
【OPEN 1+X】零基础向使用Ollama+RAGFlow构建自己本地的AI知识库
简单来说,原本的大模型在考试的时候只能依赖已经学习过的内容进行回答,RAG则相当于让大模型可以开卷作答,即使没有学习过的内容,也可以通过翻书解决。docker相当于一个开箱即用的环境,由项目开发者配置完成后,分发镜像给用户使用,无需关心其具体的运行环境配置,也不会影响计算机自身的环境。最近遇到很多人都对于本地知识库搭建的流程非常有兴趣,故做一个教程,也完成一下Datawhale的视频共建任务,文章
序言
最近遇到很多人都对于本地知识库搭建的流程非常有兴趣,故做一个教程,也完成一下Datawhale的视频共建任务,文章前半内容无需编写代码即可完成使用,后半部分会介绍一下如何在应用中与ai进行对话
由于是0基础向,一部分基础向的内容会更偏向于windows上的操作方法,当然,你需要有一台安装了显卡的计算机用来完成这个教程
RAG
为了使用本地知识库,我们需要使用到一个叫做RAG的技术
简单介绍一下RAG(检索增强生成(Retrieval-augmented Generation)),是一种可以不微调模型(这是一种需要花费较多资源完成的事情),就可以增强大模型回答问题准确性的一种方法。
