
2、目标检测:数据集的生成(PASCAL VOC Format)
转 LMDB 代码示例。
·
目标检测:数据集的生成(PASCAL VOC Format)
文章目录
一、 生成训练和测试的 filelist 以及 test_name_size
# -*- coding: utf-8 -*-
import os
import sys
import cv2
import glob
import codecs
import argparse
import numpy as np
from lxml import etree
from generate_new_xml import write_xml
reload(sys)
sys.setdefaultencoding('utf-8')
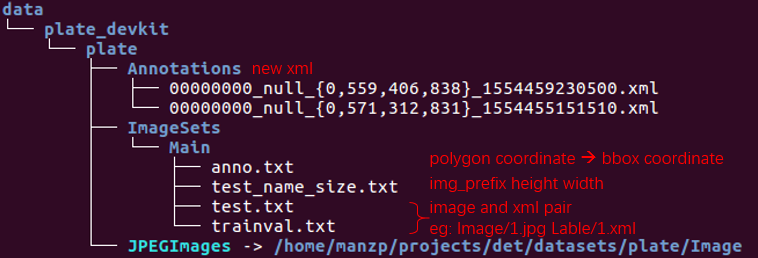
def make_voc_dir(data_save_dir, data_dir_yun):
"""
Args:
data_save_dir: dataset save dir, str, eg:'/home/manzp/projects/det/prep_resultdata/plate_devkit/plate'
data_dir_yun: real dataset dir, str, eg: '/home/manzp/projects/det/datasets/plate/Image'
Returns:
anno_dir_f: dir of annotations
jpg_dir_f: dir of images(soft link)
main_txt_dir_f: annotations filename/size/obj_label/obj_bndbox txt and trainval&test img/xml pair dir
"""
anno_dir_f = os.path.join(data_save_dir, 'Annotations')
jpg_dir_f = os.path.join(data_save_dir, 'JPEGImages')
main_txt_dir_f = os.path.join(data_save_dir, 'ImageSets/Main')
if not os.path.os.path.exists(anno_dir_f):
os.makedirs(anno_dir_f)
if not os.path.os.path.exists(jpg_dir_f):
os.system('ln -s {} {}'.format(data_dir_yun, jpg_dir_f)) # make soft link
if not os.path.os.path.exists(main_txt_dir_f):
os.makedirs(main_txt_dir_f)
print('anno_dir is {}'.format(anno_dir_f))
print('jpg_dir is {}'.format(jpg_dir_f))
print('main_txt_dir is {}'.format(main_txt_dir_f))
print('Make voc format dirs done!')
print('####################################################')
return anno_dir_f, jpg_dir_f, main_txt_dir_f
def extract_xml2txt(label_dir, anno_txt_dir):
"""
Args:
label_dir: old xml dir, eg: '/home/manzp/projects/det/datasets/plate/Label'
anno_txt_dir: new xml info txt save dir, eg:'/home/manzp/projects/det/prep_result/data/plate_devkit/plate/ImageSets/Main'
Returns:
None
"""
print('label dir is {}'.format(label_dir))
print('anno txt save dir is {}'.format(anno_txt_dir))
cnt = 0
wrong_cnt = 0
f = codecs.open(os.path.join(anno_txt_dir, 'anno.txt'), 'w', encoding='utf-8')
for anno_xml in glob.glob(os.path.join(label_dir, '*')):
img_path = anno_xml.replace('Label', 'Image').replace('xml', 'jpg')
# img_path = glob.glob(anno_xml.replace('Label', 'Image').replace('xml', '*'))[0]
img_name = img_path.split('/')[-1].encode('utf-8')
out_info = [img_name + ' ']
try:
tree = etree.parse(anno_xml) # open xml doc
root = tree.getroot() # get root node
img_bgr = cv2.imdecode(np.fromfile(img_path, dtype=np.uint8), 1)
height, width, depth = img_bgr.shape
out_info.extend([str(height) + ' ', str(width) + ' ', str(depth) + ' '])
for obj in root.iter('object'):
obj_name = obj.find('name').text.encode('utf-8')
# filter car and CAR
if obj_name == 'car':
pass
elif obj_name == 'blur':
plate_difficult = '1'
plate_obj_name = 'plate'
plate_coord = obj.find('polygonbox')
