
大数据(8i)Spark练习之TopN
需求:每个城市的广告点击Top2SparkCore实现SparkSQL实现需求:省份点击数Top2数据方法1:reduceBy省份方法2:先reduceBy城市,再reduceBy省份打印自定义分区器 求TopN
·
文章目录
需求:每个城市的广告点击Top2
SparkCore实现
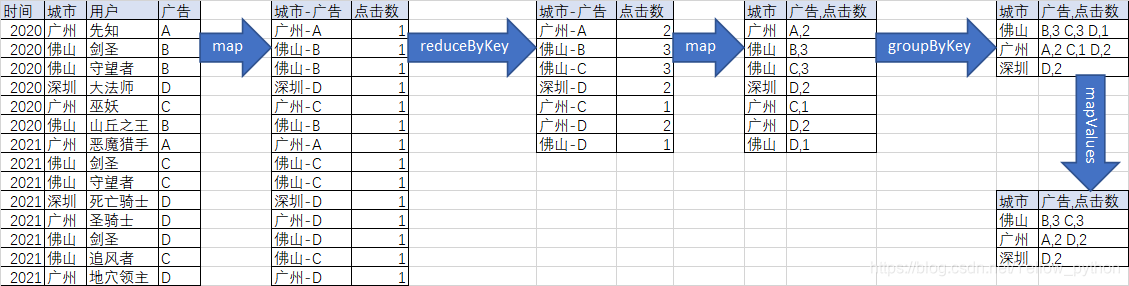
// 创建SparkConf对象,并设定配置
import org.apache.spark.{SparkConf, SparkContext}
val conf = new SparkConf().setAppName("A1").setMaster("local")
// 创建SparkContext对象,Spark通过该对象访问集群
val sc = new SparkContext(conf)
// 创建数据
val r0 = sc.makeRDD(Seq(
("2020", "guangzhou", "Farseer", "A"),
("2020", "foshan", "Blade Master", "B"),
("2020", "foshan", "Warden", "B"),
("2020", "shenzhen", "Archmage", "D"),
("2020", "guangzhou", "Lich", "C"),
("2020", "foshan", "Mountain King", "B"),
("2021", "guangzhou", "Demon Hunter", "A"),
("2021", "foshan", "Blade Master", "C"),
("2021", "foshan", "Warden", "C"),
("2021", "shenzhen", "Death Knight", "D"),
("2021", "guangzhou", "Paladin", "D"),
("2021", "foshan", "Blade Master", "D"),
("2021", "foshan", "Wind Runner", "C"),
("2021", "guangzhou", "Crypt Lord", "D"),
))
// 取出城市和广告字段
val r1 = r0.map(row => {
(row._2 + "-" + row._4, 1)
})
// 按城市和广告计数
val r2 = r1.reduceByKey(_ + _)
// 拆分城市和广告
val r3 = r2.map(kv => (kv._1.split('-')(0), (kv._1.split('-')(1), kv._2)))
// 按城市分组
val r4 = r3.groupByKey
// 排序取TopN
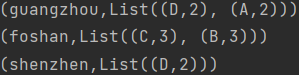
val r6 = r4.mapValues(_.toSeq.sortBy(-_._2).take(2))
r6.foreach(println)
打印结果:
SparkSQL实现
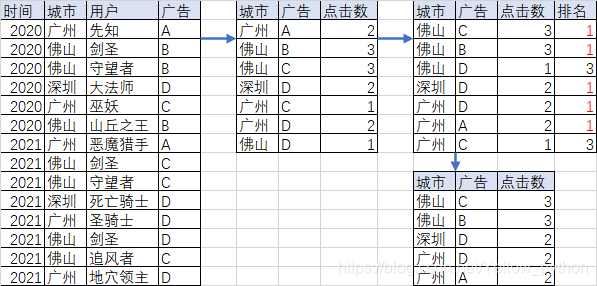
//创建SparkSession对象
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
val c1: SparkConf = new SparkConf().setAppName("a1").setMaster("local[*]")
val spark: SparkSession = SparkSession.builder().config(c1).getOrCreate()
//隐式转换支持
import spark.implicits._
// 创建临时视图0
List(
("2020", "guangzhou", "Farseer", "A"),
("2020", "foshan", "Blade Master", "B"),
("2020", "foshan", "Warden", "B"),
("2020", "shenzhen", "Archmage", "D"),
("2020", "guangzhou", "Lich", "C"),
("2020", "foshan", "Mountain King", "B"),
("2021", "guangzhou", "Demon Hunter", "A"),
("2021", "foshan", "Blade Master", "C"),
("2021", "foshan", "Warden", "C"),
("2021", "shenzhen", "Death Knight", "D"),
("2021", "guangzhou", "Paladin", "D"),
("2021", "foshan", "Blade Master", "D"),
("2021", "foshan", "Wind Runner", "C"),
("2021", "guangzhou", "Crypt Lord", "D"),
).toDF("time", "city", "user", "advertisement").createTempView("t0")
// 按城市和广告分组
spark.sql(
"""
|SELECT city,advertisement,count(0) clicks FROM t0
|GROUP BY city,advertisement
|""".stripMargin).createTempView("t1")
// 使用窗口函数,按城市分区,分区内按点击数排名
spark.sql(
"""
|SELECT
| city,
| advertisement,
| clicks,
| RANK() OVER(PARTITION BY city ORDER BY clicks DESC)AS r
|FROM t1
|""".stripMargin).createTempView("t2")
// 取排名前2
spark.sql("SELECT city,advertisement,clicks FROM t2 WHERE r<3").show()
打印结果
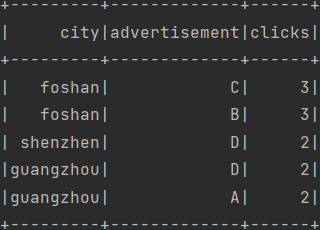
需求:省份点击数Top2
数据
// 创建SparkConf对象,并设定配置
import org.apache.spark.{SparkConf, SparkContext}
