
大模型微调实践——Prefix tuning与P-tuning v2的原理、区别与代码解析最终章
回归传统的分类标签范式,而不是映射器。第二,缺少深度提示优化,在Prompt Tuning和P-tuning中,连续提示只被插入transformer第一层的输入embedding序列中,在接下来的transformer层中,插入连续提示的位置的embedding是由之前的transformer层计算出来的,这可能导致两个可能的优化挑战。在实验中,发现不同的理解任务通常用不同的提示长度来实现其最佳
作者:vivida
本文承接上篇P-tuning,介绍prefix-tuning与P-tuning v2并列出其区别,最后对整个系列的技术做总结。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
本篇是本系列最后一篇,没看过前面两篇的强烈建议去看一下。
大模型微调实践——Prompt tuning、PET、Prefix tuning、P-tuning的原理、区别与代码解析(一)
大模型微调实践——Prompt tuning、PET、Prefix tuning、P-tuning的原理、区别与代码解析(二)
因为prefix tuning和P-tuning v2非常相似,所以放在一起来介绍。简易目录如下:
Prefix-tuning
P-tuning v2
跟以前一样,具体还是会分为论文、原理、实现细节以及对应关键代码进行详细介绍,因为prefix tuning和P-tuning v2在官方库中基本是合并在一起的,所以代码放在一起讲,最后对所有方法做一个总结区分。
在开始前,我们再回忆一下自动构建模板微调模型的关键点:
1. 对virtual token的处理:随机初始化或者基于一个可训练学习的模型编码
2. 需要参与微调的参数:某一层、全量或者其他选择
3. 调整适配下游任务的方式
那么可以对应这三点看微调技术之间的区别就比较清晰。
Prefix tuning
一、论文
Prefix-Tuning: Optimizing Continuous Prompts for Generation
这篇论文本质也是把传统人工设计模版中的真实token替换成可微的virtual token;该方法在输入token之前构造一段任务相关的virtual tokens作为Prefix;然后,在训练的时候只更新Prefix部分的参数,而 PLM 中的其他部分参数固定。
二、原理与具体实现
1. 适配不同任务的prefix构造形式
针对自回归架构模型:在句子前面添加前缀,得到 z = [PREFIX; x; y],合适的上文能够在固定 LM 的情况下去引导生成下文(比如:GPT3的上下文学习)。
针对编码器-解码器架构模型:Encoder和Decoder都增加了前缀,得到 z = [PREFIX; x; PREFIX0; y]。Encoder端增加前缀是为了引导输入部分的编码,Decoder 端增加前缀是为了引导后续token的生成

图片
2. 对virtual token的编码方式
同时,为了防止直接更新 Prefix 的参数导致训练不稳定和性能下降的情况,在 Prefix 层前面加了 MLP 结构,训练完成后,只保留 Prefix 的参数。
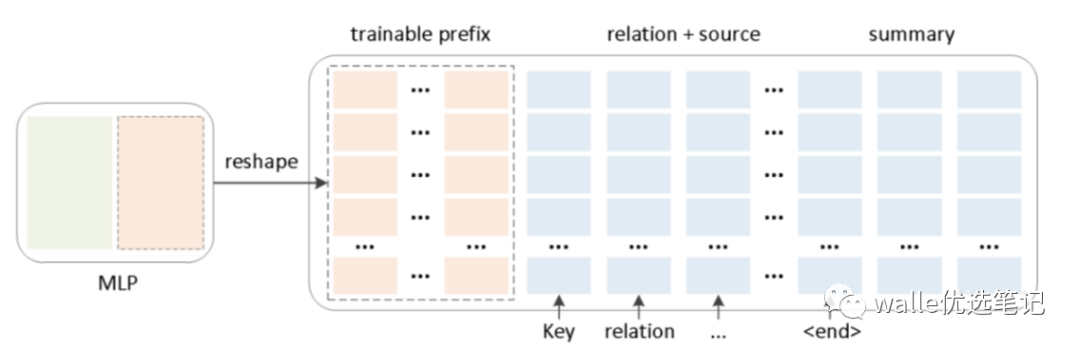
图片
除此之外,通过消融实验证实,只调整embedding层的表现力不够,将导致性能显著下降,因此,在每层都加了prompt的参数,改动较大。
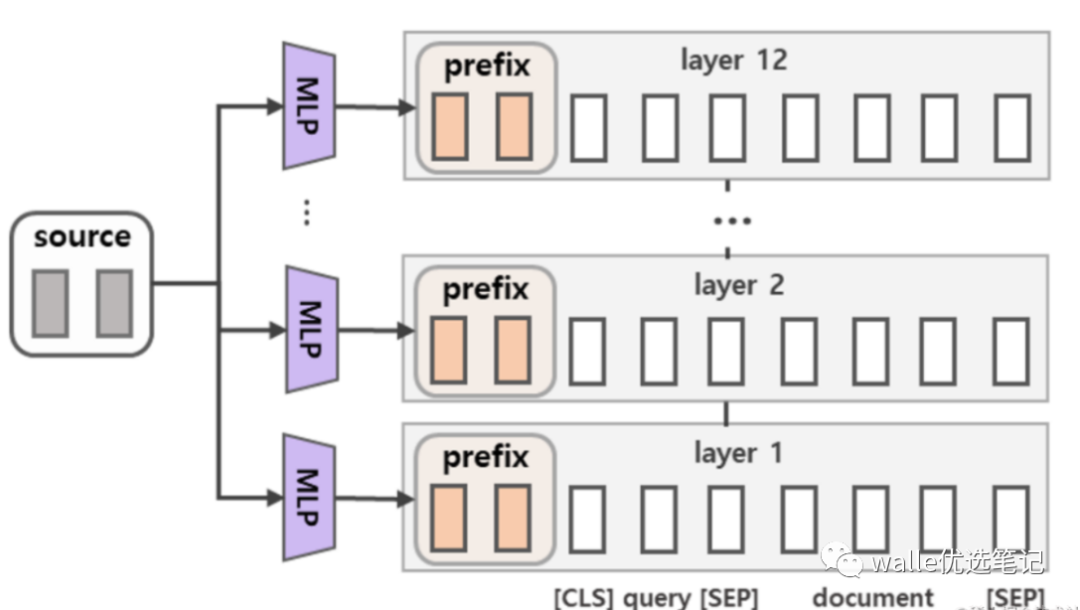
