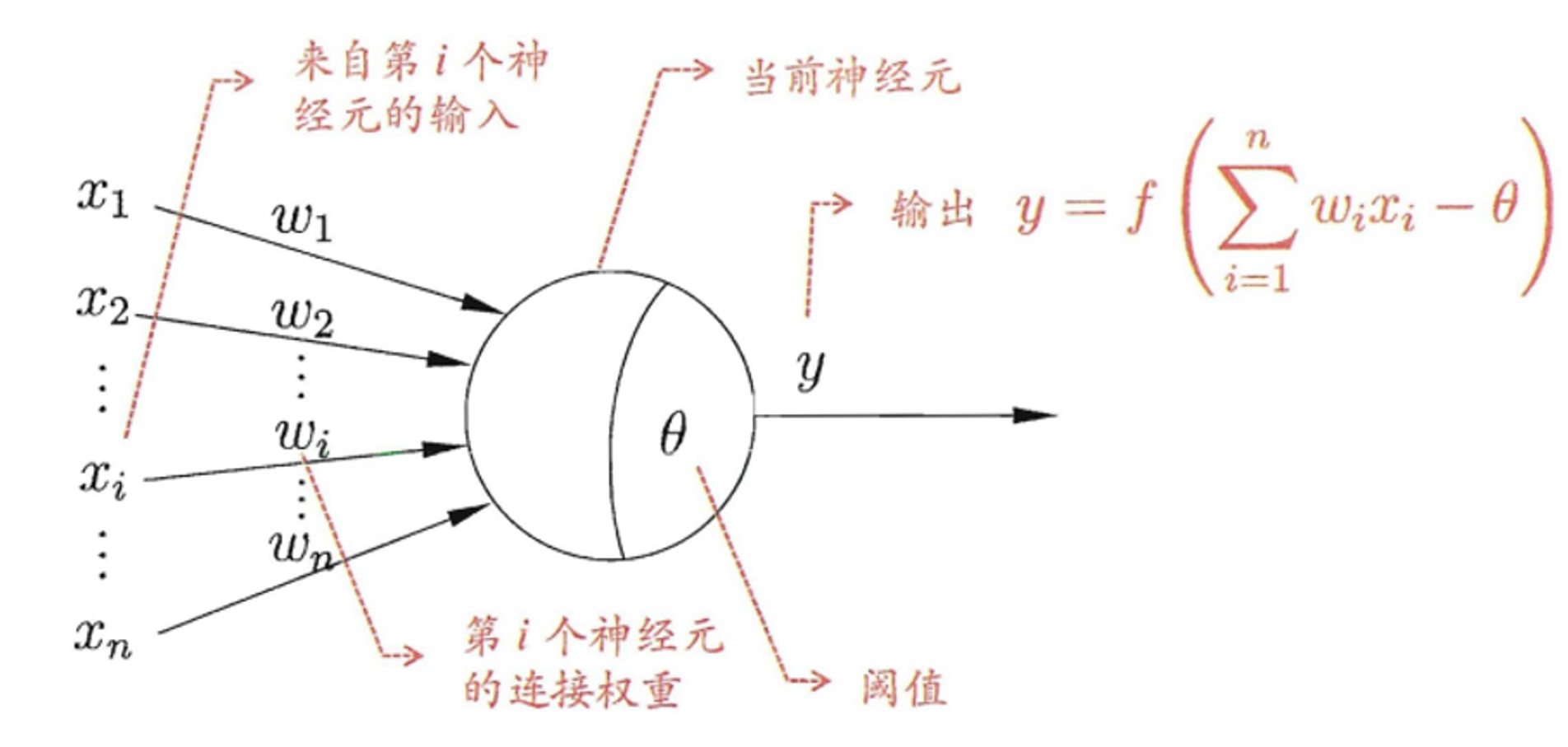
神经网络中的节点(也称为神经元)以及它们之间的连接权重都是从生物神经元的运作过程中得到的灵感。
神经网络的训练依赖于梯度下降算法,该算法通过计算每个节点的输出与实际输出之间的误差,并通过反向传播算法将误差传递回每个节点的输入,用以更新每个节点之间的连接权重。这一过程被称为反向传播算法。
在数学上,神经网络模型可以表示为一系列数学函数的组合,这些函数可以是线性或非线性的,例如加权和函数与激活函数。神经网络模型的目标是最小化预测输出与实际输出之间的误差。通常使用梯度下降或其变体来训练神经网络模型,以最小化损失函数,从而提高模型的准确性和泛化能力。
理论上,神经网络可以处理任何输入输出之间的映射关系。事实上,神经网络是一种通用的函数逼近器,可以逼近任何函数,包括非线性函数。因此,只要有足够多的神经元和适当的权重,神经网络就可以学习任何复杂的映射关系。
然而,在实践中,神经网络的性能受到许多因素的影响,包括网络结构、数据量、数据质量、训练算法等。如果神经网络的结构不合适或训练数据不足或不具代表性,则神经网络可能无法学习准确的映射关系,导致性能下降。
本案例使用BP三层(只含1层隐藏层)前馈神经网络(因为可供训练的已打标签的数据有限,且项目本身属于特定类型的模式识别,并不复杂,所以不需要复杂的神经网络模型)来反映出输入输出之间的映射关系。
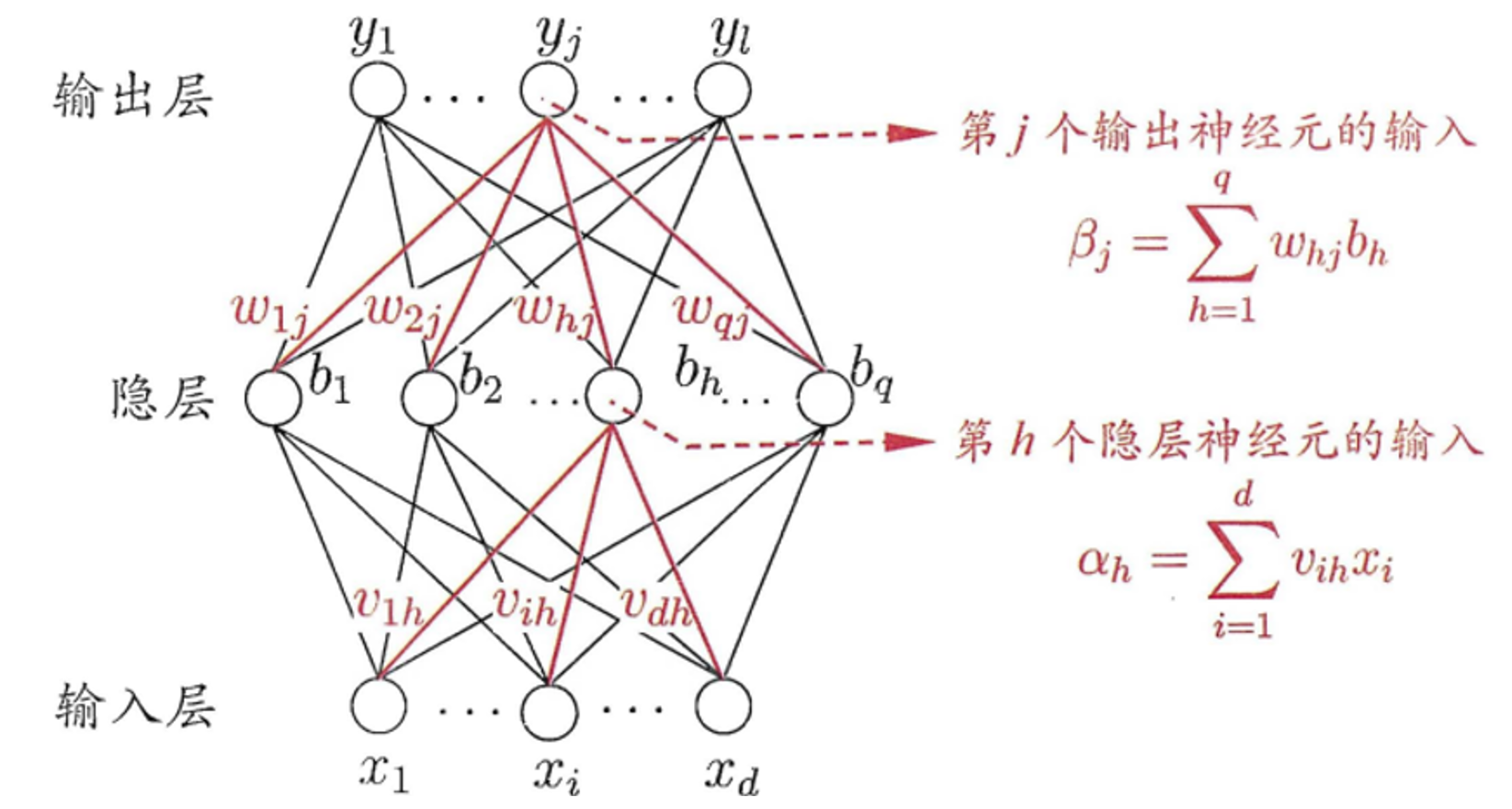
-
特征提取
在训练神经网络前,需要对已打标签的待训练数据进行特征提取。本人查阅相关资料得知目前有两大较为主流的特征提取方法。
一是把图片上的所有像素点都当成一个维度特征。
二是把满足特定规则的像素点信息当成一个维度特征,如下图:
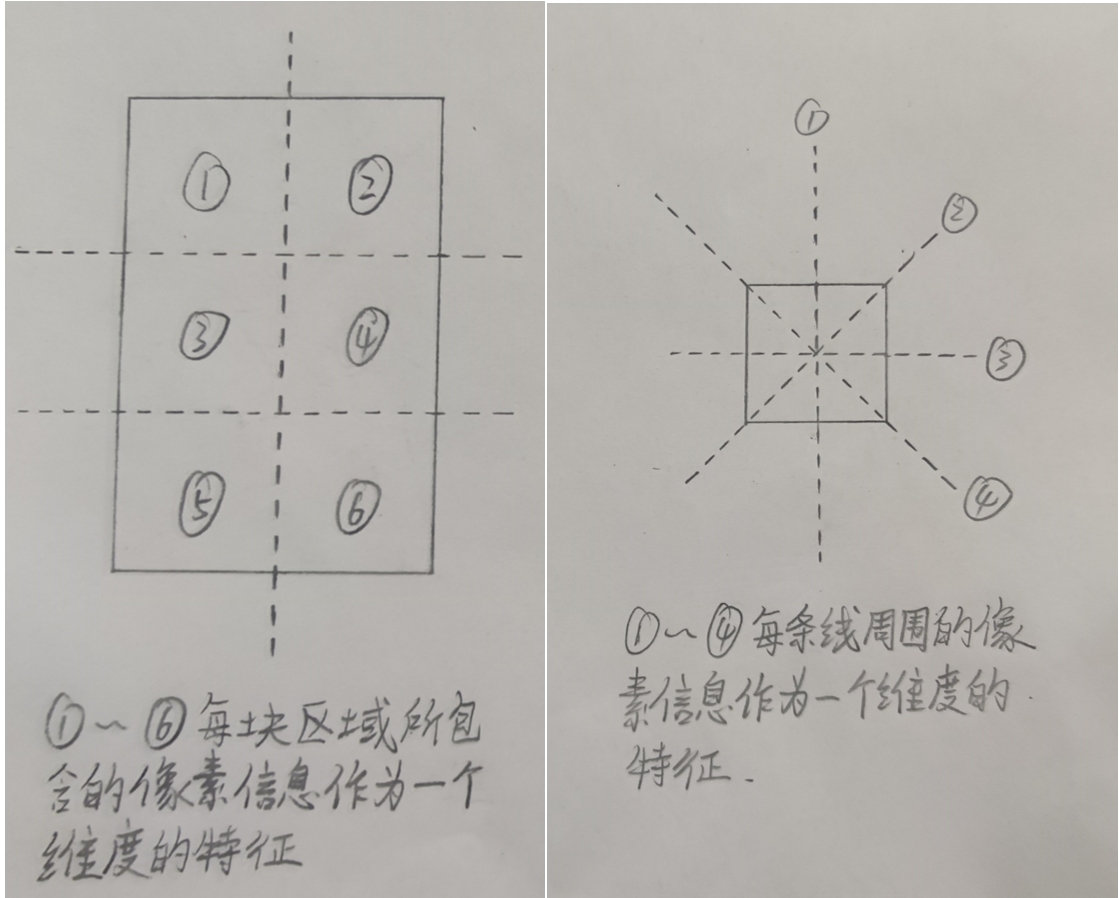
像素信息多种多样,可以根据需求自行选择。比如:R大于150的像素点个数;白色、黑色像素点的比例等。
本案例采用把图片上的所有像素点都当成一个维度特征的特征提取方法(这样可以充分利用图片信息,且不需要写代码提取满足特定规则的像素点信息,减少了工作量)。
三、问题的解决过程和
1、图片与字符的处理
此部分的目的是为了将要识别的带有车牌的汽车图片转化为神经网络可以处理得当的输入数据。
提取车牌→将车牌图转为二值滤波去边图→分割并提取车牌中的汉字、数字和字母→(不改变汉字、字符的长宽比)将汉字、数字和字母变成20行*20列的标准形式→将的20*20的图转换成1*400图
2、样本处理
此部分的目的是为了将样本图片转化为可供神经网络训练的输入和输出(目标)数据。为了提高准确率,将汉字、数字字母分开训练,共训练两个神经网络,每个网络的样本处理过程均如下所示:
载入要进行神经网络训练的样本图片→创建要进行神经网络训练的输入矩阵→创建要进行神经网络训练的输出(目标)矩阵
3、神经网络的训练
此部分主要利用matlab自带的神经网络拟合工具箱
4、车牌识别与显示
输入待识别的图片→得到拟合结果→显示结果
四、算法应用过程
可观看下列演示视频
车牌识别过程
这是待识别的车牌:

%此函数的功能:提取车牌
function [plate, Loc] = Picture_Processing(image, parm, flag)
%image:要处理的汽车图片
%parm:用于计算蓝色像素点的阈值矩阵
%flag:布尔值,是否要显示处理结果
%Plate:只含车牌的图片
%Loc:车牌位置上下和左右界
%参数确定
if nargin < 1 %函数的输入参数小于1个,即没有参数输入
image = imread('car-picture\8d1a9d0c558e9745c3afe4f265923b90.jpeg'); %加载要处理的图片
end
if nargin < 2 || isempty(parm) %函数的输入参数小于2个或者没有指定阈值
if size(image, 2) > 900 %图片的宽度(第2维数据个数)是否大于900像素
parm = [0.35 0.9 90 0.35 0.7 90 2];
end
if size(image, 2) > 700 && size(image, 2) <= 900
parm = [0.6 0.9 90 0.6 0.8 90 0.5];
end
if size(image, 2) > 500 && size(image, 2) <= 700
parm = [0.5 0.54 50 0.6 0.7 50 3];
end
if size(image, 2) <= 500
parm = [0.8 0.9 150 0.8 0.9 150 3];
end
end
if nargin < 3 %函数的输入参数小于3个
flag = 1;
end
%压缩图片
[x, y, ~] = size(image); %~为占位符,表示此处有数据传入但不使用变量接收
if x > 800 %图片的长度大于800个像素
rate = 800/x;
I = imresize(image, rate); %调整图片大小,变为原来的rate倍
[x, y, ~] = size(I);
else
I =image
end
%确定图片蓝色像素点的位置
%我们认为一个像素点满足:RGB当中的B值很大,且相对于B的值,R和G的值较小,它就是蓝色的。
myI = double(I); %变量类型转换(增大小数位数),方便后面的除法运算
bw1 = zeros(x, y);
Blue_x = zeros(x, 1);
