
PPocr-openvino实现(C++)
试用期间的任务入职面试是深度学习相关,结果进来后再也没碰过深度学习。。。被安排到传统图像和一些传统算法了。。还是血汗企业,要求无薪(试用期补贴都没有)加班的,周末还要随时联系但工资就一点点。。。和组长沟通还非常困难,不知道是他语言逻辑有问题还是我有问题。。。。坚持不下去了,最近就一直在准备跑路and整理文档,浅浅记录一下我做的项目吧。用到的东西就不做说明了,直接叙述流程。
前言
试用期间的任务
入职面试是深度学习相关,结果进来后再也没碰过深度学习。。。被安排到传统图像和一些传统算法了。。还是血汗企业,要求无薪(试用期补贴都没有)加班的,周末还要随时联系但工资就一点点。。。和组长沟通还非常困难,不知道是他语言逻辑有问题还是我有问题。。。。坚持不下去了,最近就一直在准备跑路and整理文档,浅浅记录一下我做的项目吧。用到的东西就不做说明了,直接叙述流程。
环境准备
官网下载:下载连接
本人下载的2022.3的版本

同时下载opencl,我用的是2023.2版本。
这里放一个压缩包,两个软件都有:下载连接
将openvino压缩包压缩到指定位置,我一开始用的2023结果发现不会用(哈哈),然后下了2022版本的,原来的2023是exe,默认在C盘,为了方便后面就也放在C盘了。
路径如图:
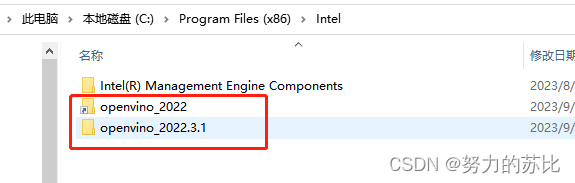
解压后再创建一个快捷文件夹,方便使用。
然后是添加path:
C:\Program Files (x86)\Intel\openvino_2022.3.1\runtime\3rdparty\tbb\bin
C:\Program Files (x86)\Intel\openvino_2022.3.1\runtime\3rdparty\tbb\bin\intel64\vc14
C:\Program Files (x86)\Intel\openvino_2022.3.1\runtime\3rdparty\tbb\redist\intel64\vc14
C:\Program Files (x86)\Intel\openvino_2022.3.1\runtime\bin\intel64\Release
C:\Program Files (x86)\Intel\openvino_2022.3.1\runtime\bin\intel64\Debug
C:\Program Files (x86)\Intel\openvino_2022.3.1\runtime\3rdparty\hddl\bin
C:\Program Files (x86)\Intel\openvino_2022.3.1\tools\compile_tool添加到系统环境变量当中,可以用快捷文件夹(2023版本的名字就很复杂,用快捷文件夹会好很多)
然后安装opencl(已经安装过就不放图了)
注意!!!还有记得有opencv!!!环境也是!
