
进击大数据系列(七): Hadoop 数据仓库 Hive
点击下方名片,设为星标!回复“1024”获取2TB学习资源!前面介绍了 Hadoop 架构基石 HDFS、统一资源管理和调度平台 YARN、分布式计算框架 MapReduce等相关的知识点,今天我将详细的为大家介绍 大数据 Hadoop 数据仓库 Hive 相关知识,希望大家能够从中收获多多!如有帮助,请点在看、转发支持一波!!!概述数据仓库概念数据仓库(Data Warehouse)是一个面向.
点击下方名片,设为星标!
回复“1024”获取2TB学习资源!
前面介绍了 Hadoop 架构基石 HDFS、统一资源管理和调度平台 YARN、分布式计算框架 MapReduce 等相关的知识点,今天我将详细的为大家介绍 大数据 Hadoop 数据仓库 Hive 相关知识,希望大家能够从中收获多多!如有帮助,请点在看、转发支持一波!!!
概述
数据仓库概念
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策;
数据仓库的体系结构: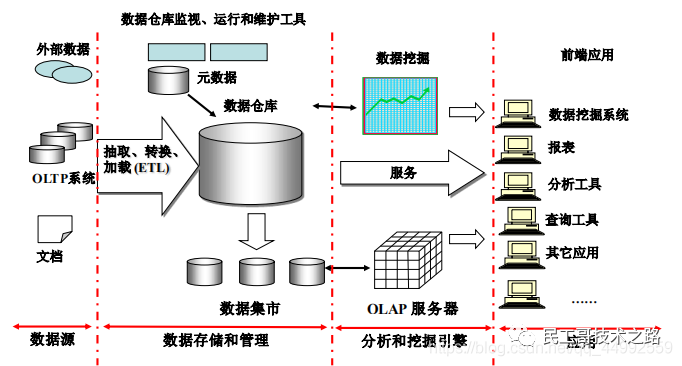
传统数据仓库面临的挑战
-
无法满足快速增长的海量数据存储需求
-
无法有效处理不同类型的数据
-
计算和处理能力不足
Hive 简介
Hive 是建立在 Hadoop 之上的数据仓库,由 Facebook 开发,在某种程度上可以看成是用户编程接口,本身并不存储和处理数据,依赖于 HDFS 存储数据,依赖 MR 处理数据。有类 SQL 语言 HiveQL,不完全支持SQL 标准,如,不支持更新操作、索引和事务,其子查询和连接操作也存在很多限制。
-
Hive是一个构建于Hadoop顶层的数据仓库工具;
-
支持大规模数据存储、分析,具有良好的可扩展性;
-
某种程度上可以看作是用户编程接口,本身不存储和处理数据;
-
依赖分布式文件系统HDFS存储数据;
-
依赖分布式并行计算模型MapReduce处理数据;
-
定义了简单的类似SQL 的查询语言——HiveQL;
-
用户可以通过编写的HiveQL语句运行MapReduce任务;
-
它可以很容易把原来构建在关系数据库上的数据仓库应用程序移植到Hadoop平台上;
-
它是一个可以提供有效、合理、直观组织和使用数据的分析工具;
Hive把HQL语句转换成MR任务后,采用批处理的方式对海量数据进行处理。数据仓库存储的是静态数据,很适合采用MR进行批处理。Hive还提供了一系列对数据进行提取、转换、加载的工具,可以存储、查询和分析存储在HDFS上的数据。更多关于大数据 Hadoop系列的学习文章,请参阅:进击大数据系列,本系列持续更新中。
Hive特点
-
采用批处理方式处理海量数据
-
Hive需要把HiveQL语句转换成MapReduce任务进行运行
-
数据仓库存储的是静态数据,对静态数据的分析适合采用批处理方式,不需要快速响应给出结果,而且数据本身也不会频繁变化
-
-
提供适合数据仓库操作的工具
-
Hive本身提供了一系列对数据进行提取、转换、加载(ETL)的工具,可以存储、查询和分析存储在Hadoop中的大规模数据
-
这些工具能够很好地满足数据仓库各种应用场景
-
-
Hive与Hadoop生态系统中其他组件的关系(略)
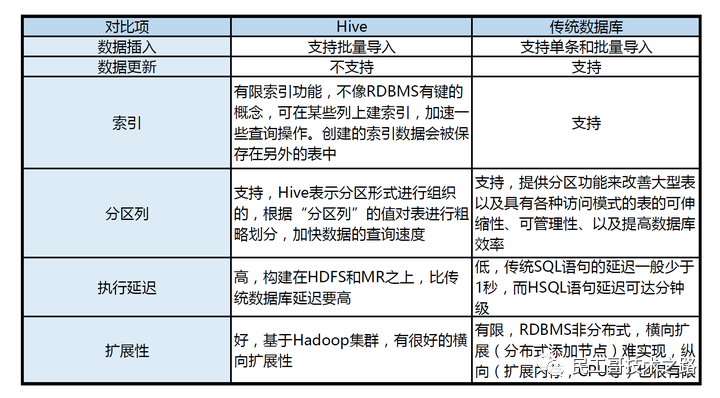
Hive与传统数据库的对比分析
Hive在企业中的部署和应用
Hive在企业大数据分析平台中的应用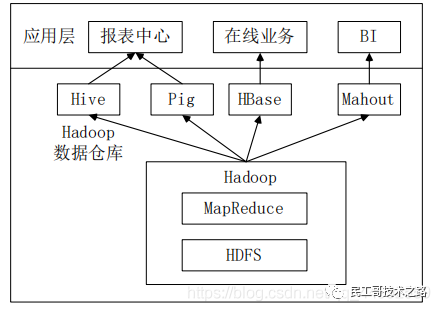
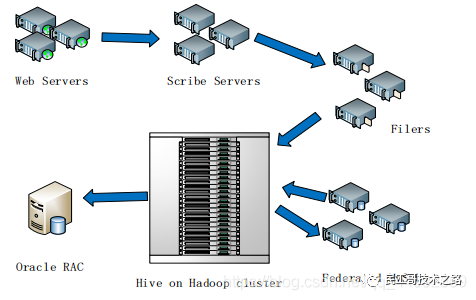
