
YOLOv8目标检测实战-(TensorRT原生API搭建网络和使用Parser搭建网络)
①Conv = conv+BN+SiLU,stride=2表示下采样,在backbone中有5个stride=2的conv模块,2的5次方是32,640/32=20,所以就有了20x20的特征图。上采样:上采样将深层特征图的分辨率提高(如从20×20上采样到40×40),与浅层特征拼接,保留细节信息的同时增强语义表达能力。②Bottleneck有add为true和false两种,⑤因为有两种上采样
文章目录
一、原理篇
1)Trt基础知识
- wts流程
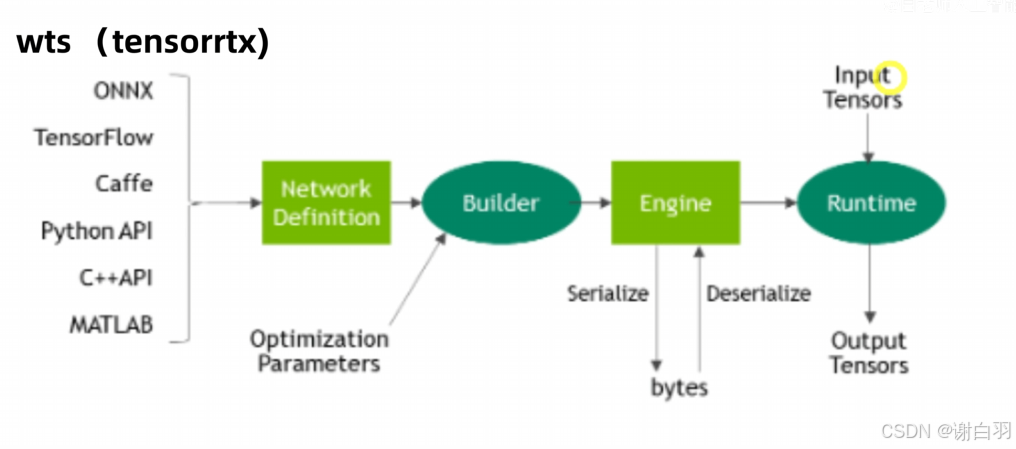
- 整体组件

- 转换成C++的推理方式
1、框架自带trt接口:例如TF-TRT,Torch-TensorRT
2、使用tensorRT自带的parser,遇到不支持的算子改parser、plugin、改网络
3、使用TensorRT原生API搭建网络,遇到不支持的算子就写plugin
- 部署方式
①tensorflow
②只是trt runtime api
③triton
- 使用trt步骤
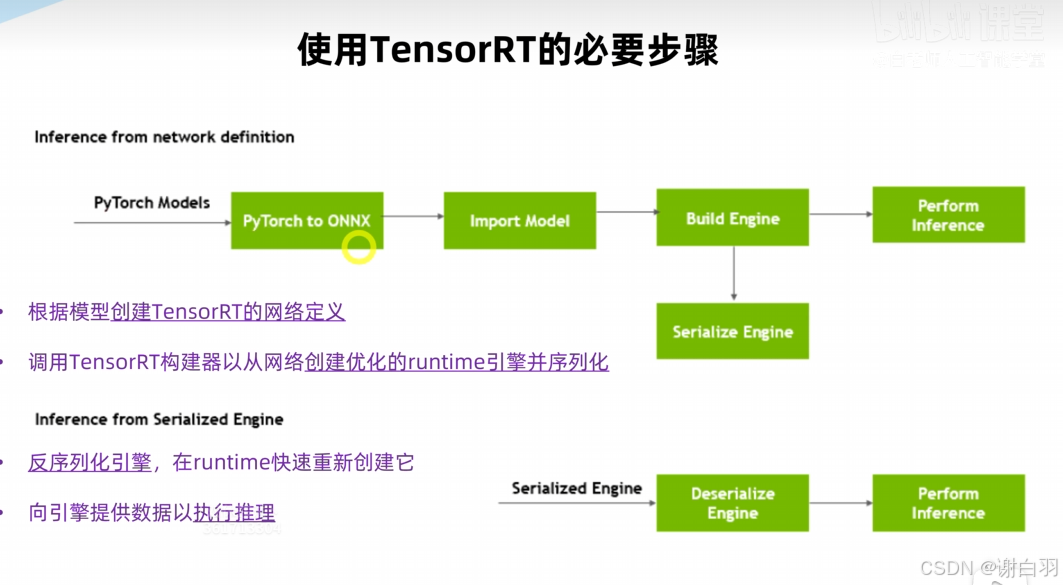
更仔细点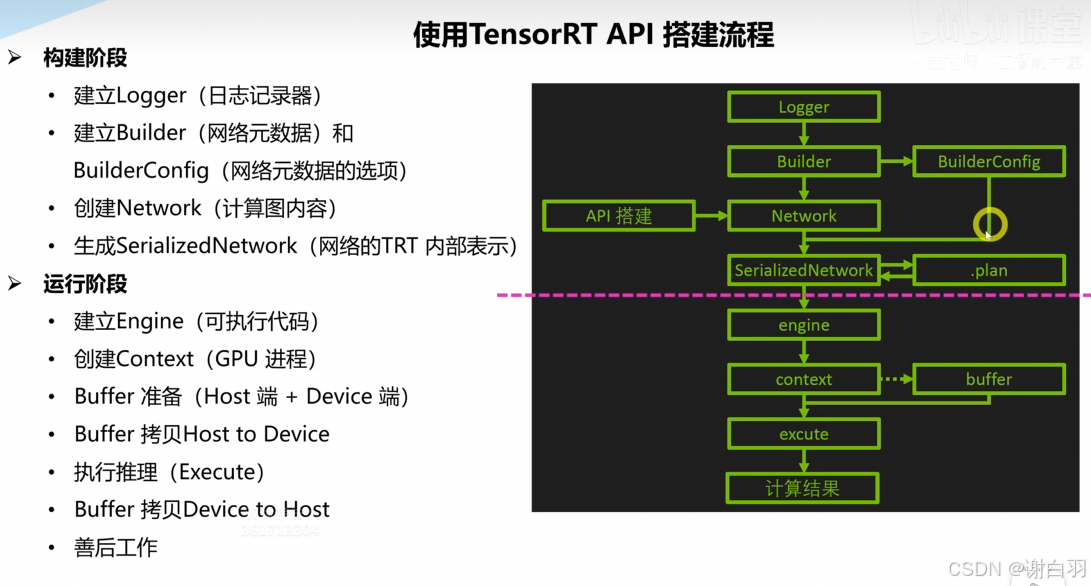
2)Trt plugin
-
plugin简介

在plugin节点附近加入reformat节点解决自定义算子与原生算子间的数据格式/精度兼容性问题 -
plugin的类型
 IPluginV2Ext 的 getOutputDimensions 方法需在
IPluginV2Ext 的 getOutputDimensions 方法需在构建期固定输出维度(包括 batch size),无法在运行时根据输入 batch 动态调整
- 接下来通过问题来介绍:
1、怎么从头实现一个plugin,需要写哪些类和函数
2、怎么把plugin接到tensorRT网络中去?要怎么包装kernel以便TensorRT识别?
3、TensorRT要怎么参与Plugin的资源管理?两者之间要交换什么信息?
4、plugin能不能序列化".plan"文件中去?
是的可以,为此,必须实现serialize和deserialize方法
5、plugin有什么扩展性?FP16/INT8,Dynamic shape,data-dependent-shape,。。。
6、plugin与原生layer相比性能怎么样?
-
怎么在tensorRT中导入plugin?