然后是VS里的:
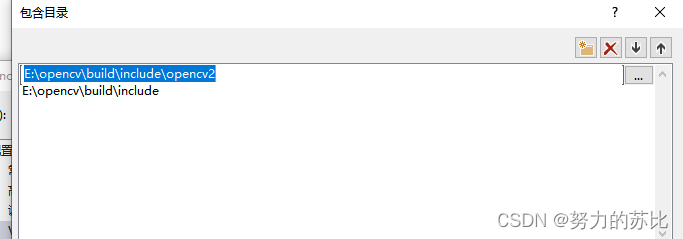
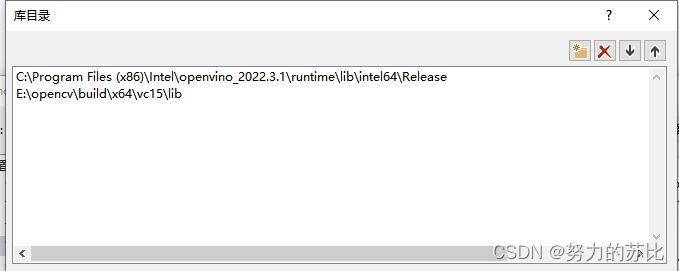
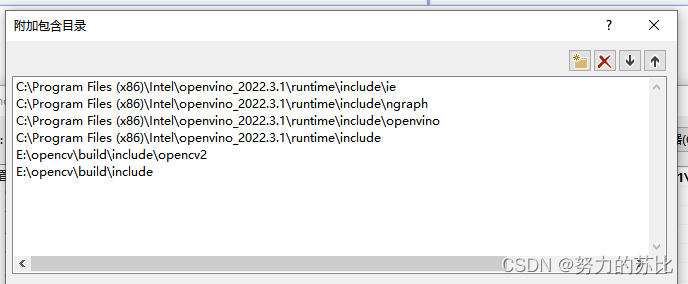
环境就装好了。
代码
用C++ 写的,安排的任务是写一份C++代码,生成dll,在C#里完成ppocr文字识别的效果。
这里就直接贴一下C++代码,
注意!!!参考了这篇文章,做了一下改动。
因为是生成dll,所以图片是在C#转换成byte数组传入C++,模型是路径传到C++再读取。
OpenvinoOcr.cpp
#include <iostream>
#include <time.h>
#include "opencv2/opencv.hpp"
#include <opencv2/core/core.hpp>
#include "OpenvinoOcr.h"
#include <inference_engine.hpp>
#include <exception>
//#include <CL/cl.hpp>
//#include <CL/opencl.h>
using namespace std;
//全局变量
InferenceEngine::ExecutableNetwork* Ptr[5];
InferenceEngine::Core core;
InferenceEngine::ExecutableNetwork executable_network;
unordered_map<int, InferenceEngine::ExecutableNetwork>Models; //字典
//unordered_map<int, InferenceEngine::ExecutableNetwork>::iterator ModelsIter;
//向字典里存放模型变量,num用来控制存放模型的数量
DLLEXPORT bool Modelinsert(int num, InferenceEngine::ExecutableNetwork executable_network) {
for (int i = 0; i <= num; i++) {
Models.insert(pair<int, InferenceEngine::ExecutableNetwork>(i, executable_network));
}
return true;
}
//根据键值 找到对应的模型变量
DLLEXPORT InferenceEngine::ExecutableNetwork Find_model(int num)
{
InferenceEngine::ExecutableNetwork executable_network;
executable_network = Models.find(num)->second;
return executable_network;
}
//模型初始化判断
DLLEXPORT bool InnitPtr(int num) {
if (Ptr[0] == NULL)
{
for (int i = 0; i <= num; i++) {
Ptr[i] = new InferenceEngine::ExecutableNetwork();
}
}
return true;
}
//读取路径,将模型输入到模型变量中
DLLEXPORT bool Create_model(int num, char* xmlPathc) {
try {
if (Models.empty() || num > Models.size()) {
string xmlPath(xmlPathc);
InferenceEngine::CNNNetwork network = core.ReadNetwork(xmlPath);
executable_network = core.LoadNetwork(network, "GPU");
for (int i = 0; i <= num; i++) {
Models.insert(pair<int, InferenceEngine::ExecutableNetwork>(i, executable_network));
}
}
return true;
}
catch (exception e) {
int i = 0;
}
}
//清空模型
DLLEXPORT void DeleteModel()
{
Models.clear();
core.UnregisterPlugin("GPU");
}
//查找模型
DLLEXPORT bool FindModel(int num, char* xmlPathc) {
InnitPtr(num);
Create_model(num, xmlPathc);
return true;
}
//归一化
void normalizeImage(const cv::Mat& image, cv::Mat& out, std::vector<double>mean, std::vector<double>stdv)
{
if (image.empty())
throw "normalizeImage input image is empty()!";
if (mean.size() != stdv.size())
throw "normalizeImage mean.size() != stdv.size()!";
if (mean.size() != image.channels())
throw "normalizeImage mean.size() != image.channels()";
for (double stdv_item : stdv)
{
//if standard deviation is zero, the image's all pixels are same
if (stdv_item == 0)
throw "normalizeImage stdv is zero";
}
image.convertTo(out, CV_32F, 1.0 / 256.0f, 0);
if (out.channels() == 1)
{
out -= mean[0];
out /= stdv[0];
}
else if (out.channels() > 1)
{
std::vector<cv::Mat> channelImage;
cv::split(out, channelImage);
for (int i = 0; i < out.channels(); i++)
{
channelImage[i] -= mean[i];
channelImage[i] /= stdv[i];
}
cv::merge(channelImage, out);
}
return;
}
//padding
void paddingImage(const cv::Mat& image, cv::Mat& out,
int top, int left, int bottom, int right,
int bodeyType, const cv::Scalar& value)
{
if (image.empty())
throw "padding input image is empty()!";