Hive在Facebook公司中的应用
-
基于Oracle的数据仓库系统已经无法满足激增的业务需求
-
Facebook公司开发了数据仓库工具Hive,并在企业内部进行了大量部署
Hive系统架构
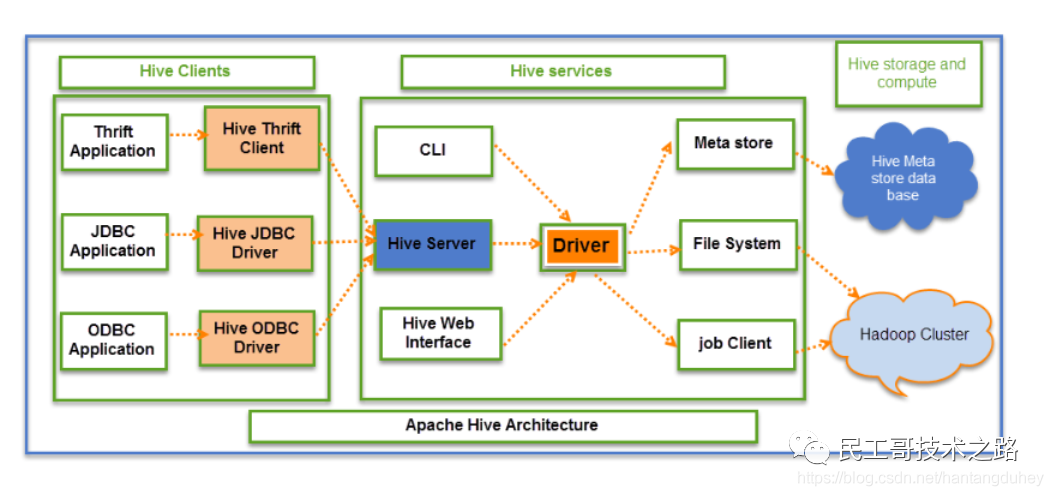 Hive 主要由三个部分组成:Clients(客户端)、Serverices(服务)、Storage and compute(存储和计算)。
Hive 主要由三个部分组成:Clients(客户端)、Serverices(服务)、Storage and compute(存储和计算)。
-
Clients(客户端):Hive 为与不同类型的应用程序的通信提供了不同的驱动程序。Hive clinets 可以支持 Thrift、JDBC、ODBC 协议与 Hive services 进行通信
-
Serverices(服务):Clients 与 Hive 的交互通过 Hive Services 执行。CLI 是命令行界面,充当 DDL(数据定义语言)操作的 Hive 服务。Serverices 核心的模块是 Driver(驱动程序)
-
Hive Services、CLI、Hive web Interface 都通过 Driver(驱动程序)对元数据、文件系统进行计算和处理
-
Storage and compute(存储和计算):Hive 的元数据存储在元数据数据库中,元数据数据库支持 Mysql 等多种类型。Hive 的查询结果和数据存储在 Hadoop 中
Hive的数据结构
Hive 的存储结构包括数据库、表、视图、分区和表数据:
-
database:在 HDFS 中表现为 ${hive.metastore.warehouse.dir} 目录下一个文件夹
-
table:在 HDFS 中表现所属 database 目录下一个文件夹
-
external table:与 table 类似,不过其数据存放位置可以指定任意 HDFS 目录路径
-
partition:在 HDFS 中表现为 table 目录下的子目录
-
bucket:在 HDFS 中表现为同一个表目录或者分区目录下根据某个字段的值进行 hash 散列之后的多个文件
-
view:与传统数据库类似,只读,基于基本表创建
使用Hive的好处
-
简单,容易上手
-
写sql的方式实现,并且语法和sql类似
-
-
统一元数据管理
-
Hive是基于Hadoop的,所以数据都是用HDFS存储的,都是一行一行的字符串,没有关系型数据库的表,列啊,字段类型之类的元数据概念。Hive会有这些元数据,并且把它们存储在Mysql中
-
-
底层支持多种执行引擎
-
Mapreduce,Tez,Spark。可以让Hive sql 语句运行在不同的模式中,比如离线在线
-
Hive工作原理
-
SQL语句转换成MapReduce作业的基本原理
-
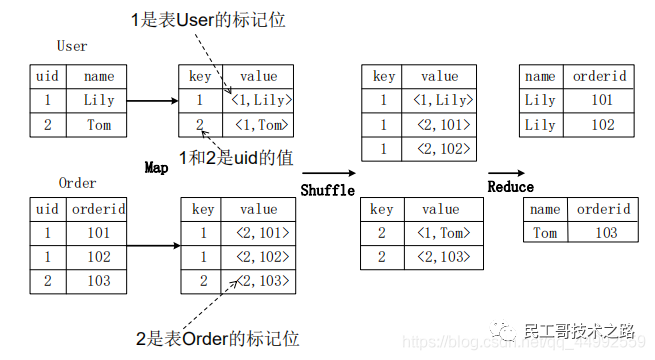
join的实现原理
-
group by的实现原理
select rank, level ,count(*) as value from score group by rank, level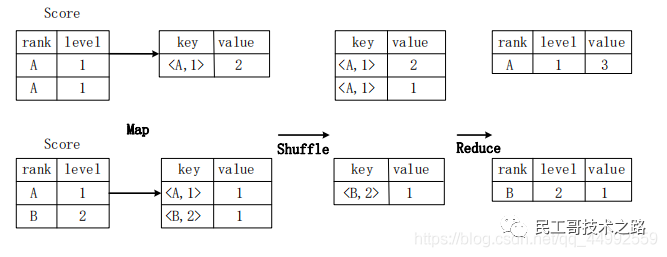
-
Hive SQL查询转换成MapReduce作业的过程
-
驱动模块接收该命令或查询编译器;
-
对该命令或查询进行解析编译;
-
由优化器对该命令或查询进行优化计算;
-
该命令或查询通过执行器进行执行;
-
当用户向Hive输入一段命令或查询时,Hive需要与Hadoop交互工作来完成该操作:
-
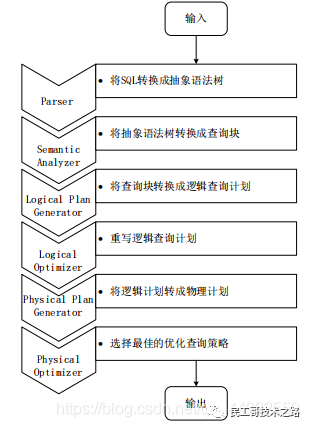
1.由Hive驱动模块中的编译器对用户输入的SQL语言进行词法和语法解析,将SQL语句转化为抽象语法树的形式;
2.抽象语法树的结构仍很复杂,不方 便直接翻译为MapReduce算法程序,因此把抽象语法树转化为查询块;
3.把查询块转换成逻辑查询计划,里面包含了许多逻辑操作符;
4.重写逻辑查询计划,进行优化,合并多余操作,减少MapReduce任务数量;
5.将逻辑操作符转换成需要执行的具体MapReduce任务;
6.对生成的MapReduce任务进行优化,生成最终的MapReduce任务执行计划;
7.由Hive驱动模块中的执行器,对最终的MapReduce任务进行执行输出;
 更多关于大数据 Hadoop系列的学习文章,请参阅:进击大数据系列,本系列持续更新中。
更多关于大数据 Hadoop系列的学习文章,请参阅:进击大数据系列,本系列持续更新中。
说明
-
当启动MapReduce程序时,Hive本身是不会生成MapReduce算法程序的;
-
需要通过一个表示“Job执行计划”的XML文件驱动执行内置的、原生的Mapper和Reducer模块;
-
Hive通过和JobTracker通信来初始化MapReduce任务,不必直接部署在JobTracker所在的管理节点上执行;
-
通常在大型集群上,会有专门的网关机来部署Hive工具,网关机的作用主要是远程操作和管理节点上的JobTracker通信来执行任务;
-
数据文件通常存储在HDFS上,HDFS由名称节点管理;
Hive HA 基本原理
-
由多个Hive实例进行管理的,这些Hive实例被纳入到一个资源池中,并由HAProxy提供一个统一的对外接口;
-
对于程序开发人员来说,可以把它认为是一台超强“Hive";
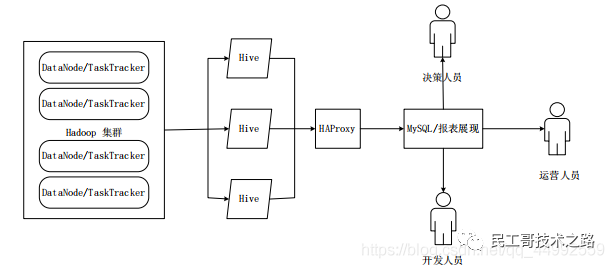
Hive安装
MySQL 安装与设置
为什么安装 MySQL 而不使用 Hive 自带的 derby?
-
使用 derby 不能开启多个 hive 客户端连接!
下载并安装 MySQL 官方的 Yum Repository,采用wget方式进行安装。
wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm使用上面的命令就直接下载了安装用的Yum Repository,大概25KB,然后就可以直接应用yum进行安装了,命令及执行效果如下:
sudo yum -y install mysql57-community-release-el7-10.noarch.rpm安装Mysql服务器
sudo yum -y install mysql-community-server启动Mysql并查看运行状态
sudo systemctl start mysqld.service
sudo systemctl status mysqld.service修改默认密码
#初始密码获取
sudo grep "password" /var/log/mysqld.log
#输入密码登录mysql
mysql -u root -p
#密码修改
ALTER USER 'root'@'localhost' IDENTIFIED BY 'Hive@2020';注意:密码设置必须要大小写字母数字和特殊符号,不然不能配置成功。
开启mysql的远程访问
执行以下命令开启远程访问限制(注意:下面命令开启所有的IP,如要开启某个具体IP是192.168.150.71,则将%替换成IP地址):
