
如何使用深度学习模型进行分割或检测任务 智慧工地数据集(戴安全帽和未戴安全帽两类) 机器(PC运输车、自卸卡车、混凝土搅拌车、挖掘机、压路机、推土机和轮式装载机七类等
如何使用深度学习模型进行分割或检测任务 智慧工地数据集(戴安全帽和未戴安全帽两类) 机器(PC运输车、自卸卡车、混凝土搅拌车、挖掘机、压路机、推土机和轮式装载机七类等
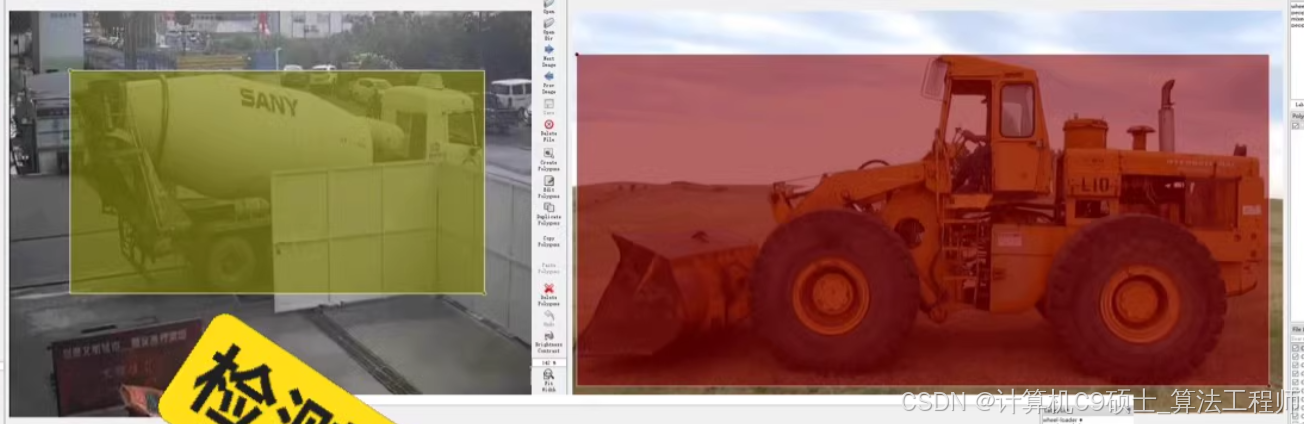
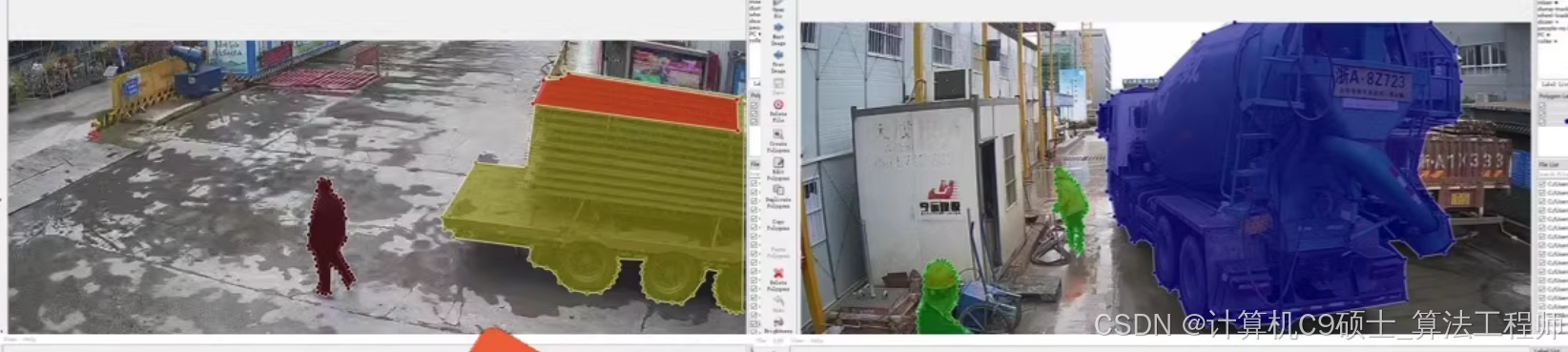

智慧工地数据集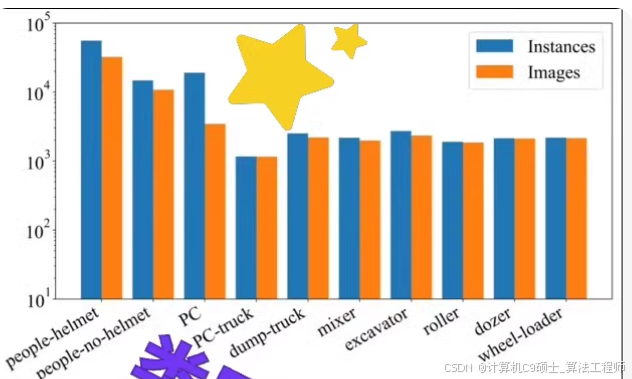
数据背景
建筑工地是一个复杂且动态的环境,涉及多种生产要素,如工人、机器和材料。及时准确地识别和管理这些要素对于提高工地的安全性和管理效率至关重要。智慧工地数据集包含5万张图像,涵盖了10种常见的建筑对象类别,每张图像都有详细的标注,适合用于训练和评估深度学习模型。
应用领域
AI+建筑工地生产要素分割
AI+建筑工地生产要素检测
文件目录
深色版本
smart_construction_dataset/
├── images/
│ ├── 000001.jpg
│ ├── 000002.jpg
│ └── …
├── annotations/
│ ├── 000001.json
│ ├── 000002.json
│ └── …
├── train.txt
├── valid.txt
├── test.txt
├── classes.txt
├── README.txt
├── models/
│ └── unet/
│ └── yolov5/
├── src/
│ ├── train_segmentation.py
│ ├── train_detection.py
│ ├── predict_segmentation.py
│ ├── predict_detection.py
│ ├── utils.py
│ ├── dataset.py
├── weights/
│ └── segmentation_best_model.pth
│ └── detection_best_model.pth
├── requirements.txt
└── README.md
数据说明
数据集规模:共包含5万张图像样张,超8.3万个标注实例。
图像格式:JPG
标注格式:JSON
类别:10种常见建筑对象类别,分为三大类:
工人:戴安全帽和未戴安全帽
机器:PC运输车、自卸卡车、混凝土搅拌车、挖掘机、压路机、推土机和轮式装载机
材料:预制构件
预处理:每张图像都有对应的JSON标注文件,标注格式为labelme格式,支持polygon多边形框和rectangle矩形框,分别用于语义分割/实例分割和目标检测。
- 安装依赖
首先,确保你已经安装了必要的库。创建一个requirements.txt文件,内容如下:
深色版本
torch
torchvision
numpy
pandas
matplotlib
tqdm
pyyaml
opencv-python
albumentations
然后,使用以下命令安装依赖:
bash
深色版本
pip install -r requirements.txt
2. 数据集准备
确保你的数据集已经按照以下结构组织:
深色版本
smart_construction_dataset/
├── images/
│ ├── 000001.jpg
│ ├── 000002.jpg
│ └── …
├── annotations/
│ ├── 000001.json
│ ├── 000002.json
│ └── …
├── train.txt
├── valid.txt
├── test.txt
├── classes.txt
├── README.txt
每个文件夹中包含对应的图像文件和标注文件。确保所有图像文件都是.jpg格式,标注文件是.json格式。
- 数据集类
创建一个数据集类,用于加载和预处理数据。
3.1 src/dataset.py
python
深色版本
import os
import json
import cv2
import torch
from torch.utils.data import Dataset
from torchvision import transforms
import numpy as np
class SmartConstructionDataset(Dataset):
def init(self, image_dir, annotation_dir, split_file, transform=None, mode=‘segmentation’):
self.image_dir = image_dir
self.annotation_dir = annotation_dir
self.transform = transform
self.mode = mode
self.image_ids = []
with open(split_file, 'r') as f:
for line in f:
self.image_ids.append(line.strip())
def __len__(self):
return len(self.image_ids)
def __getitem__(self, index):
image_id = self.image_ids[index]
image_path = os.path.join(self.image_dir, f"{image_id}.jpg")
annotation_path = os.path.join(self.annotation_dir, f"{image_id}.json")
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
with open(annotation_path, 'r') as f:
annotation = json.load(f)
if self.mode == 'segmentation':
masks = []
for shape in annotation['shapes']:
if shape['shape_type'] == 'polygon':
points = np.array(shape['points'], dtype=np.int32)
