
树莓派语音聊天机器人实战教程:讯飞与图灵的融合
树莓派(Raspberry Pi)是一款广受欢迎的单板计算机,以其小巧的体积和强大的功能在DIY爱好者和教育领域中颇受欢迎。本章将详细介绍树莓派的核心功能,以及如何将其应用到日常的IT项目中。树莓派是一种小型的单板计算机,它拥有和普通计算机类似的基本硬件组件,但是体积更小,性价比更高。树莓派的主要硬件组件包括:处理器(CPU):树莓派通常使用博通的ARM处理器。不同型号的树莓派搭载的处理器有所不同

简介:本项目详细指导如何利用树莓派构建一个语音聊天机器人,集成了科大讯飞的语音识别技术与图灵机器人的自然语言处理能力。通过实现离线命令识别与人机语音对话功能,介绍了项目的构建步骤、硬件准备、技术要点及优化调试过程。开发者可以跟随本教程,了解如何将讯飞SDK和图灵机器人API应用在实际项目中,以创建具备实时交互能力的语音对话系统。 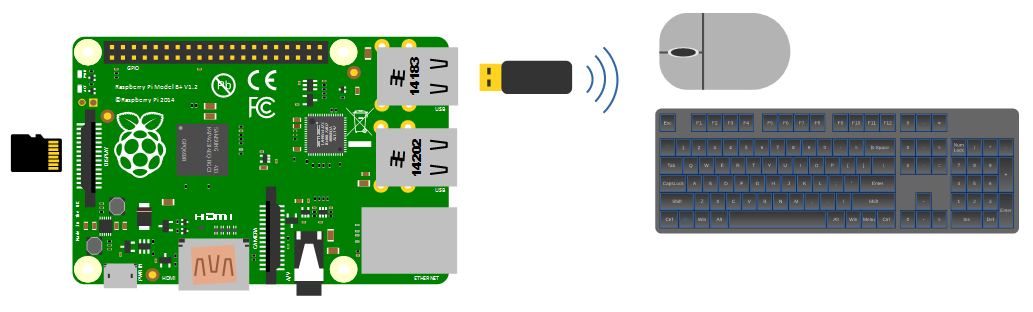
1. 树莓派功能介绍
树莓派(Raspberry Pi)是一款广受欢迎的单板计算机,以其小巧的体积和强大的功能在DIY爱好者和教育领域中颇受欢迎。本章将详细介绍树莓派的核心功能,以及如何将其应用到日常的IT项目中。
1.1 树莓派的核心功能
首先,树莓派具备普通的计算机功能,如处理文本、上网、播放视频等。此外,树莓派还支持GPIO(通用输入输出)功能,通过该接口可以直接控制外部设备,这使其成为连接物理世界与数字世界的理想桥梁。
1.2 树莓派在项目中的应用
在IT项目的实施中,树莓派可用来搭建服务器、制作媒体中心、创建智能家居控制中心等。通过安装不同的操作系统和软件包,树莓派能够适应多种应用场景。我们将在后续章节中深入探讨树莓派在这些领域的具体应用。
2. 讯飞语音SDK集成与离线命令识别
2.1 讯飞语音SDK的安装和配置
讯飞语音SDK是实现语音识别和合成的关键组件,它为开发者提供了强大的语音交互能力。要充分利用讯飞语音SDK的功能,我们首先需要进行安装和配置工作。
2.1.1 讯飞语音SDK的获取和安装
获取讯飞语音SDK的过程相对简单。首先访问讯飞开放平台,注册并登录账号,然后根据平台指引下载适用于树莓派的SDK压缩包。下载完成后,将压缩包传输到树莓派中,并进行解压。
# 下载讯飞语音SDK压缩包到树莓派(以最新版本为例)
wget http://download.xfyun.cn/aiSDK/x86Linux/xfyun_linux_v1.0.0.tar.gz
# 解压SDK
tar -zxvf xfyun_linux_v1.0.0.tar.gz
解压后,进入解压得到的目录,可以找到SDK的使用说明文档和示例代码,这将为我们后续的集成提供指导。
2.1.2 讯飞语音SDK的配置和测试
安装讯飞语音SDK,通常涉及到环境变量的配置。这样,系统在运行时就可以识别到SDK的相关命令和库。我们需要把SDK的bin目录添加到PATH环境变量中,并确保Python的库路径包含了讯飞SDK的lib目录。
# 编辑~/.bashrc或~/.profile文件,添加以下内容
export PATH=/path/to/xfyun_linux_v1.0.0/bin:$PATH
export LD_LIBRARY_PATH=/path/to/xfyun_linux_v1.0.0/lib:$LD_LIBRARY_PATH
# 生效配置
source ~/.bashrc
环境变量配置好后,就可以开始测试SDK是否安装配置成功。通常SDK会提供一个简单的测试工具,通过它我们可以验证安装配置是否正确。
# 在命令行运行讯飞SDK提供的测试工具,以检查安装情况
xfyun_test-tool
成功运行测试工具后,我们将看到讯飞语音SDK的基本信息显示在命令行中,表明安装和配置已经正确完成。
2.2 离线命令识别的实现方法
离线命令识别功能允许设备在没有互联网连接的情况下响应预设的语音指令,这对于需要离线使用的场景来说非常有用。
2.2.1 离线命令识别的原理
离线命令识别利用设备自身的计算能力,不需要将数据上传至服务器进行处理。讯飞语音SDK通过特定的算法和模型,将语音信号转换为对应的文本命令。整个过程涉及到语音信号的采集、特征提取、模式匹配和命令输出。
2.2.2 离线命令识别的实现步骤