left_topx = plate_coord.find('leftTopx').text.encode('utf-8')
left_topy = plate_coord.find('leftTopy').text.encode('utf-8')
right_topx = plate_coord.find('rightTopx').text.encode('utf-8')
right_topy = plate_coord.find('rightTopy').text.encode('utf-8')
right_bottomx = plate_coord.find('rightBottomx').text.encode('utf-8')
right_bottomy = plate_coord.find('rightBottomy').text.encode('utf-8')
left_bottomx = plate_coord.find('leftBottomx').text.encode('utf-8')
left_bottomy = plate_coord.find('leftBottomy').text.encode('utf-8')
xmin_p = min(int(left_topx), int(left_bottomx))
xmax_p = max(int(right_topx), int(right_bottomx))
ymin_p = min(int(left_topy), int(right_topy))
ymax_p = max(int(left_bottomy), int(right_bottomy))
# filter invalid coordinates xml file
if xmin_p < 0 or xmax_p < 0 or ymin_p < 0 or ymax_p < 0:
break
elif xmin_p > int(width) or xmax_p > int(width) or ymin_p > int(height) or ymax_p > int(height):
break
elif xmin_p > xmax_p or ymin_p > ymax_p:
break
else:
out_info.extend([plate_obj_name + ' ', str(xmin_p) + ' ', str(ymin_p) + ' ', str(xmax_p) + ' ',
str(ymax_p) + ' ',
plate_difficult + ' '])
else:
plate_difficult = '0'
plate_obj_name = 'plate'
plate_coord = obj.find('polygonbox')
left_topx = plate_coord.find('leftTopx').text.encode('utf-8')
left_topy = plate_coord.find('leftTopy').text.encode('utf-8')
right_topx = plate_coord.find('rightTopx').text.encode('utf-8')
right_topy = plate_coord.find('rightTopy').text.encode('utf-8')
right_bottomx = plate_coord.find('rightBottomx').text.encode('utf-8')
right_bottomy = plate_coord.find('rightBottomy').text.encode('utf-8')
left_bottomx = plate_coord.find('leftBottomx').text.encode('utf-8')
left_bottomy = plate_coord.find('leftBottomy').text.encode('utf-8')
xmin_p = min(int(left_topx), int(left_bottomx))
xmax_p = max(int(right_topx), int(right_bottomx))
ymin_p = min(int(left_topy), int(right_topy))
ymax_p = max(int(left_bottomy), int(right_bottomy))
# filter invalid coordinates xml file
if xmin_p < 0 or xmax_p < 0 or ymin_p < 0 or ymax_p < 0:
break
elif xmin_p > int(width) or xmax_p > int(width) or ymin_p > int(height) or ymax_p > int(height):
break
elif xmin_p > xmax_p or ymin_p > ymax_p:
break
else:
out_info.extend([plate_obj_name + ' ', str(xmin_p) + ' ', str(ymin_p) + ' ', str(xmax_p) + ' ',
str(ymax_p) + ' ',
plate_difficult + ' '])
# strip the last blank and write list seq to file
f.writelines(out_info[:-1] + [out_info[-1].strip()] + ['\n'])
cnt += 1
except Exception as e:
print('Error Reason is {}'.format(e))
print("Error: cannot parse file: {}".format(anno_xml))
wrong_cnt += 1
continue
f.close()
print('Successfully parsed {} images!'.format(cnt))
print('Can not parse {} images!'.format(wrong_cnt))
print('Extract xml info to anno.txt Done!')
