
人工神经网络与梯度下降法
人工神经网络(Artificial Neural Networks, ANN)是模拟生物神经元结构的计算模型,它模仿了大脑处理信息的基本方式。人工神经网络是由大量的简单处理单元——即“神经元”——组成的网络,这些神经元通过连接权重进行交互,并能够对输入数据进行复杂的非线性变换。人工神经网络通过调整连接权重来学习数据中的模式。这个过程通常涉及以下几个步骤:单个神经元示意图:对于一个简单的神经元,其输
1 人工神经网络
人工神经网络(Artificial Neural Networks, ANN)是模拟生物神经元结构的计算模型,它模仿了大脑处理信息的基本方式。人工神经网络是由大量的简单处理单元——即“神经元”——组成的网络,这些神经元通过连接权重进行交互,并能够对输入数据进行复杂的非线性变换。
1.1 工作原理
人工神经网络通过调整连接权重来学习数据中的模式。这个过程通常涉及以下几个步骤:
- 前向传播:输入数据通过网络向前传递,从输入层到输出层,经过一系列的加权和激活操作。
- 损失计算:输出层产生的结果与实际目标进行比较,得到一个误差度量,称为损失函数。
- 反向传播:通过计算损失函数相对于每个权重的梯度,然后根据这个梯度调整权重,以减小损失。
- 优化算法:如梯度下降等方法用于更新权重,目的是最小化损失函数。
1.2 人工神经网络的组成
- 神经元(Neuron):是神经网络的基本单元,类似于生物神经元的结构。
- 输入层(Input Layer):接收外部输入数据。
- 隐藏层(Hidden Layer):一个或多个,负责处理输入层传来的数据,并进行非线性变换。
- 输出层(Output Layer):输出最终结果。
1.3 数学原理
- 权重(Weight):每个神经元之间的连接都有一个权重,表示连接的强度。
- 偏置(Bias):每个神经元都有一个偏置,用于调整输出值。
- 激活函数(Activation Function):用于引入非线性因素,常见的激活函数有Sigmoid、ReLU等。
以下是神经网络的基本数学原理:
1.3.1 前向传播(Forward Propagation)
单个神经元示意图: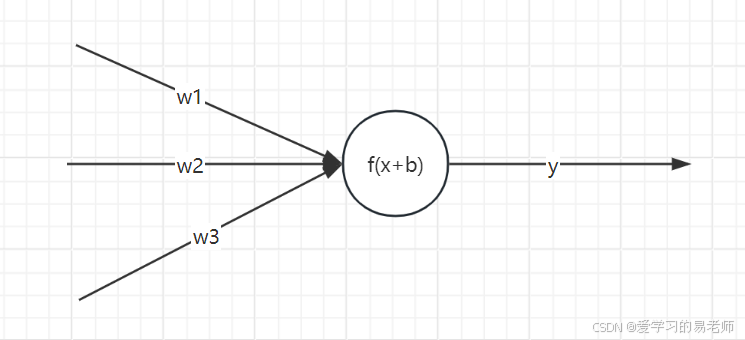
对于一个简单的神经元,其输出计算公式为:
a=σ(∑i=1nwixi+b) a = \sigma(\sum_{i=1}^{n} w_i x_i + b) a=σ(i=1∑nwixi+b)
其中:
- aaa:神经元的输出
- σ\sigmaσ:激活函数
- wiw_iwi:第iii个输入的权重
- xix_ixi:第iii个输入
- bbb:偏置
对于多层神经网络,前向传播的过程可以表示为:
z[l]=W[l]a[l−1]+b[l] z^{[l]} = W^{[l]} a^{[l-1]} + b^{[l]} z[l]=W[l]a[l−1]+b[l]
a[l]=σ(z[l]) a^{[l]} = \sigma(z^{[l]}) a[l]=σ(z[l])
其中: - z[l]z^{[l]}z[l]:第lll层的线性组合
- W[l]W^{[l]}W[l]:第lll层的权重矩阵
- a[l−1]a^{[l-1]}a[l−1]:第l−1l-1l−1层的输出
- b[l]b^{[l]}b[l]:第lll层的偏置
- a[l]a^{[l]}a[l]:第lll层的输出
1.3.2 激活函数示例
Sigmoid函数:
σ(z)=11+e−z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1
ReLU函数:
ReLU(z)=max(0,z) \text{ReLU}(z) = \max(0, z) ReLU(z)=max(0,z)
1.4 简单示例
假设我们有一个简单的神经网络,只有一个输入层、一个隐藏层和一个输出层。输入层有一个神经元,隐藏层有两个神经元,输出层有一个神经元。激活函数使用Sigmoid。
输入层到隐藏层的计算
设输入为xxx,隐藏层两个神经元的权重分别为w1w_1w1和w2w_2w2,偏置分别为b1b_1b1和b2b_2b2,则隐藏层的输出为:
z1=w1x+b1 z_1 = w_1 x + b_1 z1=w1x+b1
a1=σ(z1) a_1 = \sigma(z_1) a1=σ(z1)
z2=w2x+b2 z_2 = w_2 x + b_2 z2=w2x+b2
a2=σ(z2) a_2 = \sigma(z_2) a2=σ(z2)
隐藏层到输出层的计算
设隐藏层到输出层的权重分别为v1v_1v1和v2v_2v2,偏置为ccc,则输出层的输出为:
zout=v1a1+v2a2+c z_{\text{out}} = v_1 a_1 + v_2 a_2 + c zout=v1a1+v2a2+c
aout=σ(zout) a_{\text{out}} = \sigma(z_{\text{out}}) aout=σ(zout)