-
plugin的关键API-序列化和反序列化

-
plugin的关键API-资源管理函数

-
plugin与trt的交互
①构建期间
②运行期间
3)int8量化算法和原理


- 查看GPU是否支持FP16/INT8

4)cuda编程
- 整体流程

cuda c习题讲解
5)onnx基础知识
6)yolov8网络架构
6.1 yolov5网络架构图
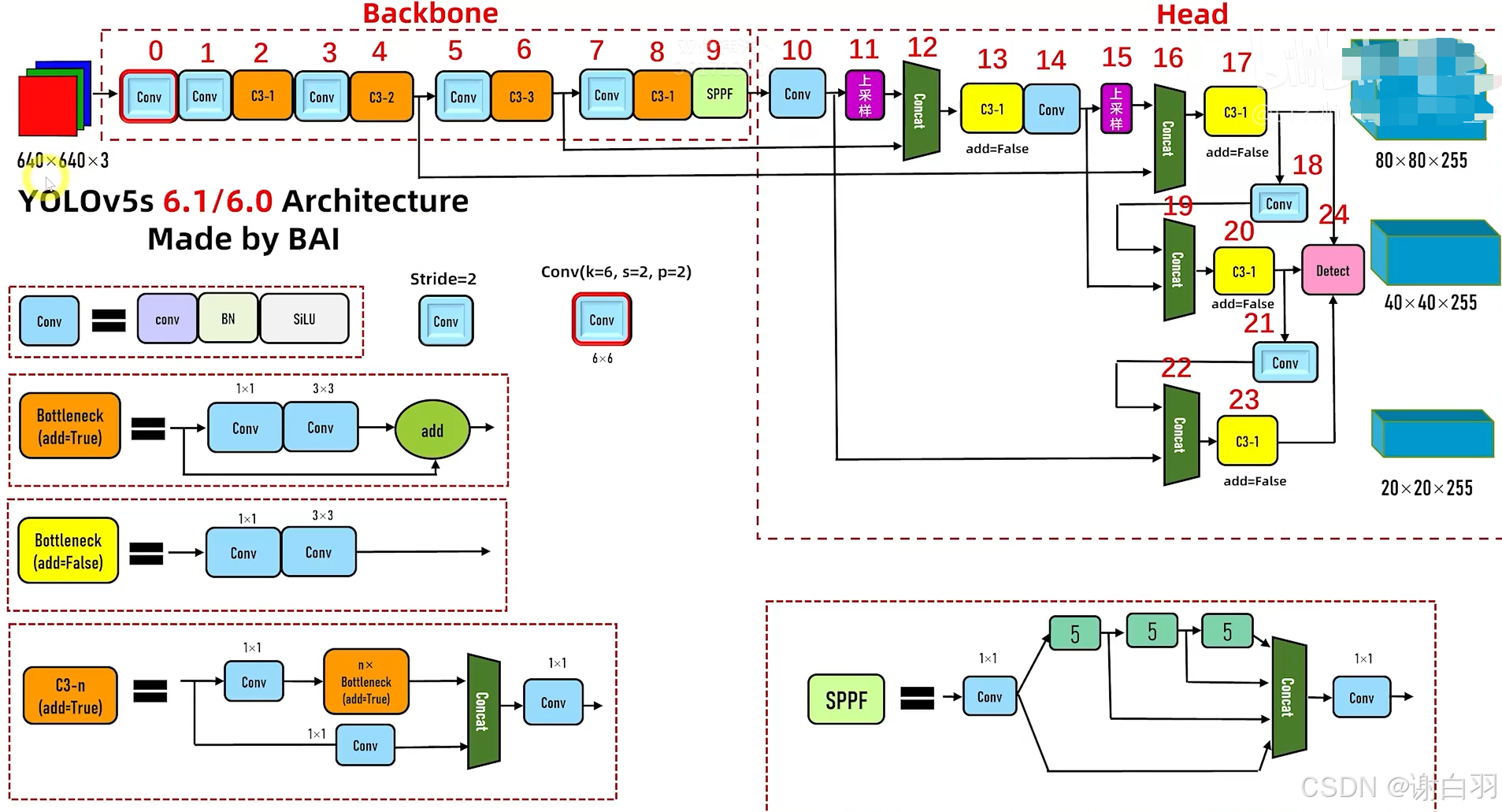
下面是主要架构展示:
①Conv = conv+BN+SiLU,stride=2表示下采样,在backbone中有5个stride=2的conv模块,2的5次方是32,640/32=20,所以就有了20x20的特征图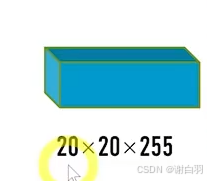
②Bottleneck有add为true和false两种,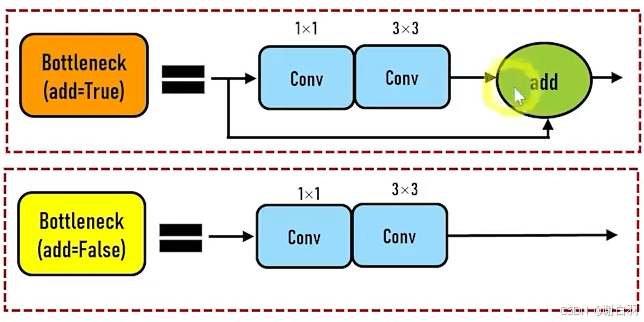
③C3-n,n表示有n个Bottleneck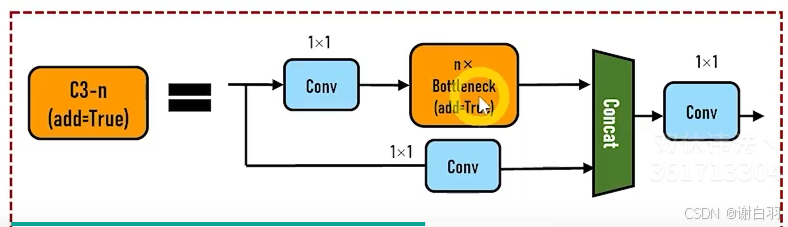