print('####################################################')
def write2xml(main_txt_dir, anno_dir, jpg_dir):
"""write plate obj to xml and filter no plate img
Args:
main_txt_dir: new xml info txt save dir
anno_dir: new xml save dir
jpg_dir: raw image dir
Returns:
None
"""
with codecs.open(os.path.join(main_txt_dir, 'anno.txt'), 'r', encoding='utf-8') as f:
cnt = 0
wrong_cnt = 0
for line in f.readlines():
line_list = line.strip().split(' ')
img_prefix = os.path.splitext(line_list[0])[0]
xml_path = os.path.join(anno_dir, img_prefix + '.xml')
img_path = os.path.join(jpg_dir, line_list[0])
img_size = line_list[1:4]
bndbox_list = line_list[4:]
# filter no plate img and wrong img
if len(bndbox_list) > 0:
sub_bndbox_list = []
try:
for i in range(0, len(bndbox_list), 6):
sub_bndbox = []
sub_bndbox.append(bndbox_list[i]) # obj_name: plate
sub_bndbox.append(bndbox_list[i + 1]) # xmin
sub_bndbox.append(bndbox_list[i + 2]) # ymin
sub_bndbox.append(bndbox_list[i + 3]) # xmax
sub_bndbox.append(bndbox_list[i + 4]) # ymax
sub_bndbox.append(bndbox_list[i + 5]) # plate_difficult
sub_bndbox_list.append(sub_bndbox)
write_xml(img_path, img_size, sub_bndbox_list, xml_path)
cnt += 1
except Exception as e:
print("Error: cannot parse file: %s" % line_list[0])
wrong_cnt += 1
continue
else:
wrong_cnt += 1
print('Regenerate xml wrong cnt num is {}'.format(wrong_cnt))
print('Regenerate xml total num is {}'.format(wrong_cnt + cnt))
print('Regenerate xml done!')
print('####################################################')
def create_filelist(anno_dir, jpg_dir, main_txt_dir):
"""split data and generate img and xml pair list and test_name_size
Args:
anno_dir: new xml dir
jpg_dir: raw image dir
main_txt_dir: trainval test image/xml pair and test_name_size txt save dir
Returns:
None
"""
xml_prefix = [i[:-4] for i in os.listdir(anno_dir)] # strip '.xml'
np.random.shuffle(xml_prefix)
xml_num = len(xml_prefix)
test_num = int(xml_num * 0.1) # 0.1/0.9
test_xml_prefix = xml_prefix[:test_num]
trainval_xml_prefix = xml_prefix[test_num:]
# generate img/xml pair list and test_name_size(prefix height width)
train_val_path = os.path.join(main_txt_dir, 'trainval.txt')
with codecs.open(train_val_path, 'w', encoding='utf-8') as f1:
for prefix in trainval_xml_prefix:
img_path = os.path.join(jpg_dir.split('data/')[1].strip(), prefix.strip() + '.jpg')
xml_path = os.path.join(anno_dir.split('data/')[1].strip(), prefix.strip() + '.xml')
line_pair = img_path + ' ' + xml_path + '\n'
f1.write(line_pair)
test_name_size_path = os.path.join(main_txt_dir, 'test_name_size.txt')
ft = codecs.open(test_name_size_path, 'w', encoding='utf-8')
test_path = os.path.join(main_txt_dir, 'test.txt')
with codecs.open(test_path, 'w', encoding='utf-8') as f2:
for prefix in test_xml_prefix:
img_path = os.path.join(jpg_dir.split('data/')[1].strip(), prefix.strip() + '.jpg')
xml_path = os.path.join(anno_dir.split('data/')[1].strip(), prefix.strip() + '.xml')
line_pair = img_path + ' ' + xml_path + '\n'
f2.write(line_pair)
img_path_full = os.path.join(jpg_dir, prefix.strip()+'.jpg')
img_bgr = cv2.imdecode(np.fromfile(img_path_full, dtype=np.uint8), 1)
height, width, depth = img_bgr.shape
ft.write(prefix + ' ' + str(height) + ' ' + str(width) + '\n')
ft.close()
print('Data split done!')
print('Generate img and xml pair list done!')
print('####################################################')
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='manual to this script')
parser.add_argument('--train_data_dir',
default='/home/manzp/projects/det/datasets/plate/Image',
help="the path of train_data_dir", nargs="?")
parser.add_argument('--train_label_dir',
default='/home/manzp/projects/det/datasets/plate/Label',
help="the path of train_label_dir", nargs="?")
parser.add_argument('--preprocess_output_dir',
default='/home/manzp/projects/det/plate_det_full/2.preprocess_code/prep_result1',
help="the path of preprocess_output_dir", nargs="?")