for i = 1 : x %按行查询
for j = 1 : y
rij = myI(i, j, 1)/(myI(i, j, 3)+eps); %eps为浮点相对精度(一个极小的正数),此处的作用是防止除数为0
gij = myI(i, j, 2)/(myI(i, j, 3)+eps);
bij = myI(i, j, 3);
if (rij < parm(1) && gij < parm(2) && bij > parm(3)) || (gij < parm(1) && rij < parm(2) && bij > parm(3))
Blue_x(i, 1) = Blue_x(i, 1) + 1; %求出第i行为蓝色的列数,其数值反映出了每一行有多少个蓝色像素点
bw1(i, j) = 1; %保存蓝色像素点的位置
end
end
end
%以颜色(蓝色)定位车牌
[~, MaxX] = max(Blue_x); %~位置传入的是Blue_x的每一列(虽然Blue_x只有一列)的最大值,MaxX保存了Blue_x的每一列最大值的位置
Th = parm(7);
PX1 = MaxX; %我们认为图片中有最多蓝色像素点的行一定在车牌区域里
while ((Blue_x(PX1,1)>Th) && (PX1>1)) %确定车牌上界
PX1 = PX1 - 1;
end
PX2 = MaxX;
while ((Blue_x(PX2,1)>Th) && (PX2<x)) %确定车牌下界
PX2 = PX2 + 1;
end
PX1 = PX1 - 2; %多框出一些
if PX1 < 1 %防止超出图片位置
PX1 = 1;
end
PX2 = PX2 + 2;
if PX2 > x
PX2 = x;
end
IX = I(PX1:PX2, :, :); %保存行过滤结果
bw2 = zeros(x, y);
Blue_y = zeros(1,y);
for j = 1:y %按列查询
for i = PX1:PX2 %利用按行查询结果,减少计算量
rij = myI(i, j, 1)/(myI(i, j, 3)+eps);
gij = myI(i, j, 2)/(myI(i, j, 3)+eps);
bij = myI(i, j, 3);
if (rij < parm(4) && gij < parm(5) && bij > parm(6)) || (gij < parm(4) && rij < parm(5) && bij > parm(6))
Blue_y(1,j) = Blue_y(1,j) + 1;
bw2(i, j) = 1;
end
end
end
PY1 = 1;
while (Blue_y(1,PY1)<Th) && (PY1<y)
PY1 = PY1 + 1;
end
PY2 = y;
while (Blue_y(1,PY2)<Th) && (PY2>PY1)
PY2 = PY2 - 1;
end
PY1 = PY1 - 2;
if PY1 < 1
PY1 = 1;
end
PY2 = PY2 + 2;
if PY2 > y
PY2 = y;
end
IY = I(:, PY1:PY2, :);
plate = I(PX1:PX2, PY1:PY2,:); %保存车牌位置
Loc.row = [PX1 PX2]; %保存车牌位置上下界
Loc.col = [PY1 PY2]; %保存车牌位置左右界
if flag
figure;
subplot(2, 2, 1); imshow(I); title('原图像', 'FontWeight', 'Bold');
subplot(2, 2, 2); imshow(IX); title('行过滤结果', 'FontWeight', 'Bold');
subplot(2, 2, 3); imshow(IY); title('列过滤结果', 'FontWeight', 'Bold');
subplot(2, 2, 4); imshow(plate); title('分割结果', 'FontWeight', 'Bold');
end
end上述代码的结果:

%函数功能:将车牌图转为二值滤波去边图
function result = Colorful_Binary_Filtering_Debounding(plate, flag1)
%Plate:只含车牌的图片
%flag1:是否展示处理过程及结果,1:展示,0:不展示
%result:车牌二值滤波去边图
if nargin < 2 %函数的输入参数小于2个
flag1 = 1;
end
if ndims(plate) == 3 %plate的维数是否是3维,即plate是否为彩图
plate1 = rgb2gray(plate); %将plate转为灰度图
else
plate1 = plate;
end
Im = plate1;
bw = im2bw(Im,0.6); %基于阈值将图像转换为二值图像,阈值默认为0.5,(写一个自动调节阈值的程序????)
h = fspecial('average', 3); %采用平均值滤波,滤波器的大小为3*3的矩阵
bw1 = imfilter(bw, h, 'replicate'); %replicate:数组边界之外的输入数组值假定为等于最近的数组边界值。
mask = imclearborder(bw1); %将把与图像边界相连接的像素全部清除(由1变0,即由白变黑)后的图片存为mask
bw2 = bw1 .* mask; %??????????