mask = np.zeros(image.shape[:2], dtype=np.uint8)
cv2.fillPoly(mask, [points], 1)
masks.append(mask)
mask = np.stack(masks, axis=-1)
mask = np.any(mask, axis=-1).astype(np.uint8)
elif self.mode == 'detection':
bboxes = []
labels = []
for shape in annotation['shapes']:
if shape['shape_type'] == 'rectangle':
points = np.array(shape['points'], dtype=np.int32)
x_min, y_min = points.min(axis=0)
x_max, y_max = points.max(axis=0)
bboxes.append([x_min, y_min, x_max, y_max])
labels.append(self.class_to_idx[shape['label']])
bboxes = np.array(bboxes, dtype=np.float32)
labels = np.array(labels, dtype=np.int64)
if self.transform:
if self.mode == 'segmentation':
transformed = self.transform(image=image, mask=mask)
image = transformed['image']
mask = transformed['mask']
elif self.mode == 'detection':
transformed = self.transform(image=image, bboxes=bboxes, labels=labels)
image = transformed['image']
bboxes = transformed['bboxes']
labels = transformed['labels']
if self.mode == 'segmentation':
return image, mask
elif self.mode == 'detection':
target = {'boxes': bboxes, 'labels': labels}
return image, target
def get_data_loaders(image_dir, annotation_dir, train_file, valid_file, test_file, batch_size=16, num_workers=4, mode=‘segmentation’):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
train_dataset = SmartConstructionDataset(image_dir, annotation_dir, train_file, transform=transform, mode=mode)
valid_dataset = SmartConstructionDataset(image_dir, annotation_dir, valid_file, transform=transform, mode=mode)
test_dataset = SmartConstructionDataset(image_dir, annotation_dir, test_file, transform=transform, mode=mode)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, collate_fn=lambda x: tuple(zip(*x)))
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers, collate_fn=lambda x: tuple(zip(*x)))
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers, collate_fn=lambda x: tuple(zip(*x)))
return train_loader, valid_loader, test_loader
- 分割模型训练代码
4.1 src/train_segmentation.py
python
深色版本
import torch
import torch.optim as optim
import torch.nn as nn
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm
from src.dataset import get_data_loaders
from torchvision.models.segmentation import deeplabv3_resnet101
def train_segmentation_model(image_dir, annotation_dir, train_file, valid_file, epochs=100, batch_size=16, learning_rate=1e-4):
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
model = deeplabv3_resnet101(pretrained=True)
model.classifier[4] = nn.Conv2d(256, 1, kernel_size=(1, 1), stride=(1, 1))
model = model.to(device)
train_loader, valid_loader, _ = get_data_loaders(image_dir, annotation_dir, train_file, valid_file, "", batch_size=batch_size, mode='segmentation')
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
