
机器学习基础——支持向量机1
间隔与支持向量给定训练样本集D={(x1,y1),(x2,y2)⋯ ,(xn,yn)},yi∈{−1,+1}D=\{(x_1,y_1),(x_2,y_2)\cdots, (x_n,y_n)\},y_i\in \{-1, +1\}D={(x1,y1),(x2,y2)⋯,(xn,yn)},yi∈{−1,+1},分类学习的最基本的思想就是基于样本空间中找个一个划分超平面,将不同类别的样本.
间隔与支持向量
给定训练样本集D={(x1,y1),(x2,y2)⋯ ,(xn,yn)},yi∈{−1,+1}D=\{(x_1,y_1),(x_2,y_2)\cdots, (x_n,y_n)\},y_i\in \{-1, +1\}D={(x1,y1),(x2,y2)⋯,(xn,yn)},yi∈{−1,+1},分类学习的最基本的思想就是基于样本空间中找个一个划分超平面,将不同类别的样本分开,但是超平面可能有很多种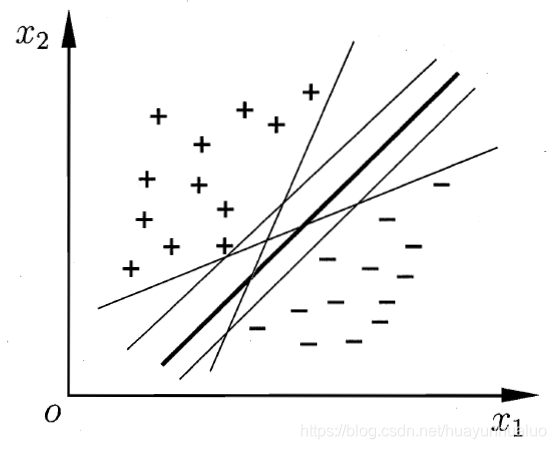
直观上应该找最中间的划分超平面,因为该超平面对训练样本局部的扰动的容忍最好的。由于训练集的局限性或噪声的因素,训练集外的样本可能更接近两个类的分隔界,这个划分超平面所产生的分类结果是最鲁棒的,对未见的示例泛化能力最强。
超平面的线性方程描述:
ωTx+b=0 {\rm\pmb{\omega}}^Tx + b = 0 ωωωTx+b=0
其中ω=(ω1;ω2;⋯ ;ωd)\pmb\omega=(\omega_1;\omega_2;\cdots;\omega_d)ωωω=(ω1;ω2;⋯;ωd)为法向量,决定超平面的方向,bbb为位移项,决定了超平面与原点之间的距离。
样本空间中任意点xxx到超平面(ω,b)(\omega,b)(ω,b)的距离可写成:
r=∣ωTx+b∣∣∣ω∣∣ r = \frac{|\rm \omega^Tx +b|}{||\omega||} r=∣∣ω∣∣∣ωTx+b∣
假设超平面(ω,b)(\omega ,b)(ω,b)能将训练样本正确分类,即对于(xi,yi)∈D(x_i,y_i)\in D(xi,yi)∈D,若yi=+1y_i=+1yi=+1,则有wTxi+b>0\pmb{w^Tx_i}+b>0wTxiwTxiwTxi+b>0,若yi=−1y_i=-1yi=−1,则有ωTxi+b<0\pmb{\omega^Tx_i}+b<0ωTxiωTxiωTxi+b<0
{ωTxi+b≥+1yi=+1ωTxi+b≤−1yi=−1 \begin{cases} \pmb{\omega^Tx_i}+b \ge +1 & y_i=+1\\ \pmb{\omega^Tx_i} + b \le -1 & y_i=-1 \end{cases} {ωTxiωTxiωTxi+b≥+1ωTxiωTxiωTxi+b≤−1yi=+1yi=−1
推导:
假设这个超平面是ω′Tx+b′=0\omega^{'T}x+b^{'}=0ω′Tx+b′=0,则对于(xi,yi)∈D(x_i,y_i)\in D(xi,yi)∈D,有:
{ω′Txi+b′>0yi=+1ω′Txi+b′<0yi=−1 \begin{cases} \omega^{'T}x_i+b^{'}> 0 & y_i=+1 \\ \omega^{'T}x_i+b^{'}< 0 & y_i=-1 \end{cases} {ω′Txi+b′>0ω′Txi+b′<0yi=+1yi=−1
根据几何间隔,将以上关系修正为