这就是一个简单的人工神经网络的数学原理和计算过程。在实际应用中,神经网络的结构和参数需要通过训练数据来学习得到。
如图:
由上图我们约定以下表示。a1、a2、h1、h2…代表神经元的名字。
a1ia1_ia1i代表a1神经元的输入,a1oa1_oa1o代表a1神经元的输出。
a1与a2代表输入层,通常情况下输入层通常不包含权重和激活函数,它仅仅接收数据。
2与3是当前神经网络的输入。当2输入到a1神经元后即a1i=2a1_i=2a1i=2,由于a1是输入层神经元,从而变成a1o=a1i=2 a1_o = a1_i=2 a1o=a1i=2
当3输入到神经元后,同理,从而变成a2o=a2i=3 a2_o= a2_i=3 a2o=a2i=3
此时神经元分别输出a1oa1_oa1o 、a2oa2_oa2o。
从图中我们可以看出,a1oa1_oa1o 、a2oa2_oa2o首先会作为隐藏层(中间那一列的神经元)的输入。
对于隐藏层神经元我们可以得到
h1i=a1o∗1+a2o∗2h1_i =a1_o*1+a2_o*2h1i=a1o∗1+a2o∗2
h1o=σ(h1i+b)h1_o = \sigma(h1_i+ b)h1o=σ(h1i+b)
h2i=a1o∗2+a2o∗3h2_i =a1_o*2+a2_o*3h2i=a1o∗2+a2o∗3
h2o=σ((h2i+b)+b)h2_o = \sigma((h2_i+ b)+ b)h2o=σ((h2i+b)+b)
…
注意
在通常情况下,输入层通常不包含权重和激活函数,它的主要功能是接收外部输入数据并将其传递给网络的下一层次,即隐藏层。输入层的节点(或称为神经元)只是简单地持有输入数据的值,并没有进行任何计算或变换。
思考
1、你可以把其它几个神经元的输入输出写出来了吗?
2、我们如何用计算机能看懂的方式去实现计算呢?
输入层定义
给定输入向量 x=[x1,x2]=[2,3]\mathbf{x} = [x_1, x_2] = [2, 3]x=[x1,x2]=[2,3]。
隐藏层权重与偏置
隐藏层到输出层的权重矩阵定义为:
Whidden=[12231131] \mathbf{W}_{\text{hidden}} = \begin{bmatrix} 1 & 2 \\ 2 & 3 \\ 1 & 1 \\ 3 & 1 \end{bmatrix} Whidden=⎣⎢⎢⎡12132311⎦⎥⎥⎤
假设每个隐藏层神经元的偏置都是 0.20.20.2,则偏置向量为:
bhidden=[0.20.20.20.2] \mathbf{b}_{\text{hidden}} = \begin{bmatrix} 0.2 \\ 0.2 \\ 0.2 \\ 0.2 \end{bmatrix} bhidden=⎣⎢⎢⎡0.20.20.20.2⎦⎥⎥⎤
计算隐藏层的输入
隐藏层每个神经元的输入计算如下:
zhidden=Whidden⋅x+bhidden \mathbf{z}_{\text{hidden}} = \mathbf{W}_{\text{hidden}} \cdot \mathbf{x} + \mathbf{b}_{\text{hidden}} zhidden=Whidden⋅x+bhidden
具体计算过程如下:
zhidden=[12231131]⋅[23]+[0.20.20.20.2] \mathbf{z}_{\text{hidden}} = \begin{bmatrix} 1 & 2 \\ 2 & 3 \\ 1 & 1 \\ 3 & 1 \end{bmatrix} \cdot \begin{bmatrix} 2 \\ 3 \end{bmatrix} + \begin{bmatrix} 0.2 \\ 0.2 \\ 0.2 \\ 0.2 \end{bmatrix} zhidden=⎣⎢⎢⎡12132311⎦⎥⎥⎤⋅[23]+⎣⎢⎢⎡0.20.20.20.2⎦⎥⎥⎤
zhidden=[1⋅2+2⋅32⋅2+3⋅31⋅2+1⋅33⋅2+1⋅3]+[0.20.20.20.2] \mathbf{z}_{\text{hidden}} = \begin{bmatrix} 1 \cdot 2 + 2 \cdot 3 \\ 2 \cdot 2 + 3 \cdot 3 \\ 1 \cdot 2 + 1 \cdot 3 \\ 3 \cdot 2 + 1 \cdot 3 \end{bmatrix} + \begin{bmatrix} 0.2 \\ 0.2 \\ 0.2 \\ 0.2 \end{bmatrix} zhidden=⎣⎢⎢⎡1⋅2+2⋅32⋅2+3⋅31⋅2+1⋅33⋅2+1⋅3⎦⎥⎥⎤+⎣⎢⎢⎡0.20.20.20.2⎦⎥⎥⎤
zhidden=[2+64+92+36+3]+[0.20.20.20.2] \mathbf{z}_{\text{hidden}} = \begin{bmatrix} 2 + 6 \\ 4 + 9 \\ 2 + 3 \\ 6 + 3 \end{bmatrix} + \begin{bmatrix} 0.2 \\ 0.2 \\ 0.2 \\ 0.2 \end{bmatrix} zhidden=⎣⎢⎢⎡2+64+92+36+3⎦⎥⎥⎤+⎣⎢⎢⎡0.20.20.20.2⎦⎥⎥⎤