criterion = nn.BCEWithLogitsLoss()
writer = SummaryWriter()
for epoch in range(epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, masks in tqdm(train_loader, desc=f"Epoch {epoch + 1}/{epochs}"):
images, masks = images.to(device), masks.to(device)
optimizer.zero_grad()
outputs = model(images)['out']
loss = criterion(outputs, masks.unsqueeze(1))
loss.backward()
optimizer.step()
running_loss += loss.item()
preds = torch.sigmoid(outputs) > 0.5
correct += (preds == masks.unsqueeze(1)).sum().item()
total += masks.numel()
train_loss = running_loss / len(train_loader)
train_acc = correct / total
writer.add_scalar('Training Loss', train_loss, epoch)
writer.add_scalar('Training Accuracy', train_acc, epoch)
model.eval()
running_valid_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, masks in valid_loader:
images, masks = images.to(device), masks.to(device)
outputs = model(images)['out']
loss = criterion(outputs, masks.unsqueeze(1))
running_valid_loss += loss.item()
preds = torch.sigmoid(outputs) > 0.5
correct += (preds == masks.unsqueeze(1)).sum().item()
total += masks.numel()
valid_loss = running_valid_loss / len(valid_loader)
valid_acc = correct / total
writer.add_scalar('Validation Loss', valid_loss, epoch)
writer.add_scalar('Validation Accuracy', valid_acc, epoch)
print(f"Epoch {epoch + 1}/{epochs}, Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}, Valid Loss: {valid_loss:.4f}, Valid Acc: {valid_acc:.4f}")
torch.save(model.state_dict(), "weights/segmentation_best_model.pth")
writer.close()
if name == “main”:
image_dir = “smart_construction_dataset/images”
annotation_dir = “smart_construction_dataset/annotations”
train_file = “smart_construction_dataset/train.txt”
valid_file = “smart_construction_dataset/valid.txt”
train_segmentation_model(image_dir, annotation_dir, train_file, valid_file)
5. 目标检测模型训练代码
5.1 src/train_detection.py
python
深色版本
import torch
import torch.optim as optim
import torch.nn as nn
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm
from src.dataset import get_data_loaders
from torchvision.models.detection import fasterrcnn_resnet50_fpn
def train_detection_model(image_dir, annotation_dir, train_file, valid_file, epochs=100, batch_size=16, learning_rate=1e-4):
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
model = fasterrcnn_resnet50_fpn(pretrained=True)
num_classes = 11 # 包括背景类
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = torch.nn.modules.linear.Linear(in_features, num_classes)
model = model.to(device)
train_loader, valid_loader, _ = get_data_loaders(image_dir, annotation_dir, train_file, valid_file, "", batch_size=batch_size, mode='detection')
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss()
writer = SummaryWriter()
for epoch in range(epochs):
model.train()