{ω′Txi+b′≥+ζyi=+1ω′Txi+b′≤−ζyi=−1 \begin{cases} \omega^{'T}x_i+b^{'}\ge +\zeta & y_i=+1 \\ \omega^{'T}x_i+b^{'}\le -\zeta & y_i=-1 \end{cases} {ω′Txi+b′≥+ζω′Txi+b′≤−ζyi=+1yi=−1
其中ζ\zetaζ为某个大于零的常数,两边同时除以ζ\zetaζ,再次修改以上关系
{1ζω′Txi+1ζb′≥+1yi=+11ζω′Txi+1ζb′≤−1yi=−1 \begin{cases} \frac{1}{\zeta}\omega^{'T}x_i+\frac{1}{\zeta}b^{'}\ge +1 & y_i=+1 \\ \frac{1}{\zeta}\omega^{'T}x_i+\frac{1}{\zeta}b^{'}\le -1 & y_i=-1 \end{cases} {ζ1ω′Txi+ζ1b′≥+1ζ1ω′Txi+ζ1b′≤−1yi=+1yi=−1
令ω=1ζω′,b=b′ζ\omega = \frac{1}{\zeta}\omega^{'},b=\frac{b^{'}}{\zeta}ω=ζ1ω′,b=ζb′,就可以得到公式。
距离超平面最近的这几个训练样本使等号成立,它们称之为支持向量(support vector),两个异类支持向量到超平面的距离之和为
γ=2∣∣ω∣∣ \gamma = \frac{2}{||\pmb{\omega}||} γ=∣∣ωωω∣∣2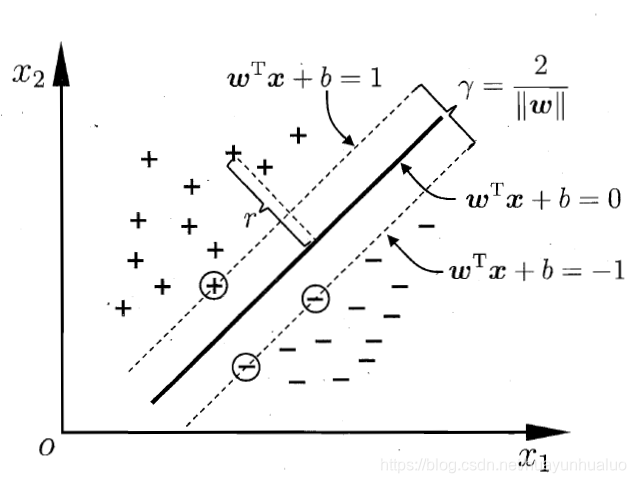
找到具有最大间隔的划分超平面,就要找到满足条件参数的ω\omegaω和bbb,使γ\gammaγ最大
maxw,b2∣∣w∣∣s.t. yi(wTxi+b)≥1,i=1,2,⋯ ,m \underset{w,b}{\max} \frac{2}{||w||}\\ s.t. \ y_i(\pmb{w^Tx_i}+b) \ge 1,i=1,2,\cdots,m w,bmax∣∣w∣∣2s.t. yi(wTxiwTxiwTxi+b)≥1,i=1,2,⋯,m
为了最大化间隔,仅需要最大化∣∣w∣∣−1||w||^{-1}∣∣w∣∣−1,这等价于最下化∣∣w∣∣2||w||^2∣∣w∣∣2
minw,b12∣∣w∣∣2s.t. yi(wTxi+b)≥1,i=1,2,⋯ ,m \underset{w,b}{\min} \frac{1}{2} ||w||^2 \\ s.t. \ y_i(\pmb{w^Tx_i} + b) \ge 1,i=1,2,\cdots,m w,bmin21∣∣w∣∣2s.t. yi(wTxiwTxiwTxi+b)≥1,i=1,2,⋯,m
对偶问题
对于最大间隔划分超平面对应的模型
f(x)=wTx+b f(\pmb{x}) = \pmb{w^Tx} + b f(xxx)=wTxwTxwTx+b
这是一个凸二次规划(convex quadratic programming)问题
使用拉格朗日乘子法可以得到其对偶问题,对于每个约束添加拉格朗日乘子αi≥0\alpha_i \ge 0αi≥0,则该问题是拉格朗日函数为:
L(ω,b,α)=12∣∣w∣∣2+∑i=1mαi(1−yi(wTxi+b)) L(\pmb{\omega},b,\alpha) = \frac{1}{2}||\pmb{w}||^2 + \sum_{i=1}^m \alpha_i(1-y_i(w^Tx_i+b)) L(ωωω,b,α)=21∣∣www∣∣2+i=1∑mαi(1−yi(wTxi+b))
