
从零开始学习构建自己的机器学习模型 - 带垃圾短信识别实战
垃圾短信分类是现代通信安全中不可忽视的问题,通过使用Python和机器学习技术,我们可以快速构建一个高效的垃圾短信分类模型。从数据加载到文本特征提取。本文将深入探讨如何使用逻辑回归等机器学习算法,通过简单易懂的代码示例,完成垃圾短信的高效分类。
垃圾短信分类是现代通信安全中不可忽视的问题,尤其在数据驱动的时代,精准识别垃圾短信对用户体验和信息安全至关重要。通过使用Python和机器学习技术,结合强大的文本处理工具如TF-IDF,我们可以快速构建一个高效的垃圾短信分类模型。从数据加载到文本特征提取,再到模型训练与评估,每一步都充分体现了数据处理与模型优化的协同作用。本文将深入探讨如何使用逻辑回归等机器学习算法,通过简单易懂的代码示例,完成垃圾短信的高效分类。
目录
1. 什么是机器学习?
机器学习是利用算法让计算机从数据中学习的一种技术,摆脱了显式编程的限制。简单来说,它是一种通过数据“教会”计算机如何完成任务的方法。
常见的机器学习任务:
- 回归问题:预测数值(如房价、股票价格)。
- 分类问题:分类标签(如垃圾短信、是否患病)。
- 聚类问题:发现数据中的隐藏模式(如用户分组)。
2. 数据预处理:机器学习的第一步
原始数据通常并不适合直接使用,我们需要将其转化为模型可以理解的格式。
2.1 数据加载
我们将使用Scikit-learn的datasets模块加载一个内置数据集,例如波士顿房价数据。
from sklearn.datasets import load_boston
import pandas as pd
# 加载数据
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['PRICE'] = boston.target
# 查看数据前五行
print(df.head())
2.2 数据清洗
处理缺失值和异常值是数据预处理的重要环节。
# 检查是否有缺失值
print(df.isnull().sum())
# 如果有缺失值,可以用均值填充
df.fillna(df.mean(), inplace=True)
2.3 特征缩放
机器学习模型对特征范围敏感,尤其是梯度下降类算法。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_features = scaler.fit_transform(df.drop('PRICE', axis=1))
3. 实现经典机器学习算法
我们以线性回归和决策树为例,介绍它们的原理和实现。
3.1 线性回归
线性回归适用于预测数值型数据,模型假设特征与目标之间是线性关系。
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 数据集划分
X = scaled_features
y = df['PRICE']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 模型训练
lr_model = LinearRegression()
lr_model.fit(X_train, y_train)
# 模型评估
y_pred = lr_model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"线性回归的均方误差: {mse}")
3.2 决策树
决策树通过划分特征空间创建规则,适合解决非线性问题。
from sklearn.tree import DecisionTreeRegressor
# 模型训练
tree_model = DecisionTreeRegressor(max_depth=5, random_state=42)
tree_model.fit(X_train, y_train)
# 模型评估
y_pred_tree = tree_model.predict(X_test)
mse_tree = mean_squared_error(y_test, y_pred_tree)
print(f"决策树的均方误差: {mse_tree}")
4. 模型调优:提升性能的关键
4.1 超参数调整
通过网格搜索优化模型的超参数。
from sklearn.model_selection import GridSearchCV
# 定义参数网格
param_grid = {'max_depth': [3, 5, 7, 9]}
# 网格搜索
grid_search = GridSearchCV(DecisionTreeRegressor(), param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
print(f"最佳参数: {grid_search.best_params_}")
4.2 交叉验证
交叉验证可以更可靠地评估模型性能。
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_model, X, y, cv=5, scoring='neg_mean_squared_error')
print(f"交叉验证均方误差: {-scores.mean()}")
5. 项目案例:垃圾短信分类
都是奔着案例来的吧,不多说直接上。
分类任务是机器学习中另一大经典场景。以下是实现垃圾短信分类的流程:
1. 数据加载
加载 spam.csv 数据集,并对标签进行编码:
数据集在文章顶部展示,和文章绑定的嗷
import pandas as pd
# 加载数据
data = pd.read_csv('spam.csv') # 确保 spam.csv 文件在当前目录下
data['label'] = data['label'].map({'垃圾': 1, '正常': 0}) # 标签编码
2. 文本特征提取
使用 TfidfVectorizer 提取文本特征:
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(stop_words='english', max_features=5000) # 限制特征数量
X = vectorizer.fit_transform(data['text']) # 转化为特征矩阵
y = data['label'] # 标签
3. 模型训练与评估
使用逻辑回归进行分类,并评估模型性能:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# 模型训练
model = LogisticRegression()
model.fit(X_train, y_train)
# 模型评估
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"逻辑回归分类准确率: {accuracy:.2f}")
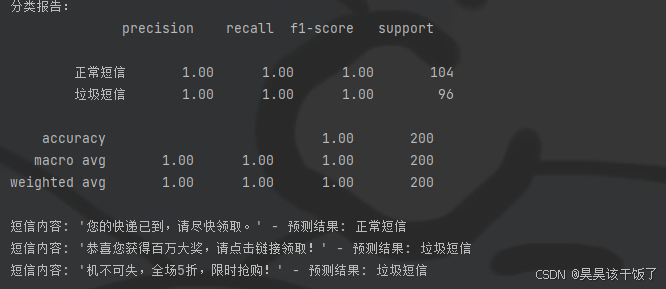
print("分类报告:")
print(classification_report(y_test, y_pred, target_names=["正常短信", "垃圾短信"]))
可选:测试新短信
使用模型对未见短信进行预测:
# 测试短信
test_sms = [
"您的快递已到,请尽快领取。",
"恭喜您获得百万大奖,请点击链接领取!",
"机不可失,全场5折,限时抢购!"
]
test_vectorized = vectorizer.transform(test_sms)
predictions = model.predict(test_vectorized)
# 输出预测结果
for sms, label in zip(test_sms, predictions):
print(f"短信内容: '{sms}' - 预测结果: {'垃圾短信' if label == 1 else '正常短信'}")
完整版
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# 1. 数据加载
# 加载垃圾短信数据集
data = pd.read_csv('spam.csv') # 确保 spam.csv 文件在当前目录下
data['label'] = data['label'].map({'垃圾': 1, '正常': 0}) # 标签编码:垃圾=1,正常=0
# 查看数据集信息
print("数据集概览:")
print(data.head())
# 2. 文本特征提取
# 使用TF-IDF方法提取短信特征
vectorizer = TfidfVectorizer(stop_words='english', max_features=5000) # 限制特征数量
X = vectorizer.fit_transform(data['text']) # 转化为特征矩阵
y = data['label'] # 提取标签
print(f"特征矩阵形状: {X.shape}")
# 3. 模型训练与评估
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# 使用逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)
# 模型预测与评估
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"逻辑回归分类准确率: {accuracy:.2f}")
print("分类报告:")
print(classification_report(y_test, y_pred, target_names=["正常短信", "垃圾短信"]))
# 测试新短信
test_sms = [
"您的快递已到,请尽快领取。",
"恭喜您获得百万大奖,请点击链接领取!",
"机不可失,全场5折,限时抢购!"
]
test_vectorized = vectorizer.transform(test_sms)
predictions = model.predict(test_vectorized)
# 输出测试结果
for sms, label in zip(test_sms, predictions):
print(f"短信内容: '{sms}' - 预测结果: {'垃圾短信' if label == 1 else '正常短信'}")
看看结果


技术共进,成长同行——讯飞AI开发者社区
更多推荐

 20
20 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)