简单来说,原本的大模型在考试的时候只能依赖已经学习过的内容进行回答,RAG则相当于让大模型可以开卷作答,即使没有学习过的内容,也可以通过翻书解决。当然大模型本身没有直接翻书的能力,我们需要给他一个工具,让他能快速的找到相关内容在哪里。这个工具就是我们的矢量数据库,将从数据库搜索到的数据嵌入到提示词后与问题一起发送给大模型,这时候他就能根据提示词中的信息,更准确地回答问题。
本地模型部署
首先我们需要部署本地的大语言模型,当然,如果你想采用在线模型的api。可以跳过这一步骤.NET程序中调用本地部署Deepseek模型进行对话_net deepseek-CSDN博客![]() https://blog.csdn.net/scixing/article/details/145498523?spm=1001.2014.3001.5501条件允许的话,请尽量选择7b及以上的模型
https://blog.csdn.net/scixing/article/details/145498523?spm=1001.2014.3001.5501条件允许的话,请尽量选择7b及以上的模型
不过我们这里还需要一个新的步骤,这是我们接下来要用到的妙妙工具下载Embedding模型
ollama pull bge-m3RAGFlow
一个工具,简化了RAG应用的部署流程。
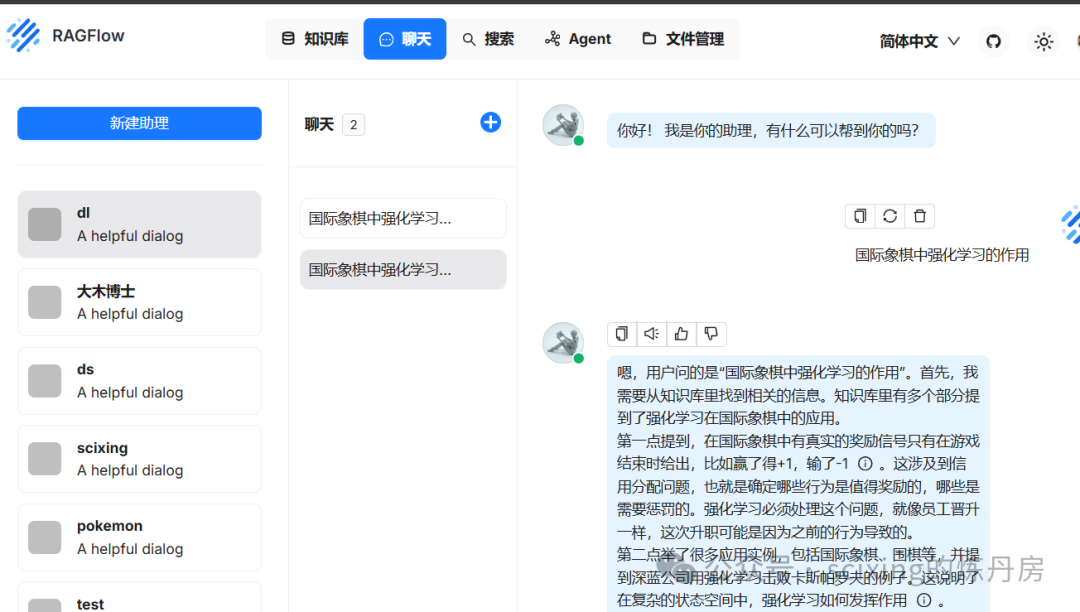
在使用RAGFlow之前,我们首先要下载其项目仓库,与下载docker