其中α=(α1,α2,⋯ ,αm)\pmb{\alpha}=(\alpha_1,\alpha_2,\cdots,\alpha_m)ααα=(α1,α2,⋯,αm)。令L(ω,b,α)L(\pmb\omega,b,\alpha)L(ωωω,b,α)对ω\pmb\omegaωωω和bbb的偏导为零可得
ω=∑i=1mαiyixi0=∑i=1mαiyi \pmb\omega = \sum_{i=1}^m \alpha_iy_i\pmb{x_i}\\ 0 = \sum_{i=1}^m \alpha_iy_i ωωω=i=1∑mαiyixixixi0=i=1∑mαiyi
推导:
L(w,b,α)=12∣∣w∣∣2+∑i=1mαi(1−yi(wtxi+b))=12∣∣w∣∣2+∑i=1m(αi−αiyiwTxi−αiyib)=12ωTω+∑i=1mαi−∑i=1mαiyiwTxi−∑i=1mαiyib \begin{aligned} L(\pmb w,b,\alpha) & =\frac{1}{2}||w||^2 + \sum_{i=1}^m \alpha_i(1-y_i(w^tx_i+b)) \\ &=\frac{1}{2} ||w||^2 + \sum_{i=1}^m(\alpha_i - \alpha_iy_iw^Tx_i - \alpha_iy_ib)\\ &= \frac{1}{2} \omega^T\omega + \sum_{i=1}^m \alpha_i-\sum_{i=1}^m\alpha_iy_iw^Tx_i -\sum_{i=1}^m \alpha_iy_ib \end{aligned} L(www,b,α)=21∣∣w∣∣2+i=1∑mαi(1−yi(wtxi+b))=21∣∣w∣∣2+i=1∑m(αi−αiyiwTxi−αiyib)=21ωTω+i=1∑mαi−i=1∑mαiyiwTxi−i=1∑mαiyib
对ω\omegaω和bbb分别求偏函数并令等于0
∂L∂w=ω+0−∑i=1maiyixi−0=0⇒w=∑i=1mαiyixi∂L∂b=0+0−0−∑i=1mαiyi=0⇒∑i=1mαiyi=0 \frac{\partial L}{\partial \pmb w} = \omega + 0 -\sum_{i=1}^m a_iy_ix_i-0 =0\Rightarrow \pmb w = \sum_{i=1}^m \alpha_iy_ix_i \\ \frac{\partial L}{\partial b} = 0+0-0-\sum_{i=1}^{m} \alpha_iy_i=0\Rightarrow \sum_{i=1}^m \alpha_iy_i=0 ∂www∂L=ω+0−i=1∑maiyixi−0=0⇒www=i=1∑mαiyixi∂b∂L=0+0−0−i=1∑mαiyi=0⇒i=1∑mαiyi=0
可以得到对偶问题
maxα∑i=1mαi−12∑i=1m∑j=1mαiαjyiyjxiTxjs.t. ∑i=1mαiyi=0αi≥0,i=1,2,⋯ ,m \underset{\alpha}{\max} \sum_{i=1}^m \alpha_i - \frac{1}{2} \sum_{i=1}^m \sum_{j=1}^m \alpha_i\alpha_j y_iy_jx_i^Tx_j \\ s.t. \ \sum_{i=1}^m \alpha_iy_i=0 \\ \alpha_i \ge 0, i=1,2,\cdots,m αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxjs.t. i=1∑mαiyi=0αi≥0,i=1,2,⋯,m