cv::copyMakeBorder(image, out, top, bottom, left, right, bodeyType, value);
return;
}
//预处理
void paddleOCRPreprocess(const cv::Mat& image, cv::Mat& out, const int targetHeight, const int targetWidth,
std::vector<double>mean, std::vector<double>stdv)
{
int sourceWidth = image.cols;
int sourceHeight = image.rows;
double sourceWHRatio = (double)sourceWidth / sourceHeight;
int newHeight = targetHeight;
int newWidth = newHeight * sourceWHRatio;
if (newWidth > targetWidth)
newWidth = targetWidth;
cv::resize(image, out, cv::Size(newWidth, newHeight));
normalizeImage(out, out, mean, stdv);
//Padding image
//the resized image's height is always equal to targetHeight,but width will not
if (newWidth < targetWidth)
{
int right = targetWidth - newWidth;
//paddingImage(out, out, 0, 0, 0, right, cv::BORDER_REPLICATE);// 按最后一行填充
paddingImage(out, out, 0, 0, 0, right, cv::BORDER_CONSTANT, cv::Scalar(0, 0, 0));//0 填充
}
//showImage(out, "padding",1,0);
}
//后处理 识别
void paddleOCRPostProcess(cv::Mat& output, std::string& result, float& prob)
{
std::string dict = "0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~!\"#$%&'()*+,-./ ";
if (output.empty())
return;
result = "";
int h = output.rows;
int w = output.cols;
std::vector<int> maxIndex;
std::vector<float>maxProb;
double maxVal;
cv::Point maxLoc;
for (int row = 0; row < h; row++)
{
cv::Mat temp(1, w, CV_32FC1, output.ptr<float>(row));
cv::minMaxLoc(temp, NULL, &maxVal, NULL, &maxLoc);
maxIndex.push_back(maxLoc.x);
maxProb.push_back((float)maxVal);
}
std::vector<int>selectedIndex;
std::vector<float>selectedProb;
//在maxIndex中找出与前一个的index不一样且不为0的位置,
//先判断第一个元素
if (maxIndex.size() != 0 && maxIndex[0] != 0)
{
selectedIndex.push_back(maxIndex[0]);
selectedProb.push_back(maxProb[0]);
}
for (int i = 1; i < maxIndex.size(); i++)
{
if (maxIndex[i] != maxIndex[i - 1] && maxIndex[i] != 0)
{
selectedIndex.push_back(maxIndex[i]);
selectedProb.push_back(maxProb[i]);
}
}
double meanProb = 0;
for (int i = 0; i < selectedIndex.size(); i++)
{
result += dict[selectedIndex[i] - 1];
meanProb += selectedProb[i];
}
if (selectedIndex.size() == 0)
meanProb = 0;
else
meanProb /= selectedIndex.size();
prob = meanProb;
return;
}
char* string2char(string s) {
char* c;
const int len = s.length();
c = new char[len + 1];
strcpy(c, s.c_str());
return c;
}
DLLEXPORT char* OpenvinoPpocr(unsigned char* ucImg, int width, int height, double* similarity, int num)
{
string result = "";
cv::Mat image = cv::Mat(height, width, CV_8UC3, ucImg, 0);
string inputNodeName = "x", outputNodeName = "softmax_2.tmp_0";
vector<double>mean = { 0.5,0.5,0.5 };
vector<double>stdv = { 0.5,0.5,0.5 };
const int targetHeight = 48;
const int targetWidth = 320;
Ptr[num] = &(Models.find(num)->second);
InferenceEngine::InferRequest inferRequest = Ptr[num]->CreateInferRequest();
inferRequest.Infer();
InferenceEngine::Blob::Ptr inputBlobPtr = inferRequest.GetBlob(inputNodeName);
InferenceEngine::SizeVector inputSize = inputBlobPtr->getTensorDesc().getDims();
auto inputdata = inputBlobPtr->buffer()
.as<InferenceEngine::PrecisionTrait<InferenceEngine::Precision::FP32>::value_type*>();
InferenceEngine::Blob::Ptr outputBlobPtr = inferRequest.GetBlob(outputNodeName);
auto outputData = outputBlobPtr->buffer().