grant all privileges on *.* to 'root'@'%' identified by 'Hive@2020' with grant option;
#刷新权限:
flush privileges;修改mysql的字符编码以防止中文乱码问题
#显示原来编码
show variables like '%character%';
#若character_set_server不是utf-8,修改/etc/my.cnf(sudo vim /etc/my.cnf)(输入如下参数选项)
character_set_server=utf8
init_connect='SET NAMES utf8'
#重启数据库生效配置
sudo systemctl restart mysqldHive安装
#下载Hive文件解压与赋权
sudo tar -zxvf ./Downloads/apache-hive-3.1.2-bin.tar.gz -C /usr/local
cd /usr/local/
sudo mv apache-hive-3.1.2-bin hive
sudo chown -R hadoop ./hiveHive环境变量配置:vim ~/.bashrc
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin记住:source ~/.bashrc
修改配置文件
新建hive-site.xml,添加如下配置信息
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.readOnlyDatastore</name>
<value>false</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>false</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateTables</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateColumns</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>Hive的MySQL配置
下载jdbc驱动:https://dev.mysql.com/downloads/connector/j/5.1.html
#解压拷贝:
sudo tar -zxvf ./Downloads/mysql-connector-java-5.1.49.tar.gz -C /usr/local #解压
cd /usr/local/
cp mysql-connector-java-5.1.49/mysql-connector-java-5.1.49-bin.jar ./hive/lib启动并登陆MySQL
mysql -u root -p新建hive数据库
create database hive; # 与hive-site.xml中localhost:3306/hive的hive对应,用来保存hive元数据配置Mysql允许hive接入
create user ‘hive’@‘localhost’ identified by ‘hive’; # hive用户密码;
GRANT ALL ON \*.\* TO ‘hive’@‘localhost’; # 将所有数据库的所有表的所有权限赋给hive用户;
flush privileges; # 刷新mysql系统权限关系表;启动hive
#启动hdfs与yarn:start-dfs.sh、start-yarn.sh
#启动hive
