
使用 vLLM 部署 bge-m3 / Qwen3-32B 模型(魔搭模型部署)
是一个高效的大型语言模型推理和服务系统,具有低延迟、高吞吐量的特点。支持 HuggingFace 格式的模型,并且可以通过简单的命令行启动服务。
·
vLLM说明
vLLM 是一个高效的大型语言模型推理和服务系统,具有低延迟、高吞吐量的特点。支持 HuggingFace 格式的模型,并且可以通过简单的命令行启动服务。
说明
CPU内存就不说了,Qwen3-32B大概需要40G以上的显存,m3为小模型,普通显卡即可
本次部署的服务器为腾讯云16核160G,H20显卡(96G),算力44+TFlops SP
基础环境:Driver 525.105.17,Python3.8,CUDA12,cuDNN8
部署
安装vllm
pip install vllm使用 ModelScope(魔搭)模型
# 用大陆的源,并且可以让 vLLM 自动从modelscope下载并加载模型
export VLLM_USE_MODELSCOPE=True
pip install modelscopemodelscope地址
用vllm启动m3
vllm serve BAAI/bge-m3 \
--gpu-memory-utilization 0.34 \
--port 10010 \
--host 0.0.0.0 &vllm启动q3-32b,32b需要更多的显卡内存
vllm serve qwen/Qwen3-32B \
--gpu-memory-utilization 0.88 \
--port 10011 \
--host 0.0.0.0 &32b稍微慢一点,启动成功后使用 BAAI/bge-m3 实现嵌入生成;使用 Qwen3-32B 实现文本生成任务。
也可以加载到本地服务运行
添加到系统运行服务器中启动
vim /etc/systemd/system/qwen.service[Unit]
Description=qwen3-32b
After=network.target
[Service]
Type=simple
Environment=VLLM_USE_MODELSCOPE=True
ExecStart=/usr/local/bin/vllm serve Qwen/Qwen3-32B --gpu-memory-utilization 0.88 --port 10011 --host 0.0.0.0
WorkingDirectory=/data/Qwen3-32B
User=root
Restart=on-failure
RestartSec=10
Environment=PYTHONUNBUFFERED=1
[Install]
WantedBy=multi-user.target重新加载 systemd 并启动服务
systemctl daemon-reexec
systemctl daemon-reload
systemctl enable qwen
systemctl start qwen
#查看运行状态
systemctl status qwen
#查看输出日志(实时)
journalctl -fu qwen
#如果失败,查看最近日志
journalctl -xeu qwen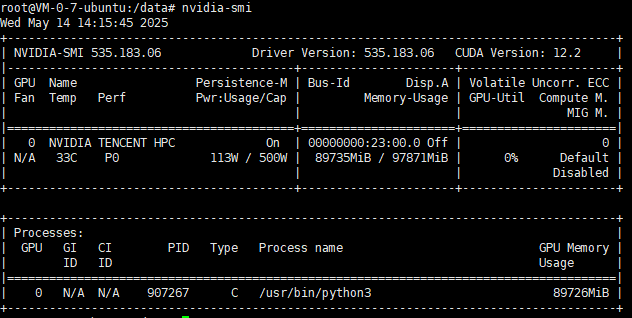


技术共进,成长同行——讯飞AI开发者社区
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)