args = parser.parse_args()
DATA_DIR_YUN = args.train_data_dir
LABEL_DIR_YUN = args.train_label_dir
DATA_SAVE_PREFIX = 'data/plate_devkit/plate'
DATA_SAVE_DIR = os.path.join(args.preprocess_output_dir, DATA_SAVE_PREFIX) # the output info dir
# 1. make voc format dir and soft link of the real data
anno_dir, jpg_dir, main_txt_dir = make_voc_dir(data_save_dir=DATA_SAVE_DIR, data_dir_yun=DATA_DIR_YUN)
# 2. extract filename/size/obj_label/obj_bndbox of the raw xml
extract_xml2txt(LABEL_DIR_YUN, main_txt_dir)
# 3. write2xml: write plate obj to xml and filter no plate img
write2xml(main_txt_dir, anno_dir, jpg_dir)
# 4. split data and generate img and xml pair list and test_name_size
create_filelist(anno_dir, jpg_dir, main_txt_dir)
- generate new xml
# -*- coding: utf-8 -*-
import sys
import codecs
reload(sys)
sys.setdefaultencoding('utf-8')
from lxml import etree
from xml.etree.ElementTree import Element, SubElement
from xml.etree import ElementTree
def gen_xml(img_path, img_size):
top = Element('annotation')
top.set('verified', 'yes')
folder = SubElement(top, 'folder')
folder.text = img_path.split('/')[-3]
filename = SubElement(top, 'filename')
filename.text = img_path.split('/')[-1].strip()
local_img_path = SubElement(top, 'path')
local_img_path.text = img_path
source = SubElement(top, 'source')
database = SubElement(source, 'database')
database.text = 'plate_det_full_datasets'
size_part = SubElement(top, 'size')
width = SubElement(size_part, 'width')
height = SubElement(size_part, 'height')
depth = SubElement(size_part, 'depth')
height.text = img_size[0]
width.text = img_size[1]
depth.text = img_size[2]
segmented = SubElement(top, 'segmented')
segmented.text = '0'
return top
def appendObjects(top, box_list):
for each_object in box_list:
object_item = SubElement(top, 'object')
name = SubElement(object_item, 'name')
name.text = each_object[0]
flag = SubElement(object_item, 'flag')
flag.text = 'rectangle'
truncated = SubElement(object_item, 'truncated')
truncated.text = '0'
difficult = SubElement(object_item, 'difficult')
difficult.text = each_object[5]
bndbox = SubElement(object_item, 'bndbox')
xmin = SubElement(bndbox, 'xmin')
xmin.text = each_object[1]
ymin = SubElement(bndbox, 'ymin')
ymin.text = each_object[2]
xmax = SubElement(bndbox, 'xmax')
xmax.text = each_object[3]
ymax = SubElement(bndbox, 'ymax')
ymax.text = each_object[4]
def write_xml(img_path, img_size, box_list, xml_path):
"""
Args:
img_path: raw img path, str
img_size: image size, list, eg: ['1080', '1920', '3']
box_list: object info, list, eg: [['obj_label, 'xmin', 'ymin', 'xmax', 'ymax', 'difficult'], [...], ...]
xml_path: new xml path, str
Returns:
None
"""
root = gen_xml(img_path, img_size)
appendObjects(root, box_list)
rough_string = ElementTree.tostring(root, encoding='utf-8')
root1 = etree.fromstring(rough_string)
result = etree.tostring(root1, encoding='utf-8', pretty_print=True)
with codecs.open(xml_path, 'w', encoding='utf-8') as out_file:
out_file.write(result)
二、统计训练数据集各个通道上的均值(BGR 顺序)
# -*- coding: utf-8 -*-
import os
import sys
import cv2
import redis
import argparse
import numpy as np
reload(sys)
sys.setdefaultencoding('utf-8')
def compute_mean(img_dir):
cnt = 0
wrong_cnt = 0
b_sum, g_sum, r_sum = 0.0, 0.0, 0.0
for img_name in os.listdir(img_dir):
try:
cnt += 1
img_path = os.path.join(img_dir, img_name)
img_bgr = cv2.imdecode(np.fromfile(img_path, dtype=np.uint8), 1)
h, w, c = img_bgr.shape
b_mean1 = 1.0 * np.sum(img_bgr[:, :, 0]) / (h*w)
g_mean1 = 1.0 * np.sum(img_bgr[:, :, 1]) / (h*w)
r_mean1 = 1.0 * np.sum(img_bgr[:, :, 2]) / (h*w)
b_sum += b_mean1
g_sum += g_mean1
r_sum += r_mean1
print("process the: %2d example" % cnt)
except Exception as e:
wrong_cnt += 1
print('wrong reason is {}'.format(e))
print(img_name)
continue
b_mean = 1.0 * b_sum / cnt
g_mean = 1.0 * g_sum / cnt
r_mean = 1.0 * r_sum / cnt
print('For train bgr imgs, each channel mean is {} {} {}'.format(b_mean, g_mean, r_mean))
print('####################################################')
if __name__ == "__main__":
# yun param
parser = argparse.ArgumentParser(description='manual to this script')
parser.add_argument('--train_data_dir', default='/home/manzp/datasets/det/plates/raw/plate_det_full/Image/TrainSet/Kedacom/plate_det_full',
help="the path of train_data_dir", nargs="?")