为了实现离线命令识别,我们需要进行一系列步骤。首先,需要在讯飞开放平台上训练或选择适合的离线模型。之后,将模型下载到树莓派中并集成到我们的应用中。具体实现步骤如下:
- 在讯飞开放平台创建离线识别任务,上传训练数据并训练模型。
- 下载训练好的模型文件到本地。
- 将模型文件集成到树莓派的应用程序中。
- 在应用中调用讯飞SDK的API来初始化离线识别器,并加载模型。
- 启动语音识别服务,通过识别器进行命令的实时识别。
下面是一个简单的代码示例,演示如何在Python中集成讯飞SDK实现离线命令识别:
from xfyun import OfflineRecognizer
# 初始化离线识别器
recognizer = OfflineRecognizer(model_path="/path/to/model")
# 设置识别参数
recognizer.set_param(key='energyThreshold', value=100)
# 实时录音并识别
while True:
try:
audio_data = capture_audio() # 自定义的录音函数
text = recognizer.recognize(audio_data)
print("识别到的命令:", text)
except Exception as e:
print("识别过程中出现错误:", e)
2.2.3 离线命令识别的测试和调试
在实现离线命令识别功能后,我们需要对其进行测试和调试以确保其稳定性和准确性。测试阶段要覆盖多种环境和不同口音的语音输入,调试则集中在识别精度和响应时间上。
- 测试:应从不同的距离、不同的声音大小、不同的背景噪音等条件下测试语音识别的准确性。
- 调试:如果识别效果不佳,需要调整相关参数,如能量阈值、噪声抑制等。
在测试中,我们可能会使用以下脚本来进行一系列的命令输入,以检验识别率:
#!/bin/bash
commands=("开启电视" "关闭灯光" "播放音乐")
for cmd in "${commands[@]}"
do
echo "测试命令:'$cmd'"
say "$cmd" | ./your_script.sh # 调用识别脚本进行命令识别
done
在 ./your_script.sh 中,包含了启动录音、识别和输出结果的逻辑,确保每次测试都能输出准确的识别结果。通过这个测试流程,我们可以验证离线命令识别功能的鲁棒性。
3. 图灵机器人API接入与对话逻辑
图灵机器人作为AI领域的先行者,为开发者们提供了丰富的人机交互能力。将图灵机器人API接入到树莓派项目中,可以增加语音助手的智能性。而设计一个合理的对话逻辑是实现良好用户体验的关键。以下详细介绍图灵机器人API的接入方法以及如何设计和实现对话逻辑。
3.1 图灵机器人API的接入方法
3.1.1 图灵机器人API的获取和配置
要接入图灵机器人API,首先需要在图灵机器人平台上创建一个账号,并创建一个应用以获得相应的API Key和Secret Key。这通常在创建应用后提供给用户。
以下是获取和配置图灵机器人API的步骤:
- 访问图灵机器人官方网站并注册账号。
- 登录后,创建一个新应用,并记下应用的API Key和Secret Key。
- 在树莓派项目中,使用获取的API Key和Secret Key配置API请求。
import requests
# 图灵机器人API的URL地址
url = "http://www.tuling123.com/openapi/api"
# 你的API Key和Secret Key
app_key = "你的API_KEY"
app_secret = "你的SECRET_KEY"
# 构造请求参数
params = {
"key": app_key,
"info": "今天天气怎么样?",
"uuid": "你的设备唯一标识符"
}
# 发送GET请求
response = requests.get(url, params=params)
# 输出响应内容
print(response.json())
3.1.2 图灵机器人API的测试和调试
为了确保API正确接入,需要进行测试和调试。通常可以使用Postman这样的工具来测试API请求,也可以直接在代码中进行。
测试时需要注意以下几点:
- 使用正确的API Key和Secret Key。
- 构造合法的请求参数。
- 检查返回的数据格式是否正确。
如果遇到问题,检查以下几点:
- 网络连接是否正常。
- API Key和Secret Key是否正确无误。
- 请求参数是否符合图灵机器人API的要求。
# 假设返回的数据格式如下
{
"results": [
{
"text": "今天北京市天气晴朗,适合出门。",
"type": 0,
"err_no": 0,
"err_msg": "成功!",
"action": "",
"id": 12345,
"lcoal_id": 1,
"userinfoid": 123456,
"lan": "zh CN",
"emotion": 0,
"words": "天气晴朗,适合出门。",
"webUrl": "https://tuling123.com/",
"image": "https://tuling123.com/static/image/tuling-logo.png"
}
]
}
3.2 对话逻辑的设计和实现
3.2.1 对话逻辑的设计原则
设计对话逻辑时要遵循以下原则:
- 简单性 :尽量减少用户需要记住的命令或者流程。
- 直接性 :直接回答用户的需求,避免答非所问。
- 健壮性 :应对不确定或意外的输入依然能给出合理的响应。
- 友好性 :使用礼貌、友好的语言与用户交流。
3.2.2 对话逻辑的实现方法
实现对话逻辑,需要编写程序来处理用户的输入,并给出响应。这通常涉及到自然语言处理技术,如意图识别、实体抽取等。
# 根据图灵机器人的API响应进行简单的逻辑处理
def handle_response(response):
data = response.get("results")[0] if response.get("results") else {}
if data.get("err_no") == 0:
# 处理成功的响应
return data.get("text", "")
else:
# 处理错误或未识别的情况
return "对不起,我不太明白您的意思,请您说得更清楚一些。"
# 测试
response = requests.get(url, params=params)
print(handle_response(response.json()))
3.2.3 对话逻辑的测试和优化
对话逻辑的测试和优化是确保用户满意度的关键。通过实际的用户反馈或者使用工具进行模拟测试,可以帮助发现逻辑上的漏洞和不足。
测试阶段需要注意:
- 覆盖性 :尽量覆盖所有可能的输入情况。
- 极端情况 :测试极端或异常输入的情况。
- 用户反馈 :收集用户反馈,并据此调整对话逻辑。
优化对话逻辑可以考虑以下策略:
- 增加更多的意图识别和实体抽取规则。
- 利用机器学习模型进一步提升意图识别的准确性。
- 增强错误处理和引导用户正确表达的能力。
mermaid
graph LR
A[开始对话] --> B[接收用户输入]
B --> C{意图识别}
C -->|已识别| D[提取实体]
C -->|未识别| E[请求用户提供更多信息]
D --> F[生成响应]
E --> B[重新接收用户输入]
F --> G[结束对话或维持对话]
通过不断地测试和优化,可以逐步提升对话逻辑的智能性和用户体验。
4. 树莓派硬件配置与环境设置
4.1 树莓派的硬件配置
4.1.1 树莓派的硬件组件介绍
树莓派是一种小型的单板计算机,它拥有和普通计算机类似的基本硬件组件,但是体积更小,性价比更高。树莓派的主要硬件组件包括:
- 处理器(CPU) :树莓派通常使用博通的ARM处理器。不同型号的树莓派搭载的处理器有所不同,例如树莓派 3B+使用了博通 BCM2837B0 四核处理器。
- 内存(RAM) :树莓派的内存配置在不同型号之间差异较大,从256MB到4GB不等。
- 存储 :树莓派使用SD卡作为存储介质,通过micro SD卡插槽进行扩展。
- 网络连接 :树莓派具有有线网络接口(Ethernet)和无线网络(Wi-Fi),部分型号还内置了蓝牙模块。
- GPIO接口 :通用输入输出(GPIO)接口是树莓派的一个重要特点,允许用户直接与硬件接口进行交互。
- 视频输出接口 :树莓派通常提供HDMI接口和复合视频输出端口,用于连接显示器。
- 音频输出接口 :音频输出可以是3.5mm的模拟音频接口或者HDMI音频输出。
4.1.2 树莓派的硬件配置方法
配置树莓派的硬件一般包括以下几个步骤:
- 选择合适的树莓派型号 :根据项目需求和预算选择适合的树莓派型号。
- 准备SD卡 :购买一张高速且容量满足需求的SD卡。
- 烧录操作系统 :使用Raspberry Pi Imager或者其它工具将操作系统镜像文件烧录到SD卡中。
- 连接外围设备 :将SD卡插入树莓派,连接显示器、键盘、鼠标、网络设备等。
- 首次启动 :初次启动树莓派时,系统会引导你进行基本配置,包括设置地区、语言、网络、用户密码等。
4.2 树莓派的操作环境设置
4.2.1 操作系统的安装和配置
树莓派推荐使用官方的Raspberry Pi OS操作系统,也支持其它Linux发行版。操作系统安装和配置步骤如下:
- 下载操作系统镜像 :访问Raspberry Pi官方网站下载最新的Raspberry Pi OS镜像文件。
- 烧录操作系统镜像到SD卡 :使用烧录工具(如Raspberry Pi Imager)将下载的镜像文件烧录到SD卡中。
- 首次启动 :将SD卡插到树莓派上,接通电源启动设备。
- 执行首次配置 :按照系统提示完成初始配置,包括选择键盘布局、设置Wi-Fi、配置隐私设置等。
- 更新系统 :打开终端,执行以下命令更新系统软件包。
bash sudo apt update sudo apt upgrade
4.2.2 必要软件包的安装和配置
在树莓派上安装和配置项目所需软件包的步骤如下:
- 更新软件源列表 :以管理员权限打开终端,执行
sudo apt update来更新软件源列表。 - 安装必要的软件包 :根据项目需求安装特定的软件包,例如编译工具链、开发库等。例如:
bash sudo apt install build-essential python3-pip libasound2-dev git - 配置网络 :配置静态IP地址以确保树莓派在局域网内可被稳定访问。
- 启动服务 :配置树莓派启动时自动运行特定服务或脚本,如设置自启动脚本
sudo systemctl enable /path/to/your/script.service。 - 安全和性能优化 :按照需要配置SSH密钥认证、禁用root登录、安装防火墙等安全设置,并根据项目需求对系统性能进行调优。
以上步骤完成了树莓派硬件配置与环境设置的核心操作,确保树莓派可以作为项目的基础运行环境,满足硬件和软件上的基本要求。
5. 项目文件结构与功能模块解析
5.1 项目文件的结构和组织
5.1.1 文件的分类和组织方法
项目文件的结构组织是软件工程中至关重要的部分,合理的文件结构不仅有助于提高开发效率,还能使项目更容易维护和扩展。在树莓派项目中,文件可以按照功能、模块或类型进行分类组织。
以功能分类为例,项目文件可以划分为以下几个主要部分:
- 源代码文件夹(src) : 包含所有核心代码,通常按照不同的功能模块进一步细分为多个子文件夹,例如语音识别模块、对话处理模块、硬件控制模块等。
- 资源文件夹(resources) : 包含项目运行所需要的非代码资源,如配置文件、数据库文件、图像、音频文件等。
- 文档文件夹(docs) : 包含项目的文档说明,包括开发文档、用户手册、设计说明等。
- 测试文件夹(tests) : 包含用于测试的脚本和数据。
在组织文件时,可以使用版本控制系统(如Git)进行管理。建议按照功能模块划分分支,每个分支对应特定的开发任务或功能迭代,以便团队协作和代码管理。
5.1.2 文件的读写操作和权限设置
文件的读写操作是项目运行时不可或缺的一部分。在树莓派上,文件的读写操作与Linux系统的文件权限密切相关。每个文件都有所有者、所属组和其他用户三类权限设置,分别是读(r)、写(w)和执行(x)。
例如,为了保护核心代码文件不被修改,可以设置为只读权限:
chmod 444 src/core.py
这里 444 表示所有者、所属组和其他用户均只有读权限。
对于需要频繁读写的临时数据文件,则可以设置读写权限:
chmod 666 temp_data.txt
这里 666 表示所有者、所属组和其他用户都有读写权限。
在编写代码时,通过Python内置的 open() 函数来执行读写操作,例如:
# 读取文件内容
with open('config.txt', 'r') as file:
config_data = file.read()
# 写入文件内容
with open('log.txt', 'a') as file:
file.write("New log entry.")
使用 with 语句可以保证文件正确关闭,避免文件占用等问题。
5.2 功能模块的设计和实现
5.2.1 功能模块的划分和设计方法
功能模块的设计是构建复杂项目的基础。设计方法通常包括以下步骤:
- 需求分析 : 分析项目要实现的功能和性能要求。
- 模块划分 : 根据功能需求将项目划分为若干模块,并确定模块之间的关系。
- 接口设计 : 设计模块间交互的接口,明确输入输出参数。
- 流程设计 : 确定每个模块内部的工作流程和操作步骤。
- 异常处理 : 设计异常处理机制,确保模块稳定运行。
例如,在我们的树莓派项目中,可以将功能划分为以下模块:
- 语音识别模块 : 负责处理语音输入并转换为文本。
- 对话管理模块 : 根据识别结果进行对话逻辑处理。
- 硬件控制模块 : 根据对话结果控制树莓派上的硬件设备。
- 日志记录模块 : 记录项目的运行日志,便于调试和性能监控。
5.2.2 功能模块的实现和测试
功能模块实现是指根据设计方法完成编码的过程。在树莓派项目中,各个模块的实现通常涉及特定的编程语言和技术栈。例如,硬件控制模块可能需要使用GPIO库来控制树莓派上的各种硬件接口。
代码实现后,需要进行测试验证其功能是否满足设计要求。测试方法可以分为以下几种:
- 单元测试 : 测试单个模块的功能是否正常,通常由开发者完成。
- 集成测试 : 测试多个模块组合在一起时是否能够正常工作。
- 系统测试 : 测试整个系统在模拟运行环境下的表现。
- 性能测试 : 测试系统的响应速度、资源消耗等性能指标。
例如,针对语音识别模块,可以编写单元测试来验证识别准确性:
import unittest
from voice_recognition_module import recognize_speech
class TestVoiceRecognition(unittest.TestCase):
def test_speech_recognition_accuracy(self):
test_audio_file = 'test_audio.wav'
recognized_text = recognize_speech(test_audio_file)
expected_text = "Expected speech recognition result"
self.assertEqual(recognized_text, expected_text)
if __name__ == '__main__':
unittest.main()
5.2.3 功能模块的优化和维护
功能模块在测试通过后,可能还需要进行优化以提高性能或修正发现的问题。优化可以从以下几个方面进行:
- 代码优化 : 精简代码逻辑,提高执行效率。
- 资源优化 : 减少不必要的资源消耗,如内存和存储空间。
- 算法优化 : 改进算法以提高数据处理速度和准确性。
例如,针对语音识别模块,可以使用更高效的算法来减少处理时间:
# 使用高效的算法库进行语音识别
import speech_recognition as sr
recognizer = sr.Recognizer()
with sr.Microphone() as source:
audio_data = recognizer.listen(source)
try:
recognized_text = recognizer.recognize_google(audio_data)
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print(f"Could not request results from Google Speech Recognition service; {e}")
print(f"Recognized: {recognized_text}")
在模块的维护方面,需要定期更新依赖的库和框架,修复已知的bug,以及根据用户反馈进行功能改进。
通过细致的测试和优化,确保每个功能模块都能高效且稳定地工作,整个项目才能达到预期的运行效果。
6. 语音输入输出处理流程
语音识别和语音合成是实现人机交互的重要技术,它们让机器能够理解和响应人类的语音指令。在本章中,我们将详细探讨语音输入和输出的处理流程,包括它们的获取、处理、生成、播放以及相关测试和优化方法。
