
机器学习-决策树
在决策树的构建过程中,信息增益指导着选择在哪个特征上进行划分。信息增益越大,说明使用该特征进行划分后,数据集的纯度提升得越多。在决策树的构建过程中,基尼指数被用来选择最佳的划分特征。基尼指数越低,说明使用该特征进行划分后,数据集的纯度提升得越多。剪枝的目标是通过移除一些节点或子树来降低模型的复杂度,同时保持或提高模型的性能。通过选择最佳的特征来划分数据集,使得划分后各个子集的纯度尽可能高。子节点的
决策树
决策树是一种基本的分类和回归方法。它通过对数据集进行递归地划分,每次选择最佳的特征来生成树形结构。在分类问题中,每个叶节点代表一个类别,而在回归问题中,每个叶节点代表一个数值。
构建决策树的过程
选择最佳特征划分数据集: 通过选择最佳的特征来划分数据集,使得划分后各个子集的纯度尽可能高。常用的指标包括信息增益、基尼不纯度等。
递归地构建子树: 对划分后的每个子集重复上述过程,直到满足停止条件,例如达到最大深度、节点中的样本数量小于某个阈值等。
生成决策树: 将以上过程递归地进行,直到生成完整的决策树。
剪枝: 可选的步骤,用于减少树的复杂度并提高泛化能力。剪枝的目标是通过移除一些节点或子树来降低模型的复杂度,同时保持或提高模型的性能。
信息增益:
信息增益是基于信息论的概念,用来衡量一个特征对于减少不确定性的影响。在决策树的构建过程中,信息增益指导着选择在哪个特征上进行划分。信息增益越大,说明使用该特征进行划分后,数据集的纯度提升得越多。信息增益的计算涉及到熵的概念,通常使用以下公式来计算:
信息增益=父节点的熵 - 加权子节点的熵
父节点的熵越高,代表数据集的不确定性越大;子节点的熵越低,代表划分后的数据集越纯净。
基尼指数:
基尼指数衡量了一个数据集中随机抽取两个样本,其类别标签不一致的概率。在决策树的构建过程中,基尼指数被用来选择最佳的划分特征。基尼指数越低,说明使用该特征进行划分后,数据集的纯度提升得越多。基尼指数的计算公式为:
G=1-∑ (Pi^2)
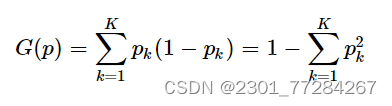
基尼指数越低,表示数据集的纯度越高,即样本属于同一类别的概率越大。
决策树模型构建:
读入数据并划分数据集
# 读取 xlsx 文件,指定文件路径
df = pd.read_excel(r'C:\Users\86187\Desktop\IRIS.xlsx')
# 替换分类名称为数字
df = df.replace({'Species': {'setosa': 0, 'versicolor': 1, 'virginica': 2}})
# X为特征,去掉目标变量列
X = df.drop(columns=['Species'])
# y为目标变量
y = df['Species']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)构建模型
# 创建决策树模型
model = DecisionTreeClassifier(max_depth=3, random_state=123)
# 拟合模型
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)显示分类模型