推导:
minw,bL(w,b,α)=12ww+∑i=1mαi−∑i=1mαiyiwTxi−∑i=1mαiyib=12ωT∑i=1mαiyixi−wT∑i=1mαiyixi+∑i=1mαi−b∑i=1mαiyi=−12wT∑i=1mαiyixi+∑i=1mαi−b∑i=1mαiyi \begin{aligned} \underset{w,b}{\min} L(w,b,\alpha) &= \frac{1}{2}w^w + \sum_{i=1}^m \alpha_i - \sum_{i=1}^m \alpha_iy_iw^Tx_i - \sum_{i=1}^m \alpha_iy_ib \\ &= \frac{1}{2}\omega^T\sum_{i=1}^m \alpha_iy_ix_i -w^T\sum_{i=1}^m \alpha_i y_ix_i + \sum_{i=1}^m \alpha_i - b\sum_{i=1}^m \alpha_iy_i \\ &=-\frac{1}{2} w^T\sum_{i=1}^m \alpha_i y_i x_i + \sum_{i=1}^m \alpha_i - b\sum_{i=1}^m \alpha_iy_i \end{aligned} w,bminL(w,b,α)=21ww+i=1∑mαi−i=1∑mαiyiwTxi−i=1∑mαiyib=21ωTi=1∑mαiyixi−wTi=1∑mαiyixi+i=1∑mαi−bi=1∑mαiyi=−21wTi=1∑mαiyixi+i=1∑mαi−bi=1∑mαiyi
由于∑i=1mαiyi=0\sum_{i=1}^m \alpha_iy_i=0∑i=1mαiyi=0,所以
minw,bL(w,b,α)=−12wT∑i=1mαiyixi+∑i=1mαi=−12(∑i=1mαiyixi)T(∑i=1mαiyixi)+∑i=1mαi=−12(∑i=1mαiyixiT)(∑i=1mαiyixi)+∑i=1mαi=∑i=1mαi−12∑i=1m∑j=1mαiαjyiyjxiTxj \begin{aligned} \underset{w,b}{\min} L(w,b,\alpha) & = -\frac{1}{2}w^T\sum_{i=1}^m \alpha_iy_ix_i + \sum_{i=1}^m \alpha_i \\ &=-\frac{1}{2}(\sum_{i=1}^m \alpha_iy_ix_i)^T(\sum_{i=1}^m \alpha_iy_ix_i) + \sum_{i=1}^m \alpha_i \\ & = -\frac{1}{2} (\sum_{i=1}^m \alpha_iy_ix_i^T)(\sum_{i=1}^m \alpha_iy_ix_i) + \sum_{i=1}^m \alpha_i \\ &=\sum_{i=1}^m \alpha_i - \frac{1}{2} \sum_{i=1}^m \sum_{j=1}^m \alpha_i\alpha_j y_iy_jx_i^Tx_j \end{aligned} w,bminL(w,b,α)=−21wTi=1∑mαiyixi+i=1∑mαi=−21(i=1∑mαiyixi)T(i=1∑mαiyixi)+i=1∑mαi=−21(i=1∑mαiyixiT)(i=1∑mαiyixi)+i=1∑mαi=i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj
所以