parser.add_argument('--train_label_dir', default='/opt/training/DataSet/Label/TrainSet/Kedacom/dataset_name',
help="the path of train_label_dir", nargs="?")
parser.add_argument('--preprocess_output_dir',
default='/opt/training/dl_train_plat/training_result/task-id/prep_result',
help="the path of preprocess_output_dir", nargs="?")
parser.add_argument('--redis_key', default='', help='redis key', nargs="?")
args = parser.parse_args()
IMAGE_DIR = args.train_data_dir
compute_mean(IMAGE_DIR)
三、通过 filelist 将 data/label 转换为 LMDB
-
create_annoset.py和create_annoset.cpp的用法# 1、create_annoset.py 的用法 usage: create_annoset.py [-h] [--redo] [--anno-type ANNO_TYPE] [--label-type LABEL_TYPE] [--backend BACKEND] [--check-size] [--encode-type ENCODE_TYPE] [--encoded] [--gray] [--label-map-file LABEL_MAP_FILE] [--min-dim MIN_DIM] [--max-dim MAX_DIM] [--resize-height RESIZE_HEIGHT] [--resize-width RESIZE_WIDTH] [--shuffle] [--check-label] root listfile outdir exampledir # 2、create_annoset.cpp 的用法 # ROOTFOLDER is the root folder that holds all the images and annotations, # and LISTFILE should be a list of files as well as their labels or label files. convert_annoset [FLAGS] ROOTFOLDER/ LISTFILE DB_NAME # 分类和检测 listfile 示例 For classification task, the file should be in the format as imgfolder1/img1.JPEG 7 .... For detection task, the file should be in the format as imgfolder1/img1.JPEG annofolder1/anno1.xml .... -
转 LMDB 代码示例
#!/bin/bash start="creat data job start!" end="creat data job done!" echo $start data_root_dir="/opt/training/dl_train_plat/training_result/convert2lmdb8/prep_result/data" # img dir, default add "/" to root directory txt_dir="/opt/training/dl_train_plat/training_result/convert2lmdb8/prep_result/data/plate_devkit/plate/ImageSets/Main" # txt dir dataset_name="plate" # lmdb prefix mapfile="./labelmap_plate.prototxt" # 要和 xml 中的类别名相对应 anno_type="detection" db="lmdb" min_dim=0 max_dim=0 width=0 height=0 redo=1 extra_cmd="--encode-type=jpg --encoded" # The encoded image will be save in datum if [ $redo ] then extra_cmd="$extra_cmd --redo" fi for subset in test trainval do # last four param corresponding to create_annoset.py's root listfile outdir exampledir # 写上 --shuffle 和 --check-label 则为 True python /home/manzp/caffe_ssd/caffe/scripts/create_annoset.py \ --anno-type=$anno_type \ --label-map-file=$mapfile \ --min-dim=$min_dim \ --max-dim=$max_dim \ --resize-width=$width \ --resize-height=$height \ --shuffle --check-label \ $extra_cmd \ $data_root_dir \ $txt_dir/$subset.txt \ $data_root_dir/$dataset_name"_"$db/$subset"_"$db \ examples/$dataset_name done echo $end # labelmap_plate.prototxt item { name: "none_of_the_above" label: 0 display_name: "background" } item { name: "plate" label: 1 display_name: "plate" }
四、ReadXMLToAnnotatedDatum 源码
- gt bboxes 的左上和右下坐标除以了图像的宽和高做了归一化,并且设置了
set_difficult(difficult)标签
// https://github.com/weiliu89/caffe/blob/ssd/src/caffe/util/io.cpp-->line 257
// Parse VOC/ILSVRC detection annotation.