result = bw2;
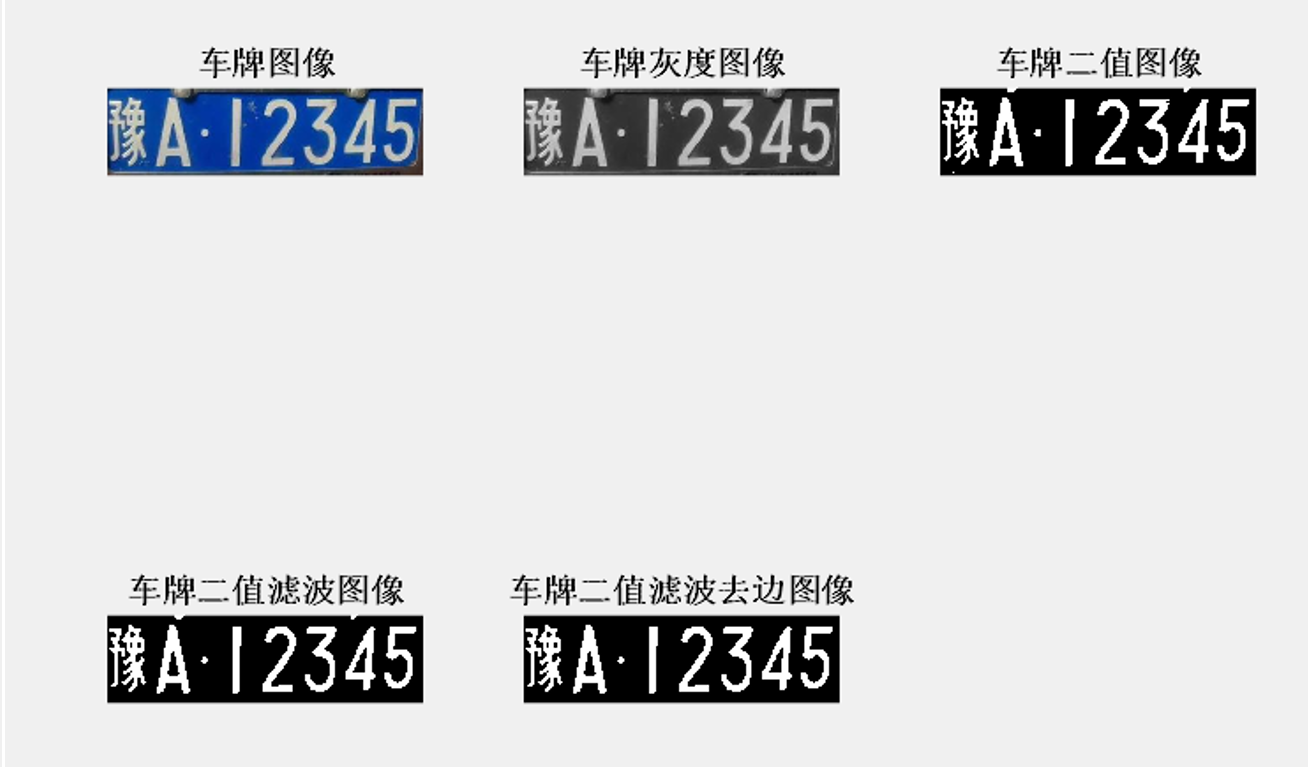
if flag1
subplot(2, 3, 1); imshow(plate); title('车牌图像', 'FontWeight', 'Bold');
subplot(2, 3, 2); imshow(Im); title('车牌灰度图像', 'FontWeight', 'Bold');
subplot(2, 3, 3); imshow(bw); title('车牌二值图像', 'FontWeight', 'Bold');
subplot(2, 3, 4); imshow(bw1); title('车牌二值滤波图像', 'FontWeight', 'Bold');
subplot(2, 3, 5); imshow(bw2); title('车牌二值滤波去边图像', 'FontWeight', 'Bold');
end
end
上述代码的结果:
%函数功能:去除边框(直接删掉边界,注意与前文滤波后的去边区别),使字符撑满整个区域
function e = Segmation(result)
%result:要处理的图片
%e:去除边框后的图片
[m, n] = size(result);
top = 1;
bottom = m;
left = 1;
right = n;
while sum(result(top,:))==0 && top<=m %当当前行没有白色像素且当前行不是最底下一行时,自顶向下追溯
top = top + 1;
end
while sum(result(bottom,:))==0 && bottom>=1 %自底向上追溯
bottom = bottom - 1;
end
while sum(result(:,left))==0 && left<=n
left = left + 1;
end
while sum(result(:,right))==0 && right>=1 %当当前列没有白色像素且当前列不是最左一列时,自右向左追溯
right = right - 1;
end
dd = right - left; %宽度
hh = bottom - top; %高度
e = imcrop(result, [left top dd hh]); %剪裁图像,只保留result中以第left行第top列为起点,宽度为dd高度为hh的部分
end%函数功能:提取车牌中的汉字和数字字母
function [Chinese, characters] = Chinese_Segmation(e)
%e;已去除边框的车牌二值滤波去边图像
%word:车牌汉字图像(已去除边框)
%:result:车牌数字字母(6个连在一起)图像(已去除边框)
Chinese = [];
flag = 1; %标志位,while条件
[m, n] = size(e);
wideTol = round(n/20); %宽度阈值,round:4舍5入
rateTol = 0.25; %???
while flag
wide = 0;
%按列确定一片有白色像素的区域
while sum(e(:,wide+1)) ~= 0 && wide <= n-2 %当没有追溯到图像边界时,从左向右追溯,直到某一列没有白色像素,用wide记录下此刻的位置
wide = wide + 1;
end
temp = Segmation(imcrop(e , [1 1 wide m])); %截取这片有白色像素的区域后,去除边框(虽然整个车牌已去除边框,但这部分不一定已去除边框),存入临时变量temp
[m1,n1] = size(temp);
if wide<wideTol && n1/m1>rateTol %这片有白色像素的区域宽度小且相对其高度大(防止去除掉因前期处理不佳而使汉字或字符不连续的部分),此if是为了去除(用于安装车牌)铆钉的干扰
e(:, 1:wide) = 0; %去除噪点(变黑)
if sum(sum(e)) ~= 0 %此时的e还有白色区域
e = Segmation(e); %要确保图片左边框有白色像素
else %直到最后都没有恰当宽度的白色区域可以被认为是汉字
Chinese = [];
flag = 0; %flag置0,跳出while循环
end
else %这片有白色像素的区域宽度可以被认为是汉字
Chinese = Segmation(imcrop(e, [1 1 wide m]));
e(:, 1:wide) = 0; %将汉字的区域变黑
if sum(sum(e)) ~= 0;
e = Segmation(e); %去除边框后的e就是(6个连在一起)数字字母图像
flag = 0;
else
e = []; %直到最后都没有找到6个连在一起)数字字母所在的区域
end
end
[m, n] = size(e);
end
characters = e;
subplot(2,1,1);imshow(Chinese);title('省份', 'FontWeight', 'Bold');
subplot(2,1,2);imshow(characters);title('字符', 'FontWeight', 'Bold');上述代码的结果:

%函数功能:将提取出的车牌字符串分割成单个字符
%未注释的部分见[Chinese, characters] = Chinese_Segmation(e)
function [c,x,y] = character_Segmation(characters)