maxαminw,b=maxα∑i=1mαi−12∑i=1m∑j=1mαiαjyiyjxiTxj \underset{\alpha}{\max}\underset{w,b}{\min} = \underset{\alpha}{\max}\sum_{i=1}^m \alpha_i - \frac{1}{2} \sum_{i=1}^m \sum_{j=1}^m \alpha_i\alpha_j y_iy_jx_i^Tx_j αmaxw,bmin=αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj
解出α\alphaα后,求出w,bw,bw,b即可得到模型
上述过程需要满足KKT(Karush-Kuhn-Tucker)条件,即要求
{αi≥0yif(xi)−1≥0αi(yif(xi)−1)=0 \begin{cases} \alpha_i \ge 0 \\ y_if(x_i)-1\ge 0 \\ \alpha_i(y_if(x_i)-1) = 0 \end{cases} ⎩⎪⎨⎪⎧αi≥0yif(xi)−1≥0αi(yif(xi)−1)=0
对于任意训练样本(xi,yi)(x_i,y_i)(xi,yi),总有αi=0\alpha_i=0αi=0或yif(xi)=1y_if(x_i)=1yif(xi)=1,若αi=0\alpha_i=0αi=0,则这样的样本不会出现在求和中,对f(x)f(x)f(x)有任何影响。若αi>0\alpha_i >0αi>0,则必有yif(xi)=1y_if(x_i)=1yif(xi)=1,则对应的样本点在于最大分隔边界上,是一个支持向量。
如何求解呢,这是一个二次规划问题,可以使用通用的二次规划算法来求解,其中高效的算法有很多,其中SMO(Sequential Minimal Optimization)是其中一个著名的代表。
SMO的基本思想是先管你的固定αi\alpha_iαi之外的所有参数,然后求αi\alpha_iαi上的极限。。由于存在约束∑i=1mαiyi=0\sum_{i=1}^m \alpha_iy_i=0∑i=1mαiyi=0,若固定αi\alpha_iαi之外的其他变量,则αi\alpha_iαi可由其他变量导出。于是,SMO每次选择两个变量αi\alpha_iαi和αj\alpha_jαj,并固定其他参数。
- 选择一对需要更新的变量αi\alpha_iαi和αj\alpha_jαj
- 固定αi\alpha_iαi和αj\alpha_jαj以外的参数,求解更新后的αi\alpha_iαi和$\alpha_j $
注意到只需选取的αi\alpha_iαi和αj\alpha_jαj中有一个不满足KKT条件,目标函数就会在迭代后减少,于是,SMO先选取违背KKT条件的最大的变量,第二个变量应选择一个使目标函数值减少最快的变量,但是比较各变量所对应的目标函数值减少幅度复杂度过高,因此SMO采用了一个启发式:使选择的两变量所对应样本之间的间隔最大,一种直观解释就是,这样的两个变量有很大的差别,与对两个相似的变量进行更新相比,对他们更新会给目标函数值更大的变化。
SMO算法值所以高效,由于在固定其他参数后,优化两个参数的过程能够非常有效。具体来说,仅考虑αi\alpha_iαi和αj\alpha_jαj时,约束可以重新写成:
αiyi+ajyj=c,αi≥0,αj≥0 \alpha_iy_i+a_jy_j = c , \alpha_i \ge 0, \alpha_j \ge 0 αiyi+ajyj=c,αi≥0,αj≥0
其中