zhidden=[8.213.25.29.2] \mathbf{z}_{\text{hidden}} = \begin{bmatrix} 8.2 \\ 13.2 \\ 5.2 \\ 9.2 \end{bmatrix} zhidden=⎣⎢⎢⎡8.213.25.29.2⎦⎥⎥⎤
应用激活函数
隐藏层的输出使用sigmoid函数:
ahidden=σ(zhidden)=11+e−zhidden \mathbf{a}_{\text{hidden}} = \sigma(\mathbf{z}_{\text{hidden}}) = \frac{1}{1 + e^{-\mathbf{z}_{\text{hidden}}}} ahidden=σ(zhidden)=1+e−zhidden1
对于每个元素 ziz_izi:
σ(8.2)≈0.9997,σ(13.2)≈0.9999,σ(5.2)≈0.9933,σ(9.2)≈0.9998 \sigma(8.2) \approx 0.9997, \quad \sigma(13.2) \approx 0.9999, \quad \sigma(5.2) \approx 0.9933, \quad \sigma(9.2) \approx 0.9998 σ(8.2)≈0.9997,σ(13.2)≈0.9999,σ(5.2)≈0.9933,σ(9.2)≈0.9998
因此:
ahidden≈[0.99970.99990.99330.9998] \mathbf{a}_{\text{hidden}} \approx \begin{bmatrix} 0.9997 \\ 0.9999 \\ 0.9933 \\ 0.9998 \end{bmatrix} ahidden≈⎣⎢⎢⎡0.99970.99990.99330.9998⎦⎥⎥⎤
输出层的输入
输出层到隐藏层的权重矩阵定义为:
Woutput=[11111001] \mathbf{W}_{\text{output}} = \begin{bmatrix} 1 & 1 & 1 & 1 \\ 1 & 0 & 0 & 1 \end{bmatrix} Woutput=[11101011]
输出层的偏置向量假设为:
boutput=[0.20.2] \mathbf{b}_{\text{output}} = \begin{bmatrix} 0.2 \\ 0.2 \end{bmatrix} boutput=[0.20.2]
输出层的输出计算如下:
zoutput=σ(Woutput⋅ahidden+boutput) \mathbf{z}_{\text{output}} = \sigma(\mathbf{W}_{\text{output}} \cdot \mathbf{a}_{\text{hidden}} + \mathbf{b}_{\text{output}}) zoutput=σ(Woutput⋅ahidden+boutput)
接下来,您可以根据这些步骤计算输出层的输入和最终的输出。
练习:
计算上图中的y1与y2。
2 梯度下降法
#2.1 梯度下降法的数据基础
梯度下降法是一种更新神经网络参数的算法,该算法是一种迭代算法,其目的是找到函数的最优值。梯度指的函数在某点处沿着其方向导数的方向所取得的最大值。
梯度是一个矢量,梯度的值表示函数在此点的最大斜率或变化率,梯度的总体方向表示函数在此点的变化方向。梯度下降法的优化过程是沿着函数的梯度寻找最优值。
当然可以。梯度是数学分析中的一个基本概念,特别是在向量分析和优化问题中。以下是梯度的定义和关键点:
- 定义:梯度是一个多变量函数在其定义域内的某一点处变化最快的方向,以及在该方向上的变化率。
- 数学表示:对于实值函数 f(x)f(\mathbf{x})f(x),其中 x=[x1,x2,…,xn]\mathbf{x} = [x_1, x_2, \ldots, x_n]x=[x1,x2,…,xn] 是一个包含 nnn 个变量的向量,梯度通常表示为 ∇f(x)\nabla f(\mathbf{x})∇f(x) 或 ∂if(x)\partial_i f(\mathbf{x})∂if(x),并定义为:
∇f(x)=[∂f∂x1,∂f∂x2,…,∂f∂xn] \nabla f(\mathbf{x}) = \left[ \frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, \ldots, \frac{\partial f}{\partial x_n} \right] ∇f(x)=[∂x1∂f,∂x2∂f,…,∂xn∂f]
这里,∂f∂xi\frac{\partial f}{\partial x_i}∂xi∂f 是函数 fff 对变量 xix_ixi 的偏导数。 - 向量性质:梯度是一个向量,其分量是函数对各个变量的偏导数,因此梯度的方向指示了函数增长最快的方向,其大小(模长)表示在该方向上的增长率。