%characters:提取出的车牌字符串
%c:存有字符信息的3维数组(前两维为每个字符的行列数据,第三维表示第几个字符)
%x:字符的最后一行在c中的位置
%y:字符的最后一列在c中的位置
[m, n] = size(characters);
c=zeros(m,n,6)
wideTol = round(n/20);
rateTol = 0.25;
flag = 1;
i=1 %字符的次序
x=zeros(1,6)
y=zeros(1,6)
while flag
wide = 0;
while sum(characters(:,wide+1)) ~= 0 && wide <= n-2
wide = wide + 1;
end
temp = Segmation(imcrop(characters , [1 1 wide m]));
[m1,n1] = size(temp);
if wide<wideTol && n1/m1>rateTol
characters(:, 1:wide) = 0;
if sum(sum(characters)) ~= 0
characters = Segmation(characters);
else
flag = 0;
end
else
if i<7
c(1:m1,1:n1,i) = Segmation(imcrop(characters, [1 1 wide m])); %截取这片有白色像素的区域后,去除边框,存入c中对应的位置
x(i)=m1 %保存字符的最后一行在c中的位置
y(i)=n1 %保存字符的最后一列在c中的位置
i=i+1 %即将处理下一个字符
characters(:, 1:wide) = 0; %将字符的区域变黑
else
flag = 0;
end
if sum(sum(characters)) ~= 0;
characters = Segmation(characters);
else
flag = 0;
end
end
[m, n] = size(characters);
end
subplot(2,3,1);imshow(c(1:x(1),1:y(1),1));title('地级行政区', 'FontWeight', 'Bold');
subplot(2,3,2);imshow(c(1:x(2),1:y(2),2));title('第1个字符', 'FontWeight', 'Bold');
subplot(2,3,3);imshow(c(1:x(3),1:y(3),3));title('第2个字符', 'FontWeight', 'Bold');
subplot(2,3,4);imshow(c(1:x(4),1:y(4),4));title('第3个字符', 'FontWeight', 'Bold');
subplot(2,3,5);imshow(c(1:x(5),1:y(5),5));title('第4个字符', 'FontWeight', 'Bold');
subplot(2,3,6);imshow(c(1:x(6),1:y(6),6));title('第5个字符', 'FontWeight', 'Bold');
end
上述代码的结果:

%函数功能:(不改变汉字、字符长宽比)将汉字和字符变成20行*20列的标准形式
function [chin char]=Normalization(Chinese,c,x,y)
%Chinese:汉字图片
%c:存有字符信息的3维数组(前两维为每个字符的行列数据,第三维表示第几个字符)
%x:字符的最后一行在c中的位置
%y:字符的最后一列在c中的位置
%chin:汉字的标准形式
%char:字符的标准形式
char=zeros(20,20,6) %存有标准字符的3维数组(前两维为每个字符的行列数据,第三维表示第几个字符)
for i=1:6
if x(i) ~= 20 || y(i) ~= 20 %图片的长或宽不等于20个像素
if(x(i)>=y(i)) %图片更瘦长
rate = 20/x(i)
I= imresize(c(1:x(i),1:y(i),i), rate); %调整图片大小,变为原来的rate倍;当图片大小不为整数时,向上取整;当输入时黑白二值图时,imresize输出灰度图
%I=im2bw(I,0.5) %后续在用神经网络识别时发现:灰度图的效果要比二值图好
[~,n]=size(I)
char(:,(11-round(n/2)):(10+round(n/2)-(mod(n,2))),i)=I %字符(左右)居中,当为奇数列时,字符偏左一个像素
else %图片更矮胖
rate = 20/y(i)
I= imresize(c(1:x(i),1:y(i),i), rate);
%I=im2bw(I,0.5)
[m,~]=size(I)
char((11-round(m/2)):(10+round(m/2)-(mod(m,2))),:,i)=I %字符(上下)居中,当为奇数列时,字符偏上一个像素
end
else
char(:,:,i) =c
end
end
chin=zeros(20,20)
[w z]=size(Chinese)
if w ~= 20 || z ~= 20
if(w>=z)
rate = 20/w
I= imresize(Chinese, rate);
%I=im2bw(I,0.5)
[~,n]=size(I)
chin(:,(11-round(n/2)):(10+round(n/2)-(mod(n,2))))=I
else
rate = 20/z