running_loss = 0.0
for images, targets in tqdm(train_loader, desc=f"Epoch {epoch + 1}/{epochs}"):
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
optimizer.zero_grad()
losses = model(images, targets)
loss = sum(loss for loss in losses.values())
loss.backward()
optimizer.step()
running_loss += loss.item()
train_loss = running_loss / len(train_loader)
writer.add_scalar('Training Loss', train_loss, epoch)
model.eval()
running_valid_loss = 0.0
with torch.no_grad():
for images, targets in valid_loader:
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
losses = model(images, targets)
loss = sum(loss for loss in losses.values())
running_valid_loss += loss.item()
valid_loss = running_valid_loss / len(valid_loader)
writer.add_scalar('Validation Loss', valid_loss, epoch)
print(f"Epoch {epoch + 1}/{epochs}, Train Loss: {train_loss:.4f}, Valid Loss: {valid_loss:.4f}")
torch.save(model.state_dict(), "weights/detection_best_model.pth")
writer.close()
if name == “main”:
image_dir = “smart_construction_dataset/images”
annotation_dir = “smart_construction_dataset/annotations”
train_file = “smart_construction_dataset/train.txt”
valid_file = “smart_construction_dataset/valid.txt”
train_detection_model(image_dir, annotation_dir, train_file, valid_file)
6. 模型评估
训练完成后,可以通过测试集来评估模型的性能。示例如下:
6.1 src/predict_segmentation.py
python
深色版本
import torch
import matplotlib.pyplot as plt
from torchvision.models.segmentation import deeplabv3_resnet101
from src.dataset import get_data_loaders
import numpy as np
def predict_and_plot_segmentation(image_dir, annotation_dir, test_file, model_path, num_samples=5):
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
model = deeplabv3_resnet101(pretrained=True)
model.classifier[4] = nn.Conv2d(256, 1, kernel_size=(1, 1), stride=(1, 1))
model.load_state_dict(torch.load(model_path))
model = model.to(device)
model.eval()
_, _, test_loader = get_data_loaders(image_dir, annotation_dir, "", test_file, "", batch_size=1, num_workers=4, mode='segmentation')
fig, axes = plt.subplots(num_samples, 2, figsize=(10, 5 * num_samples))
with torch.no_grad():
for i, (images, masks) in enumerate(test_loader):
if i >= num_samples:
break
images, masks = images.to(device), masks.to(device)
outputs = model(images)['out']
preds = torch.sigmoid(outputs) > 0.5
preds = preds.squeeze().cpu().numpy().astype(np.uint8)
masks = masks.squeeze().cpu().numpy().astype(np.uint8)
images = images.squeeze().cpu().numpy().transpose((1, 2, 0))
ax = axes[i] if num_samples > 1 else axes
ax[0].imshow(images)
ax[0].set_title("Input Image")
ax[0].axis('off')
ax[1].imshow(preds, cmap='gray')
ax[1].set_title("Predicted Mask")
ax[1].axis('off')
plt.tight_layout()
plt.show()
if name == “main”:
image_dir = “smart_construction_dataset/images”