- 几何意义:在三维空间中,如果将梯度向量 ∇f(x)\nabla f(\mathbf{x})∇f(x) 放在点 x\mathbf{x}x 上,则该向量垂直于函数 fff 在该点的等高线(或等值面),并且指向函数值增加最快的方向。
- 应用:
- 优化:在优化问题中,梯度下降法利用梯度的信息来找到函数的局部最小值。算法通过沿着梯度的反方向更新变量,以减少函数的值。
- 物理:在物理学中,梯度可以表示物理量的空间变化率,如温度或电势。
- 特殊情况:对于单变量函数,梯度简化为该函数的导数,并且是一个标量而不是向量。
总结来说,梯度是一个多变量函数在特定点上关于各个变量的偏导数构成的向量,它描述了函数在该点处最大增长的方向和增长的速度。
自变量如何变化,才能使得应变量快速地变成最小值??????
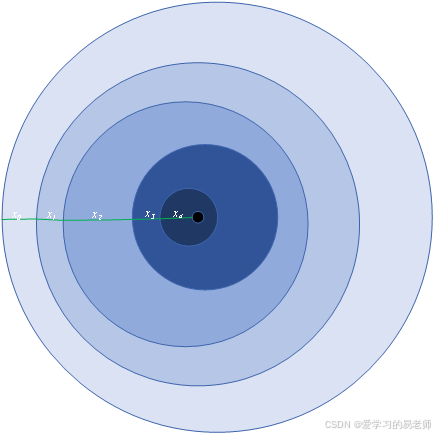
图2中每一次下降的移动方向都与出发点垂直。
现有函数,第kkk次的迭代值记为f(xk)f(x_k)f(xk),迭代kkk次后最优值表示为x∗x^*x∗。对于在xxx的梯度如公式所示。
∇f(x)\nabla f(x)∇f(x)
在函数仅有一阶导数时。
若存在多个自变量如x1,x2,...,xnx_1, x_2, ..., x_nx1,x2,...,xn,则梯度公式如公式所示。
∇f(x)=(∂f∂x1,∂f∂x2,...,∂f∂xn)\nabla f(x) = \left( \frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, ..., \frac{\partial f}{\partial x_n} \right)∇f(x)=(∂x1∂f,∂x2∂f,...,∂xn∂f)
对于第kkk次迭代值如公式所示。
xk+1=xk−α∇f(xk)x_{k+1} = x_k - \alpha \nabla f(x_k)xk+1=xk−α∇f(xk)
代表第kkk次的步长,α\alphaα是当前梯度。在梯度下降的情况下,α\alphaα的值为正数,且必须大于0。多次迭代的目的是使得公式成立。
f(x∗)=minxf(x)f(x^*) = \min_{x} f(x)f(x∗)=xminf(x)
2.2 神经网络的梯度下降法
梯度下降法常用于神经网络的参数更新,设神经网络的权值参数为www,是一个该神经网络所有参数的集合。往神经网络输入数据后,输入数据与神经网络的参数进行矩阵运算得出结果,如公式所示。
y^=fw(x)\hat{y} = f_w(x)y^=fw(x)
是神经网络模型,XXX是所以输入数据的集合,通常是一个矩阵,X可以是多条数据的集合。当得出预测值后需要求该预测值与标签值的误差,即存在误差函数如公式(2.19)所示。
L(y^,y)=12(y^−y)2L(\hat{y}, y) = \frac{1}{2} (\hat{y} - y)^2L(y^,y)=21(y^−y)2
函数显示了预测值与标签值的差距,此时需要调整神经网络的www,使得值最小。这一步可以用2.2.1小节所示的梯度下降法更新参数以求得最小值。此时需要将公式(2.19)中的www作为自变量,X,yX, yX,y作为固定值。如公式(2.20)所示。
∇wL(y^,y)\nabla_w L(\hat{y}, y)∇wL(y^,y)
则根据梯度下降法,参数的更新公式如公式(2.21)所示。
w←w−α∇wL(y^,y)w \leftarrow w - \alpha \nabla_w L(\hat{y}, y)w←w−α∇wL(y^,y)
2.2.3 数学计算示例
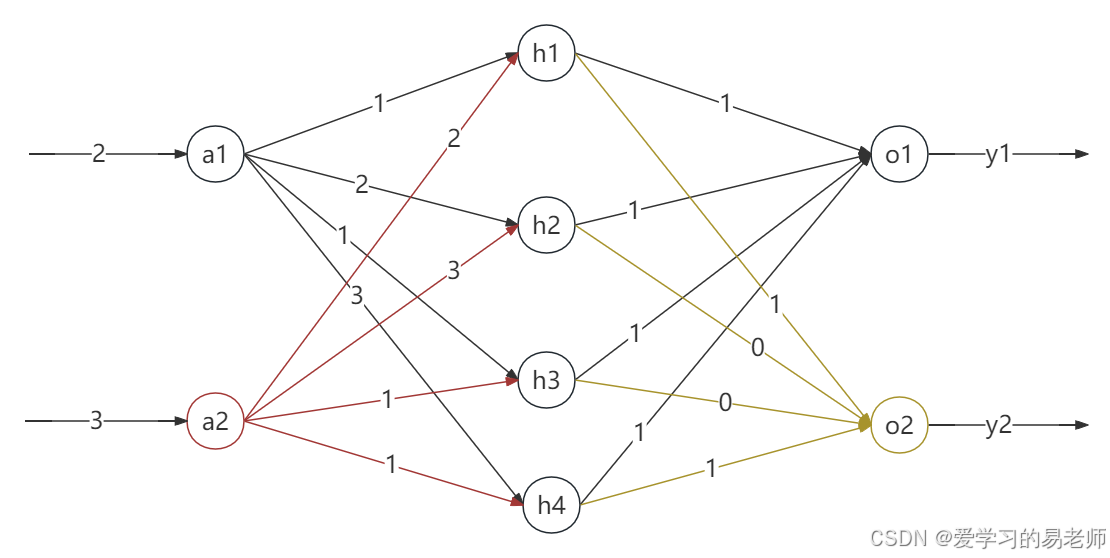
以本图为例:
假设:
激活函数为 f(x+b)=2(x+0)=2xf(x+b)=2(x+0)=2xf(x+b)=2(x+0)=2x
损失函数为 f(yt,ym)=12(yt−ym)2f(y_t,y_m)=\frac{1}{2}(y_t-y_m)^2f(yt,ym)=21(yt−ym)2
yty_tyt代表标签,ymy_mym代表模型输出。
隐藏层到输出层的权重矩阵定义为:
Whidden=[12231131] \mathbf{W}_{\text{hidden}} = \begin{bmatrix} 1 & 2 \\ 2 & 3 \\ 1 & 1 \\ 3 & 1 \end{bmatrix} Whidden=⎣⎢⎢⎡12132311⎦⎥⎥⎤
输出层到隐藏层的权重矩阵定义为:
Woutput=[11111001] \mathbf{W}_{\text{output}} = \begin{bmatrix} 1 & 1 & 1 & 1 \\ 1 & 0 & 0 & 1 \end{bmatrix} Woutput=[11101011]
偏置bias=0bias=0bias=0