cd /usr/local/hive
./bin/schematool -dbType mysql -initSchema
./bin/hive使用mysql作为元数据库时登陆启动Hive过程中,可能出现的错误和解决方案:
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument
#原因:hive内依赖的guava.jar和hadoop内的版本不一致;
#解决方法:
1、查看hadoop安装目录下share/hadoop/common/lib内guava.jar版本;
2、查看hive安装目录下lib内guava.jar的版本 如果两者不一致,删除版本低的,并拷贝高版本的,问题解决;
org.datanucleus.store.rdbms.exceptions.MissingTableException: Required table missing : “VERSION” in Catalog “Schema”. DataNucleus requires this table to perform its persistence operations.
#解决方法:进入hive安装目录(比如/usr/local/hive),执行如下命令
./bin/schematool -dbType mysql -initSchemaHive metastore database is not initialized
-
原因:以前曾经安装了Hive或MySQL,重新安装Hive和MySQL以后,导致版本、配置不一致
-
解决方法:使用schematool工具(Hive现在包含一个用于 Hive Metastore 架构操控的脱机工具,名为 schematool),此工具可用于初始化当前 Hive 版本的 Metastore 架构;此外,其还可处理从较旧版本到新版本的架构升级。故解决上述错误,在终端执行如下命令即可:
schematool -dbType mysql -initSchema更多关于大数据 Hadoop系列的学习文章,请参阅:进击大数据系列,本系列持续更新中。
Hive编程实战
知识准备
Hive的基本数据类型
-
TINYINT:1 byte 有符号整数(1)
-
SMALLINT:2 bytes 有符号整数(1)
-
INT:4 bytes 有符号整数(1)
-
BIGINT:8 bytes 有符号整数(1)
-
FLOAT:4 bytes 单精度浮点数(1.0)
-
DOUBLE:8 bytes 双精度浮点数(1.0)
-
BOOLEAN:布尔类型,true or false(false)
-
STRING:字符串,可指定字符集(“hive”)
-
TIMESTAMP:整数、浮点数or字符串(1321123121)
Hive的集合数据类型
-
ARRAY:一组有序的字段,字段的类型必须相同;
-
MAP:一组无序的键/值对,键的类型必须是原子的,值可以是任何数据类型,同一个映射的键和值额类型必须相同;
-
STRUCT:一组命名的字段,字段类型可以不同
Hive基本操作
创建数据库、表、视图
#创建数据库:create database [if not exists] database_name;
hive> create database if not exists college;
#创建表(内部表、外部表以及分区表见附录):
create [external] table [if not exists] table_name
[(col_1 dt [comment c_com_1],col_2 dt [comment c_com_2],...)]