④SPFF:改进的空间计算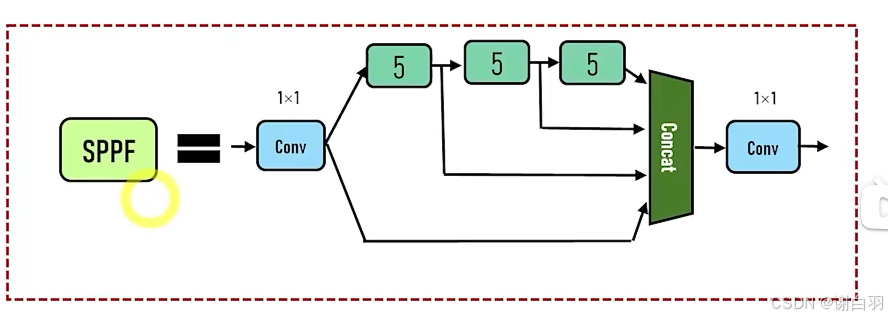
⑤因为有两种上采样的存在,所以输出有三种维度的特征图
上采样:上采样将深层特征图的分辨率提高(如从20×20上采样到40×40),与浅层特征拼接,保留细节信息的同时增强语义表达能力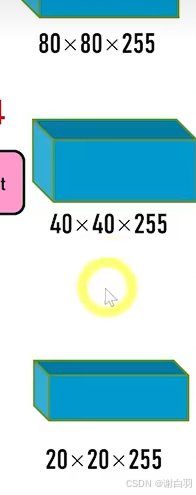
⑥225表示什么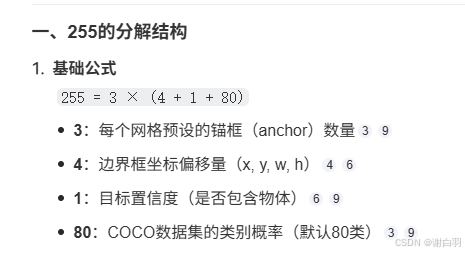
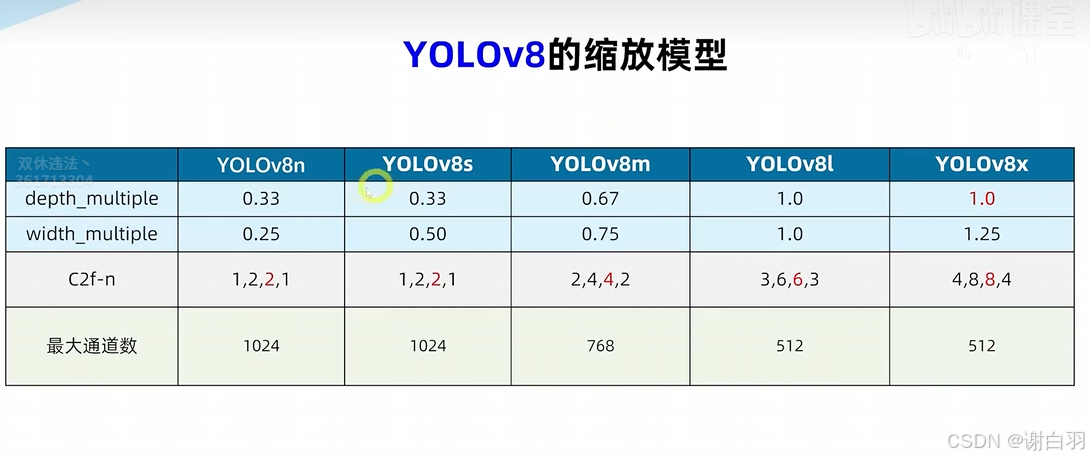
⑦yolov5的缩放模型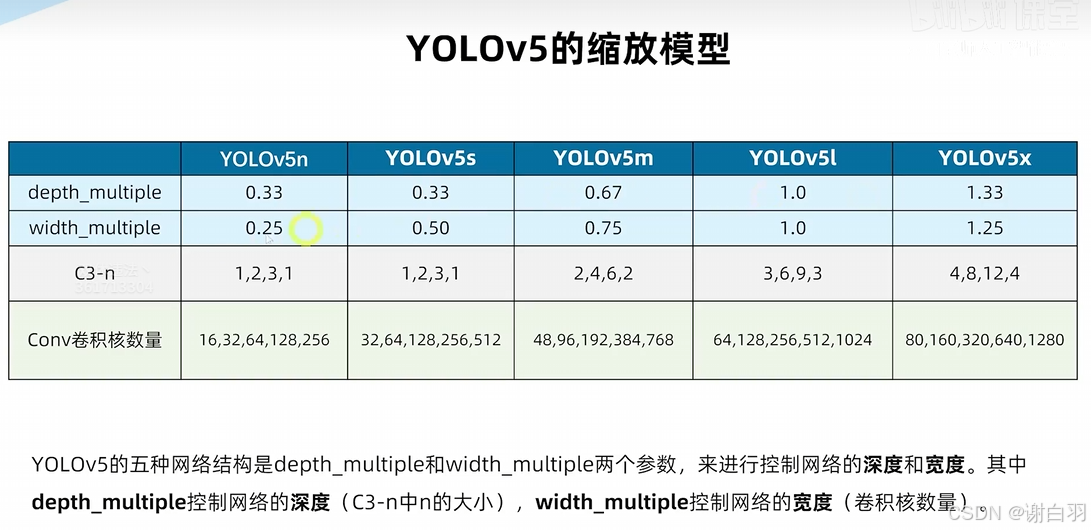
第三个数字依次都是n的大小,图中的C3模块表示模型都各有四个C3,只是n各不相同
6.2 yolov8s网络架构
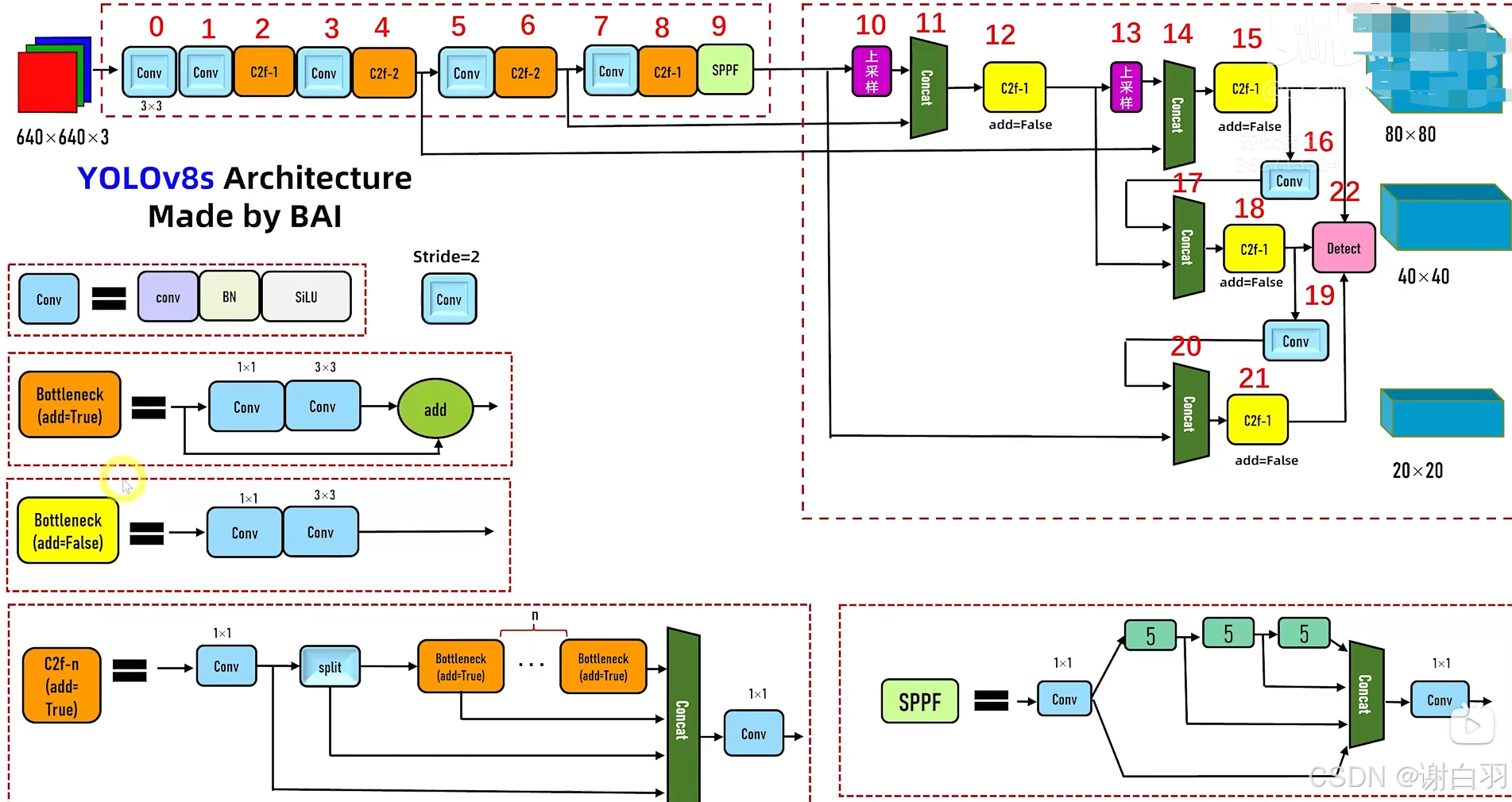
-
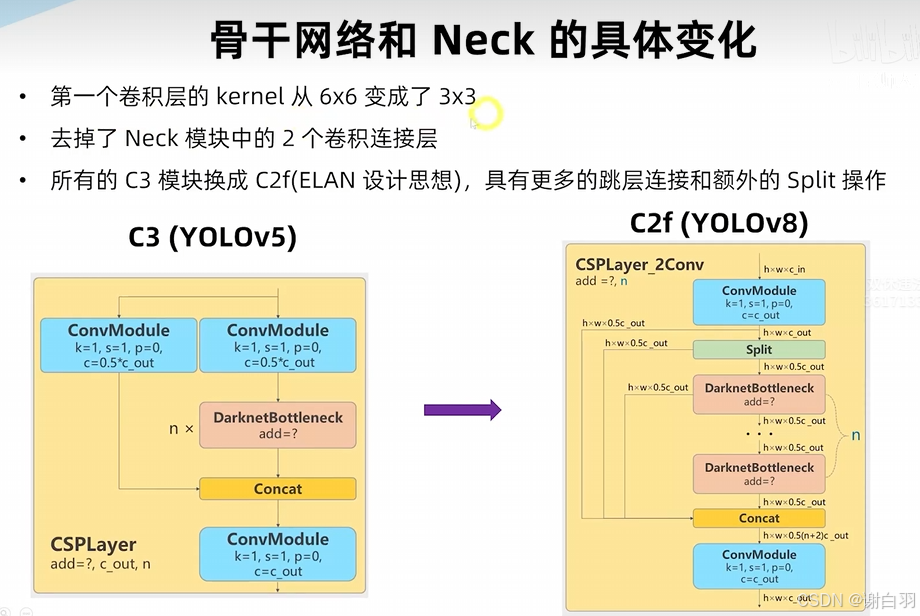
与yolo5的不同点