I= imresize(Chinese, rate);
%I=im2bw(I,0.5)
[m,~]=size(I)
chin((11-round(m/2)):(10+round(m/2)-(mod(m,2))),:)=I
end
else
chin(:,:,i) =Chinese
end
figure(1)
imshow(chin);title('省级行政区', 'FontWeight', 'Bold');
figure(2)
subplot(2,3,1);imshow(char(:,:,1));title('地级行政区', 'FontWeight', 'Bold');
subplot(2,3,2);imshow(char(:,:,2));title('第1个字符', 'FontWeight', 'Bold');
subplot(2,3,3);imshow(char(:,:,3));title('第2个字符', 'FontWeight', 'Bold');
subplot(2,3,4);imshow(char(:,:,4));title('第3个字符', 'FontWeight', 'Bold');
subplot(2,3,5);imshow(char(:,:,5));title('第4个字符', 'FontWeight', 'Bold');
subplot(2,3,6);imshow(char(:,:,6));title('第5个字符', 'FontWeight', 'Bold');
end
上述代码的结果:

%函数功能:将传入的20*20的二值或灰度图转换成1*400的图
function one_dimensional = two_dimensional2one_dimensional(I)
%I:传入的20*20的二值或灰度图
%one_dimensional:转换成1*400的图
one_dimensional=zeros(1,400);
%将图像按列转换成一个行向量,一列一列的转换
for j=1:20
for i=1:20
one_dimensional(1,20*(j-1)+i)=I(i,j);
end
end%函数功能:载入要进行神经网络训练的样本图片
function image_list=import_imageDatas(flag)
%flag=0加载汉字图片,flag=1加载数字字母图片
%image_path:样本所在的文件夹
%image_list:包含样本图片信息的结构体
if flag
image_path='CharacterDataNormalization\character'
else
image_path='CharacterDataNormalization\Chinese'
end
image_list=dir(fullfile(image_path,'**/*.jpg'));%列出image_path(包括其子文件夹)路径下所有后缀为.jpg的文件
image_num=length(image_list);%获取图片数量
if image_num==0
fprintf('未找到任何图像\n');
else
fprintf('已找到%d张图像\n',image_num);
end
end
%函数功能:创建要进行神经网络训练的车牌省份输入矩阵
function Input_Chinese=input_province_sequence(image_list)
%image_list:包含车牌省份样本图片信息的结构体
%Input_Chinese:车牌省份输入矩阵
image_num=length(image_list);%获取图片数量
Input_Chinese=zeros(image_num,400)%车牌省份输入矩阵共有image_num个样本,每个样本有400个特征
for i=1:image_num
image_name=image_list(i).name;%获取每一张图片名称
folder_name=image_list(i).folder%获取每一张图片所在文件夹的名称
I1=imread(fullfile(folder_name,image_name))
I2=im2bw(I1,0.5)
Input_Chinese(i,:)=two_dimensional2one_dimensional(I2)
end
end%函数功能:创建要进行神经网络训练的车牌省份输出(目标)矩阵
function Output_Chinese =output_province_sequence(image_list)
%image_list:包含车牌省份样本图片信息的结构体
%Output_Chinese:车牌省份输出(目标)矩阵
province=['chuan';'e1666';'gan66';'gan16';'gui66';'gui16';'hei66';'hu666';'ji666';'ji166';'jin66';'jin16';'jing6';'liao6';'lu666';'meng6';'min66';'ning6';'qing6';'qiong';'shan6';'su666';'wan66';'xiang';'xin66';'yu666';'yu166';'yue66';'yun66';'zang6';'zhe66']%按字母顺序创建包含31个省份文件夹名的字符矩阵。每行5个字符(不足5个的后面补'6'),方便之后的字符处理
j=1
image_num=length(image_list);
Output_Chinese=zeros(image_num,31)