c=−∑k≠i,jakyk c = -\sum_{k\ne i,j} a_ky_k c=−k=i,j∑akyk
消去αj\alpha_jαj,则得到一个关于αi\alpha_iαi的单变量二次规划问题,仅有约束αi≥0\alpha_i \ge 0αi≥0 。这样的二次规划问题具有闭式解,于是不必调用数值优化算法即可高效的计算出更新后的αi\alpha_iαi和αj\alpha_jαj
对于ySf(xS=1)y_Sf(\pmb{x_S}=1)ySf(xSxSxS=1)
ys(∑i∈SαiyixiTxs+b)=1 y_s(\sum_{i\in S}\alpha_iy_i\pmb{x_i^Tx_s}+b)=1 ys(i∈S∑αiyixiTxsxiTxsxiTxs+b)=1
其中S={i∣αi>0,i=1,2,3,⋅,m}S = \{i|\alpha_i>0,i=1,2,3,\cdot,m\}S={i∣αi>0,i=1,2,3,⋅,m}所支持向量的下标集。
b=1∣S∣∑s∈S(ys−∑αiyixiTxs) b = \frac{1}{|S|} \sum_{s\in S} (y_s-\sum{\alpha_iy_i\pmb{x_i^Tx_s}}) b=∣S∣1s∈S∑(ys−∑αiyixiTxsxiTxsxiTxs)
核函数
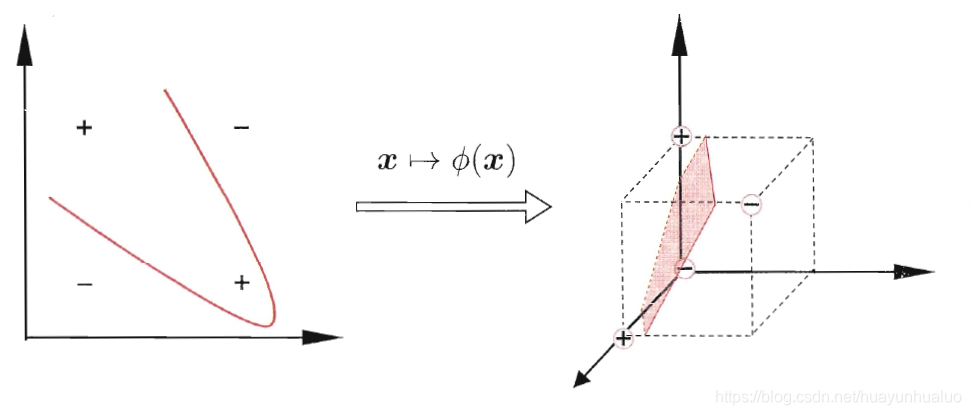
在实际的任务中,原始样本空间内也许不存在一个能正确划分两类样本的超平面,对于这样的问题,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。
令ϕ(x)\phi(\pmb{x})ϕ(xxx)表示将x\pmb{x}xxx映射后的特征向量,于是,在特征空间中划分超平面所对应的模型可表示为
f(x)=wTϕ(x)+b f(\pmb{x}) = \pmb{w}^T\phi(\pmb{x}) +b f(xxx)=wwwTϕ(xxx)+b
其中w\pmb{w}www和bbb是参数模型
minw,b12∣∣w∣∣2s.t. yi(wTϕ(xi)+b)≥1,i=1,2,⋯ ,m \underset{\pmb{w},b}{\min} \frac{1}{2} ||\pmb{w}||^2 \\ s.t. \ y_i(\pmb{w}^T\phi(\pmb{x_i})+b) \ge 1,i=1,2,\cdots,m www,bmin21∣∣www∣∣2s.t. yi(wwwTϕ(xixixi)+b)≥1,i=1,2,⋯,m
对偶问题是:
maxα∑i=1mαi−12∑i=1m∑j=1mαiαjyiyjϕ(xi)Tϕ(xj)s.t. ∑i=1mαiyj=0,αi≥0,i=1,2,3⋯ ,m \underset{\alpha}{\max} \sum_{i=1}^m \alpha_i - \frac{1}{2}\sum_{i=1}^m \sum_{j=1}^m \alpha_i \alpha_j y_i y_j \phi(\pmb{x_i})^T\phi(\pmb{x_j}) \\ s.t. \ \sum_{i=1}^m \alpha_iy_j = 0, \alpha_i \ge 0,i=1,2,3\cdots,m αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjϕ(xixixi)Tϕ(xjxjxj)s.t. i=1∑mαiyj=0,αi≥0,i=1,2,3⋯,m