输入 x=[2,3]x=[2,3]x=[2,3] 标签为yt=[2,3]y_t=[2,3]yt=[2,3]
则计算过程为:
首先,我们需要根据给定的网络结构和参数计算模型的输出。这个过程涉及到前向传播。然后,我们将计算损失函数的梯度,并更新权重矩阵。这个过程称为反向传播。
前向传播
-
计算隐藏层的输出:
隐藏层的输出是由输入层通过隐藏层权重矩阵计算得到的。我们使用给定的激活函数 f(x+b)=2xf(x+b) = 2xf(x+b)=2x。
h=f(Whidden⋅x+b)=2(Whidden⋅x) \mathbf{h} = f(\mathbf{W}_{\text{hidden}} \cdot \mathbf{x} + \mathbf{b}) = 2(\mathbf{W}_{\text{hidden}} \cdot \mathbf{x}) h=f(Whidden⋅x+b)=2(Whidden⋅x)
其中 x=[2,3]\mathbf{x} = [2, 3]x=[2,3],b\mathbf{b}b 是偏置,这里为0。 -
计算输出层的输出:
输出层的输出是由隐藏层通过输出层权重矩阵计算得到的。
ym=Woutput⋅h \mathbf{y}_m = \mathbf{W}_{\text{output}} \cdot \mathbf{h} ym=Woutput⋅h
接下来,我们将使用Python来计算这些值。
import numpy as np
#定义权重矩阵和输入
W_hidden = np.array([[1, 2], [2, 3], [1, 1], [3, 1]])
W_output = np.array([[1, 1, 1, 1], [1, 0, 0, 1]])
x = np.array([2, 3])
bias = 0
#计算隐藏层的输出
h = 2 * (W_hidden @ x)
#计算输出层的输出
y_m = W_output @ h
h, y_m
(array([16, 26, 10, 18]), array([70, 34]))
隐藏层的输出为 [16,26,10,18][16, 26, 10, 18][16,26,10,18],输出层的输出(模型输出)为 [70,34][70, 34][70,34]。
反向传播
- 计算损失函数的梯度:
损失函数为 f(yt,ym)=12(yt−ym)2f(y_t, y_m) = \frac{1}{2}(y_t - y_m)^2f(yt,ym)=21(yt−ym)2。我们需要计算损失函数关于模型输出 ymy_mym 的梯度。
∇ymf(yt,ym)=ym−yt \nabla_{y_m} f(y_t, y_m) = y_m - y_t ∇ymf(yt,ym)=ym−yt - 计算输出层权重的梯度:
梯度是损失函数关于输出层权重矩阵的导数。
∇Woutputf=∇ymf(yt,ym)⋅hT \nabla_{\mathbf{W}_{\text{output}}} f = \nabla_{y_m} f(y_t, y_m) \cdot \mathbf{h}^T ∇Woutputf=∇ymf(yt,ym)⋅hT - 计算隐藏层权重的梯度:
梯度是损失函数关于隐藏层权重矩阵的导数。
∇Whiddenf=∇Woutputf⋅Woutput⋅2⋅xT \nabla_{\mathbf{W}_{\text{hidden}}} f = \nabla_{\mathbf{W}_{\text{output}}} f \cdot \mathbf{W}_{\text{output}} \cdot 2 \cdot \mathbf{x}^T ∇Whiddenf=∇Woutputf⋅Woutput⋅2⋅xT - 更新权重:
使用梯度下降法更新权重。这里我们假设学习率为 η\etaη。
Woutput′=Woutput−η∇Woutputf \mathbf{W}_{\text{output}}' = \mathbf{W}_{\text{output}} - \eta \nabla_{\mathbf{W}_{\text{output}}} f Woutput′=Woutput−η∇Woutputf
Whidden′=Whidden−η∇Whiddenf \mathbf{W}_{\text{hidden}}' = \mathbf{W}_{\text{hidden}} - \eta \nabla_{\mathbf{W}_{\text{hidden}}} f Whidden′=Whidden−η∇Whiddenf
接下来,我们将计算这些梯度,并假设学习率为0.01来更新权重。
思考:一次性输入多条数据怎么办??
当时是求平均,求多条数据算出的梯度,然后求平均就是当前批次算出的梯度。
定义标签和学习率
yt=np.array([2,3])y_t = np.array([2, 3])yt=np.array([2,3])
eta=0.01eta = 0.01eta=0.01
-