①第一个conv不再是6x6的,而是3x3的
②C3-n模块换成了C2f模块
③C2f-n模块:
1)split是在channel维度上做split
2)后面每个bottleneck都有抽头,合起来concat有n+2个抽头 -
yolov8网络的输入和输出(到detect)
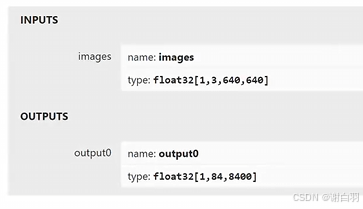
①输入
1.3.640,640:
1:batch_size
3:channel
640x640:Height & Width
②输出
1,84,8400:
1:output0的第一个维度表示批次大小
84:84=4+80,4表示检测奥物体边界框的坐标,80表示物体属于每个类别的概率
8400:可能检测到物体的数量,80*80+40*40+20*20
- yolov8缩放模型
- 对比yolov5和yolov8的变化
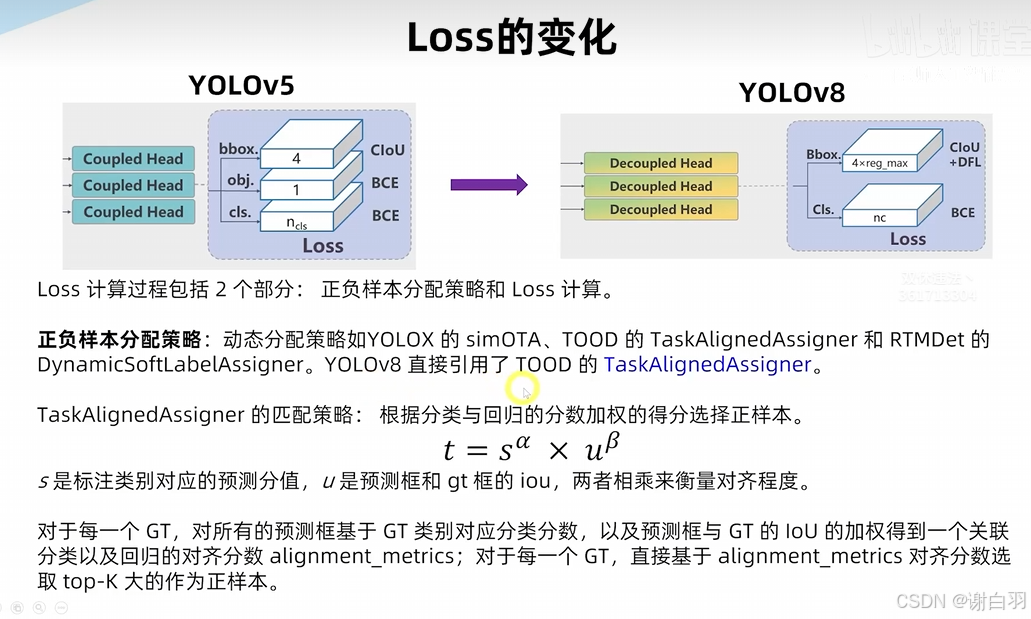
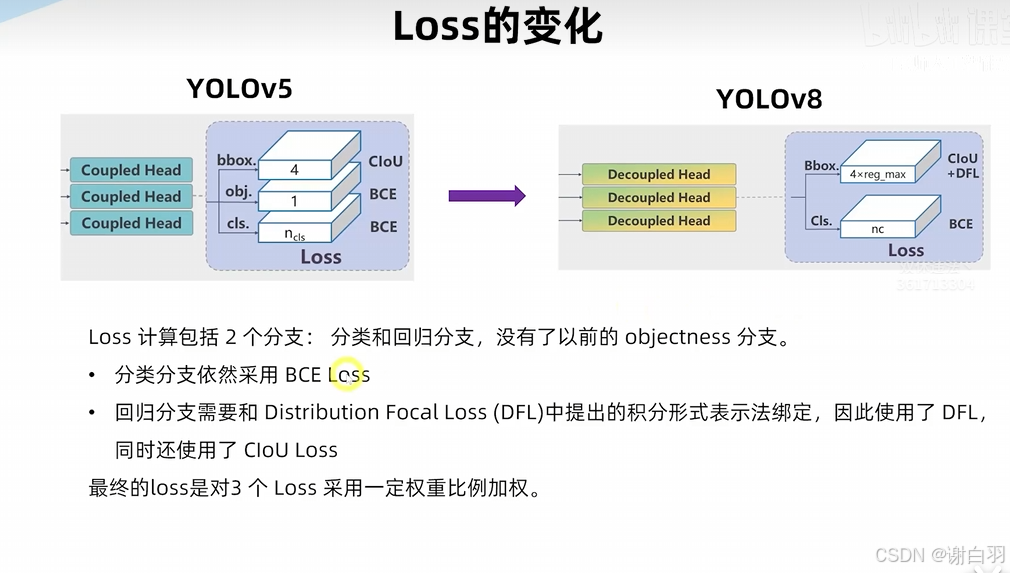
- loss的变化
- 训练数据增强

