
循环神经网络(三)RNN的输入与输出结构
在生成式任务中,RNN需要一个字、一个字、或一个词一个词地进行生成,在多次生成中逐渐构建出一个完整的句子或段落(所以你可能会观察到,ChatGPT这样的产品在说话的时候是一个词一个词往外蹦),所以生成式RNN的输出层和分类任务中的输出层有很大的区别。首先,NLP算法的生成并不能“无中生有”,模型只能从它曾经见过的字/词/短语中挑选它认为当下最能在语义上自洽的字/词/短语来进行输出,所以生成的本质是
- 输入结构
循环神经网络是为数不多的、能够在不改变网络结构情况下同时处理二维数据和三维数据的网络,但在PyTorch或tensorflow这样的深度学习框架的要求下,循环神经网络的输入结构一律为三维数据。
通常来说,最常见的结构就是之前提到过无数次的(batch_size,vocal_size,input_dimension),且循环是在vocal_size维度进行。不过,如果你曾经自学循环神经网络,或找寻过其他相关的材料,那你可能会发现,在某些材料当中,循环神经网络的输入被描述为(vocal_size,batch_size,input_dimension)结构。事实上,这两种结构是同一种结构,我们来看:
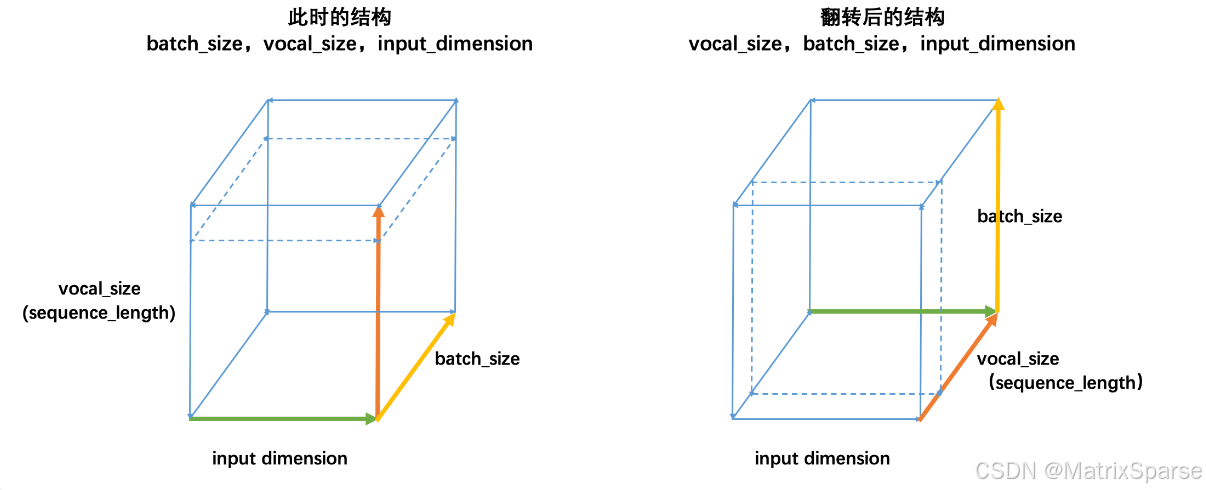
普通的结构(batch_size,vocal_size,input_dimension)如左图,此时循环神经网络会在vocal_size这一维度上循环,执行vocal_size个时间步的正向传播、即从上至下不断处理面向上方的二维表单(虚线标注处)。但立方体是可以被旋转的,当我们将立方体旋转一个角度,即需要处理的二维表单由正上方专向正前方时,我们就得到了(vocal_size,batch_size,input_dimension)的数据结构,此时循环神经网络依然是在vocal_size方向进行循环,只不过我们需要处理的表单方向由从上到下变成了从前往后。
因此不难发现,本质上这两种结构是一模一样的,但无论是哪种结构,循环神经网络都必须在时间步的方向进行循环。对于时序数据来说,这个方向是time_step的方向,对于文字数据来说,这个方向是vocab_size的方向。
- 输出结构
循环神经网络的输出层结构是由具体的输出任务决定的,但丰富的NLP任务让RNN输出层也变得丰富多彩。从网络结构的角度,我们可以将NLP的任务大略分成以下三类:
- 对语义/关系/文字本身进行有标签分类/标注的任务,包括但不限于——
文本分类:如情感分析、新闻分类、垃圾邮件检测等。
命名实体识别(NER):识别文本中的人名、地点、日期、组织等实体。
关系抽取:从文本中抽取实体之间的关系。
词性标注:为文本中的每个词指定其词性(名词、动词等)。
依存句法分析:解析句子中词语之间的依存关系。
核心指代消解:确定文本中的代词或名词短语指的是什么。
对这类有标签的经典任务,RNN的行为与CNN、DNN相似,会一次性判断出所有样本的标签。此时,输出层的神经元数量通常是标签的类别数量,例如具体有多少分类、具体有多少种关系、具体有多少种词性等等。所使用的损失也是相对常规的损失函数,例如交叉熵损失、Hinge损失(Hinge Loss)、负对数似然损失(Negative Log Likelihood Loss),特别的,如果是标注任务或NER任务,我们还可能使用Dice损失、条件随机场CRF损失(Conditional Random Fields Loss)等。
- 其他基于时序/语义的分类/回归任务,包括但不限于——
文本匹配和相似度计算:如自动问答评分、重复问题检测等。
时序任务:预测趋势变化(温度变化、股价变化)、根据历史行为预测未来行为变化(特定时间点下,用户是否购买、是否留存、是否点击)等等。
