
学习法Stacking-----机器学习
学习法前面的博文中我们介绍了Boosting和Bagging两种集成学习方法,这篇博文中我们继续学习其他的集成学习方法。当训练数据很多的时候,一种更为强大的结合策略是使用“学习法”,即通过另外一个学习器来进行结合。Stacking是学习的典型代表。在学习法中将个体学习器称为初级学习器,用于结合的学习器称为次级学习器或者元学习器。Stacking先从初始数据集中训练处初级学习器,然后“生成”...
学习法
前面的博文中我们介绍了Boosting和Bagging两种集成学习方法,这篇博文中我们继续学习其他的集成学习方法。当训练数据很多的时候,一种更为强大的结合策略是使用“学习法”,即通过另外一个学习器来进行结合。Stacking是学习的典型代表。在学习法中将个体学习器称为初级学习器,用于结合的学习器称为次级学习器或者元学习器。
Stacking先从初始数据集中训练处初级学习器,然后“生成”一个新的数据集用于训练次级学习器。在这个新的数据集中,初级学习器的输出被当做样例输入特征,而初始样本的标记仍被当做样例标记。
在训练阶段,次级训练集是利用初级学习器产生的,也就是说初级学习器和次级学习器的训练集不是一样,否则很容易过拟合。因此,一般通过使用交叉验证法或者留一法这样的方式,用训练初级学习器未使用的样本来产生次级学习器的训练样本。
如以k折交叉验证为例,我们将初始训练集随机划分为k个大小相似的集合:
。令
为第j折测试集,
为第j折训练集。
首先训练初级学习器,假设我们要训练T个初级学习器,那这T个初级学习器的训练集是什么呢?

如上图所示,引入,表示在
上使用t个学习器的算法所得到的的初级学习器。如此一来对于
中每个样本
在输入到
中产生的次级训练样例都有T个,记为:
![]()
其中:
![]()
其对应的标记仍然为,所以在整个交叉验证完成之后,从这T个初级学习器产生的次级训练集为:
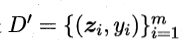
可能这里会有点难理解,多解读几遍,也能啃下来。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)