计算输出层的梯度:首先,我们计算损失函数关于输出层输出 $ y_m $ 的梯度。这是因为损失函数直接依赖于模型输出和真实标签。
∇ymf(yt,ym)=∂f∂ym=ym−yt \nabla_{y_m} f(y_t, y_m) = \frac{\partial f}{\partial y_m} = y_m - y_t ∇ymf(yt,ym)=∂ym∂f=ym−yt -
传播梯度到输出层权重:然后,我们使用链式法则将这个梯度传播到输出层的权重。这涉及到计算损失函数关于每个输出层权重的偏导数。
∇Woutputf=∂f∂Woutput=∇ymf(yt,ym)⋅hT \nabla_{\mathbf{W}_{\text{output}}} f = \frac{\partial f}{\partial \mathbf{W}_{\text{output}}} = \nabla_{y_m} f(y_t, y_m) \cdot \mathbf{h}^T ∇Woutputf=∂Woutput∂f=∇ymf(yt,ym)⋅hTym=Woutputh \mathbf{y}_m = \mathbf{W}_{\text{output}} \mathbf{h} ym=Woutputh
根据链式法则,损失函数关于输出层权重 Woutput\mathbf{W}_{\text{output}}Woutput 的梯度可以表示为:
∇Woutputf=∂f∂ym⋅∂ym∂Woutput \nabla_{\mathbf{W}_{\text{output}}} f = \frac{\partial f}{\partial \mathbf{y}_m} \cdot \frac{\partial \mathbf{y}_m}{\partial \mathbf{W}_{\text{output}}} ∇Woutputf=∂ym∂f⋅∂Woutput∂ym
我们已经计算了 ∂f∂ym\frac{\partial f}{\partial \mathbf{y}_m}∂ym∂f,即 ∇ymf(yt,ym)\nabla_{y_m} f(y_t, y_m)∇ymf(yt,ym)。接下来,我们需要计算 ∂ym∂Woutput\frac{\partial \mathbf{y}_m}{\partial \mathbf{W}_{\text{output}}}∂Woutput∂ym。 -
计算 ∂ym∂Woutput\frac{\partial \mathbf{y}_m}{\partial \mathbf{W}_{\text{output}}}∂Woutput∂ym:由于 ym=Woutputh\mathbf{y}_m = \mathbf{W}_{\text{output}} \mathbf{h}ym=Woutputh,我们可以得出:
∂ym∂Woutput=hT \frac{\partial \mathbf{y}_m}{\partial \mathbf{W}_{\text{output}}} = \mathbf{h}^T ∂Woutput∂ym=hT
之所以是 hT\mathbf{h}^ThT 是因为矩阵乘的时候转置了。现在要求一一对应所有要转置回来。
这是因为对于矩阵 Woutput\mathbf{W}_{\text{output}}Woutput 中的每个元素 wijw_{ij}wij,ym\mathbf{y}_mym 的第 iii 个元素是 wijw_{ij}wij 和 h\mathbf{h}h 的第jjj 个元素的乘积之和。 -
最终梯度:将这两个部分结合起来,我们得到:
∇Woutputf=(ym−yt)⋅hT \nabla_{\mathbf{W}_{\text{output}}} f = (\mathbf{y}_m - \mathbf{y}_t) \cdot \mathbf{h}^T ∇Woutputf=(ym−yt)⋅hT
这就是损失函数关于输出层权重矩阵的梯度。通过这个梯度,我们可以更新输出层的权重,以减少损失函数的值。 -
计算隐藏层的梯度:接下来,我们需要计算损失函数关于隐藏层输出的梯度,然后将这个梯度传播到隐藏层的权重。
∇hf=∂f∂h=∂f∂ym⋅∂ym∂h \nabla_{\mathbf{h}} f = \frac{\partial f}{\partial \mathbf{h}} = \frac{\partial f}{\partial \mathbf{y}_m} \cdot \frac{\partial \mathbf{y}_m}{\partial \mathbf{h}} ∇hf=∂h∂f=∂ym∂f⋅∂h∂ym
∇hf=∂f∂h=WoutputT⋅∇ymf(yt,ym) \nabla_{\mathbf{h}} f = \frac{\partial f}{\partial \mathbf{h}} = \mathbf{W}_{\text{output}}^T \cdot \nabla_{y_m} f(y_t, y_m) ∇hf=∂h∂f=WoutputT⋅∇ymf(yt,ym) -
