
深度学习:胶囊网络capsule net
这里计算有点不同,pytorch代码的实现里只有这个双线性变换参数大小,没有“还需要1152个b参数矩阵和1152个c参数矩阵”。上述函数可以直接通过probs = torch.softmax(logits, dim=2)替换,效果是一样的。torch.softmax归一化]2 priors的计算也可以替代。两部分损失函数加权和。
第一部分:编码器
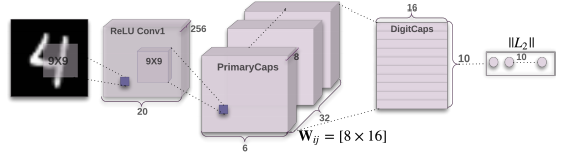
网络参数计算
for name, param in model.named_parameters():
print("# {}:{}".format(name, param.numel()))
第一层:卷积层
20992 # conv1.weight:20736 # conv1.bias:256
第二层:主胶囊层
5308672(# primary_capsules.capsules.0.weight:663552,# primary_capsules.capsules.0.bias:32)*8
第三层:数字胶囊层
# digit_capsules.route_weights:1474560
这里计算有点不同,pytorch代码的实现里只有这个双线性变换参数大小,没有“还需要1152个b参数矩阵和1152个c参数矩阵”。
第二部分:解码器
# decoder.0.weight:81920
# decoder.0.bias:512
# decoder.2.weight:524288
# decoder.2.bias:1024
# decoder.4.weight:802816
# decoder.4.bias:784
损失函数Loss
两部分损失函数加权和。
(margin_loss + 0.0005 * reconstruction_loss) / images.size(0)
[初探胶囊网络(Capsule Network)四:胶囊网络结构]
Code实现
1 def softmax(input, dim=1):
transposed_input = input.transpose(dim, len(input.size()) - 1)
softmaxed_output = F.softmax(transposed_input.contiguous().view(-1, transposed_input.size(-1)), dim=-1)
return softmaxed_output.view(*transposed_input.size()).transpose(dim, len(input.size()) - 1)
probs = softmax(logits, dim=2)
上述函数可以直接通过probs = torch.softmax(logits, dim=2)替换,效果是一样的。
2 priors的计算也可以替代。
priors = torch.matmul(x.unsqueeze(0).unsqueeze(3), self.route_weights.unsqueeze(1))
priors = x[None, :, :, None, :] @ self.route_weights[:, None, :, :, :]
[PyTorch:tensor-数学API torch.softmax归一化]
from:-柚子皮-

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)