as<InferenceEngine::PrecisionTrait<InferenceEngine::Precision::FP32>::value_type*>();
InferenceEngine::SizeVector outputSize = outputBlobPtr->getTensorDesc().getDims();
cv::Mat input, output;
size_t channels = inputSize[1];
size_t inputHeight = inputSize[2];
size_t inputWidth = inputSize[3];
rsize_t imageSize = inputHeight * inputWidth;
paddleOCRPreprocess(image, input, targetHeight, targetWidth, mean, stdv);
for (size_t pid = 0; pid < imageSize; ++pid)
{
for (size_t ch = 0; ch < channels; ++ch)
{
inputdata[imageSize * ch + pid] = input.at<cv::Vec3f>(pid)[ch];
}
}
inferRequest.Infer();
cv::Mat temp(outputSize[1], outputSize[2], CV_32FC1, outputData);
output = temp;
float prob;
paddleOCRPostProcess(output, result, prob);
* similarity = (double)prob;
char* resultc = string2char(result);
return resultc;
}
.h文件,如果要添加活修改接口记得cpp和h的函数要一致就行。
#pragma once
#ifndef _PADDLEOCR_H_
#define _PADDLEOCR_H_
#include "opencv.hpp"
#include "inference_engine.hpp"
#define DLLEXPORT extern "C" __declspec(dllexport)
using namespace std;
void normalizeImage(const cv::Mat& image, cv::Mat& out, std::vector<double>mean, std::vector<double>stdv);
void paddingImage(const cv::Mat& image, cv::Mat& out,
int top, int left, int bottom, int right,
int bodeyType, const cv::Scalar& value = cv::Scalar());
void paddleOCRPreprocess(const cv::Mat& image, cv::Mat& out, const int targetHeight, const int targetWidth,
std::vector<double>mean, std::vector<double>stdv);
void paddleOCRPostProcess(cv::Mat& output, std::string& result, float& prob);
char* string2char(string s);
//DLLEXPORT void demo(char* xmlPathc, char* binPathc, unsigned char* ucImg, int width, int height, char* resultc);
DLLEXPORT char* OpenvinoPpocr(unsigned char* ucImg, int width, int height, double* similarity, int num);
DLLEXPORT bool Create_model(int num, char* xmlPathc);
DLLEXPORT void DeleteModel();
DLLEXPORT bool InnitPtr(int num);
DLLEXPORT bool FindModel(int num, char* xmlPathc);
#endif // !_PADDLEOCR_H_
#pragma once
#pragma once
#pragma once
模型
模型现在可以用onnx的也没问题了好像,但我拿到手的是ir模型,网上搜了一下转换的方式,可能需要用到python的openvino包,具体可以在csdn里查阅,不难喔,然后因为还是深度学习算法,模型都比较有针对性,这里就不放我们的了,有参考的代码也有修改后的,各位好好使用吧。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)