如果你还没有git的话,也请访问https://git-scm.com/downloads/win下载安装哦
docker相当于一个开箱即用的环境,由项目开发者配置完成后,分发镜像给用户使用,无需关心其具体的运行环境配置,也不会影响计算机自身的环境。https://www.docker.com/ 在此链接中下载安装对于系统的版本
然后我们需要克隆ragflow项目
在你希望下载该项目的文件夹中,打开powershell(在空白处右键,点击在终端打开
git clone https://github.com/infiniflow/ragflow
cd ragflow/docker/接下来拉取镜像, 如果你没有访问外网的工具,你可能需要配置docker的镜像源
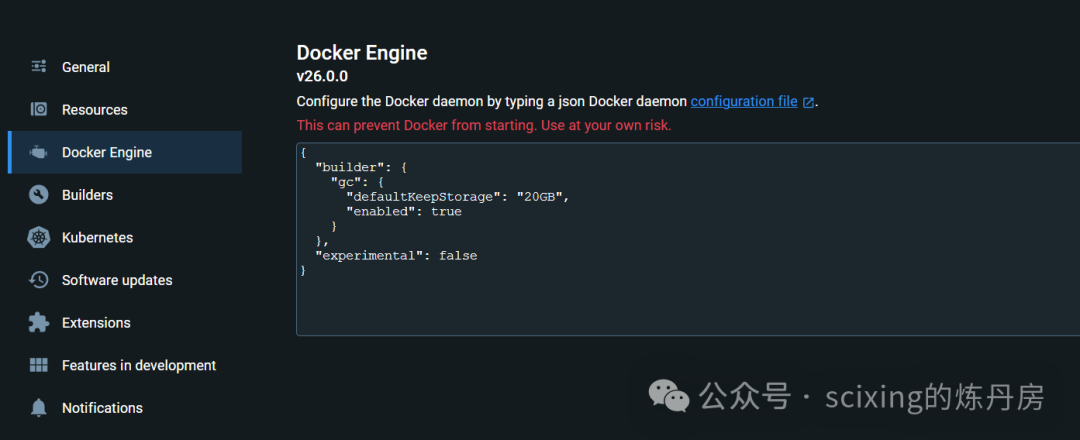
打开docker在设置中找到Docker Enging后,将配置改为
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"experimental": false,
"registry-mirrors": [
"https://docker-0.unsee.tech",
]
}(p.s. 镜像源也有可能会失效,若无法正常下载,请寻找访问外网的工具或者搜索新的镜像源)
docker compose -f docker-compose.yml up -d运行上述指令后,不出意外,你将会经历一段时间的等待,不过当你看到类似