val conf = new SparkConf().setAppName("A").setMaster("local[8]")
// 创建SparkContext对象,Spark通过该对象访问集群
val sc = new SparkContext(conf)
// 创建数据
val r0 = sc.makeRDD(Seq(
4401, 4401, 4401, 4401, 4401, 4401, 4401,
4401, 4401, 4401, 4401, 4401, 4401,
4406, 4406, 4406, 4406, 4406, 4406, 4406, 4406,
4602, 4602, 4601,
4301, 4301,
))
方法1:reduceBy省份
// 省份汇总统计
val r1 = r0.map(a => (a.toString.slice(0, 2), 1)).reduceByKey(_ + _)
// 查看各分区元素
r1.mapPartitionsWithIndex((pId, iter) => {
println("分区" + pId + "元素:" + iter.toList)
iter
}).collect
// 省份TopN
r1.sortBy(-_._2).take(2).foreach(println)
方法2:先reduceBy城市,再reduceBy省份
reduceBy城市可以使并行更充分,缓解数据倾斜
// reduceBy城市
val r1 = r0.map((_, 1)).reduceByKey(_ + _)
// 查看各分区元素
r1.mapPartitionsWithIndex((pId, iter) => {
println("分区" + pId + "元素:" + iter.toList)
iter
}).collect
// reduceBy省份
val r2 = r1.map(t => (t._1.toString.slice(0, 2), t._2)).reduceByKey(_ + _)
// 查看各分区元素
r2.mapPartitionsWithIndex((pId, iter) => {
println("分区" + pId + "元素:" + iter.toList)
iter
}).collect
// 省份TopN
r2.sortBy(-_._2).take(2).foreach(println)
打印
reduceBy城市各分区元素
分区4元素:List()
分区3元素:List()
分区7元素:List()
分区0元素:List()
分区2元素:List((4602,2))
分区6元素:List((4406,8))
分区5元素:List((4301,2))
分区1元素:List((4401,13), (4601,1))
reduceBy省份各分区元素
分区5元素:List()
分区3元素:List()
分区1元素:List()
分区4元素:List()
分区6元素:List()
分区7元素:List((43,2))
分区0元素:List((44,21))
分区2元素:List((46,3))
结果
(44,21)
(46,3)
自定义分区器 求TopN
自定义分区器可以缓解数据倾斜,后面需要二次聚合
import org.apache.spark.{HashPartitioner, Partitioner, SparkConf, SparkContext}
import scala.util.Random
class MyPartitioner extends Partitioner {
val random: Random = new Random
// 总的分区数
override def numPartitions: Int = 8
// 按key分区,此处假设44数据倾斜
override def getPartition(key: Any): Int = key match {
case "44" => random.nextInt(7)
case _ => 7
}
}
object Hello {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设定配置
val conf = new SparkConf().setAppName("A").setMaster("local[8]")
// 创建SparkContext对象,Spark通过该对象访问集群
val sc = new SparkContext(conf)
// 创建数据
val r0 = sc.makeRDD(Seq(
44, 44, 44, 44, 44, 44, 44,
44, 44, 44, 44, 44, 44,
44, 44, 44, 44, 44, 44, 44, 44,
46, 46, 46,
43, 43,
))
// 省份汇总统计
val r1 = r0.map(a => (a.toString.slice(0, 2), 1))
// 自定义分区
val r2 = r1.reduceByKey(partitioner = new MyPartitioner, func = _ + _)
// 查看各分区元素
r2.mapPartitionsWithIndex((pId, iter) => {
println("分区" + pId + "元素:" + iter.toList)
iter
}).collect
// 二次聚合
val r3 = r2.reduceByKey(partitioner = new HashPartitioner(1), func = _ + _)
// 查看各分区元素
r3.mapPartitionsWithIndex((pId, iter) => {
println("分区" + pId + "元素:" + iter.toList)
iter
}).collect
// TopN
r3.sortBy(-_._2).take(2).foreach(println)
}
}
某次随机自定义分区打印
分区4元素:List()
分区6元素:List()
分区1元素:List()
分区3元素:List((44,1))
分区7元素:List((46,3), (43,2))
分区0元素:List((44,6))
分区5元素:List((44,7))
分区2元素:List((44,7))
二次聚合分区打印
分区0元素:List((46,3), (44,21), (43,2))

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)