设计到计算ϕ(xi)Tϕ(xj)\phi(\pmb{x_i})^T\phi(\pmb{x_j})ϕ(xixixi)Tϕ(xjxjxj),由于映射后的特征空间维数可能很高,甚至可能是无穷维的,因此直接计算ϕ(xi)Tϕ(xj)\phi(\pmb{x_i})^T\phi(\pmb{x_j})ϕ(xixixi)Tϕ(xjxjxj)通常是困难的。可以设想这样的一个函数
κ(xi,xj)=⟨ϕ(xi),ϕ(xj)⟩=ϕ(xi)Tϕ(xj) \kappa(\pmb{x_i,x_j}) = \langle \phi(\pmb{x_i}),\phi(\pmb{x_j}) \rangle =\phi(\pmb{x_i})^T\phi(\pmb{x_j}) κ(xi,xjxi,xjxi,xj)=⟨ϕ(xixixi),ϕ(xjxjxj)⟩=ϕ(xixixi)Tϕ(xjxjxj)
于是xix_ixi与xjx_jxj在特征空间的内积等于他们在原始样本空间中通过函数κ\kappaκ来计算的结果。
maxα∑i=1mαi−12∑i=1m∑j=1mαiαjyiyjκ(xi,xj)s.t. ∑i=1mαiyi=0,αi≥0,i=1,2,⋯ ,m \underset{\alpha}{\max} \sum_{i=1}^m \alpha_i - \frac{1}{2} \sum_{i=1}^m\sum_{j=1}^m \alpha_i\alpha_j y_iy_j\kappa(\pmb{x_i,x_j}) \\ s.t. \ \sum_{i=1}^m \alpha_iy_i=0 , \alpha_i \ge 0, i=1,2,\cdots,m αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjκ(xi,xjxi,xjxi,xj)s.t. i=1∑mαiyi=0,αi≥0,i=1,2,⋯,m
求解后可得到
f(x)=wTϕ(x)+b=∑i=1mαiyiϕ(xi)Tϕ(xi)+b=∑i=1mαiyiκ(xi,xj)+b \begin{aligned} f(x) &= \pmb{w}^T\phi(\pmb{x})+b \\ &= \sum_{i=1}^m \alpha_i y_i\phi(\pmb{x_i})^T\phi(\pmb{x_i}) + b \\ &= \sum_{i=1}^m \alpha_i y_i \kappa(\pmb{x_i,x_j}) + b \end{aligned} f(x)=wwwTϕ(xxx)+b=i=1∑mαiyiϕ(xixixi)Tϕ(xixixi)+b=i=1∑mαiyiκ(xi,xjxi,xjxi,xj)+b
这里的κ\kappaκ就是核函数,显示出来的模型最优解可通过训练样本的核函数展开,称为支持向量展式
核函数
令X\mathcal{X}X为输入空间,κ(⋅,⋅)\kappa(\cdot, \cdot)κ(⋅,⋅)是定义在X×X\mathcal{X}\times \mathcal{X}X×X上的对称函数,则κ\kappaκ是核函数当且仅当对于任意数据D={x1,x2,,⋯ ,xm}D=\{\pmb{x_1,x_2,,\cdots,x_m}\}D={x1,x2,,⋯,xmx1,x2,,⋯,xmx1,x2,,⋯,xm}。核矩阵K\pmb{K}KKK总是半正定的