图片
P-tuning v2
一、论文
P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
之前的Prompt Tuning和P-Tuning等方法存在两个主要的问题:
第一,缺乏模型参数规模和任务通用性。
缺乏规模通用性:Prompt Tuning论文中表明当模型规模超过100亿个参数时,提示优化可以与全量微调相媲美。但是对于那些较小的模型(从100M到1B),提示优化和全量微调的表现有很大差异,这大大限制了提示优化的适用性。
缺乏任务普遍性:尽管Prompt Tuning和P-tuning在一些 NLU 基准测试中表现出优势,但提示调优对硬序列标记任务(即序列标注)的有效性尚未得到验证。
第二,缺少深度提示优化,在Prompt Tuning和P-tuning中,连续提示只被插入transformer第一层的输入embedding序列中,在接下来的transformer层中,插入连续提示的位置的embedding是由之前的transformer层计算出来的,这可能导致两个可能的优化挑战。
由于序列长度的限制,可调参数的数量是有限的。
输入embedding对模型预测只有相对间接的影响。
考虑到这些问题,作者提出了Ptuning v2,它利用深度提示优化(如:Prefix Tuning),对Prompt Tuning和P-Tuning进行改进,作为一个跨规模和NLU任务的通用解决方案。
该方法在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这带来两个方面的好处:
更多可学习的参数(从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%),同时也足够参数高效。
加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
二、原理与具体实现
具体做法基本同Prefix Tuning,可以看作是将文本生成的Prefix Tuning技术适配到NLU任务中,然后做了一些改进:
移除重参数化的编码器。以前的方法利用重参数化功能来提高训练速度和鲁棒性(如:Prefix Tuning 中的 MLP 、P-Tuning 中的 LSTM)。在 P-tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型,同时还会影响模型的表现。
针对不同任务采用不同的提示长度。提示长度在提示优化方法的超参数搜索中起着核心作用。在实验中,发现不同的理解任务通常用不同的提示长度来实现其最佳性能,这与 Prefix-Tuning 中的发现一致,不同的文本生成任务可能有不同的最佳提示长度。
引入多任务学习。先在多任务的Prompt上进行预训练,然后再适配下游任务。多任务学习对我们的方法来说是可选的,但可能是相当有帮助的。一方面,连续提示的随机性给优化带来了困难,这可以通过更多的训练数据或与任务相关的无监督预训练来缓解;另一方面,连续提示是跨任务和数据集的特定任务知识的完美载体。我们的实验表明,在一些困难的序列任务中,多任务学习可以作为P-tuning v2的有益补充。
回归传统的分类标签范式,而不是映射器。标签词映射器(Label Word Verbalizer)一直是提示优化的核心组成部分,它将one-hot类标签变成有意义的词,以利用预训练语言模型头。尽管它在few-shot设置中具有潜在的必要性,但在全数据监督设置中,Verbalizer并不是必须的,它阻碍了提示调优在我们需要无实际意义的标签和句子嵌入的场景中的应用。因此,P-Tuning v2回归传统的CLS标签分类范式,采用随机初始化的分类头(Classification Head)应用于tokens之上,以增强通用性,可以适配到序列标注任务。