for i=1:image_num
folder_name=image_list(i).folder
folder_name_length=length(folder_name)
image_province=[]
while folder_name(folder_name_length)~='\' %文件夹名的最后一个字符不是'\'
image_province=[folder_name(folder_name_length),image_province] %将文件夹名从后往前数的上一个字符提取到此字符前面
folder_name_length=folder_name_length-1
end
while length(image_province) < 5 %文件夹名最后一个'\'后的字符(省份的拼音)个数小于5
image_province=[image_province,'6'] %在后面补'6'
end
while ~strcmp(image_province,province(j,:)) %比较是否是当前的省份
j=j+1 %因为image_list.folder和province都是按字母顺序罗列的,所以当前不相等时,下一个一定相等
end
Output_Chinese(i,j)=1 %在对应省份的位置置1
end%函数功能:创建要进行神经网络训练的车牌数字字母输入矩阵
function Input_character=input_character_sequence(image_list)
%image_list:包含车牌数字字母样本图片信息的结构体
%Input_Chinese:车牌数字字母输入矩阵
image_num=length(image_list);
Input_character=zeros(image_num,400)
for i=1:image_num
image_name=image_list(i).name;
folder_name=image_list(i).folder
I1=imread(fullfile(folder_name,image_name))
I2=im2bw(I1,0.5)
Input_character(i,:)=two_dimensional2one_dimensional(I2)
end
end%函数功能:创建要进行神经网络训练的车牌数字字母输出(目标)矩阵
function Output_character =output_character_sequence(image_list)
%image_list:包含车牌数字字母样本图片信息的结构体
%Output_character:车牌数字字母输出(目标)矩阵
Character=['0';'1';'2';'3';'4';'5';'6';'7';'8';'9';'A';'B';'C';'D';'E';'F';'G';'H';'J';'K';'L';'M';'N';'P';'Q';'R';'S';'T';'U';'V';'W';'X';'Y';'Z'] %按数字字母顺序创建包含10个数字和24个字母(没有i和o)的字符矩阵
j=1
image_num=length(image_list);
Output_character=zeros(image_num,34)
for i=1:image_num
folder_name=image_list(i).folder
folder_name_length=length(folder_name)
while ~strcmp(folder_name(folder_name_length),Character(j,:))
j=j+1
end
Output_character(i,j)=1
end
end%函数功能:训练识别汉字的神经网络
function NN_Chinese=neural_network_Chinese(Input_Chinese,Output_Chinese)
%Input_Chinese:车牌省份输入矩阵
%Output_Chinese:车牌省份输出(目标)矩阵
%NN_Chinese:识别汉字的神经网络结构
% Solve an Input-Output Fitting problem with a Neural Network
% Script generated by Neural Fitting app
% Created 09-Apr-2023 10:00:19
%
% This script assumes these variables are defined:
%
% Input_Chinese - input data.
% Output_Chinese - target data.
x = Input_Chinese';
t = Output_Chinese';
% Choose a Training Function
% For a list of all training functions type: help nntrain
% 'trainlm' is usually fastest.
% 'trainbr' takes longer but may be better for challenging problems.
% 'trainscg' uses less memory. Suitable in low memory situations.
trainFcn = 'trainlm'; % Levenberg-Marquardt backpropagation.
