
【深度学习的数学】交叉熵公式如何推导?
使用最小二乘法的二次代价函数作为损失函数由于存在计算收敛时间长的情况,人们引入了交叉熵函数,利用交叉熵和sigmoid函数,可以消除sigmoid函数的冗长性,提高梯度下降法的计算速度,那么,交叉熵函数是如何推导出来的呢?...
使用最小二乘法的二次代价函数作为损失函数由于存在计算收敛时间长的情况,人们引入了交叉熵函数,利用交叉熵和sigmoid函数,可以消除sigmoid函数的冗长性,提高梯度下降法的计算速度,那么,交叉熵函数是如何推导出来的呢?
20210819
均方误差函数在x=0附近不陡,交叉熵损失函数在x=0和x=1都有一定陡度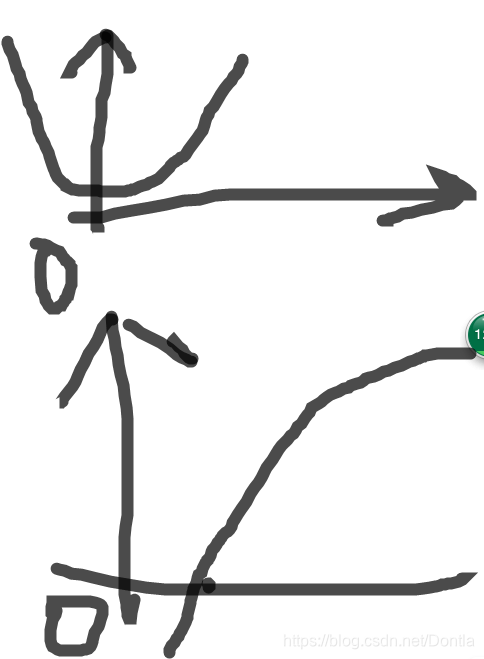
- 学习过程
交叉熵损失函数经常用于分类问题中,特别是在神经网络做分类问题时,也经常使用交叉熵作为损失函数,此外,由于交叉熵涉及到计算每个类别的概率,所以交叉熵几乎每次都和sigmoid(或softmax)函数一起出现。
我们用神经网络最后一层输出的情况,来看一眼整个模型预测、获得损失和学习的流程:
神经网络最后一层得到每个类别的得分scores(也叫logits);
该得分经过sigmoid(或softmax)函数获得概率输出;
模型预测的类别概率输出与真实类别的one hot形式进行交叉熵损失函数的计算。
- 计算求导
使用交叉熵损失函数,不仅可以很好的衡量模型的效果,又可以很容易的的进行求导计算。
- 优点
在用梯度下降法做参数更新的时候,模型学习的速度取决于两个值:一、学习率;二、偏导值。其中,学习率是我们需要设置的超参数,所以我们重点关注偏导值。从上面的式子中,我们发现,偏导值的大小取决于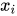
和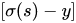
,我们重点关注后者,后者的大小值反映了我们模型的错误程度,该值越大,说明模型效果越差,但是该值越大同时也会使得偏导值越大,从而模型学习速度更快。所以,使用逻辑函数得到概率,并结合交叉熵当损失函数时,在模型效果差的时候学习速度比较快,在模型效果好的时候学习速度变慢。
- 缺点
Deng [4]在2019年提出了ArcFace Loss,并在论文里说了Softmax Loss的两个缺点:1、随着分类数目的增大,分类层的线性变化矩阵参数也随着增大;2、对于封闭集分类问题,学习到的特征是可分离的,但对于开放集人脸识别问题,所学特征却没有足够的区分性。对于人脸识别问题,首先人脸数目(对应分类数目)是很多的,而且会不断有新的人脸进来,不是一个封闭集分类问题。
另外,sigmoid(softmax)+cross-entropy loss 擅长于学习类间的信息,因为它采用了类间竞争机制,它只关心对于正确标签预测概率的准确性,忽略了其他非正确标签的差异,导致学习到的特征比较散。基于这个问题的优化有很多,比如对softmax进行改进,如L-Softmax、SM-Softmax、AM-Softmax等。
ps. 你得辩证的看,说不定作者写的有疏漏哦。。。。。(Dontla)

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 0
0 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)