传播梯度到隐藏层权重:最后,我们将这个梯度传播到隐藏层的权重。
∇Whiddenf=∂f∂Whidden=∇hf⋅xT \nabla_{\mathbf{W}_{\text{hidden}}} f = \frac{\partial f}{\partial \mathbf{W}_{\text{hidden}}} = \nabla_{\mathbf{h}} f \cdot \mathbf{x}^T ∇Whiddenf=∂Whidden∂f=∇hf⋅xT
2.3 代码计算1
import numpy as np
# 定义权重矩阵、输入和标签
W_hidden = np.array([[1, 2], [2, 3], [1, 1], [3, 1]])
W_output = np.array([[1, 1, 1, 1], [1, 0, 0, 1]])
x = np.array([2, 3])
y_t = np.array([2, 3])
bias = 0
eta = 0.01 # 学习率
# 步骤 1: 前向传播
# 计算隐藏层输出
h = 2 * (W_hidden @ x)
# 计算输出层输出
y_m = W_output @ h
# 步骤 2: 反向传播
# 计算损失函数关于模型输出的梯度
grad_y_m = y_m - y_t
# 计算输出层权重的梯度
grad_W_output = grad_y_m[:, np.newaxis] * h[np.newaxis, :]
# 计算损失函数关于隐藏层输出的梯度
grad_h = W_output.T @ grad_y_m
# 计算隐藏层权重的梯度
grad_W_hidden = grad_h[:, np.newaxis] * x[np.newaxis, :]
# 步骤 3: 更新参数
W_output_new = W_output - eta * grad_W_output
W_hidden_new = W_hidden - eta * grad_W_hidden
# 输出:h, y_m, grad_y_m, grad_W_output, grad_h, grad_W_hidden, W_output_new, W_hidden_new)
print("h:", h)
print("y_m:", y_m)
print("grad_y_m:", grad_y_m)
print("grad_W_output:", grad_W_output)
print("grad_h:", grad_h)
print("grad_W_hidden:", grad_W_hidden)
print("W_output_new:", W_output_new)
print("W_hidden_new:", W_hidden_new)
2.4 基于深度学习框架的快速运算
PaddlePaddle
import paddle
from paddle import nn
from paddle.optimizer import SGD
# 定义模型
class SimpleNN(paddle.nn.Layer):
def __init__(self):
super(SimpleNN, self).__init__()
self.hidden_layer = nn.Linear(2, 4, bias_attr=False)
self.output_layer = nn.Linear(4, 2, bias_attr=False)
self.activation = nn.ReLU()
def forward(self, x):
x = self.hidden_layer(x)
x = self.activation(x)
x = self.output_layer(x)
return x
# 实例化模型
model = SimpleNN()
# 设置参数(权重)
model.hidden_layer.weight.set_value(paddle.to_tensor([[1, 2], [2, 3], [1, 1], [3, 1]], stop_gradient=False))
model.output_layer.weight.set_value(paddle.to_tensor([[1, 1, 1, 1], [1, 0, 0, 1]], stop_gradient=False))
# 生成随机数据集
num_samples = 100 # 数据集大小
x_dataset = paddle.randn([num_samples, 2]) # 随机生成输入
y_dataset = paddle.sum(x_dataset, axis=1, keepdim=True) # 生成标签(这里简单地使用输入的两列之和)
# 设置优化器和损失函数
optimizer = SGD(learning_rate=0.01, parameters=model.parameters())
criterion = nn.MSELoss()