annotation_dir = “smart_construction_dataset/annotations”
test_file = “smart_construction_dataset/test.txt”
model_path = “weights/segmentation_best_model.pth”
predict_and_plot_segmentation(image_dir, annotation_dir, test_file, model_path)
6.2 src/predict_detection.py
python
深色版本
import torch
import matplotlib.pyplot as plt
from torchvision.models.detection import fasterrcnn_resnet50_fpn
from src.dataset import get_data_loaders
import numpy as np
def predict_and_plot_detection(image_dir, annotation_dir, test_file, model_path, num_samples=5):
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
model = fasterrcnn_resnet50_fpn(pretrained=True)
num_classes = 11 # 包括背景类
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = torch.nn.modules.linear.Linear(in_features, num_classes)
model.load_state_dict(torch.load(model_path))
model = model.to(device)
model.eval()
_, _, test_loader = get_data_loaders(image_dir, annotation_dir, "", test_file, "", batch_size=1, num_workers=4, mode='detection')
fig, axes = plt.subplots(num_samples, 2, figsize=(10, 5 * num_samples))
with torch.no_grad():
for i, (images, targets) in enumerate(test_loader):
if i >= num_samples:
break
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
outputs = model(images)
predictions = outputs[0]['boxes'].cpu().numpy()
labels = outputs[0]['labels'].cpu().numpy()
images = images[0].cpu().numpy().transpose((1, 2, 0))
ax = axes[i] if num_samples > 1 else axes
ax[0].imshow(images)
ax[0].set_title("Input Image")
ax[0].axis('off')
ax[1].imshow(images)
for box, label in zip(predictions, labels):
ax[1].add_patch(plt.Rectangle((box[0], box[1]), box[2] - box[0], box[3] - box[1], fill=False, edgecolor='red', linewidth=2))
ax[1].text(box[0], box[1], str(label), color='red', fontsize=12)
ax[1].set_title("Predicted Bounding Boxes")
ax[1].axis('off')
plt.tight_layout()
plt.show()
if name == “main”:
image_dir = “smart_construction_dataset/images”
annotation_dir = “smart_construction_dataset/annotations”
test_file = “smart_construction_dataset/test.txt”
model_path = “weights/detection_best_model.pth”
predict_and_plot_detection(image_dir, annotation_dir, test_file, model_path)
7. 运行项目
确保你的数据集已经放在相应的文件夹中。
在项目根目录下运行以下命令启动分割模型训练:
bash
深色版本
python src/train_segmentation.py
在项目根目录下运行以下命令启动检测模型训练:
bash
深色版本
python src/train_detection.py
训练完成后,运行以下命令进行评估和可视化:
bash
深色版本
python src/predict_segmentation.py
python src/predict_detection.py
8. 功能说明
数据集类:SmartConstructionDataset类用于加载和预处理数据。
数据加载器:get_data_loaders函数用于创建训练、验证和测试数据加载器。
分割模型训练:train_segmentation.py脚本用于训练DeepLabV3+模型。
检测模型训练:train_detection.py脚本用于训练Faster R-CNN模型。
分割模型评估:predict_segmentation.py脚本用于评估分割模型性能,并可视化输入图像和预测结果。
检测模型评估:predict_detection.py脚本用于评估检测模型性能,并可视化输入图像、真实标签和预测结果。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)