% Create a Fitting Network
hiddenLayerSize = 10;
net = fitnet(hiddenLayerSize,trainFcn);
% Setup Division of Data for Training, Validation, Testing
net.divideParam.trainRatio = 70/100;
net.divideParam.valRatio = 15/100;
net.divideParam.testRatio = 15/100;
% Train the Network
[net,tr] = train(net,x,t);
% Test the Network
y = net(x);
e = gsubtract(t,y);
performance = perform(net,t,y)
% View the Network
view(net)
% Plots
% Uncomment these lines to enable various plots.
%figure, plotperform(tr)
%figure, plottrainstate(tr)
%figure, ploterrhist(e)
%figure, plotregression(t,y)
%figure, plotfit(net,x,t)
NN_Chinese.Network=net
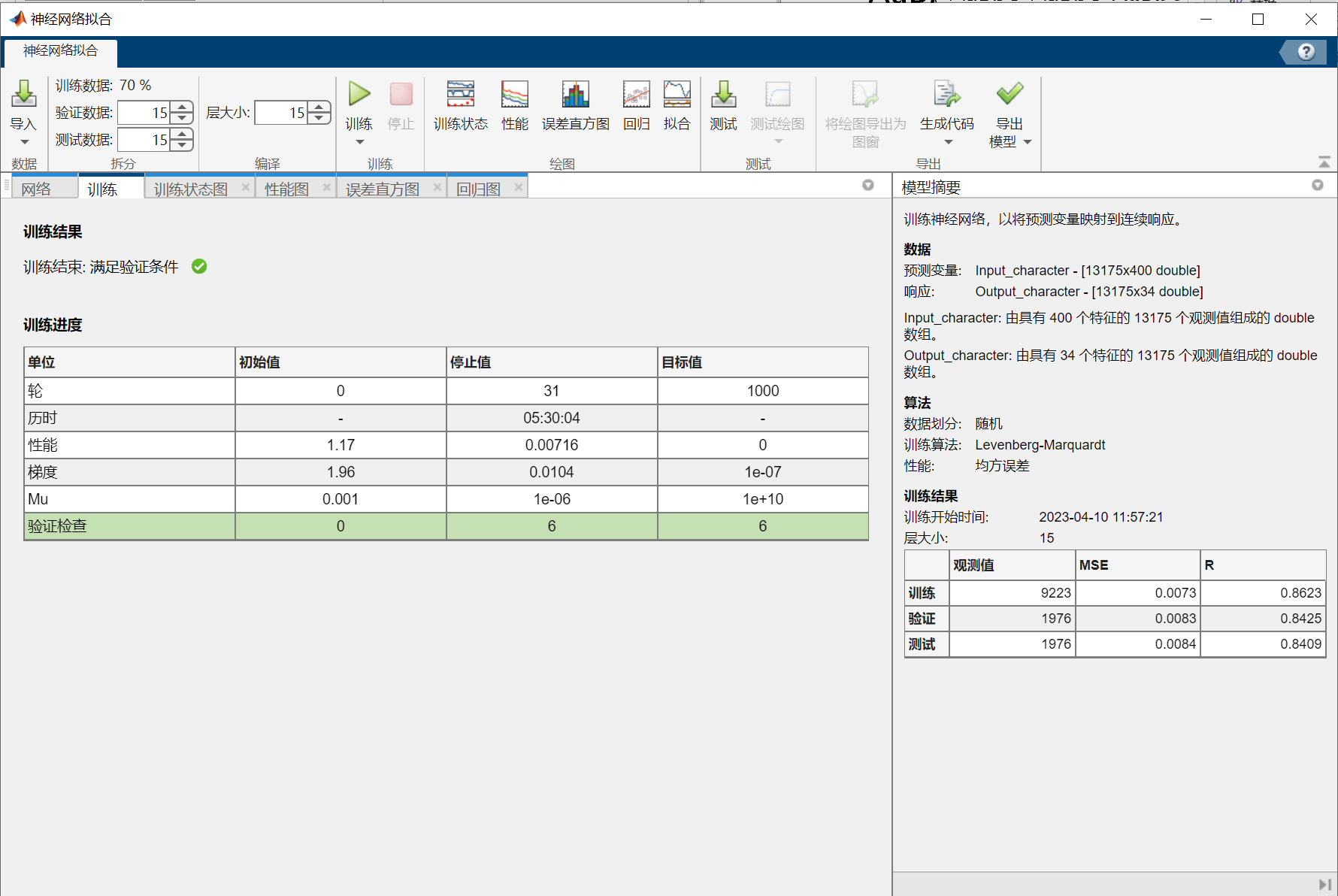
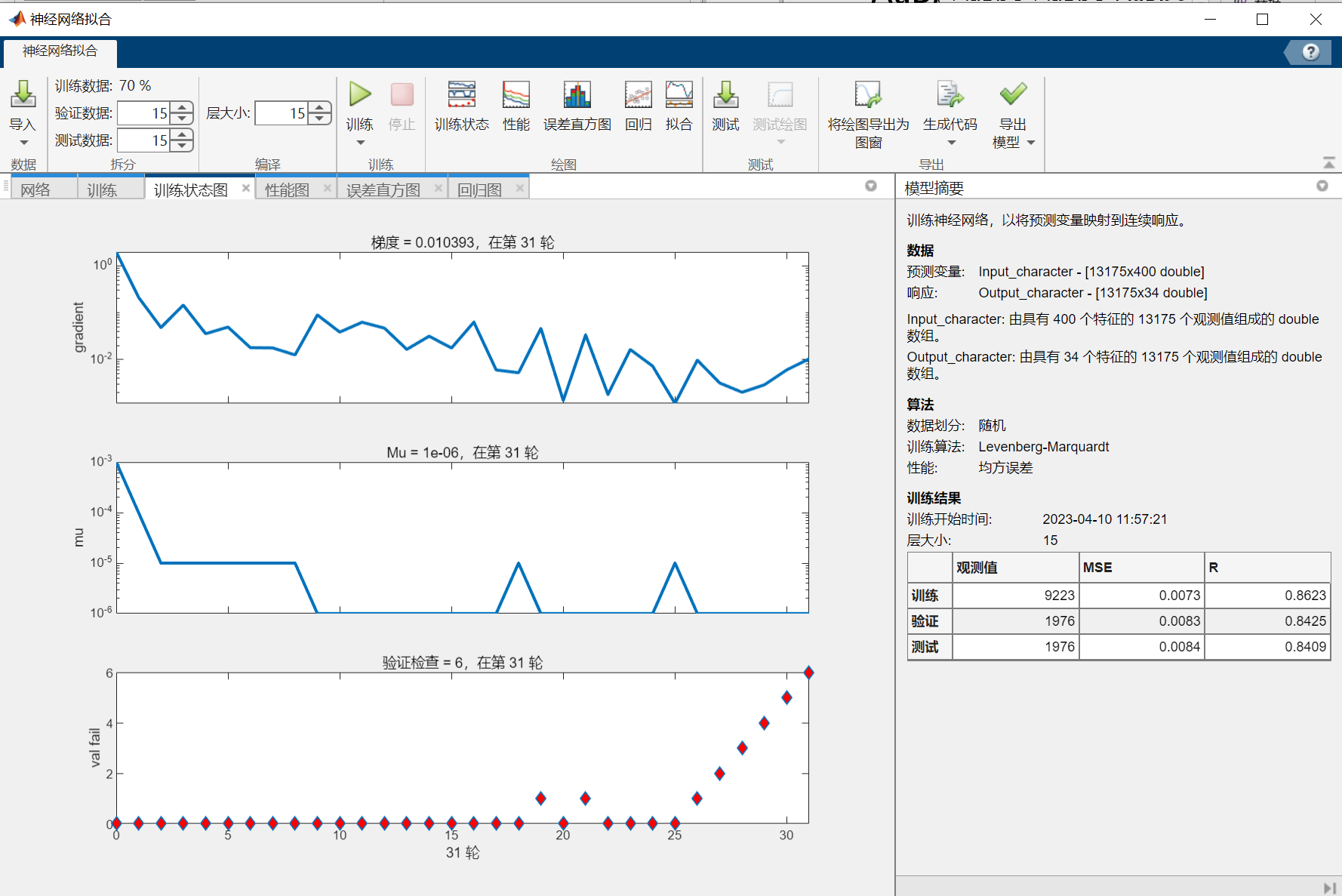
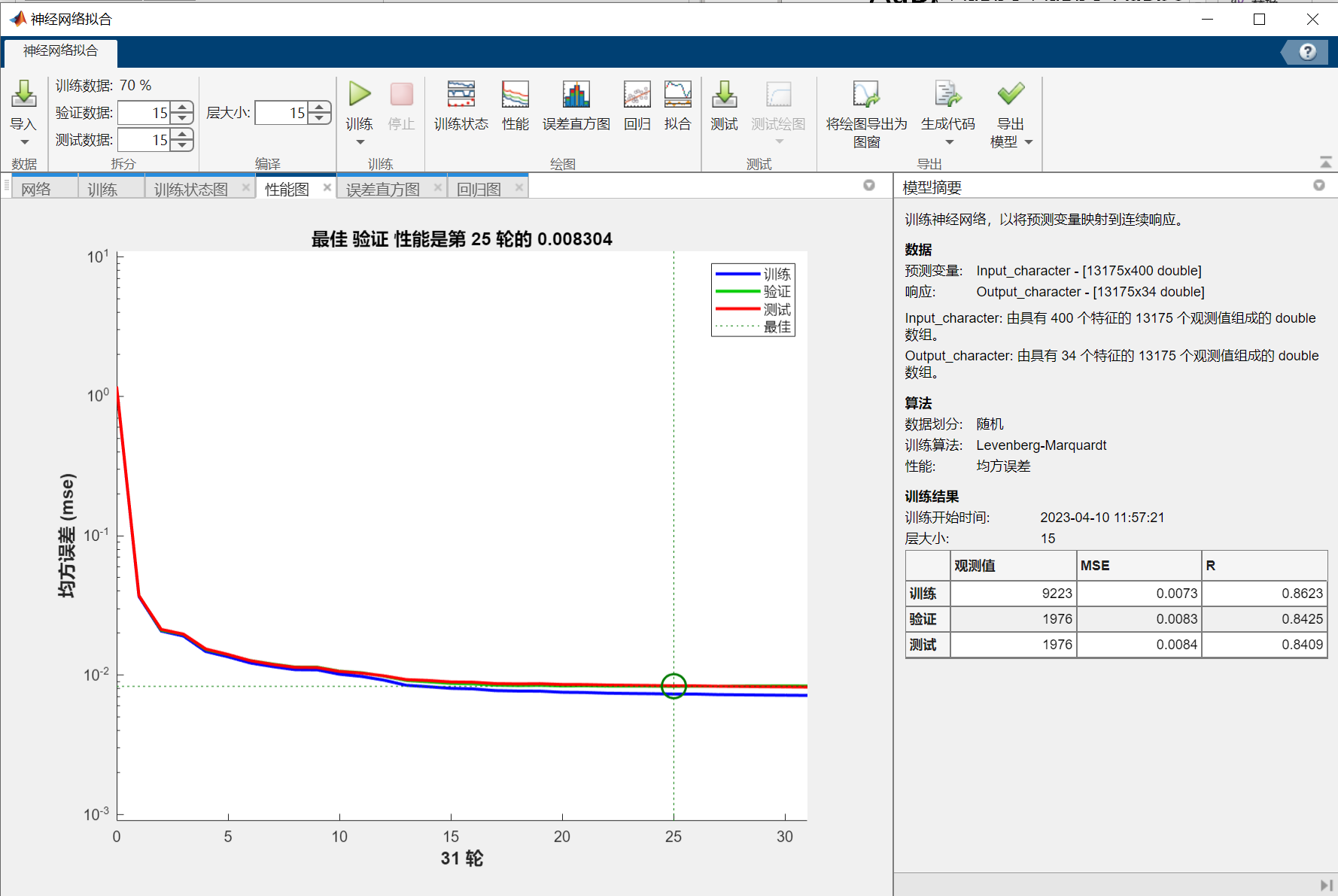
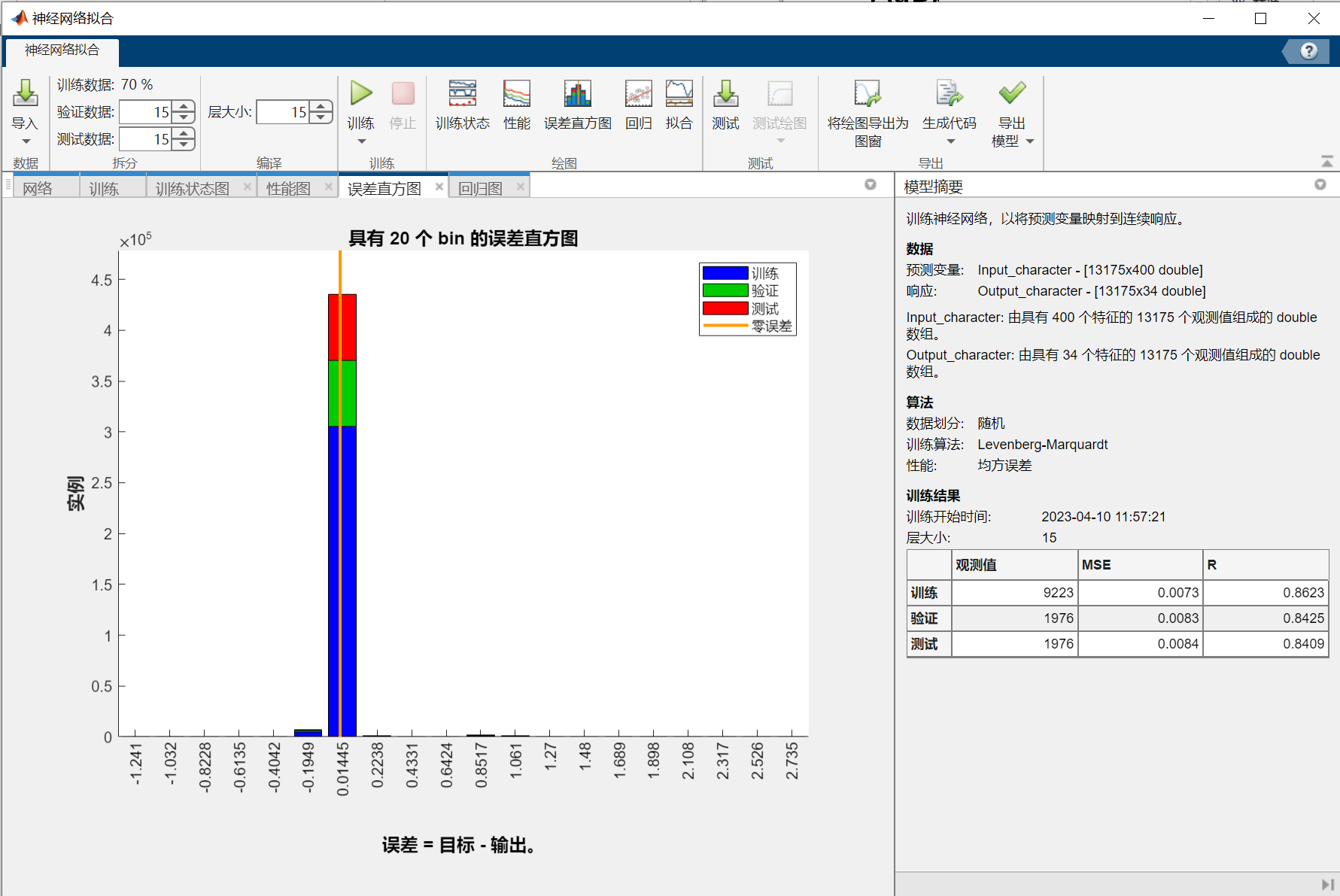
NN_Chinese.TrainingResults=tr上述代码的结果:
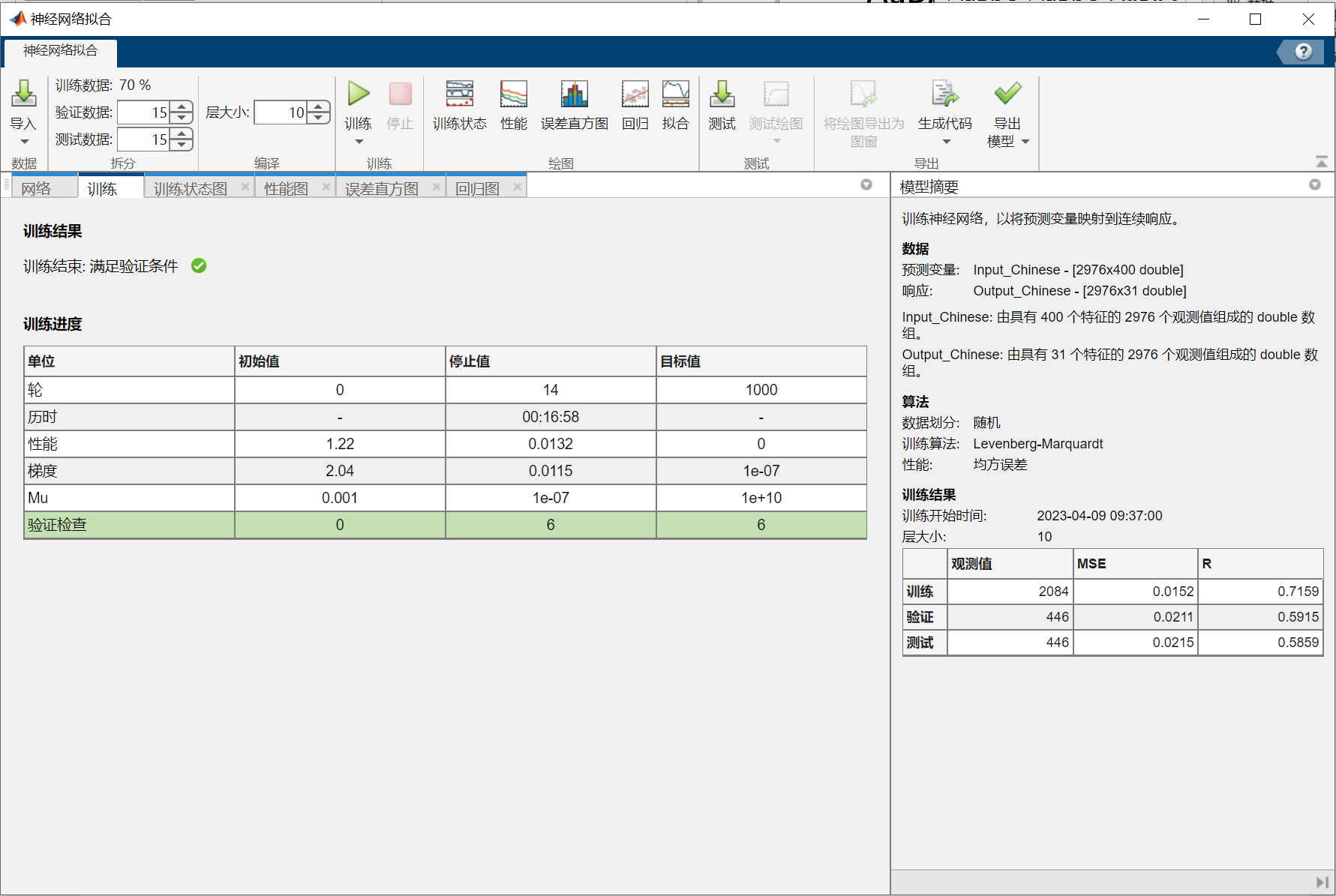
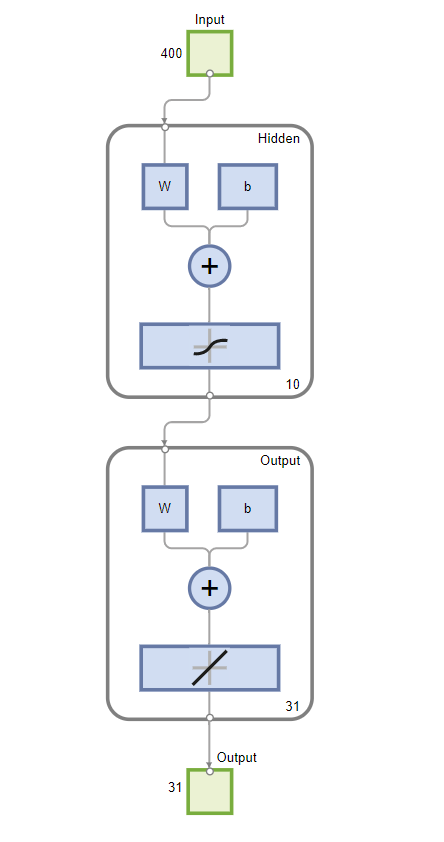
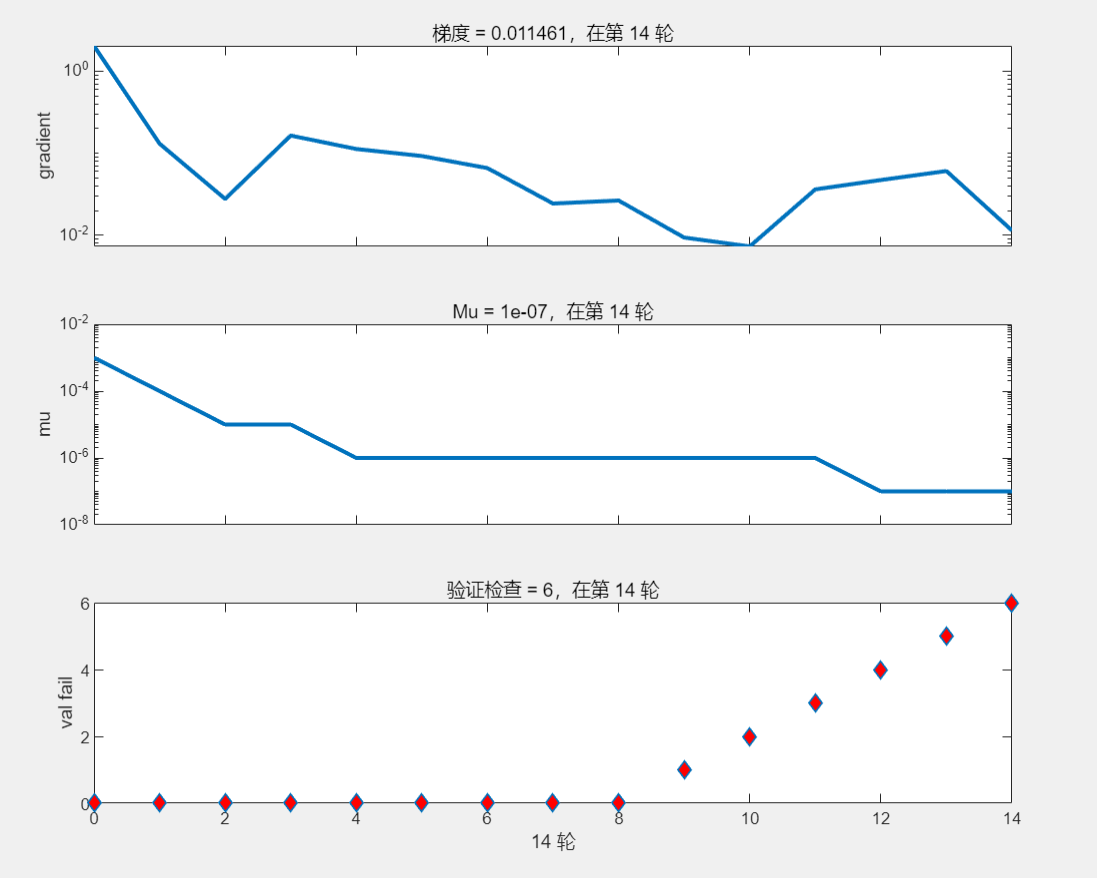
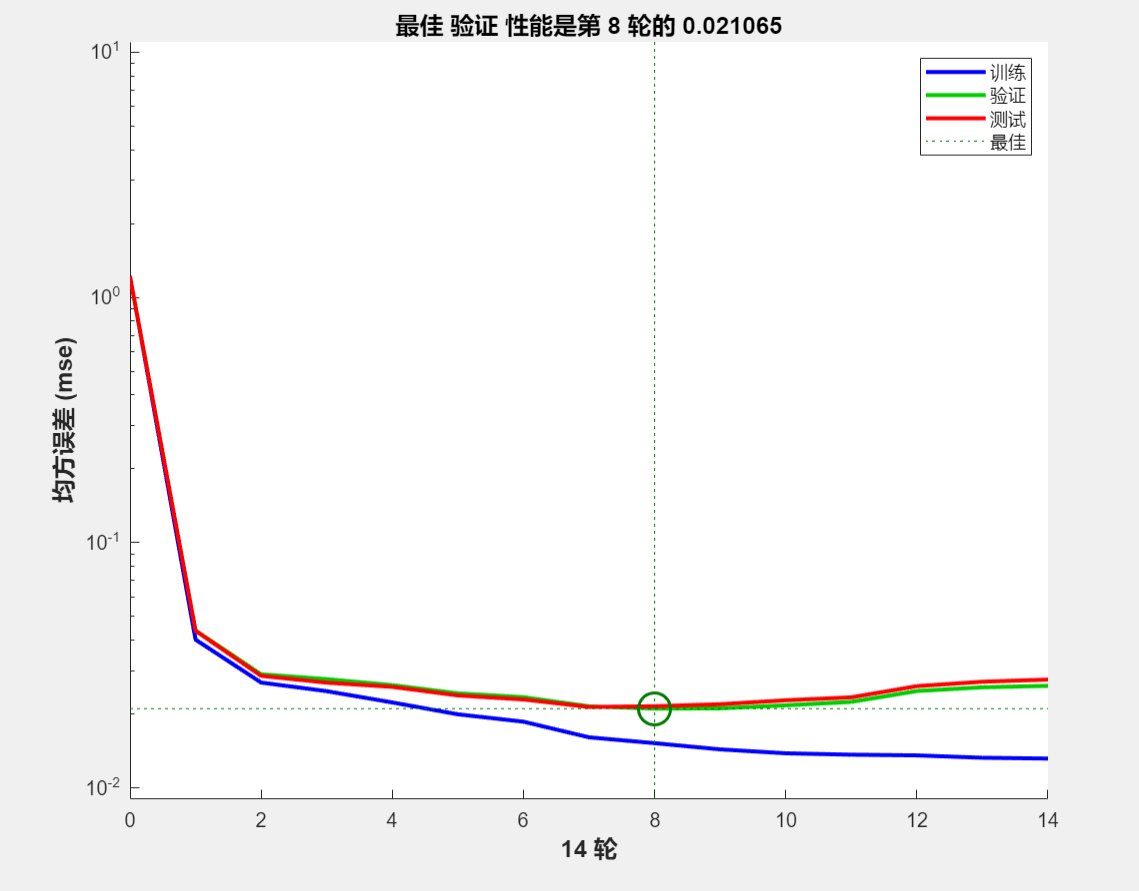
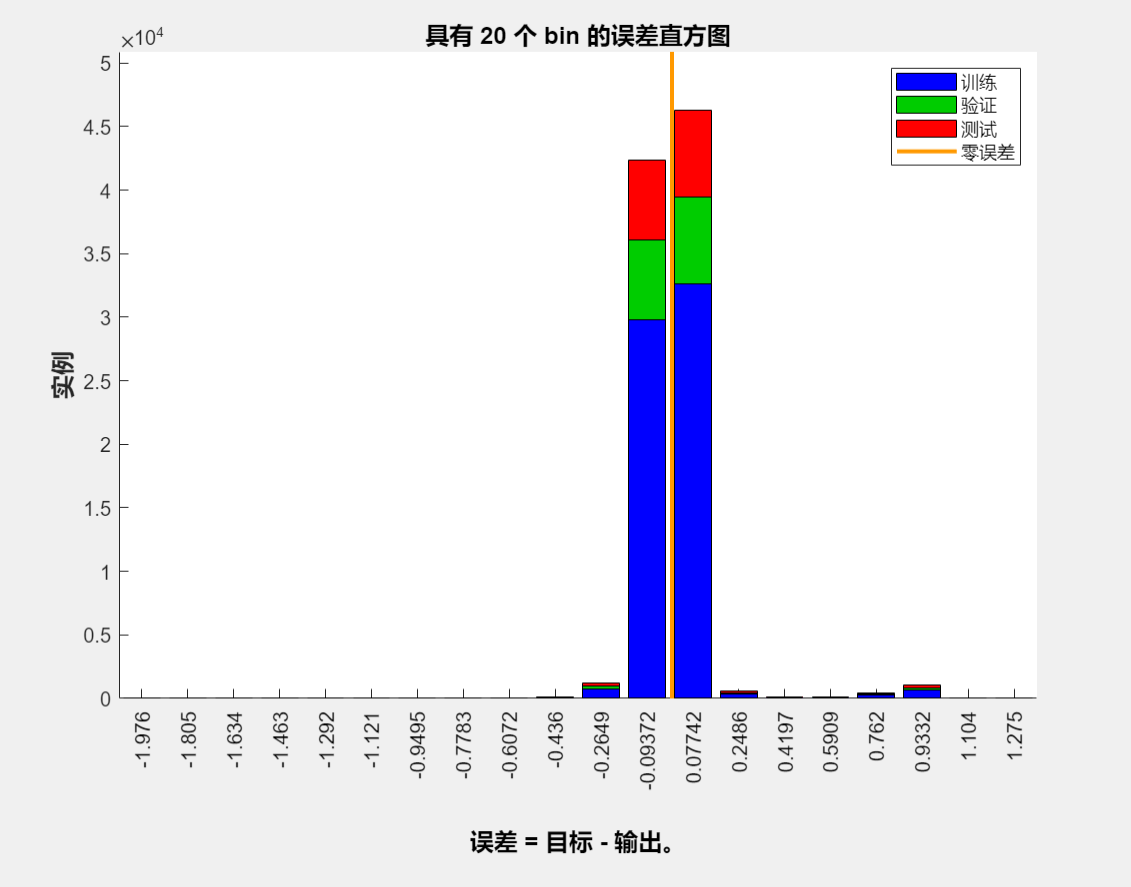
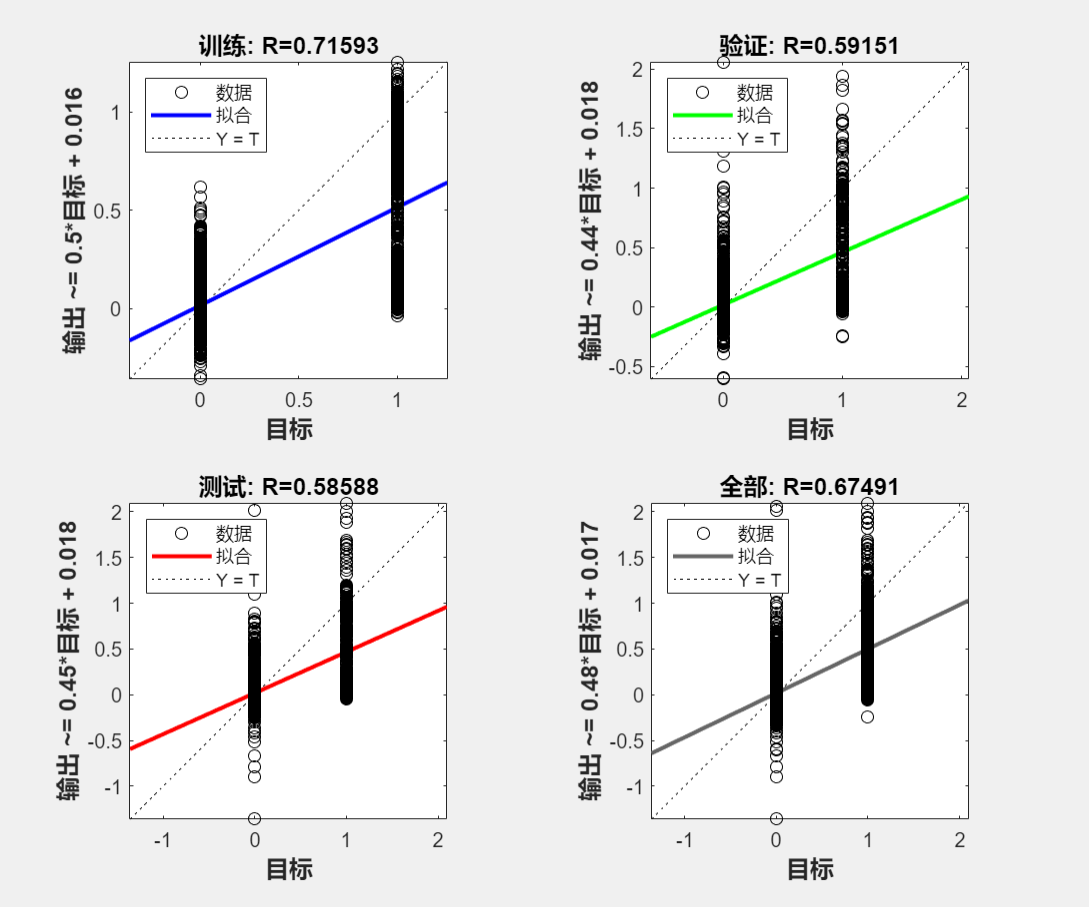
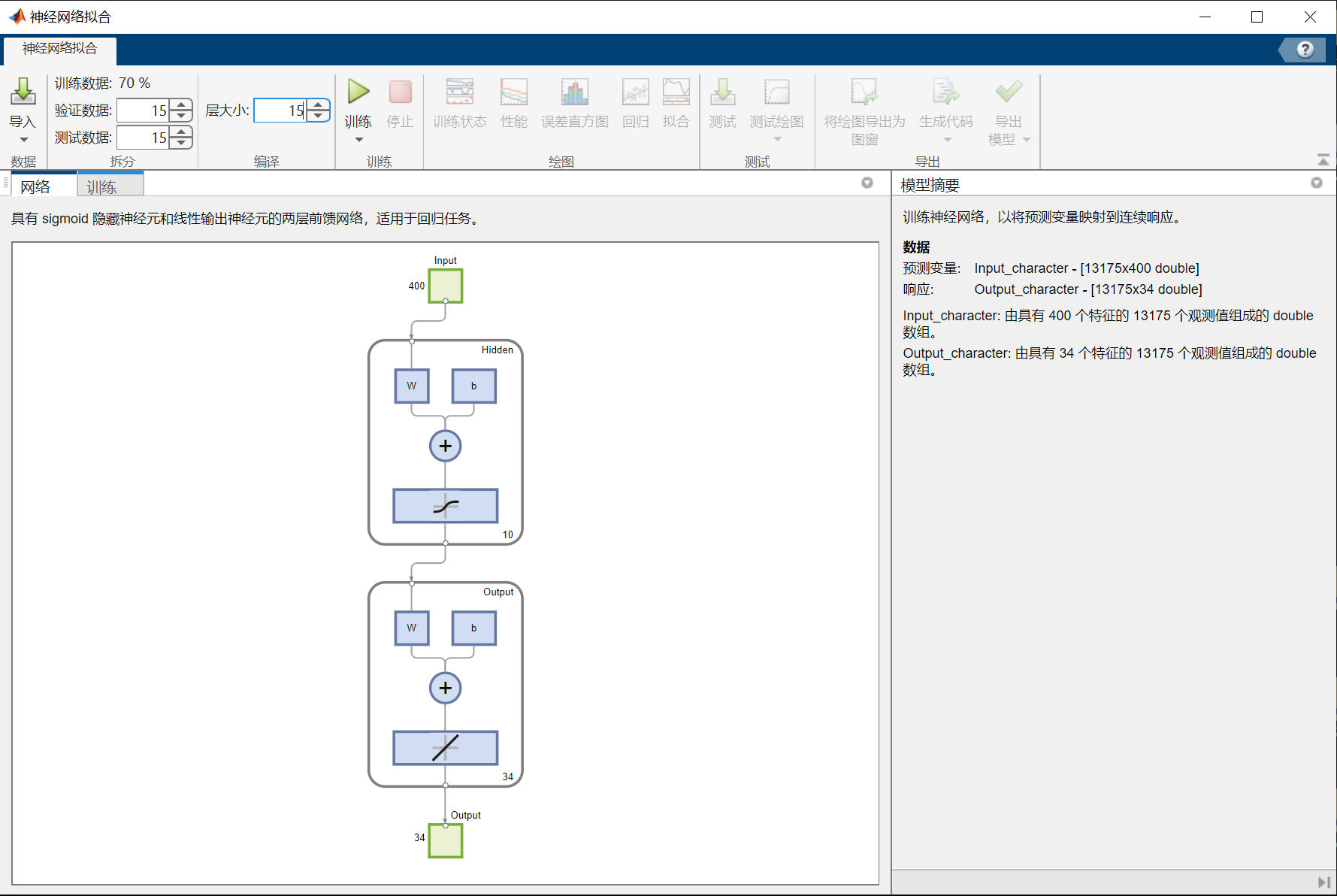
%函数功能:训练识别数字字母的神经网络
function NN_character=neural_network_character(Input_character,Output_character)
%Input_Chinese:车牌数字字母输入矩阵
%Output_character:车牌数字字母输出(目标)矩阵
%NN_character:识别数字字母的神经网络结构
% Solve an Input-Output Fitting problem with a Neural Network
% Script generated by Neural Fitting app
% Created 10-Apr-2023 18:25:59
%
% This script assumes these variables are defined:
%
% Input_character - input data.
% Output_character - target data.
x = Input_character';
t = Output_character';
% Choose a Training Function
% For a list of all training functions type: help nntrain
% 'trainlm' is usually fastest.
% 'trainbr' takes longer but may be better for challenging problems.
% 'trainscg' uses less memory. Suitable in low memory situations.
trainFcn = 'trainlm'; % Levenberg-Marquardt backpropagation.
% Create a Fitting Network
hiddenLayerSize = 15;
net = fitnet(hiddenLayerSize,trainFcn);
% Setup Division of Data for Training, Validation, Testing
net.divideParam.trainRatio = 70/100;
net.divideParam.valRatio = 15/100;
net.divideParam.testRatio = 15/100;
% Train the Network
[net,tr] = train(net,x,t);
% Test the Network
y = net(x);
e = gsubtract(t,y);
performance = perform(net,t,y)
% View the Network
view(net)
% Plots
% Uncomment these lines to enable various plots.