# 打印分类报告
print("Classification Report:\n", classification_report(y_test, y_pred))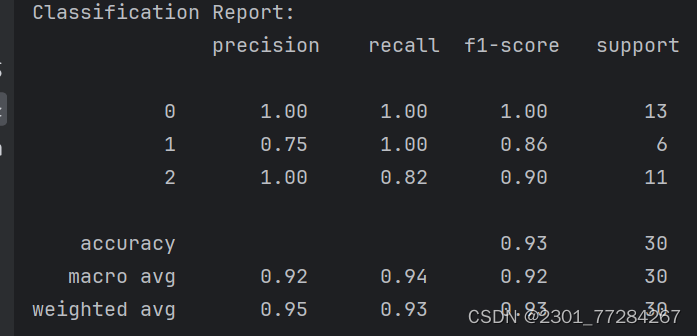
绘制roc曲线
# 计算各类别的ROC曲线和AUC
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(3):
fpr[i], tpr[i], _ = roc_curve(y_test == i, y_pred_proba[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# 绘制ROC曲线
plt.figure()
colors = ['blue', 'red', 'green']
for i, color in zip(range(3), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=2,
label='ROC curve of class {0} (area = {1:0.2f})'
''.format(i, roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()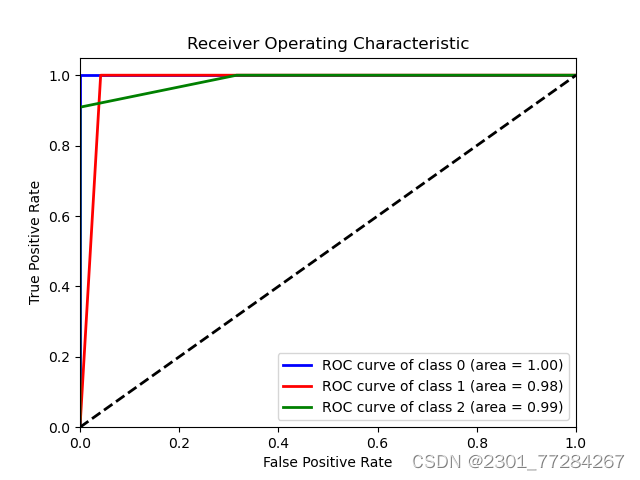
特征重要性
# 计算特征重要性
feature_importance = model.feature_importances_
feature_names = X.columns
sorted_idx = np.argsort(feature_importance)
plt.figure(figsize=(8, 6))
plt.barh(range(len(sorted_idx)), feature_importance[sorted_idx], align='center')
plt.yticks(range(len(sorted_idx)), feature_names[sorted_idx])
plt.xlabel('Feature Importance')
plt.title('Feature Importance for Decision Tree Classifier')
plt.show()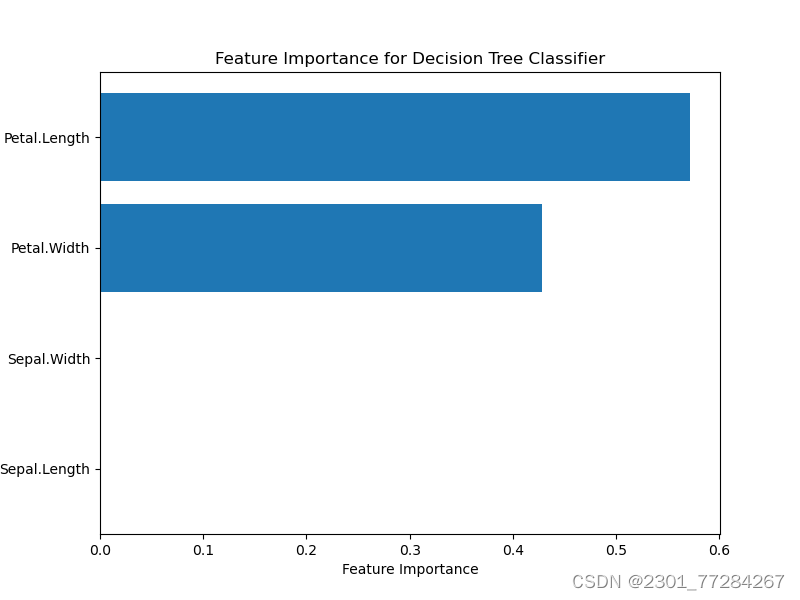
k值交叉验证
# K折交叉验证
kfold = StratifiedKFold(n_splits=5, shuffle=True, random_state=123)
scores = cross_val_score(model, X, y, cv=kfold)
print("Cross-validated Scores:", scores)
print("Mean Accuracy:", scores.mean())

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)