二、使用Parser搭建网络
1)window实践
1.1 安装基础环境、pytorch、yolov8、trt、opencv
1.2 模型文件转换
1.3 编译trt加速的yolov8
1.4 执行trt加速后的命令(C++)
1.5 执行trt加速后的命令(python)
2)ubuntu实践
2.1 安装基础环境、pytorch、yolov8、trt、opencv
2.2 模型文件转换
2.3 编译trt加速的yolov8
2.4 执行trt加速后的命令(C++)
2.5 执行trt加速后的命令(python)
3)代码解析
3.1 代码解析先序知识
3.2 infer相关代码解析
3.3 yolo相关代码解析-前处理
3.3 yolo相关代码解析-后处理
3.4 detect.cpp代码解析
3.5 项目python代码解析
3.6 ubuntu代码的不同之处
三、TensorRT原生API搭建网络
1)windows
1.1 安装基础环境、pytorch、yolov8、trt、opencv
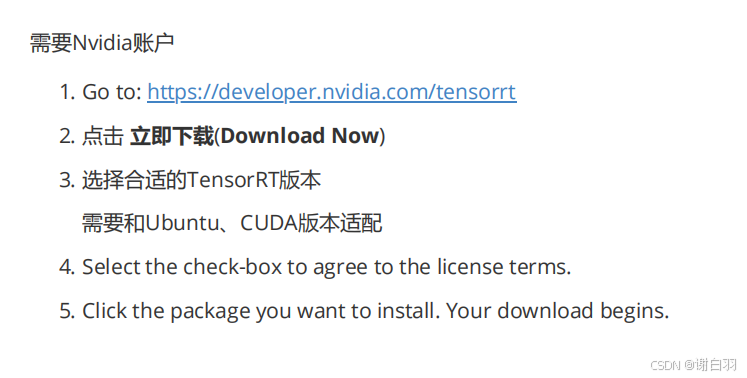
- 安装trt
1)下载安装包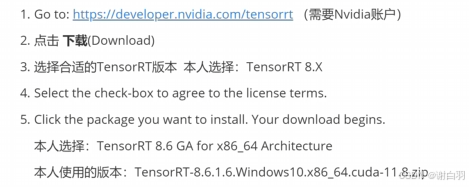
2)配置环境变量
3)安装pycuda
4)测试TensorRT