%figure, plotperform(tr)
%figure, plottrainstate(tr)
%figure, ploterrhist(e)
%figure, plotregression(t,y)
%figure, plotfit(net,x,t)
NN_character.Network=net
NN_character.TrainingResults=tr上述代码的结果:
%函数功能:车牌识别与显示
function [zxcvb,mnbvc]=RecognitionAndView(NN_Chinese,NN_character,chi,cha,plate)
%NN_Chinese:识别汉字的神经网络结构
%NN_character:识别数字字母的神经网络结构
%chi:转换成1*400的汉字图
%cha:转换成1*400的字符图
%Plate:只含车牌的图片
%zxcvb:识别到的汉字
%mnbvc:识别到的数字字母
province=['川';'鄂';'赣';'甘';'贵';'桂';'黑';'呼';'冀';'吉';'津';'晋';'京';'辽';'鲁';'蒙';'闽';'宁';'青';'琼';'陕';'苏';'皖';'湘';'新';'豫';'渝';'粤';'云';'藏';'浙']
qwert=sim(NN_Chinese.Network,chi') %将待识别的汉字输入神经网络拟合
asdfg=abs(qwert-1) %求各输出特征与1的距离
[~,p]=min(asdfg) %找到与1的距离小的特征的位置
zxcvb=province(p,:) %存储识别到的汉字
Character=['0';'1';'2';'3';'4';'5';'6';'7';'8';'9';'A';'B';'C';'D';'E';'F';'G';'H';'J';'K';'L';'M';'N';'P';'Q';'R';'S';'T';'U';'V';'W';'X';'Y';'Z']
poiuy=sim(NN_character.Network,cha')
lkjhg= abs(poiuy-1) ;
[~,t]=min(lkjhg)
mnbvc='??????'
for i=1:6 %依次存储识别到的数字字母
mnbvc(i)=Character(mod(t(i),34),:)
end
figure()
imshow(plate)
title('识别结果', 'FontWeight', 'Bold');
annotation('textbox',[.4 .2 .1 .1],'String',[zxcvb,mnbvc],'FitBoxToText','on')
end上述代码的结果:

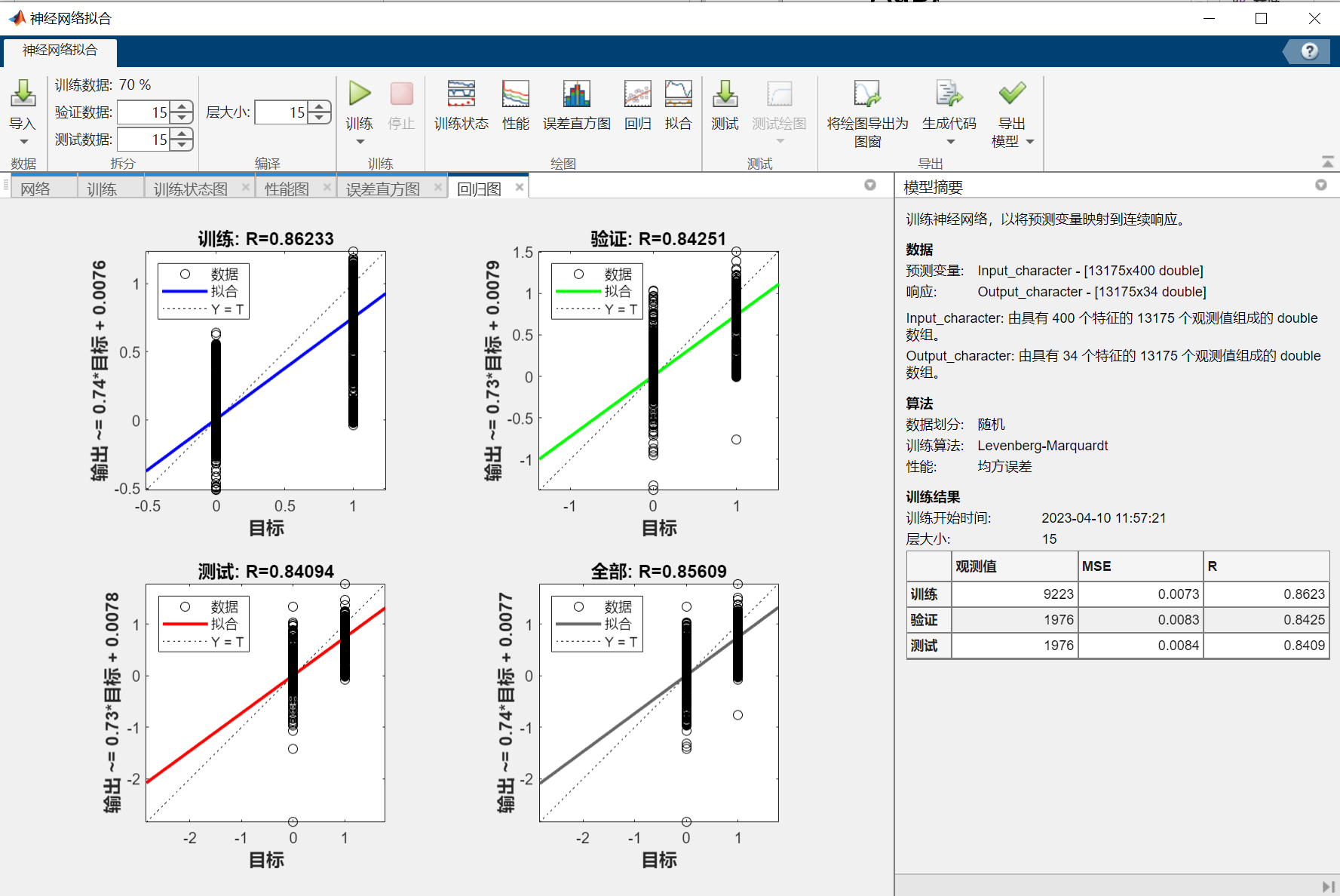
五、结果分析与讨论
1、结果分析
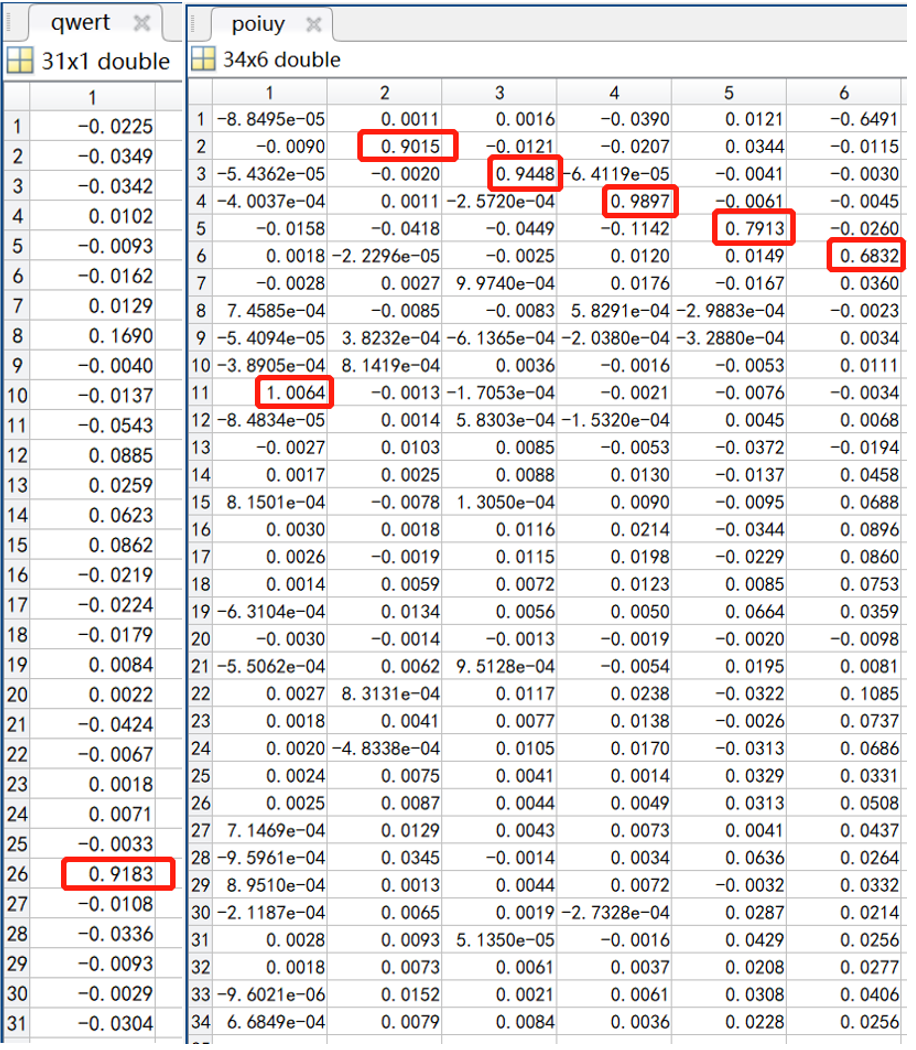
从神经网络拟合出的结果来看,识别的效果非常好。识别结果所在位置的拟合值非常接近1(最后两个较为接近),绝大多数结果以外的值非常接近0,且这两者有数量级上的差距。
但是可以观察到,最后两个车牌字符识别得并不完美,尤其是最后一个差点儿识别成了“0”(上表最后一列第一行),本人推测这可能是车牌有小幅弯曲,导致图片处理后得到的“4”和“5”有小幅度的变形。
在多次尝试后发现,本案例主要的误差来自于图像处理的不够精准,而不是神经网络拟合的拟合效果(虽然这两个神经网络结构较简单,完全称不上宽度学习或深度学习)。
2、可以提高识别精度的地方
用更高清的摄像装置捕捉车牌画面。
定位车牌时除了利用蓝色信息,还可以利用车牌的形状以及铆钉的位置等信息进行更精准的定位。
在图像滤波处理掉噪声这里,可以尝试其他的滤波算法。(不过实话实说,这部分我没太搞懂原理,不知道是否有用) (顺便一提,好像人工智能也可以反过来用于图片去噪)
单个字符(既指待识别的也指用于训练神经网络的)可以用更多的像素点来表示,增多特征。
对于同一个车牌,可以从不同角度拍摄多张照片,将神经网络输出的拟合结果平均,以抵消一部图片处理的误差。(现在许多智能手机在拍照时也会开启短暂的录像功能,通过比较按下快门前后的图像信息的差异,对图片进行润色)
用于训练神经网络的样本本身也可以带有与待识别车牌同样类型的环境噪声。如果能够明确此案例的应用场景,那么识别的结果将会有很大的提高。比如:将车牌识别应用于地下车库的门禁用以收取停车费。那么我们可以想到地下车库的环境较为灰暗,拍摄的图片应该也是比较暗淡的。那么训练神经网络选取的样本就应该较为暗淡,不过最好的还是从之前地下车库里的图片中人工打标签给神经网络去训练。再比如:将车牌用于小区的门禁。小区有一高楼,高楼的影子会对车牌处理造成一些影响。而影子变化受时间(太阳光照的位置)和天气的影响。我们可以利用这些信息来处理待识别的车牌图片以及样本。顺便一提,matlab自带了神经网络时间序列这个APP工具箱,可以很好的求解非线性时间序列问题。
六、参考文献
以下内容参考极多
图像处理和模式识别案例-一个简单的车牌识别系统_哔哩哔哩_bilibili
图像处理和模式识别案例--车牌识别2_哔哩哔哩_bilibili
《MATLAB图像与视频处理实用案例详解》 P46~P63 刘衍琦 詹福宇 编著 电子工业出版社ISBN 978-7-121-25226-6 “车牌识别\第05章 基于阈值分割的车牌定位识别”文件夹中已保存此书籍的pdf版以及此书中的可执行代码和车牌图片
以下内容略微参考
数字图像处理——车牌识别(matlab)_iamstarlee的博客-CSDN博客
基于MATLAB的车牌识别基本原理及算法讲解_3D视觉工坊的博客-CSDN博客
车牌识别的matlab程序(程序-讲解-模板)_yl624624的博客-CSDN博客
【老生谈算法】基于matlab的车牌识别算法详解及程序源码——车牌识别算法_车辆转换脉冲程序_阿里matlab建模师的博客-CSDN博客
【车牌识别】基于matlab GUI BP神经网络车牌识别(带语音播报)【含Matlab源码 668期】_di = image(:,:,3);_海神之光的博客-CSDN博客
车牌数据集

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)