[partitioned by (col dt,...)];
hive> use college;
hive> create table if not exists student(id int,name string);
#创建视图
hive> create view stu as select id,name from student where id<10;查看数据库、表
查看数据库
#查看所有数据库
hive> show databases;
#查看以h开头的所有数据库
hive> show databases like ‘col.*’
#查看hive数据库位置等信息
describe database hive;
desc database hive;
desc database extended hive;
#查看表
hive> show tables;
hive> show tables in college like ‘s.*’;修改数据库、表
-
修改数据库
用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES设置键-值对属性值,来描述这个数据库的属性信息,数据库的其它元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。
alter database hive set dbproperties(‘createtime’=‘20201122’);-
修改表
#重命名(RENAME)表
alter table table_name rename to new_table_name
#增加(ADD)/修改(CHANGE)/替换(REPLACE)列信息
alter table table_name add columns (col dt); # 加到所有列后,但在partition列前
alter table table_name change column col_name new_col_name data_type;
alter table table_name replace columns (col_a dt,col_b dt,…); # 替换整个表的列删除数据库、表
#删除数据库
drop database db [cascade]; # 非空数据库使用cascade,否则报错
#删除表
drop table table_name;向表中装载数据
#装载本地数据
hive> load data local inpath ‘/home/hadoop/stu.txt’ overwrite into table student; #overwrite覆盖
#与下述语句等同(load本地数据本质即为上传本地数据到hive数据表存放路径)
hadoop fs -put /home/hadoop/stu.txt /hive/warehouse/college.db/student
#装载hdfs数据
hive> load data inpath ‘/user/hadoop/stu.txt’ overwrite into table student; # overwrite 覆盖向表中插入数据
insert (overwrite) table student_copy select * from student where id<10;从查询表中数据
使用select…from…where…等语句,并结合关键字group by、having、like等操作;
case…when…then…
select id,name
case
when id=1 then 'first'
when id=2 then 'second'
else 'other' end from student;连接
#内连接
select stu.*, course.* from stu join course on(stu.id=course.sid);
#左连接
select stu.*, course.* from stu left outer join course on(stu.id=course.sid);
#右连接
select stu.*, course.* from stu right outer join course on(stu.id=course.sid);
#全连接
select stu.*, course.* from stu full outer join course on(stu.id=course.sid);
#半连接
select stu.* from stu left semi join course on(stu.id=course.sid);附一:管理表(内部表)
默认创建的表都是所谓的管理表,有时也被称为内部表,因为这种表,Hive会或多或少地控制着数据的生命周期。Hive默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse/dir所定义的目录或其子目录下。当我们删除一个管理表时,Hive也会删除这个表中的数据。管理表不适合和其它工具共享数据。
附二:外部表
Hive创建外部表时,仅记录数据所在的路径,不会对数据的位置做任何改变。外部表与内部表的主要区别在于删除外部表时,Hive不会删除这个表中的数据,重新创建该表仍然可以查到该数据(Mysql的元数据与Hdfs的原数据缺失任何一个都不能查询到该表的数据,且它们数据的先后,即先有元数据或先有原数据,不影响表数据的查询;Hive删除外部表只是删除元数据,但删除内部表会删除元数据与原数据)。
管理表与外部表的的互相转换:
-
查询表的类型:desc formatted student;
-
修改表为内部表or外部表:
alter table student set tblproperties(‘EXTERNAL’=‘FALSE’);
alter table student set tblproperties(‘EXTERNAL’=‘TRUE’)注:‘EXTERNAL’='FALSE’必须大写;
附三:分区表
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句的表达式选择查询所需要的指定的分区能够提高查询效率(避免全表扫描)。
更多关于大数据 Hadoop系列的学习文章,请参阅:进击大数据系列,本系列持续更新中。
来源:https://blog.csdn.net/qq_44992559/article
/details/109724432
读者专属技术群
构建高质量的技术交流社群,欢迎从事后端开发、运维技术进群(备注岗位),相互帮助,一起进步!请文明发言,主要以技术交流、内推、行业探讨为主。
广告人士勿入,切勿轻信私聊,防止被骗

推荐阅读 点击标题可跳转

PS:因为公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。点“在看”支持我们吧!

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 0
0 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)