6.1 语音输入的处理流程
语音输入处理是整个交互系统的第一步,它需要准确无误地捕捉到用户的指令并将其转换为机器可读的文本格式。
6.1.1 语音输入的获取和处理方法
要实现语音输入的获取,我们需要使用音频捕获设备(如麦克风)和适当的软件库。在树莓派上,可以使用 ALSA (Advanced Linux Sound Architecture) 等库来实现音频的捕获。
arecord -D plughw:1,0 -f cd -d 5 output.wav
上述命令使用 arecord 程序从默认输入设备捕获5秒的音频,并保存为 output.wav 文件。
在捕获了音频文件后,需要对音频数据进行预处理,如降噪、静音检测等,以提高语音识别的准确性。接下来,使用讯飞语音SDK进行语音到文本的转换。
6.1.2 语音输入的测试和优化
在测试阶段,要确保输入的语音能够被准确识别,并且对各种环境噪音具有较强的鲁棒性。可以通过调整预处理参数,或选择不同场景下的语音样本进行训练和测试。
import speech_recognition as sr
recognizer = sr.Recognizer()
with sr.Microphone() as source:
audio_data = recognizer.listen(source)
try:
text = recognizer.recognize_google(audio_data)
print("You said: " + text)
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
在上述代码中, speech_recognition 库被用来捕获和识别语音数据。对识别结果进行分析,并根据需要进行优化。
6.2 语音输出的处理流程
语音输出是将文本信息转化为语音信息反馈给用户,它的重要性不亚于语音输入,特别是在不便使用视觉信息的场景中。
6.2.1 语音输出的生成和播放方法
生成语音输出主要涉及文本到语音(Text-to-Speech, TTS)技术。树莓派上可以使用如Google TTS、MaryTTS等服务。
import os
from gtts import gTTS
import pygame
text_to_speak = "Hello, I am a tree莓派 speaking to you."
tts = gTTS(text=text_to_speak, lang='en')
tts.save("hello.mp3")
pygame.mixer.init()
pygame.mixer.music.load("hello.mp3")
pygame.mixer.music.play()
while pygame.mixer.music.get_busy():
pygame.time.Clock().tick(10)
在以上示例中, gTTS 用于生成语音输出文件,并使用 pygame 库进行播放。这样的语音输出可以增强用户体验,特别是在提供指令响应时。
6.2.2 语音输出的测试和优化
测试语音输出时,要考虑播放的清晰度、语速、音调和情感等。优化可能包括选择更合适的TTS引擎、调整语音参数或者对特定语言或方言的支持。
性能测试是语音输出优化的重要环节,通过反复测试来评估不同参数设置对输出语音质量的影响。例如,调整 rate 参数来控制语速,或使用不同性别和年龄段的声音样本来提高输出的自然度。
以上两小节详细阐述了语音输入输出的处理流程。从获取、处理到测试和优化,每一步都是必不可少的,它们确保了系统的有效性和用户的满意度。接下来的章节将深入讨论如何在系统中进一步进行性能优化与用户体验提升。
简介:本项目详细指导如何利用树莓派构建一个语音聊天机器人,集成了科大讯飞的语音识别技术与图灵机器人的自然语言处理能力。通过实现离线命令识别与人机语音对话功能,介绍了项目的构建步骤、硬件准备、技术要点及优化调试过程。开发者可以跟随本教程,了解如何将讯飞SDK和图灵机器人API应用在实际项目中,以创建具备实时交互能力的语音对话系统。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 24
24 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)