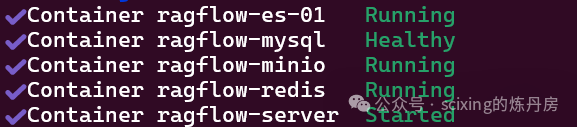
的输出时,恭喜你,你已经成功的部署了RAGFlow。
如果你是在wsl部署的,有时候可能会看到类似linux Error response from daemon: Ports are not available: exposing port的输出,不要担心,这时候在windows侧输入即可(需要管理员权限)
net stop winnat
net start winnat到此我们的准备工作已经完成了, 接下来只需鼠标点点配置使用即可。
配置RAGFLow
浏览器访问localhost
注册账号(这里是本地账号,随便注册都行 test@test.com都没有任何问题)
登陆后看到如下界面,先不用急着创建知识库,我们还需要配置我们的默认模型
点击右上角后选中Model providers(模型提供商)
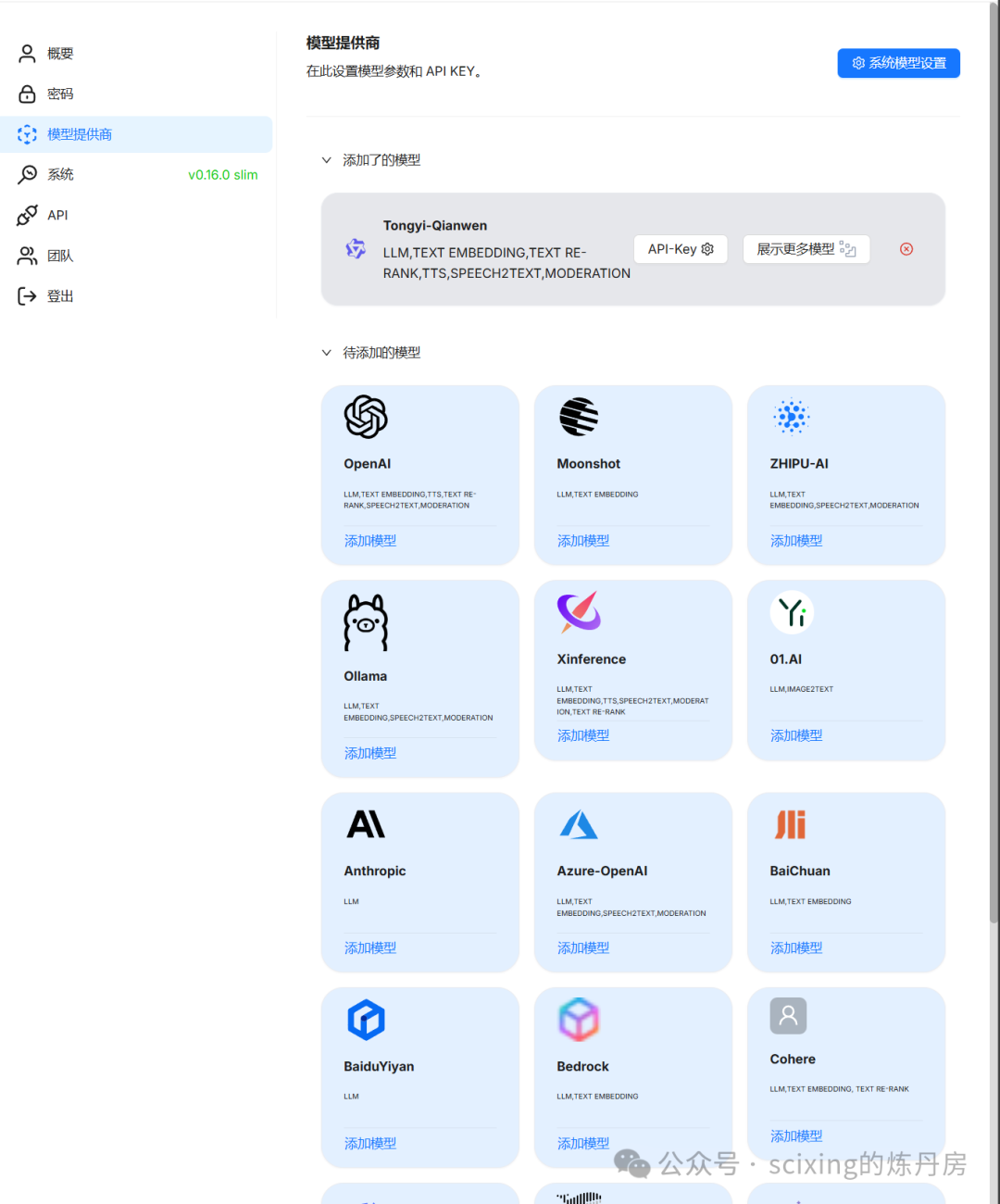
可以看到这里由非常多的模型可以选择,我们这里选择ollama, 分别添加两个模型
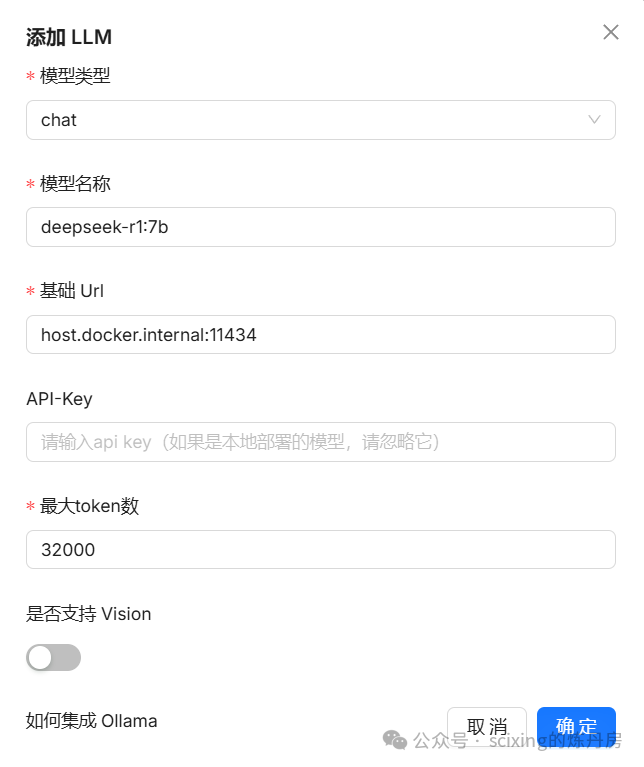
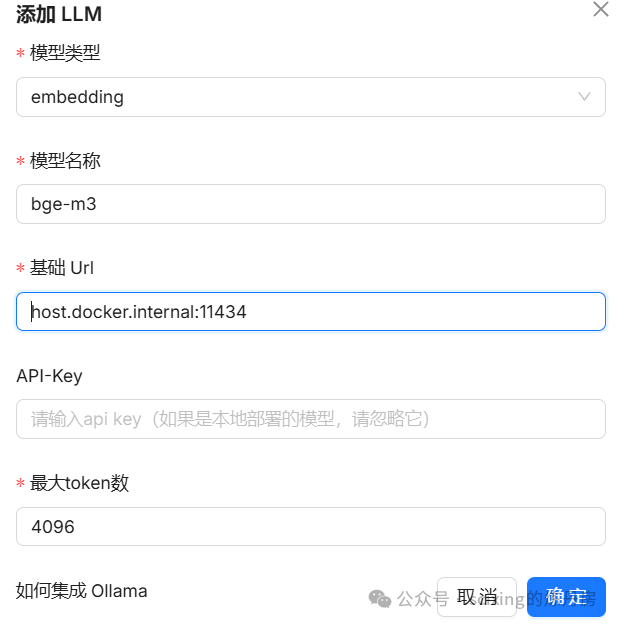
(token数我随便填的,看实际需求)
接下来配置默认模型