- 安装opencv

1.2 模型文件转换(生成wts文件)

1.3 编译trt加速的yolov8

1.4 执行trt加速后的命令(C++)
1.5 执行trt加速后的命令(python)

1.6 yolov8的trt int8量化(PTQ)
2)ubuntu
2.1 安装基础环境、pytorch、yolov8、trt、opencv
- 安装trt
1)下载安装包
2)安装trt
解压 tar file
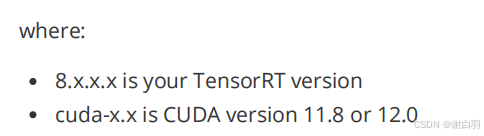
version="8.x.x.x"
arch=$(uname -m)
cuda="cuda-x.x"
tar -xzvf TensorRT-${version}.Linux.${arch}-gnu.${cuda}.tar.gz
本人使用的命令:
version="8.6.1.6"
arch=$(uname -m)
cuda="cuda-11.8"
tar -xzvf TensorRT-${version}.Linux.${arch}-gnu.${cuda}.tar.gz
将下面环境变量写入环境变量文件~/.bashrc并保存
sudo gedit ~/.bashrc #Linux 系统中用于编辑用户环境配置文件的命令
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:<TensorRT-${version}/lib>
本人使用的命令:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/bai/TensorRT-8.6.1.6/lib
当cuda环境没有指定时,也需要指定:
export LD_LIBRARY_PATH=/usr/local/cuda-11.7/lib64:$LD_LIBRARY_PATH
export CUDA_INSTALL_DIR=/usr/local/cuda-11.7
export CUDNN_INSTALL_DIR=/usr/local/cuda-11.7
使刚刚修改的环境变量文件生效
source ~/.bashrc
3)安装pycuda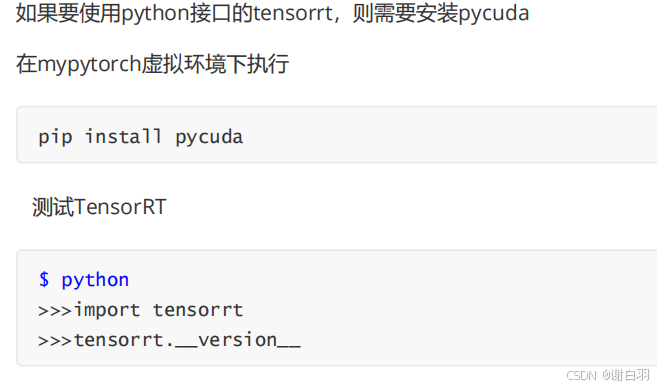
4)测试TensorRT示例代码
编译后可执行得到测试结果
编译:
cd ~/TensorRT-8.6.1.6/samples/sampleOnnxMNIST
make clean
make
转到bin目录下面,make后的可执行文件在此目录下
cd ~/TensorRT-8.6.1.6/bin
执行
./sample_onnx_mnist
- 安装opencv
step1:安装cmake
执行以下命令安装最新的cmake
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install build-essential cmake
step2:安装opencv依赖项
sudo apt-get install build-essential libgtk2.0-dev libavcodec-dev libavformat-dev
libjpeg-dev libswscale-dev libtiff5-dev
sudo apt-get install libcanberra-gtk-module
sudo apt-get install pkg-config
step3:下载opencv:
https://opencv.org/releases/step4:解压并新建build文件夹
- 将下载的文件opencv-4.7.0.zip解压到需要安装的目录,解压后会得到opencv-4.7.0文件夹。
- 打开opencv-4.7.0文件夹,并新建build文件夹。
(我是装在/home/user_name/目录下,其中user_name是我的用户名)
step5:编译opencv
打开刚才新建的build文件夹,并在该文件夹路径下执行以下命令:
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local ..
sudo make -j8
sudo make install
step6:配置opencv在ubuntu的参数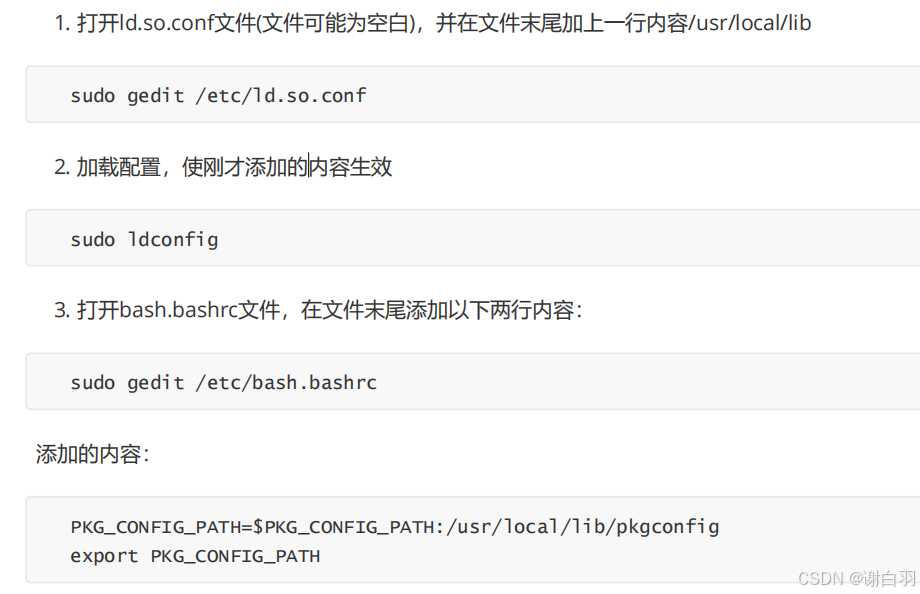 4. 运行bash.bashrc:
4. 运行bash.bashrc:
source /etc/bash.bashrc
5.更新系统的配置环境
sudo updatedb
如果报错 sudo updatedb: command not found
先执行 sudo apt-get install mlocate
再执行 sudo updatedb
执行 opencv_version
6.创建并配置opencv.pc文件
执行以下命令创建并打开opencv.pc文件:
cd /usr/local/lib/pkgconfig
touch opencv.pc
sudo gedit opencv.pc
2.2 模型文件转换(生成wts文件)
1)下载tensorrt项目文件
https://github.com/wang-xinyu/tensorrtx
2)脚本转pt文件成wts文件
拷贝gen_wts.py文件到ultralytics/ultralytics目录下
cp ~/tensorrtx/yolov8/gen_wts.py ~/ultralytics/ultralytics
在ultralytics/ultralytics路径下执行
python gen_wts.py
可在gen_wts.py中修改需要转换的权重文件
import sys
import argparse
import os
import struct
import torch
pt_file = "./weights/yolov8s.pt"
wts_file = "./weights/yolov8s.wts"
# Initialize
device = 'cpu'
# Load model
model = torch.load(pt_file, map_location=device)['model'].float() # load to FP32
anchor_grid = model.model[-1].anchors * model.model[-1].stride[..., None, None]
delattr(model.model[-1], 'anchors')
model.to(device).eval()
with open(wts_file, 'w') as f:
f.write('{}\n'.format(len(model.state_dict().keys())))
for k, v in model.state_dict().items():
vr = v.reshape(-1).cpu().numpy()
f.write('{} {} '.format(k, len(vr)))
for vv in vr:
f.write(' ')
f.write(struct.pack('>f', float(vv)).hex())
f.write('\n')
拷贝文件yolov8s.wts文件到tensorrtx/yolov8/workspace目录下
注意:workspace目录自己创建
3) 修改CMakeLists.txt
修改tensorrtx/yolov8下的CMakeLists.txt文件
注意:使用时需要根据自己电脑上的软件位置和GPU架构做相应的修改。
GPU架构官网查询:https://developer.nvidia.com/cuda-gpus
4) 修改include/config.h
2.3 编译trt加速的tensorrtx/yolov8
mkdir build
cd build
cmake ..
make
2.4 执行trt加速后的命令(C++)
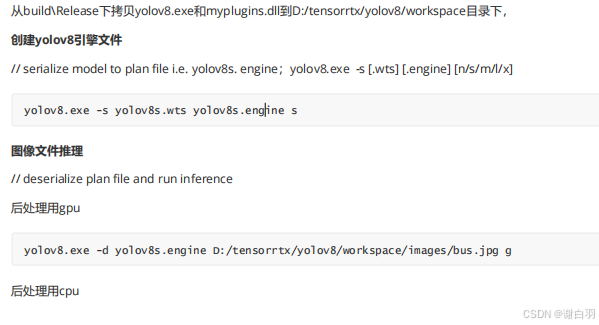
拷贝yolov8和libmyplugins.so到tensorrtx/yolov8/workspace目录下
1)创建yolov8引擎文件
2)图像文件推理
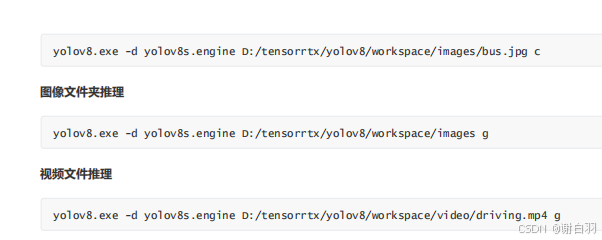
3)图像文件夹推理
./yolov8 -d yolov8s.engine ./images g
4)视频文件推理
./yolov8 -d yolov8s.engine ./video/driving.mp4 g
2.5 执行trt加速后的命令(python)
创建yolov8引擎文件这一步同c++一样
拷贝libmyplugins.so到tensorrtx/yolov8/workspace目录下,
拷贝yolov8_trt.py到tensorrtx/yolov8/workspace目录下
在mypytorch虚拟环境下执行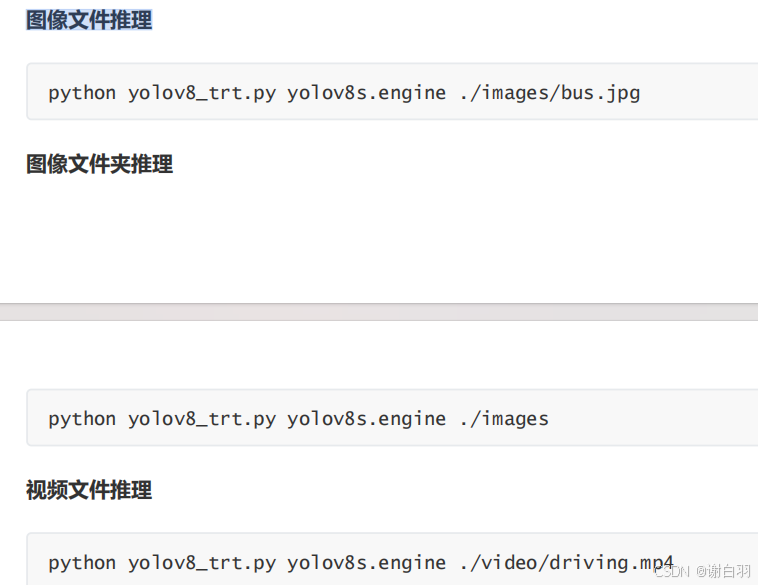
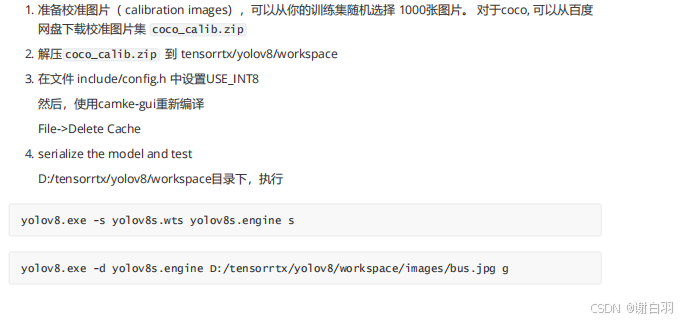
2.6 yolov8的trt int8量化(PTQ)