三、代码详解
代码部分把prefix tuning和P-tuning v2放在一起写(Hugging face官方库也是合在一起的),因为virtual token是插入进每一层的,那么需要重点关注的是他是怎么进入每一层的:
本质上是通过past_key_values进入attention运算内部,在每一层中运算的。
这里先列出Hugging face 原生库中怎么实现的,然后再写一段仿真代码便于比较直观简易的理解。
Huggingface 官方版本
1. 设置virtual_token的数量及past_key_values维度
2. prefix encoder类的定义
这里如果self.prefix_projection为True,就是prefix tuning;如果self.prefix_projection为False,就是P-tuning v2。
3. past_key_values如何进入各层参与训练
这里从类ChatGLMModel中forward函数开始,逐步深挖past_key_values的相关运算。
1)类ChatGLMModel中forward函数
从上述代码 kv_caches=past_key_values 中可以看到,关键是encoder函数中的kv_caches 变量,我们继续挖。
2)encoder类
这里具体以类GLMTransformer中的forward函数为例。
我们重点关注 kv_cache 变量,可以看到这里分别加入了每一层并在 layer 函数中进行运算。
3)layers类
这里以GLMBlock为例,列出其forward函数。
4)self_attention类
终于找到了,我们直接看forward函数。
可以看到 kv_cache 实际是通过跟 key_layer 和 value_layer 连接,并入每一层运算的。
为了便于大家结合维度更深入理解,下面提供仿真代码来解释计算过程。
仿真代码
仿真代码这边就不需要关注prefix encoder类了,只需要记住加上MLP就是prefix tuning,不加就是p-tuning v2;这里就只写past_key_values的运算过程。
下面上代码,注意看运算向量维度的变化。
至此,我们就把Prompt Tuning、Pattern-Exploiting Training(PET)、prefix tuning、P-tuning、P-tuning v2全部介绍完了。最后我们先来做个粗略的总结:
Prompt Tuning:是个比较宽泛的概念,指按照特定模板去微调大模型,这个模板可以有两种形式:离散的或是连续的;
PET:这种模板是人工构建的,也就是离散的,其中被MASK掉的是自然语言;
prefix tuning、P-tuning、P-tuning v2:这种模板是连续的,可单独求导求参数。
针对prefix tuning、P-tuning、P-tuning v2,我们再做比较细致的区别,根据我们前面说的自动构建模板微调模型的三个关键点:
1. 对virtual token的处理:随机初始化或者基于一个可训练学习的模型编码
2. 需要参与微调的参数:某一层、全量或者其他选择
3. 调整适配下游任务的方式
我们列出具体区分的表格。


技术共进,成长同行——讯飞AI开发者社区
更多推荐



 1
1 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)