
大数据最全【Hive】(十六)Hive 执行过程实例分析_hive执行结果选择(2)
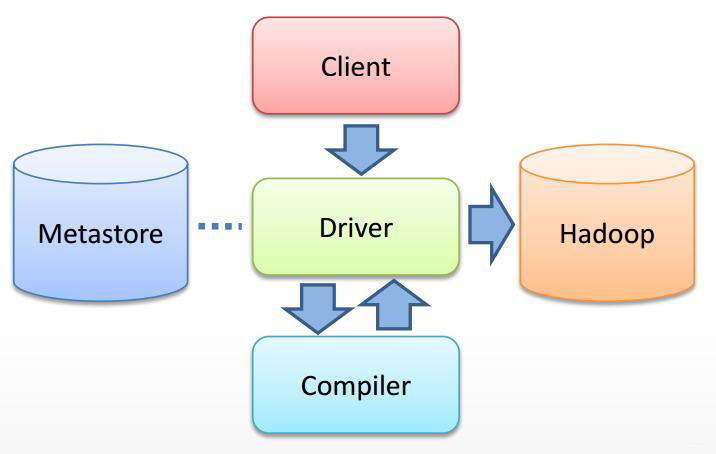
(1) Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator,JoinOperator 等(2)操作符 Operator 是 Hive 的最小处理单元(3)每个操作符代表一个 HDFS 操作或者 MapReduce 作业(4)Hive 通过 ExecMapper 和 ExecReducer 执行 MapReduce 程序,执行模式有本地模式和分布式两种。
文章目录
一、Hive 执行过程概述
1、概述
(1) Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator,JoinOperator 等
(2)操作符 Operator 是 Hive 的最小处理单元
(3)每个操作符代表一个 HDFS 操作或者 MapReduce 作业
(4)Hive 通过 ExecMapper 和 ExecReducer 执行 MapReduce 程序,执行模式有本地模式和分布式两种
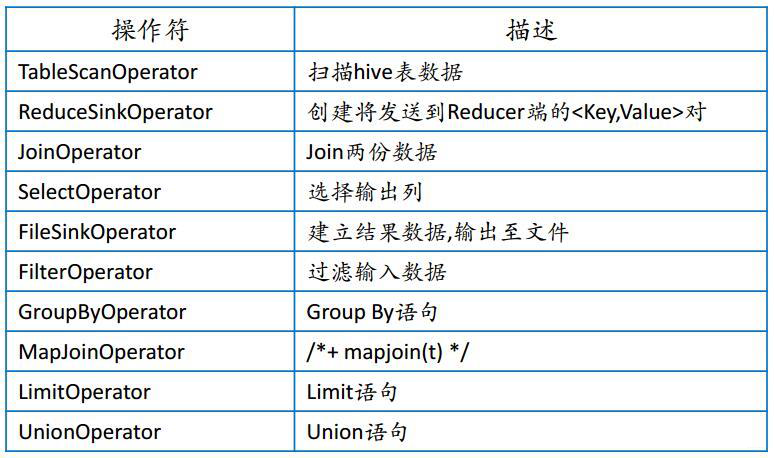
2、Hive 操作符列表
3、Hive 编译器的工作职责
(1)Parser:将 HQL 语句转换成抽象语法树(AST:Abstract Syntax Tree)
(2)Semantic Analyzer:将抽象语法树转换成查询块
(3)Logic Plan Generator:将查询块转换成逻辑查询计划
(4)Logic Optimizer:重写逻辑查询计划,优化逻辑执行计划
(5)Physical Plan Gernerator:将逻辑计划转化成物理计划(MapReduce Jobs)
(6)Physical Optimizer:选择最佳的 Join 策略,优化物理执行计划
4、优化器类型
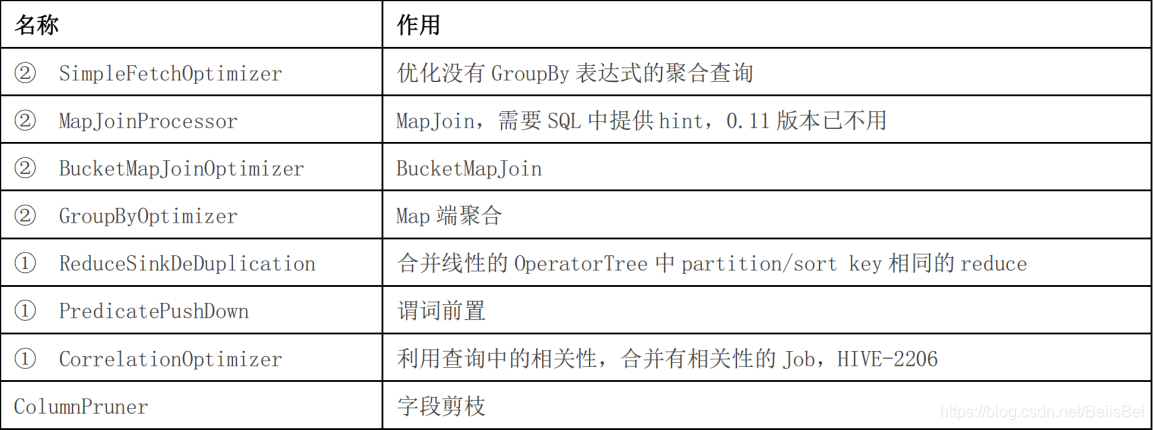
- 上表中 ① 的优化目的都是尽量将任务合并到一个 Job 中,以减少 Job 数量
- ② 的优化目的是尽量减少 shuffle 数据量。
二、JOIN
1、对于 JOIN 操作
SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON pv.userid = u.userid;
2、实现过程
Map:
1、以 JOIN ON 条件中的列作为 Key,如果有多个列,则 Key 是这些列的组合
2、以 JOIN 之后所关心的列作为 Value,当有多个列时,Value 是这些列的组合。在 Value 中还会包含表的 Tag 信息,用于标明此 Value 对应于哪个表
3、按照 Key 进行排序

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)