# 训练模型
num_epochs = 10 # 训练轮数
for epoch in range(num_epochs):
for i in range(num_samples):
# 获取单个样本
x = paddle.unsqueeze(x_dataset[i], axis=0) # 增加一个批次维度
y = paddle.unsqueeze(y_dataset[i], axis=0)
# 前向传播
outputs = model(x)
# 计算损失
loss = criterion(outputs, y)
# 反向传播和参数更新
loss.backward() # 反向传播,计算当前梯度
optimizer.step() # 根据梯度更新参数
model.clear_gradients() # 清空过往梯度
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {loss.numpy()}')
# 输出更新后的参数与原版本参数
print("Updated Parameters:")
print("Hidden Layer Weights:", model.hidden_layer.weight.numpy())
print("Output Layer Weights:", model.output_layer.weight.numpy())
Pytorch
import torch
import torch.nn as nn
import torch.optim as optim
# 定义模型
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.hidden_layer = nn.Linear(2, 4, bias=False)
self.output_layer = nn.Linear(4, 2, bias=False)
self.activation = nn.ReLU()
def forward(self, x):
x = self.hidden_layer(x)
x = self.activation(x)
x = self.output_layer(x)
return x
# 实例化模型
model = SimpleNN()
# 设置参数(权重)
model.hidden_layer.weight.data = torch.tensor([[1, 2], [2, 3], [1, 1], [3, 1]], dtype=torch.float,requires_grad=True)
model.output_layer.weight.data = torch.tensor([[1, 1, 1, 1], [1, 0, 0, 1]],dtype=torch.float, requires_grad=True)
# 生成随机数据集
num_samples = 100 # 数据集大小
x_dataset = torch.randn(num_samples, 2) # 随机生成输入
y_dataset = x_dataset.sum(dim=1, keepdim=True) # 生成标签(这里简单地使用输入的两列之和)
# 设置优化器和损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.MSELoss()
# 训练模型
num_epochs = 10 # 训练轮数
for epoch in range(num_epochs):
for i in range(num_samples):
# 获取单个样本
x = x_dataset[i].unsqueeze(0) # 增加一个批次维度
y = y_dataset[i].unsqueeze(0)
# 前向传播
outputs = model(x)
# 计算损失
loss = criterion(outputs, y)
# 反向传播和参数更新
optimizer.zero_grad() # 清空过往梯度
loss.backward() # 反向传播,计算当前梯度
optimizer.step() # 根据梯度更新参数
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {loss.item()}')
# 输出更新后的参数与原版本参数
print("Updated Parameters:")
print("Hidden Layer Weights:", model.hidden_layer.weight.data)
print("Output Layer Weights:", model.output_layer.weight.data)

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 26
26 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)