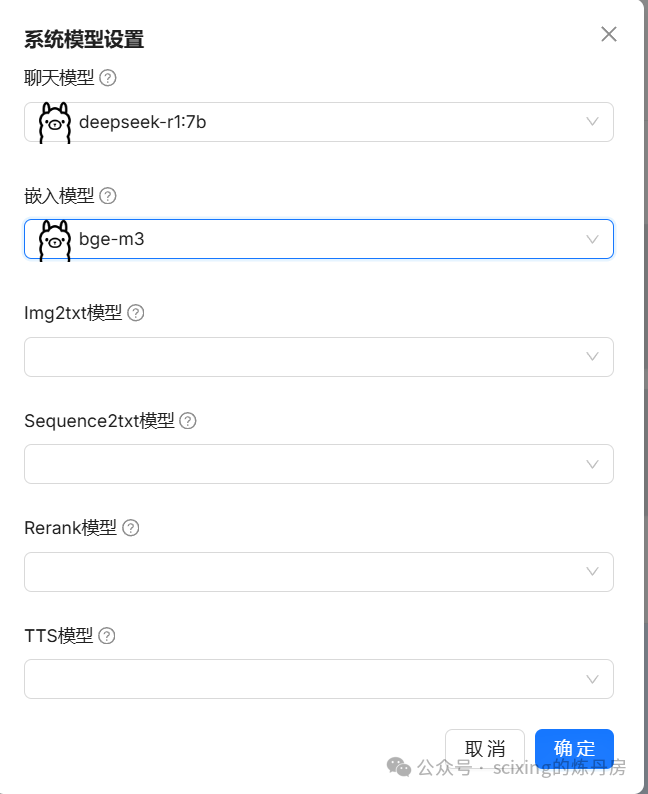
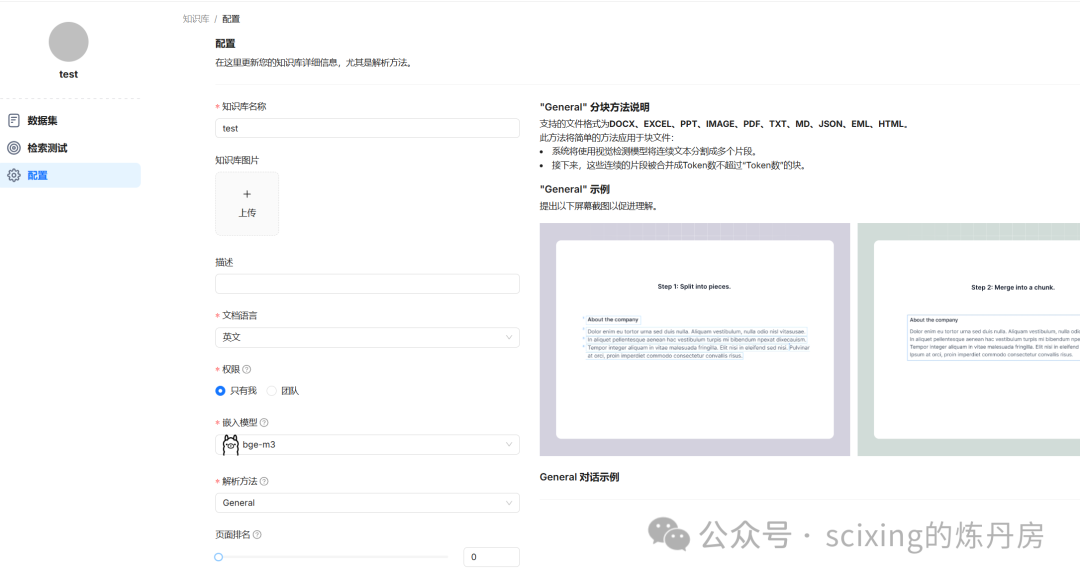
接下来就可以配置我们的知识库了!如果以上都配置完成,在添加知识库之后,你应该会看到类似界面。其他配置可以无需修改,语言按需设置,点击保存
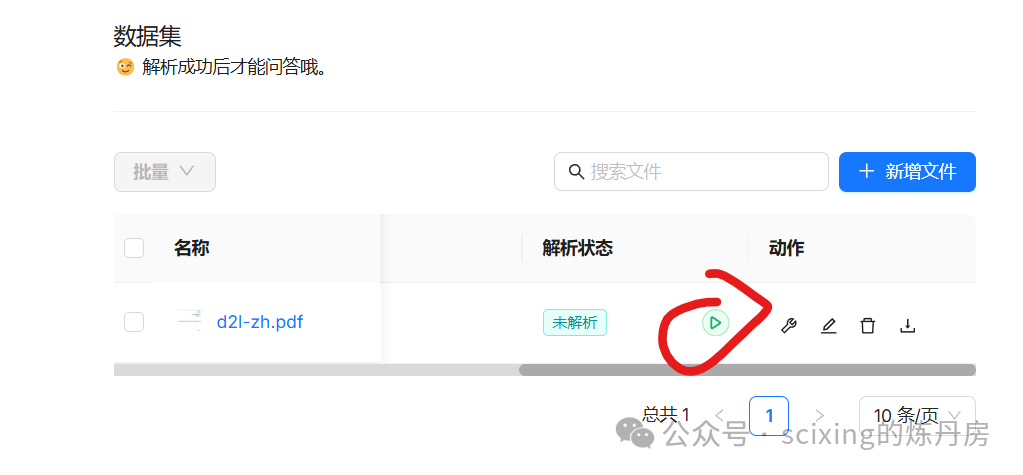
接下来就可以上传数据集了,上传后,点击绿箭头开始解析数据
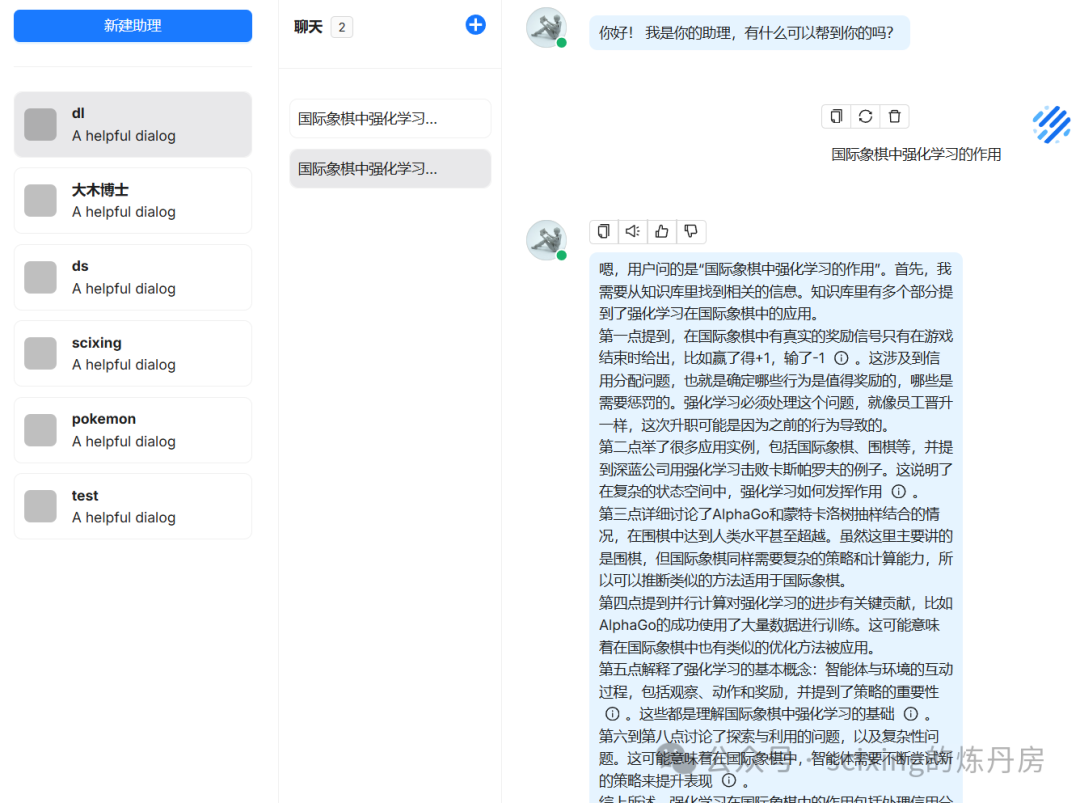
接下来就可以在聊天中配置使用了!完成。
在python中使用RAGFlow
首先我们要先在网站中生成apikey备用
新建一个虚拟环境后安装官方提供的python SDK(推荐使用Anaconda)
pip install ragflow-sdkfrom ragflow_sdk import RAGFlow
rag_object = RAGFlow(api_key="ragflow-xxx", base_url="http://localhost:80") # 创建一个RAGFlow对象
assistants = rag_object.list_chats(name="dlmaster") # 获取名为"dlmaster"的助手
assistant = assistants[0].get() # 获取第一个助手
session = assistant.create_session("test") # 创建一个会话
while True:
question = input("\n==================== User =====================\n> ")
print("\n==================== scixing =====================\n")
cont = ""
for ans in session.ask(question, stream=True): # 向助手发送问题
print(ans.content[len(cont):], end='', flush=True) # 打印助手的回答
cont = ans.content使用以上代码,便可以与RAGFlow的助手完成通讯!
当然python sdk本质也是基于HTTP API,我们也可以通过其他语言自己封装SDK。目前在进行这方面的工作,敬请期待RagFlow.NET (x)
微信公众号: @scixing的炼丹房
BiliBili: @无聊的年 【OPEN 1+X】零基础向使用Ollama+RAGFlow构建自己本地的AI知识库_哔哩哔哩_bilibili

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)