4. serialize the model and test
tensorrtx/yolov8/workspace目录下,执行
./yolov8 -s yolov8s.wts yolov8s.engine s
./yolov8 -d yolov8s.engine ./images g
3)代码解析
3.1 gen_wts.py代码解析
- 代码目的
这段代码主要用于将PyTorch模型( .pt 文件)转换为一个简化的权重格式( .wts 文件)。 - 解释代码
①导入必要库及库的说明
sys : 用于访问Python解释器的变量和与解释器交互。
argparse : 用于解析命令行参数。
os : 提供了多种操作系统服务的接口。
struct : 用于将Python数据转换为C-style数据结构。
torch : PyTorch库,用于深度学习和张量计算。
②定义文件路径:
pt_file : 指定PyTorch模型的路径。
wts_file : 定义输出的 .wts 文件路径
③模型初始化:
将设备设置为’cpu’,表示模型将在CPU上加载和运行。
device = 'cpu'
④加载模型:
使用 torch.load 加载 .pt 文件,将其映射到CPU,并将模型权重转换为浮点32格式。
model = torch.load(pt_file, map_location=device)['model'].float()
⑤对模型进行修改:计算 anchor_grid (可能用于某种目标检测任务,如YOLO)。从模型中删除’anchors’属性。
⑥模型评估模式
通过调用 model.eval() 将模型设置为评估模式,这确保了模型在推理时不使用Dropout或BatchNorm
⑦保存为.wts格式:
1\使用 open 函数打开或创建 .wts 文件。
2\首先写入模型的键的数量。
3\遍历模型的 state_dict (这是一个包含模型所有权重和参数的字典)。
4\对于每一个键和相应的权重张量,将权重值重塑为一维数组,并转换为numpy数组。
5\将每个权重值转换为浮点32位,并使用 struct.pack 转换为十六进制格式,然后写入到 .wts 文件中
- 代码
import sys
import argparse
import os
import struct
import torch
pt_file = "./weights/yolov8s.pt"
wts_file = "./weights/yolov8s.wts"
# Initialize
device = 'cpu'
# Load model
model = torch.load(pt_file, map_location=device)['model'].float() # load to FP32
anchor_grid = model.model[-1].anchors * model.model[-1].stride[..., None, None]
delattr(model.model[-1], 'anchors')
model.to(device).eval()
with open(wts_file, 'w') as f:
f.write('{}\n'.format(len(model.state_dict().keys())))
for k, v in model.state_dict().items():
vr = v.reshape(-1).cpu().numpy()
f.write('{} {} '.format(k, len(vr)))
for vv in vr:
f.write(' ')
f.write(struct.pack('>f', float(vv)).hex())
f.write('\n')
3.2 yolov8的预处理相关代码解析(或称为前处理)
3.3 yoloLayerPlugin代码解析
结合plugin说明来看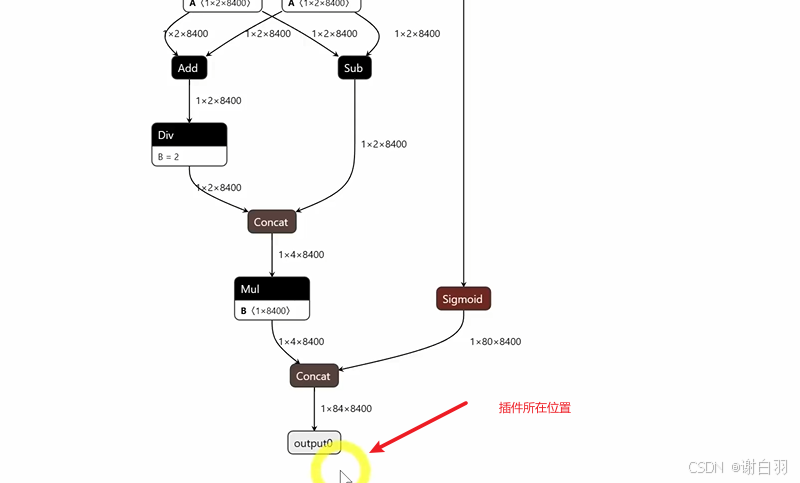
- 插件说明
①YoloLayerPlugin类继承IPluginV2IOExt类,实现具体内容是实现YoloLayer这个算子内容的类
②YoloPluginCreator类继承IPluginCreator类,实现重写创建plugin类和获取版本、获取field名字、创建plugin等初始化操作,成员变量PluginFieldCollection类对象mFC和PluginField类对象的mPluginAttributes通常用于描述插件的属性和参数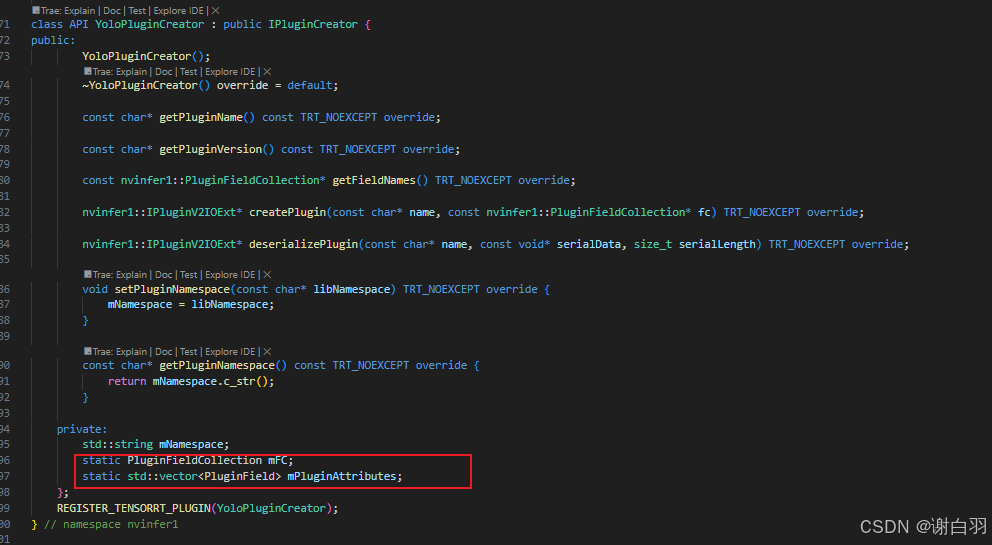
③两个类放在nvinfer1命名空间下
④这个插件是将通过api构建yolo网络最后的输出转为坐标框信息,每个cuda线程处理一个yolo的网格单元预测,核函数就是将输出转为坐标框信息
⑤输出有8400个网格单元,会有8400个cuda线程并行处理
⑥宏定义在 TensorRT 中注册 YoloPluginCreator 插件。这样,当 TensorRT 实例化时,它就可以知道并使用这个插件
REGISTER_TENSORRT_PLUGIN(YoloPluginCreator);
⑦插件功能实现类函数说明
1、getNbOutputs()
作用:返回插件输出的张量数量
参数:无
返回值:固定返回1(单输出插件)
2、getOutputDimensions()
作用:根据输入维度计算指定输出的张量维度
参数:
index:输出张量索引
inputs:输入张量维度数组指针
nbInputDims:输入张量数量
3、initialize()
作用:初始化插件资源(如分配显存)8
返回值:0表示成功
4、terminate()
作用:释放initialize()中分配的资源8
5、getWorkspaceSize()
作用:返回插件所需临时显存大小7
参数:maxBatchSize最大批处理量
返回值:0表示不需要额外空间
6、enqueue()
作用:执行插件核心计算逻辑78
参数:
batchSize:当前批次大小
inputs:输入数据指针数组
outputs:输出数据指针数组
workspace:临时显存指针
stream:CUDA流对象
7、getSerializationSize()
作用:返回序列化插件所需的字节数(就是参数的大小)
8、serialize()
作用:将插件参数序列化到缓冲区
参数:buffer目标缓冲区指针
9、supportsFormatCombination()
作用:指明插件支持的输入输出张量格式和数据类型组合
参数:
pos:张量位置索引
inOut:张量描述符数组
nbInputs/nbOutputs:输入/输出数量
10、getPluginType()
作用:返回插件类型名称(需全局唯一)
11、getPluginVersion()
作用:返回插件版本字符串
12、destroy()
作用:销毁插件实例
13、clone()
作用:创建插件副本方便trt做测试不同加速策略
14、setPluginNamespace()
作用:设置插件命名空间
参数:pluginNamespace命名空间字符串
15、getPluginNamespace()
作用:获取当前命名空间
16、getOutputDataType()
作用:返回指定输出的数据类型
参数:
index:输出索引
inputTypes:输入数据类型数组
nbInputs:输入数量
17、isOutputBroadcastAcrossBatch()
作用:检查输出是否在批次维度广播 一般是false不做广播的话
18、canBroadcastInputAcrossBatch()
作用:检查输入是否允许批次广播 一般是false不做广播的话
19、attachToContext() #一般不需要做任何使用
作用:关联CUDA上下文资源8
参数:
cudnnContext:cuDNN句柄
cublasContext:cuBLAS句柄
gpuAllocator:显存分配器
20、configurePlugin()
作用:配置插件输入/输出张量描述 #一般不需要做任何使用
21、detachFromContext() #一般不需要做任何使用
作用:解除上下文关联
- 补充
1)getOutputDimensions:获取插件输出张量的维度
函数解释:total_size + 1:前面计算出的存储检测对象所需的浮点数数量,再加上 1 个浮点数,这个额外的浮点数用来存储实际检测到的对象数量。后面两个维度设为 1,意味着输出张量在这两个维度上的大小为 1,即输出张量本质上是一个一维向量。
2)getSerializationSize:获取序列化参数的大小
size_t CustomScalarPlugin::getSerializationSize() const noexcept
{
/* 如果把所有的参数给放在mParams中的话, 一般来说所有插件的实现差不多一致 */
return sizeof(mParams);
}