在这一类任务中,输出层神经元的情况是相当灵活的。例如,如果是对趋势进行预测的时序问题,在采用单步预测方法时,可能一次性输出未来所有时间点上的预测值,此时输出层上可能会有test_size个神经元;在采用多步预测方法时,一次只能预测一个值,则可能输出层上只有1个神经元。如果要一次性输出一个时间点下的多个行为变化(例如,输出下午4点的空气适度、温度、风向等指标),那神经元的数量可能与要输出的类别数量一致。整体来说,这个类别的任务在输出层面时比较简单的。
- 序列到序列、或对序列进行补充或回应的生成式任务,包括但不限于——
依据指令进行文本生成:如生成诗歌、生成故事、生成一段话,对现有的内容进行续写等等。
图-文生成、语音识别:根据输入的语音数据、图像数据生成描述、进行语音识别等等。
问答系统或对话生成:对用户的问题给出直接的答案,或针对用户给出的关键词生成一系列自问自答的对话等等
摘要生成:从长文本中生成简短的摘要、写总结、提取信息。
机器翻译:将一种语言翻译成另一种语言。
尽管NLP世界的预测任务都有非常专业的流程,但总体来说生成式任务的流程比分类/回归任务要复杂得多。在生成式任务中,RNN需要一个字、一个字、或一个词一个词地进行生成,在多次生成中逐渐构建出一个完整的句子或段落(所以你可能会观察到,ChatGPT这样的产品在说话的时候是一个词一个词往外蹦),所以生成式RNN的输出层和分类任务中的输出层有很大的区别。
首先,NLP算法的生成并不能“无中生有”,模型只能从它曾经见过的字/词/短语中挑选它认为当下最能在语义上自洽的字/词/短语来进行输出,所以生成的本质是“在模型曾见过的字/词/短语中,挑选出最有可能使句子语义自洽的那个字/词/短语”。在进行实际生成时,模型会对它所见过的每个字/词/短语都输出一个概率,预测这个字/词/短语是当前最佳输出的可能性,再从中挑选出可能性最高或较高的词进行输出。因此本质上来说,生成模型是多分类概率模型。
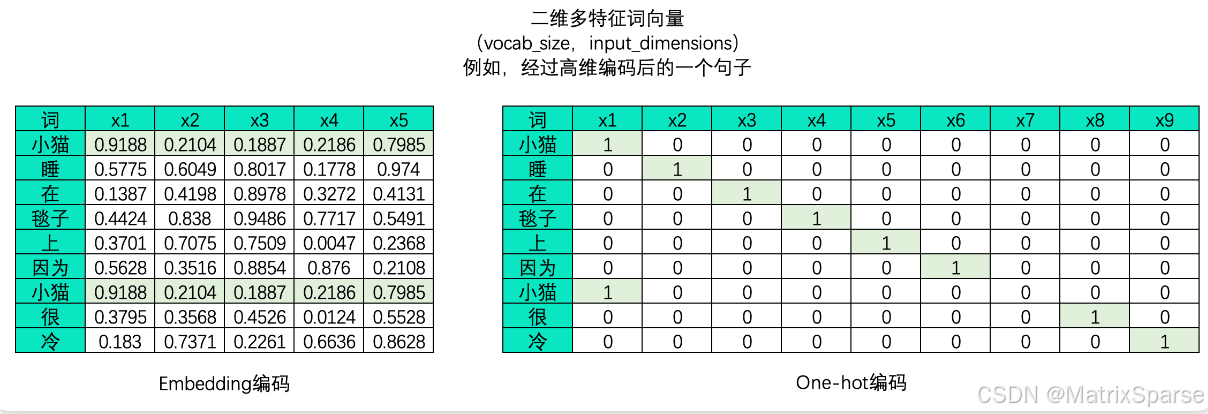
那模型曾见过的全部字/词/短语都在哪里呢?我们之前提到,在NLP数据进入模型之前,首先要进行分词和编码,这两个步骤会为我们构建当前训练集上所有字/词/短语对应的完整词汇表。此时,词汇表的大小vocab_size就是生成模型多分类的类别数量,因此在生成式任务中,输出层神经元数量原则上需要与词汇表的大小一致——假设训练集经过分词后有2w个不重复的字/词/短语,那输出层上就需要2w个神经元。此时,每个神经元对应着一个可能的字符/词,这个神经元的输出代表了该位置对应的词或字符被模型预测为下一个词或字符的概率,模型再选择概率最高或较高的词进行输出。
所以不难发现,一个生成式模型想要进行灵活、丰富的文字生成,就必须先见过巨量文字数据。同时,分词越细致,生成式模型在生成时的创造力就会越强。如果模型是基于字符级别的,那么输出层的神经元数量就是所有可能字符的数量,模型就可能基于字符构建新的词语。如果模型是基于词级别的,那么输出层的神经元数量就是词汇表中所有词的数量,模型就可能基于词语构建新的短语。但这样,模型自然对数据量、算力就会有更高的要求。
当然,在实际进行生成式任务时,我们会有很多手段来结局生成式模型中的问题——例如,每次预测下一个字时都必须对全部的数十万个字/单词生成概率,那计算效率实在是会过低;同时,如果模型只能生成“曾经见过”的词/短语的话,那远远达不到具备“认知智能”的水准,因此业内也有相当多的手段用于增强语言模型的创造力和泛化能力。
如果你还想挖掘更多宝藏内容,请关注公众号“智界元枢”。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)