K=[κ(x1,x1)⋯κ(x1,xj)⋯κ(x1,xm)⋮⋱⋮⋱⋮κ(xi,x1)⋯κ(xi,xj)⋯κ(xi,xm)⋮⋱⋮⋱⋮κ(xm,x1)⋯κ(xm,xj)⋯κ(xm,xm)] \pmb{K} = \begin{bmatrix} \kappa(\pmb{x_1,x_1}) & \cdots & \kappa(\pmb{x_1,x_j}) & \cdots & \kappa(\pmb{x_1,x_m}) \\ \vdots & \ddots & \vdots & \ddots & \vdots \\ \kappa(\pmb{x_i,x_1}) & \cdots & \kappa(\pmb{x_i,x_j}) &\cdots & \kappa(\pmb{x_i,x_m}) \\ \vdots & \ddots & \vdots & \ddots & \vdots \\ \kappa(\pmb{x_m,x_1}) & \cdots & \kappa(\pmb{x_m,x_j}) & \cdots & \kappa(\pmb{x_m,x_m}) \end{bmatrix} KKK=⎣⎢⎢⎢⎢⎢⎢⎡κ(x1,x1x1,x1x1,x1)⋮κ(xi,x1xi,x1xi,x1)⋮κ(xm,x1xm,x1xm,x1)⋯⋱⋯⋱⋯κ(x1,xjx1,xjx1,xj)⋮κ(xi,xjxi,xjxi,xj)⋮κ(xm,xjxm,xjxm,xj)⋯⋱⋯⋱⋯κ(x1,xmx1,xmx1,xm)⋮κ(xi,xmxi,xmxi,xm)⋮κ(xm,xmxm,xmxm,xm)⎦⎥⎥⎥⎥⎥⎥⎤
表明只要一个对称函数所对应的的核矩阵半正定,就能作为核函数使用。任何一个核函数都隐式地定义一个称为再生核希尔伯特空间(Reproducing Kernel Hilbert Sapce,RKHS)的特征空间。
常用的核函数
| 名称 | 表达式 | 参数 |
|---|---|---|
| 线性核 | κ(xi,xj)=xiTxj\kappa(x_i,x_j)=x_i^Tx_jκ(xi,xj)=xiTxj | |
| 多项式核 | κ(xi,xj)=(xiTxj)d\kappa(x_i,x_j)=(x_i^Tx_j)^dκ(xi,xj)=(xiTxj)d | d≥1d\ge 1d≥1为多项式的次数 |
| 高斯核 | $\kappa(x_i,x_j)=\exp(-\frac{ | |
| 拉普拉斯核 | $\kappa(x_i,x_j)=\exp(-\frac{ | |
| Sigmoid核 | κ(xi,xj)=tanh(βjxiTxi+θ)\kappa(x_i,x_j)=\tanh(\beta jx_i^Tx_i+\theta)κ(xi,xj)=tanh(βjxiTxi+θ) | tanh\tanhtanh为双曲正切函数,β>0,θ<0\beta>0,\theta <0β>0,θ<0 |
还可以通过函数组合通过
-
若κ1\kappa_1κ1和κ2\kappa_2κ2为核函数,则对于任意整数γ1,γ2\gamma_1,\gamma_2γ1,γ2其线性组合为
γ1κ1+γ2κ2 \gamma_1\kappa_1 + \gamma_2 \kappa_2 γ1κ1+γ2κ2
也是核函数 -
若κ1\kappa_1κ1和κ2\kappa_2κ2是核函数,则核函数的直积
κ1⊗κ2(x,z)=κ1(x,z)κ2(x,z) \kappa_1\otimes\kappa_2(x,z) =\kappa_1(x,z)\kappa_2(x,z) κ1⊗κ2(x,z)=κ1(x,z)κ2(x,z)
也是核函数 -
若κ1\kappa_1κ1为核函数,则对于任意函数g(x)g(x)g(x)
κ(x,z)=g(x)κ1(x,z)g(z) \kappa(x,z) = g(x)\kappa_1(x,z)g(z) κ(x,z)=g(x)κ1(x,z)g(z)

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)