- 插件推理函数enqueue说明
返回0,表示成功
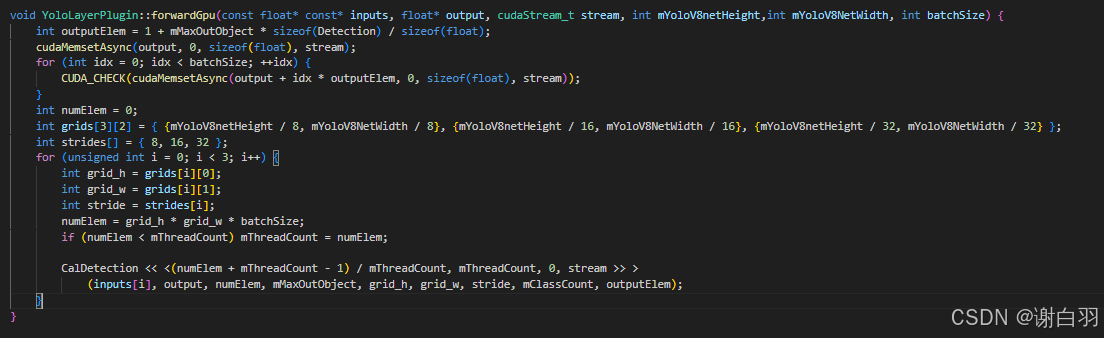
__global__ void CalDetection(const float* input, float* output, int numElements, int maxoutobject,
const int grid_h, int grid_w, const int stride, int classes, int outputElem) {
//当前线程的全局索引
int idx = threadIdx.x + blockDim.x * blockIdx.x;
if (idx >= numElements) return;
int total_grid = grid_h * grid_w;
int info_len = 4 + classes;
int batchIdx = idx / total_grid;
int elemIdx = idx % total_grid;
const float* curInput = input + batchIdx * total_grid * info_len;
int outputIdx = batchIdx * outputElem;
int class_id = 0;
float max_cls_prob = 0.0;
for (int i = 4; i < info_len; i++) {
float p = Logist(curInput[elemIdx + i * total_grid]);
if (p > max_cls_prob) {
max_cls_prob = p;
class_id = i - 4;
}
}
if (max_cls_prob < 0.1) return;
int count = (int)atomicAdd(output + outputIdx, 1);
if (count >= maxoutobject) return;
char* data = (char*)(output + outputIdx) + sizeof(float) + count * sizeof(Detection);
Detection* det = (Detection*)(data);
int row = elemIdx / grid_w;
int col = elemIdx % grid_w;
det->conf = max_cls_prob; //置信度
det->class_id = class_id; //类别ID
det->bbox[0] = (col + 0.5f - curInput[elemIdx + 0 * total_grid]) * stride;
det->bbox[1] = (row + 0.5f - curInput[elemIdx + 1 * total_grid]) * stride;
det->bbox[2] = (col + 0.5f + curInput[elemIdx + 2 * total_grid]) * stride;
det->bbox[3] = (row + 0.5f + curInput[elemIdx + 3 * total_grid]) * stride;
}
①__global__ 修饰符表示这是一个可以由 CPU 调用并在 GPU 上执行的函数。
②int idx = threadIdx.x + blockDim.x * blockIdx.x; :这是一个常见的模式,用于计算当前线
程的全局索引
③if (idx >= numElements) return;如果全局索引超出了需要处理的元素数量,函数会立即返回
④total_grid 计算总的网格数量。
info_len 是每个网格的信息长度,它由 4 个边界框属性和类别数量组成。
batchIdx 和 elemIdx 分别表示当前处理的批次索引和元素索引。
⑤循环遍历所有类别,并使用 Logist 函数(之前在代码中定义)计算每个类别的概率,记录最大的类别概率和对应的类别索引。
for 循环从 4 开始,是为了跳过前 4 个边界框信息,直接遍历类别置信度。
class_id 减去 4,是因为 i 从 4 开始,要将其转换为从 0 开始的类别索引。
int class_id = 0;
float max_cls_prob = 0.0;
for (int i = 4; i < info_len; i++) {
float p = Logist(curInput[elemIdx + i * total_grid]);
if (p > max_cls_prob) {
max_cls_prob = p;
class_id = i - 4;
}
}
⑥如果最大概率小于 0.1,则该线程不会输出任何检测结果。
if (max_cls_prob < 0.1) return;
⑦使用 atomicAdd 函数原子地增加输出计数。这是必要的,因为多个线程可能会尝试同时更新相同的输出位置。如果计数超过了 maxoutobject ,则该线程不会输出任何检测结果。
int count = (int)atomicAdd(output + outputIdx, 1);
if (count >= maxoutobject) return;
参数解释:
1)outputElem 表示每个批次在输出数组里所需的元素数量
int outputIdx = batchIdx * outputElem;
2)outputIdx 于定位当前批次在 output 数组中的起始位置,从而正确记录该批次检测到的有效目标数量
batchIdx表示当前处理的批次索引
⑧根据当前线程处理的元素索引,计算检测框的行和列。
更新检测框的置信度、类别和边界框坐标
⑨mThreadCount 代表每个 CUDA 线程块里线程的数量。在 CUDA 编程中,核函数是通过线程网格(grid)和线程块(block)来执行的,线程块由多个线程组成,mThreadCount 就定义了每个线程块中线程的具体数目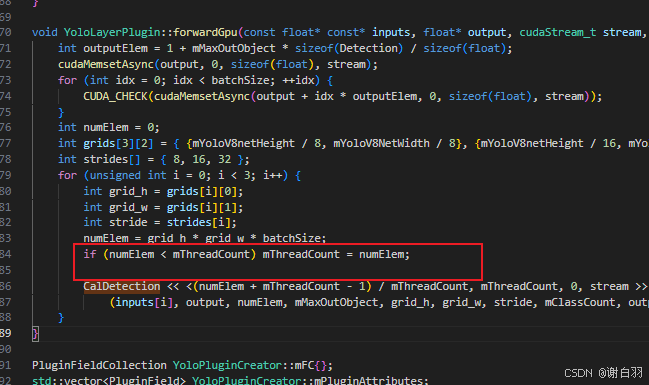
当 numElem < mThreadCount 时,意味着需要处理的元素数量比初始设定的每个线程块的线程数量少。在这种情况下,若仍然按照初始的 mThreadCount 启动线程,会有部分线程没有实际的工作可做,造成资源浪费。所以,代码会将 mThreadCount 的值更新为 numElem,确保每个线程都有对应的元素需要处理,避免资源浪费
3.4 yolo组件相关代码解析
3.5 yolo模型构建相关代码解析
3.6 int8量化校准器代码解析
3.7 main.cpp代码解析
3.8 yolo8_trt.py代码解析
3.9 代码更新
3.10 参数备注
①yolo目标检测后处理里面 conf_threshold和nms相关的IOU_THRESHOLD有什么用,增大数值对模型有什么作用?
回答:
1)conf_threshold:过滤低置信度的预测框,仅保留置信度高于该阈值的检测结果26。
例如,conf_threshold=0.25表示丢弃置信度低于25%的预测框
2)IOU_THRESHOLD:控制非极大值抑制(NMS)中合并重叠框的严格程度35。
计算预测框之间的交并比(IoU),若高于阈值则保留置信度最高的框
3)数值变化作用:高conf_threshold + 高iou_threshold:结果严格,适合高精度场景610。
低conf_threshold + 低iou_threshold:提高召回率,但噪声增多

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 25
25 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)