bool ReadXMLToAnnotatedDatum(const string& labelfile, const int img_height,
const int img_width, const std::map<string, int>& name_to_label,
AnnotatedDatum* anno_datum) {
ptree pt;
read_xml(labelfile, pt);
// Parse annotation.
int width = 0, height = 0;
try {
height = pt.get<int>("annotation.size.height");
width = pt.get<int>("annotation.size.width");
} catch (const ptree_error &e) {
LOG(WARNING) << "When parsing " << labelfile << ": " << e.what();
height = img_height;
width = img_width;
}
LOG_IF(WARNING, height != img_height) << labelfile <<
" inconsistent image height.";
LOG_IF(WARNING, width != img_width) << labelfile <<
" inconsistent image width.";
CHECK(width != 0 && height != 0) << labelfile <<
" no valid image width/height.";
int instance_id = 0;
BOOST_FOREACH(ptree::value_type &v1, pt.get_child("annotation")) {
ptree pt1 = v1.second;
if (v1.first == "object") {
Annotation* anno = NULL;
bool difficult = false;
ptree object = v1.second;
BOOST_FOREACH(ptree::value_type &v2, object.get_child("")) {
ptree pt2 = v2.second;
if (v2.first == "name") {
string name = pt2.data();
if (name_to_label.find(name) == name_to_label.end()) {
LOG(FATAL) << "Unknown name: " << name;
}
int label = name_to_label.find(name)->second;
bool found_group = false;
for (int g = 0; g < anno_datum->annotation_group_size(); ++g) {
AnnotationGroup* anno_group =
anno_datum->mutable_annotation_group(g);
if (label == anno_group->group_label()) {
if (anno_group->annotation_size() == 0) {
instance_id = 0;
} else {
instance_id = anno_group->annotation(
anno_group->annotation_size() - 1).instance_id() + 1;
}
anno = anno_group->add_annotation();
found_group = true;
}
}
if (!found_group) {
// If there is no such annotation_group, create a new one.
AnnotationGroup* anno_group = anno_datum->add_annotation_group();
anno_group->set_group_label(label);
anno = anno_group->add_annotation();
instance_id = 0;
}
anno->set_instance_id(instance_id++);
} else if (v2.first == "difficult") {
difficult = pt2.data() == "1";
} else if (v2.first == "bndbox") {
int xmin = pt2.get("xmin", 0);
int ymin = pt2.get("ymin", 0);
int xmax = pt2.get("xmax", 0);
int ymax = pt2.get("ymax", 0);
CHECK_NOTNULL(anno);
LOG_IF(WARNING, xmin > width) << labelfile <<
" bounding box exceeds image boundary.";
LOG_IF(WARNING, ymin > height) << labelfile <<
" bounding box exceeds image boundary.";
LOG_IF(WARNING, xmax > width) << labelfile <<
" bounding box exceeds image boundary.";
LOG_IF(WARNING, ymax > height) << labelfile <<
" bounding box exceeds image boundary.";
LOG_IF(WARNING, xmin < 0) << labelfile <<
" bounding box exceeds image boundary.";
LOG_IF(WARNING, ymin < 0) << labelfile <<
" bounding box exceeds image boundary.";
LOG_IF(WARNING, xmax < 0) << labelfile <<
" bounding box exceeds image boundary.";
LOG_IF(WARNING, ymax < 0) << labelfile <<
" bounding box exceeds image boundary.";
LOG_IF(WARNING, xmin > xmax) << labelfile <<
" bounding box irregular.";
LOG_IF(WARNING, ymin > ymax) << labelfile <<
" bounding box irregular.";
// Store the normalized bounding box.
NormalizedBBox* bbox = anno->mutable_bbox();
bbox->set_xmin(static_cast<float>(xmin) / width);
bbox->set_ymin(static_cast<float>(ymin) / height);
bbox->set_xmax(static_cast<float>(xmax) / width);
bbox->set_ymax(static_cast<float>(ymax) / height);
bbox->set_difficult(difficult);
}
}
}
}
return true;
五、参考资料
1、https://github.com/weiliu89/caffe/blob/ssd/scripts/create_annoset.py
2、https://github.com/weiliu89/caffe/blob/ssd/tools/convert_annoset.cpp
3、https://github.com/weiliu89/caffe/blob/ssd/src/caffe/util/io.cpp
4、一次将自己的数据集制作成PASCAL VOC格式的惨痛经历

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)